In the previous article, we introduced the installation, deployment and basic concepts of Flink. Today, let's learn about DataStream API, one of the core of Flink.
01 distributed stream processing foundation
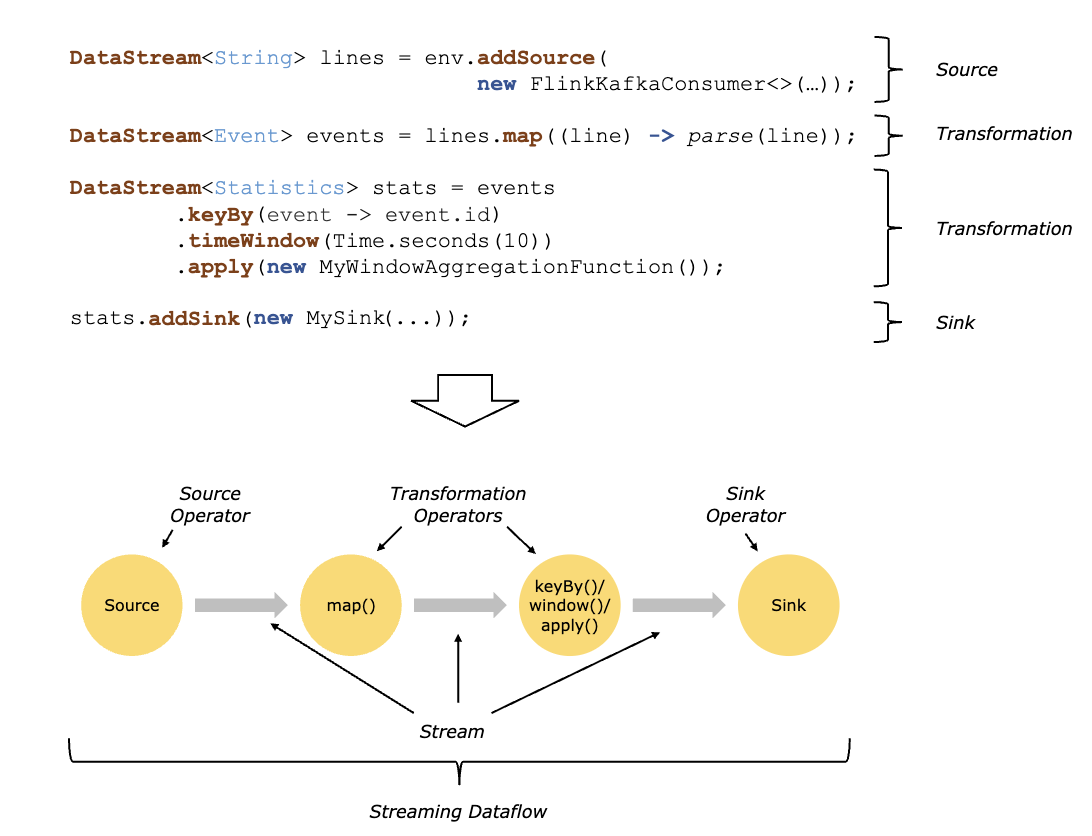
In the figure above, we divide the whole code into three parts, namely, the basic model of distributed stream processing:
- Source
- Transformation
- Sink
Thus, we can give Flink programming framework:
// 1. Obtain the operating environment
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. Load data source
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
// 3. Data processing operation
DataStream<Person> adults = flintstones.filter(new
FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
// 4. Write to Sink
adults.print();
// 5. Submit tasks for implementation
env.execute();
02 Flink DataStream API overview
For the programming model, we focus on the second step of Transformations, the processing of DataStream. The following figure shows the conversion process from DataStream to each Stream.
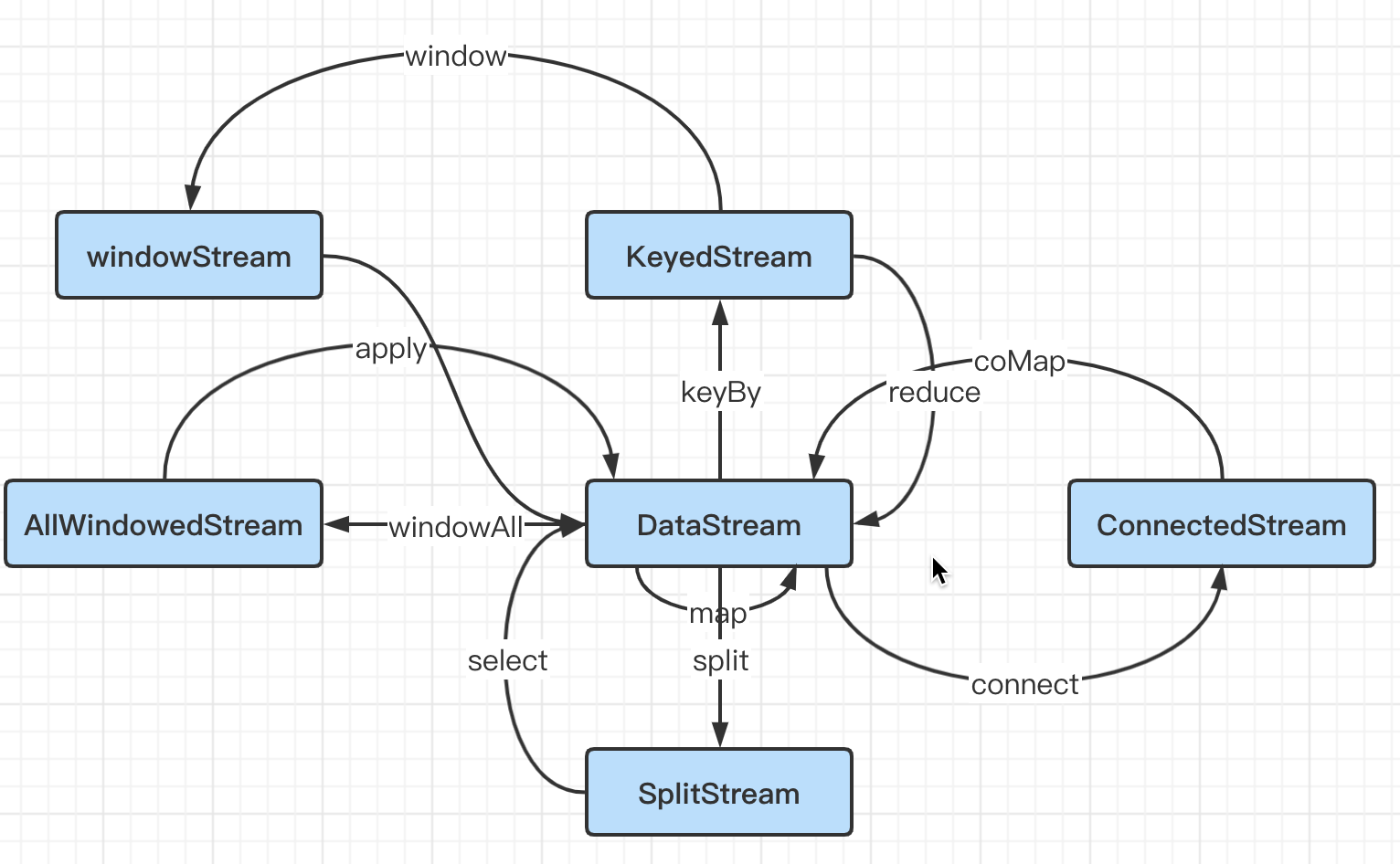
First of all, let's make a summary of the conversion operators between streams.
DataStream --> DataStream
fliter operator
Execute the filter function on each record and return the result as true.
SingleOutputStreamOperator<String> filter = kafkaDStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
if (s.contains("actions")) {
return true;
}
return false;
}
});
filter.print();
map operator
One input corresponds to one output, and MapFunction is executed for each record.
SingleOutputStreamOperator<String> map = kafkaDStream.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
return "Big data dry goods" + s;
}
});
map.print();
flatMap operator
One input corresponds to multiple outputs.
SingleOutputStreamOperator<String> flatMap = kafkaDStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] split = s.split("},");
for (String s1 : split) {
collector.collect(s1);
}
}
});
flatMap.print();
DataStream --> KeyedStream
keyBy operator
Data is grouped by key. Data with the same key is allocated to the same partition. hashcode is used internally.
The following data types cannot be used as key s:
- POJO type does not override hashcode method and depends on object Hashcode () implementation
- Array of any type
dataStream.keyBy(value -> value.getSomeKey()); dataStream.keyBy(value -> value.f0);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = jsonDS.map(new MapFunction<JSONObject, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(JSONObject jsonObject) throws Exception {
return new Tuple2<>(jsonObject.getJSONObject("common").getString("mid"), 1);
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
}).sum(1);
KeyedStream --> DataStream
Reduce operator
Only keyedStream can perform reduce, aggregate and merge the last reduce value and the current value, and submit a new result
Note that the returned stream contains the result of each aggregation, rather than just the final result of the last aggregation
SingleOutputStreamOperator<JSONObject> reduce = jsonDS.keyBy(new KeySelector<JSONObject, String>() {
@Override
public String getKey(JSONObject value) throws Exception {
return value.getJSONObject("common").getString("mid");
}
}).reduce(new ReduceFunction<JSONObject>() {
@Override
public JSONObject reduce(JSONObject value1, JSONObject value2) throws Exception {
Integer num = Integer.parseInt(value1.getJSONObject("common").getString("is_new")) +
Integer.parseInt(value2.getJSONObject("common").getString("is_new"));
value1.getJSONObject("common").put("is_new", num);
return value1;
}
});
reduce.print();
KeyedStream --> WindowedStream
window operator
In the last article "Flink streaming processing concept", we introduced the concept of window, that is, logically divide the data flow into "buckets" and calculate the data of the buckets.
The window is defined on the keyedStream. The window groups the data of each key according to certain rules, such as the data arriving in the last 5 seconds.
The following is only an example of the use of window operator, and the specific use methods will be given in subsequent articles.
SingleOutputStreamOperator<JSONObject> reduceWindow = jsonDS.keyBy(new KeySelector<JSONObject, String>() {
@Override
public String getKey(JSONObject value) throws Exception {
return value.getJSONObject("common").getString("mid");
}
}).window(TumblingEventTimeWindows.of(Time.seconds(10))) // Specify the scrolling window, and the window size is 10s
.reduce(new ReduceFunction<JSONObject>() {
@Override
public JSONObject reduce(JSONObject value1, JSONObject value2) throws Exception {
Integer num = Integer.parseInt(value1.getJSONObject("common").getString("is_new")) +
Integer.parseInt(value2.getJSONObject("common").getString("is_new"));
value1.getJSONObject("common").put("is_new", num);
return value1;
}
});
DataStream --> AllWindowedStream
windowAll operator
The window is defined on the general DataStream. The events in the whole stream are grouped according to certain rules. There is no parallel operation, and all data will be aggregated into one task.
SingleOutputStreamOperator<JSONObject> reduceWindowAll = jsonDS.windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.reduce(new ReduceFunction<JSONObject>() {
@Override
public JSONObject reduce(JSONObject value1, JSONObject value2) throws Exception {
Integer num = Integer.parseInt(value1.getJSONObject("common").getString("is_new")) +
Integer.parseInt(value2.getJSONObject("common").getString("is_new"));
value1.getJSONObject("common").put("is_new", num);
return value1;
}
});
WindowedStream/AllWindowedStream --> DataStream
apply operator
Apply a generic function to the window.
windowedStream.apply(new WindowFunction<Tuple2<String, Integer>, Integer, Tuple, window>(){
public void apply(Tuple tuple,Window window,Iterable<Tuple2<String,Integer>> values, Collector<Integer> out) throws Exception(){
int sum=0;
for(value t : values){
sum += t.f1;
}
out.collect(new Integer(sum));
}
});
allWindowedStream.apply(new AllWindowFunction<Tuple2<String, Integer>, Integer, Tuple, window>(){
public void apply(Tuple tuple,Window window,Iterable<Tuple2<String,Integer>> values, Collector<Integer> out) throws Exception(){
int sum=0;
for(value t : values){
sum += t.f1;
}
out.collect(new Integer(sum));
}
});
WindowReduce operator
Apply a reduce function to the window, return the result, and call the reduce operator of KeyedStream.
windowedStream.reduce(new ReduceFunction<Tuple2<String,Integer>>(){
public Tuple2<String,Integer> reduce(Tuple2<String,Integer> value1,Tuple2<String,Integer> value2) throws Exception{
return Tuple2<String,Integer>(value1.f0,value.f1+value2.f1);
}
});
DataStream* --> DataStream
union operator
Create a new DataStream that contains all elements of multiple streams and requires the same data type of streams.
dataStream.union(otherStream1,OtherStream2,...);
DataStream,DataStream --> DataStream
join operator
join two datastreams according to the given key.
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply(new JObFunction(){...});
CoGroup operator
Combine two datastreams according to the given key in one window
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply(new CoGroupFunction(){...});
KeyedStream,KeyedStream --> DataStream
Join interval operator
join two keyedstreams in a given time interval
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2),Time.milliseconds(2))
.upperBoundExclusive(true)
.lowerBoundExclusive(true)
.process(new IntervalJoinFunction(){...});
DataStream,DataStream --> ConnectedStream
connect operator
connect two hold type data streams. After the two data streams are connected, they are only placed in the same stream. Their internal data and form remain unchanged, and the two streams are independent of each other
DataStream<Integer> someStream = //... DataStream<String> otherStream = //... ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
ConnectedStream --> DataStream
CoMap,CoFlatMap operator
Similar to map and flatMap, but different processing logic can be applied to the two streams respectively
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>(){
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, Boolean>(){
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});
DataStream --> IterativeStream -->ConnectedStream
Iterate operator
Creates a feedback loop in the stream by redirecting the output of an operator to a previous operator. This is particularly useful for defining algorithms that constantly update the model. The following code starts with a flow and continuously applies the iteration body. Elements greater than 0 are sent back to the feedback channel, and other elements are forwarded downstream
IterativeStream<Long> iteration = initialStream.iterate();
DataStream<Long> iterationBody = iteration.map(...);
DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception{
return value>0;
}
});
iteration.colseWith(feedback);
DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception{
return value = 0;
}
});
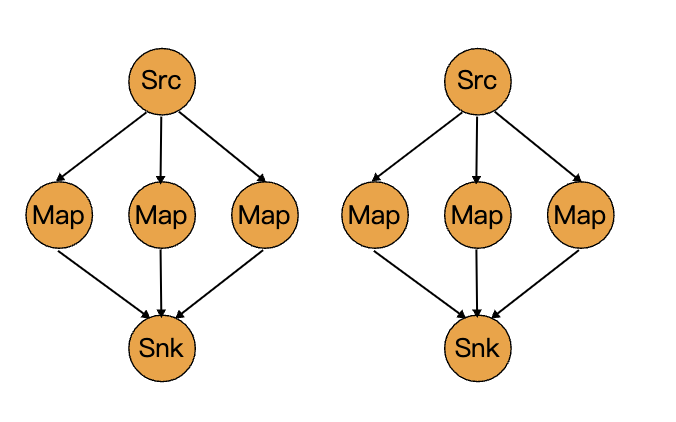
03 physical grouping
Flink program can set parallelism for each operator
Physical grouping can be used to partition data in finer granularity. The commonly used physical grouping is as follows:
Custom Partitioning
Use the user-defined partition function to select the target of each data.
dataStream.partitionCustom(partitioner, "someKey"); dataStream.partitionCustom(partitioner, 0);
Random Partitioning
Random uniform partition, i.e. random grouping.
dataStream.shuffle();
Rescaling
Local rotation allocation.
This operator is useful when you need to output from each parallel instance of the source to a subset of multiple mappers to distribute the load, but you don't want rebalance() to lead to a complete rebalancing.
At the same time, only local data transmission is required, not through the network, depending on other configuration values, such as the number of slots in TaskManager.
The subset of downstream operations to which the upstream operation sends elements depends on the parallelism of the upstream and downstream operations. For example, if the parallelism of upstream operations is 2 and the parallelism of downstream operations is 6, one upstream operation will assign elements to three downstream operations and the other upstream operation will assign elements to the other three downstream operations. On the other hand, if the parallelism of downstream operations is 2 and the parallelism of upstream operations is 6, three upstream operations will be assigned to one downstream operation and the other three upstream operations will be assigned to another downstream operation.
Where different degrees of parallelism are not multiples of each other, one or more downstream operations will have a different number of inputs from upstream operations.
jsonDS.keyBy(new KeySelector<JSONObject, String>() {
@Override
public String getKey(JSONObject value) throws Exception {
return value.getJSONObject("common").getString("mid");
}
}).map(new MapFunction<JSONObject, JSONObject>() {
@Override
public JSONObject map(JSONObject value) throws Exception {
return null;
}
}).setParallelism(6).rescale();
Broadcasting
Broadcast each element to all partitions, that is, each element will be sent to all partitions.
dataStream.broadcast();
04 type system
Flink supports the following data types:
| type | explain |
|---|---|
| Basic type | Java basic types (wrapper classes) and void, String, Date, BigDecimal, BigInteger |
| Composite type | Tuple and scala case classes (null is not supported), ROW and POJO |
| Auxiliary, set type | Option, Either, List, Map, etc |
| Arrays of the above types | |
| Other types | Custom type |
05 task chain and resource group
Task chain: linking two operators together can make them execute in the same thread, so as to improve performance.
By default, Flink links operators that can be linked as much as possible (for example, two map conversion operations). It also provides APIs for finer-grained control of links. These APIs can only be called after the DataStream conversion operation, because they only take effect for the previous data conversion.
Resource group: a resource group corresponds to a slot in Flink. Operators can be manually isolated into different slots as needed
Start New Chain
someStream.filter(...).map(...).startNewChain().map(...);
Disable Chaining
Do not open link operation.
someStream.map(...).disableChaining();
Set Slot Sharing Group
Sets the slot sharing group for the operation. Flink places operations with the same slot sharing group in the same slot, while operations without a slot sharing group remain in other slots. This can be used to isolate slots.
If all input operations are in the same slot sharing group, the slot sharing group inherits from the input operation. The name of the default slot sharing group is "default", and operations can be explicitly put into the group by calling slotSharingGroup("default").
someStream.filter(...).slotSharingGroup("name");
That's all for Flink's DataStream API. During the learning process, you still need to write your own code to understand the essence. You can use the code in the article flink-learning I hope it can help you.
