Flink reads Kafka data and sinks to Clickhouse
In real-time streaming data processing, we can usually do real-time OLAP processing in the way of Flink+Clickhouse. The advantages of the two will not be repeated. This paper uses a case to briefly introduce the overall process.
Overall process:
- Import json format data to kafka specific topics
- Write the data under the consumption theme of Flink Kafka consumer
- Data processing using Flink operator (ETL)
- Sink the processed data into the Clickhouse database
Import json format data to kafka specific topics
After creating the theme, use Kafka - console - producer The SH command sends the pre JSON format data to the created topic, such as JSON format data:
{"appKey":"mailandroid","deviceId":"1807516f-1cb3-4a6e-8ac1-454d401a5716","version":"1.0","uid":"","dashiUid":"1388f4059f87578418ba2906c5425af5","ua":"","carrier":"China Mobile", ...}
{"appKey":"mailios","deviceId":"0B4D45A9-3212-4C38-B58E-1A96792AF297","version":"1.0","uid":"","dashiUid":"c53f631b1d33273f28953893b7383e0a","ua":"Mozilla/5.0 (iPhone; CPU iPhone OS 15_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148","carrier":"China Mobile", ...}
...
After writing, you can use Kafka console consumer SH to check whether the data under the corresponding topic has been written.
Write the data under the consumption theme of Flink Kafka consumer
Create a project in Idea to write code and connect Kafka for consumption.
package com.demo.flink;
import com.alibaba.fastjson.JSON;
import com.demo.flink.pojo.Mail;
import com.demo.flink.utils.MyClickHouseUtil;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.HashMap;
import java.util.Properties;
public class FlinkSinkClickhouse {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// source
String topic = "test_process";
Properties props = new Properties();
// Set parameters for connecting kafka clusters
props.setProperty("bootstrap.servers", "10.224.192.133:9092, 10.224.192.134:9092");
// Define Flink Kafka Consumer
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), props);
consumer.setStartFromGroupOffsets();
consumer.setStartFromEarliest(); // Set to consume from scratch every time
// Add source data stream
DataStreamSource<String> source = env.addSource(consumer);
System.out.println(source);
SingleOutputStreamOperator<Mail> dataStream = source.map(new MapFunction<String, Mail>() {
@Override
public Mail map(String value) throws Exception {
HashMap<String, String> hashMap = JSON.parseObject(value, HashMap.class);
// System.out.println(hashMap);
String appKey = hashMap.get("appKey");
String appVersion = hashMap.get("appVersion");
String deviceId = hashMap.get("deviceId");
String phone_no = hashMap.get("phone_no");
Mail mail = new Mail(appKey, appVersion, deviceId, phone_no);
// System.out.println(mail);
return mail;
}
});
dataStream.print();
// sink
String sql = "INSERT INTO test.ods_countlyV2 (appKey, appVersion, deviceId, phone_no) " +
"VALUES (?, ?, ?, ?)";
MyClickHouseUtil ckSink = new MyClickHouseUtil(sql);
dataStream.addSink(ckSink);
env.execute();
The above uses Java Flink to connect to Kafka, and sets some necessary parameters for initialization and connection. Finally, add the data stream to addSource
Data processing using Flink operator (ETL)
A simple ETL process uses Flink's Map operator to write its own data processing logic in the Map operator. The Mail class here is a Pojo class defined by myself, which is used to encapsulate the json results to be saved after processing. Because the data read by Kafka is value in String format, it uses the json of fastjson Parseobject (value, HashMap. Class) is converted to the format of HashMap to get the key value pairs I need. Finally, the required key value pairs are encapsulated as MailPojo classes for return. So as to make a simple ETL process for data flow.
Sink the processed data into the Clickhouse database
Finally, the processed data needs to sink into the Clickhouse for saving and use. The code of sink clickhouse is given below
package com.demo.flink.utils;
import com.demo.flink.pojo.Mail;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import ru.yandex.clickhouse.ClickHouseConnection;
import ru.yandex.clickhouse.ClickHouseDataSource;
import ru.yandex.clickhouse.ClickHouseStatement;
import ru.yandex.clickhouse.settings.ClickHouseProperties;
import ru.yandex.clickhouse.settings.ClickHouseQueryParam;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.HashMap;
import java.util.Map;
public class MyClickHouseUtil extends RichSinkFunction<Mail> {
private ClickHouseConnection conn = null;
String sql;
public MyClickHouseUtil(String sql) {
this.sql = sql;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
return ;
}
@Override
public void close() throws Exception {
super.close();
if (conn != null)
{
conn.close();
}
}
@Override
public void invoke(Mail mail, Context context) throws Exception {
String url = "jdbc:clickhouse://10.224.192.133:8123/test";
ClickHouseProperties properties = new ClickHouseProperties();
properties.setUser("default");
properties.setPassword("ch20482048");
properties.setSessionId("default-session-id");
ClickHouseDataSource dataSource = new ClickHouseDataSource(url, properties);
Map<ClickHouseQueryParam, String> additionalDBParams = new HashMap<>();
additionalDBParams.put(ClickHouseQueryParam.SESSION_ID, "new-session-id");
try {
conn = dataSource.getConnection();
PreparedStatement preparedStatement = conn.prepareStatement(sql);
preparedStatement.setString(1,mail.getAppKey());
preparedStatement.setString(2, mail.getAppVersion());
preparedStatement.setString(3, mail.getDeviceId());
preparedStatement.setString(4, mail.getPhone_no());
preparedStatement.execute();
}
catch (Exception e){
e.printStackTrace();
}
}
}
The MyClickHouseUtil class inherits the RichSinkFunction class. Since the data flow type processed by the previous Flink operator is Mail type, the generic type of RichSinkFunction class is Mail type.
The next step is to override the open, close, and invoke methods. The key is the invoke method, which will be called once for each piece of data in sink. Therefore, the first parameter type of the invoke method is Mail, that is, the sink data flow type is required after processing by the Flink operator. Therefore, our main sink logic can be written here.
Firstly, an object of ClickHouseProperties is defined to save the parameters required to connect to the Clickhouse, such as user name and password. Next, use the properties and url to construct a DataSource connecting to the Clickhouse, and obtain the connection conn from the connection pool. Finally, the prepareStatement of JDBC is used to assign the placeholder in the written SQL. Call the execute method to execute SQL and insert the processed data stream into the Clickhouse.
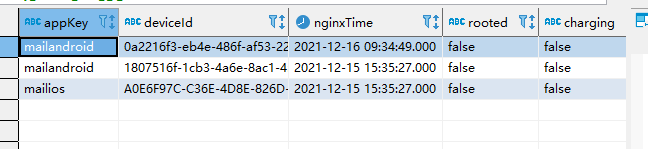
After running, check the data in the Clickhouse to find that the data has been written to the corresponding table in the Clickhouse.
Finally, POM Source code of XML and Mail classes:
pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>kafka_flink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.10</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.59</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.2</version>
</dependency>
<!-- Write data to clickhouse -->
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.1.54</version>
</dependency>
</dependencies>
</project>
The most important is the introduction of Ru yandex. Clickhouse, used to sink clickhouse
Mail class:
package com.demo.flink.pojo;
public class Mail {
private String appKey;
private String appVersion;
private String deviceId;
private String phone_no;
public Mail(String appKey, String appVersion, String deviceId, String phone_no) {
this.appKey = appKey;
this.appVersion = appVersion;
this.deviceId = deviceId;
this.phone_no = phone_no;
}
public String getAppKey() {
return appKey;
}
public void setAppKey(String appKey) {
this.appKey = appKey;
}
public String getAppVersion() {
return appVersion;
}
public void setAppVersion(String appVersion) {
this.appVersion = appVersion;
}
public String getDeviceId() {
return deviceId;
}
public void setDeviceId(String deviceId) {
this.deviceId = deviceId;
}
public String getPhone_no() {
return phone_no;
}
public void setPhone_no(String phone_no) {
this.phone_no = phone_no;
}
@Override
public String toString() {
return "Mail{" +
"appKey='" + appKey + '\'' +
", appVersion='" + appVersion + '\'' +
", deviceId='" + deviceId + '\'' +
", phone_no='" + phone_no + '\'' +
'}';
}
public Mail of(String appKey, String appVersion, String deviceId, String phone_no)
{
return new Mail(appKey, appVersion, deviceId, phone_no);
}
}
For some data to be extracted during data processing, we can make a Pojo class for storage, which is more convenient and clear, and the code level is more concise.