Overview
This paper uses datafaker tool to generate data and send it to MySQL flink cdc The tool sends mysql binlog data to kafka, and then reads the data from kafka and writes it to hudi Yes.
At the same time, queries are performed synchronously when data is written to hudi.
Component version and dependency
- datafaker 0.6.3
- mysql 5.7
- zookeeper 3.6.3
- kafka 2.8.0
- hadoop 3.2.0
- flink 1.12.2
- hudi 0.9.0
To complete the following, please ensure that mysql, zookeeper, kafka and hadoop are installed and started normally, and MySQL needs to start binlog.
The installation methods of relevant components can be directly searched according to keywords in the search box in the upper right corner.
This paper takes two hosts as the test, named hadoop and hadoop 1 respectively. The components installed on the host are as follows:
hadoop | hadoop1 |
|---|---|
Component name | Component name |
namenode | zookeeper |
datanode | kafka |
resourcemanager | |
nodemanager | |
mysql | |
flink |
Use datafaker to generate test data and send it to mysql
Create a stu3 table in the database
mysql -u root -p create database test; use test; create table stu3 ( id int unsigned auto_increment primary key COMMENT 'Self increasing id', name varchar(20) not null comment 'Student name', school varchar(20) not null comment 'School name', nickname varchar(20) not null comment 'Student nickname', age int not null comment 'Student age', class_num int not null comment 'Class size', phone bigint not null comment 'Telephone number', email varchar(64) comment 'Home network mailbox', ip varchar(32) comment 'IP address' ) engine=InnoDB default charset=utf8;Copy
New meta Txt file, the file content is:
id||int||Self increasing id[:inc(id,1)] name||varchar(20)||Student name school||varchar(20)||School name[:enum(qinghua,beida,shanghaijiaoda,fudan,xidian,zhongda)] nickname||varchar(20)||Student nickname[:enum(tom,tony,mick,rich,jasper)] age||int||Student age[:age] class_num||int||Class size[:int(10, 100)] phone||bigint||Telephone number[:phone_number] email||varchar(64)||Home network mailbox[:email] ip||varchar(32)||IP address[:ipv4]Copy
Generate 10000 pieces of data and write them to the test.xml in mysql Stu3 table
datafaker rdb mysql+mysqldb://root:Pass-123-root@hadoop:3306/test?charset=utf8 stu3 10000 --meta meta.txt Copy
Note: if you want to generate test data again, you need to change the 1 in the self increment id to a number greater than 10000, otherwise there will be a primary key conflict.
hudi, Flink MySQL CDC, and Flink Kafka related jar packages
Download the jar package to the lib directory of flink
cd flink-1.12.2/lib wget https://obs-githubhelper.obs.cn-east-3.myhuaweicloud.com/blog-images/category/bigdata/hudi/flink-sql-client-cdc-datalake/hudi-flink-bundle_2.12-0.9.0.jar wget https://obs-githubhelper.obs.cn-east-3.myhuaweicloud.com/blog-images/category/bigdata/hudi/flink-sql-client-cdc-datalake/flink-connector-kafka_2.12-1.12.2.jar wget https://obs-githubhelper.obs.cn-east-3.myhuaweicloud.com/blog-images/category/bigdata/hudi/flink-sql-client-cdc-datalake/flink-sql-connector-mysql-cdc-1.2.0.jar Copy
Note: the above Hudi flex bundle_ 2.12-0.9.0. Jar has fixed the official bug that the default configuration item cannot be loaded. It is recommended to use the jar package provided above.
If you encounter the problem of missing some classes during starting and running the flick task, please download the relevant jar package and place it in the directory of flick-1.12.2/lib. The missing packages encountered during the operation of this experiment are as follows (click to download):
- commons-logging-1.2.jar
- htrace-core-3.1.0-incubating.jar
- htrace-core4-4.1.0-incubating.jar
- hadoop-mapreduce-client-core-3.2.0.jar
Start the flink session cluster on yarn
First, make sure Hadoop is configured_ Classpath, for the open source version Hadoop 3 2.0, which can be set as follows:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/client/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/tools/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/etc/hadoop/*Copy
Check point needs to be opened for flick, and the configuration file of flick-conf.yaml needs to be modified
execution.checkpointing.interval: 150000ms state.backend: rocksdb state.checkpoints.dir: hdfs://hadoop:9000/flink-chk state.backend.rocksdb.localdir: /tmp/rocksdbCopy
Start the flink session cluster
cd flink-1.12.2 bin/yarn-session.sh -s 4 -jm 2048 -tm 2048 -nm flink-hudi-test -d Copy
You can see the application launched on yarn

Click the application master on the right to enter the flynk management page
Start the flynk SQL client
cd flink-1.12.2 bin/sql-client.sh embedded -s yarn-session -j ./lib/hudi-flink-bundle_2.12-0.9.0.jar shell Copy
Enter the following flink SQL client

flink reads mysql binlog and writes it to kafka
We build a real-time task through the flick SQL client to write the mysql binlog log to kafka in real time:
Create mysql source table
create table stu3_binlog( id bigint not null, name string, school string, nickname string, age int not null, class_num int not null, phone bigint not null, email string, ip string ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'hadoop', 'port' = '3306', 'username' = 'root', 'password' = 'Pass-123-root', 'database-name' = 'test', 'table-name' = 'stu3' );Copy
The attributes in with() are mysql connection information.
Create kafka target table
create table stu3_binlog_sink_kafka( id bigint not null, name string, school string, nickname string, age int not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) with ( 'connector' = 'kafka' ,'topic' = 'cdc_mysql_stu3_sink' ,'properties.zookeeper.connect' = 'hadoop1:2181' ,'properties.bootstrap.servers' = 'hadoop1:9092' ,'format' = 'debezium-json' );Copy
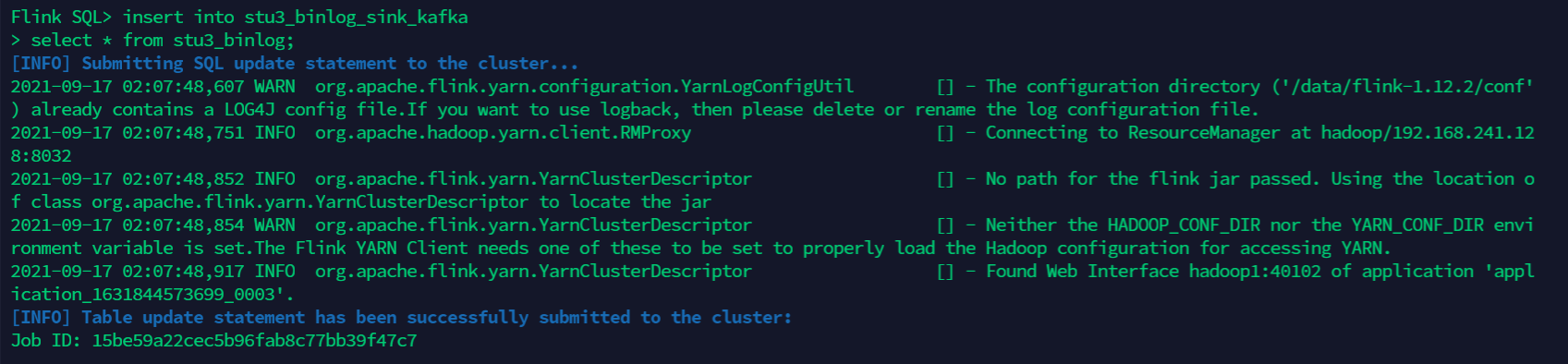
Create a task to write mysql binlog log to kafka
insert into stu3_binlog_sink_kafka select * from stu3_binlog;Copy
Task submission information can be seen:
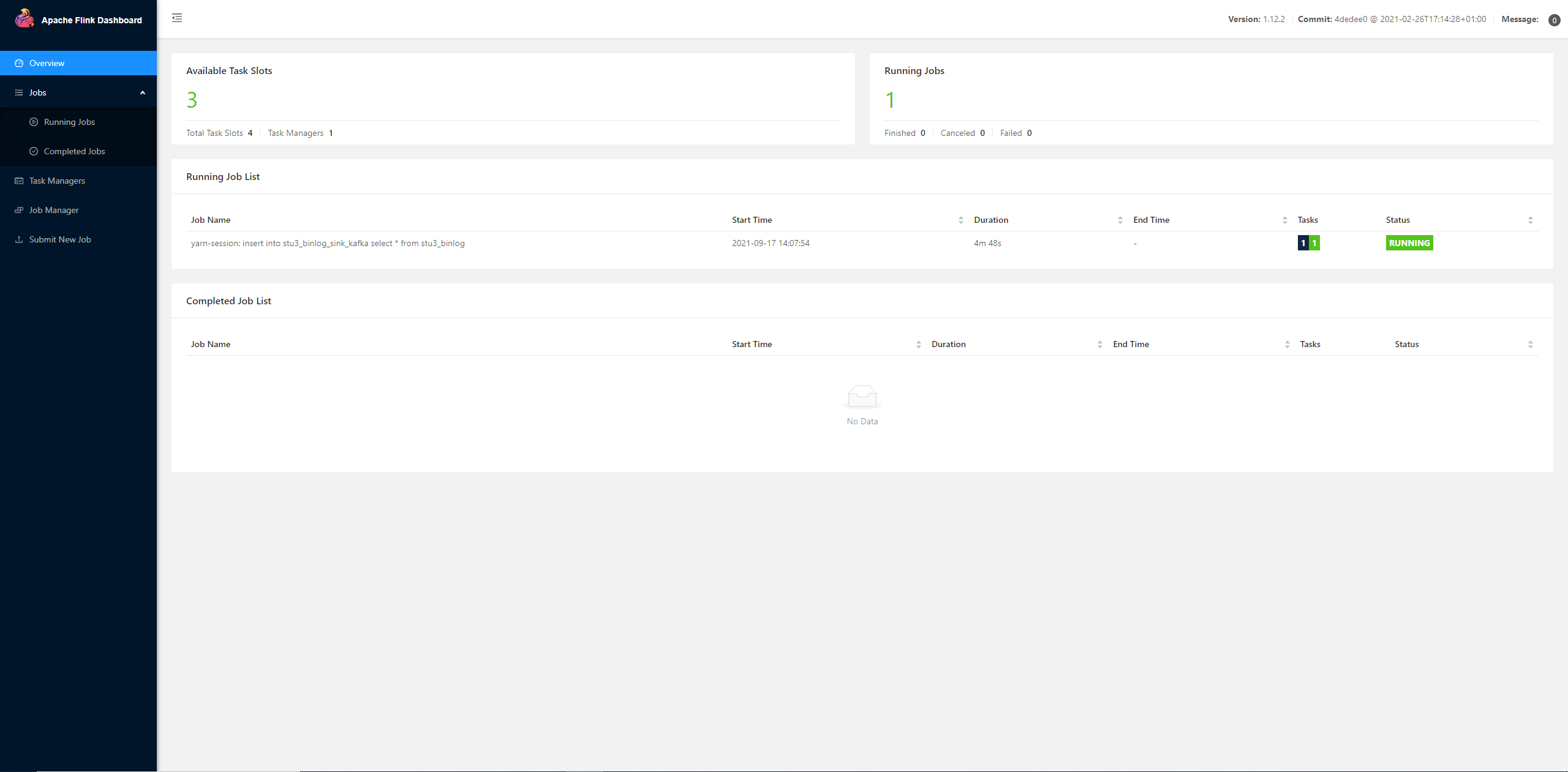
Relevant task information can also be seen on the flynk management page:
Flynk reads kafka data and writes hudi data
Create kafka source table
create table stu3_binlog_source_kafka( id bigint not null, name string, school string, nickname string, age int not null, class_num int not null, phone bigint not null, email string, ip string ) with ( 'connector' = 'kafka', 'topic' = 'cdc_mysql_stu3_sink', 'properties.bootstrap.servers' = 'hadoop1:9092', 'format' = 'debezium-json', 'scan.startup.mode' = 'earliest-offset', 'properties.group.id' = 'testGroup' );Copy
Create hudi target table
create table stu3_binlog_sink_hudi( id bigint not null, name string, `school` string, nickname string, age int not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) partitioned by (`school`) with ( 'connector' = 'hudi', 'path' = 'hdfs://hadoop:9000/tmp/stu3_binlog_sink_hudi', 'table.type' = 'MERGE_ON_READ', 'write.option' = 'insert', 'write.precombine.field' = 'school' );Copy
Create a task to write kafka data to hudi
insert into stu3_binlog_sink_hudi select * from stu3_binlog_source_kafka;Copy
You can see the task submission information:

Relevant task information can also be seen on the flynk management page:
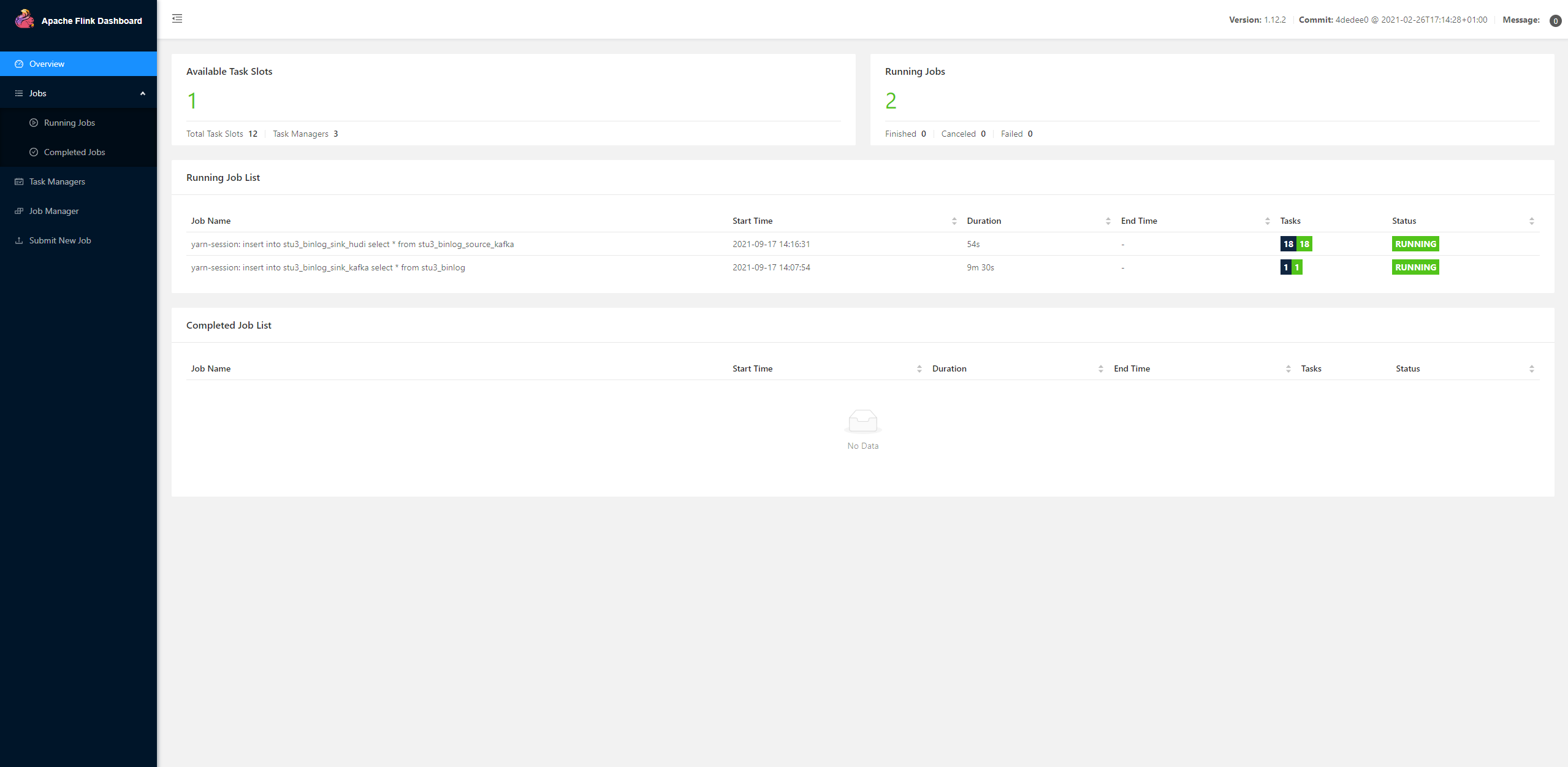
View data consumption through Flink UI
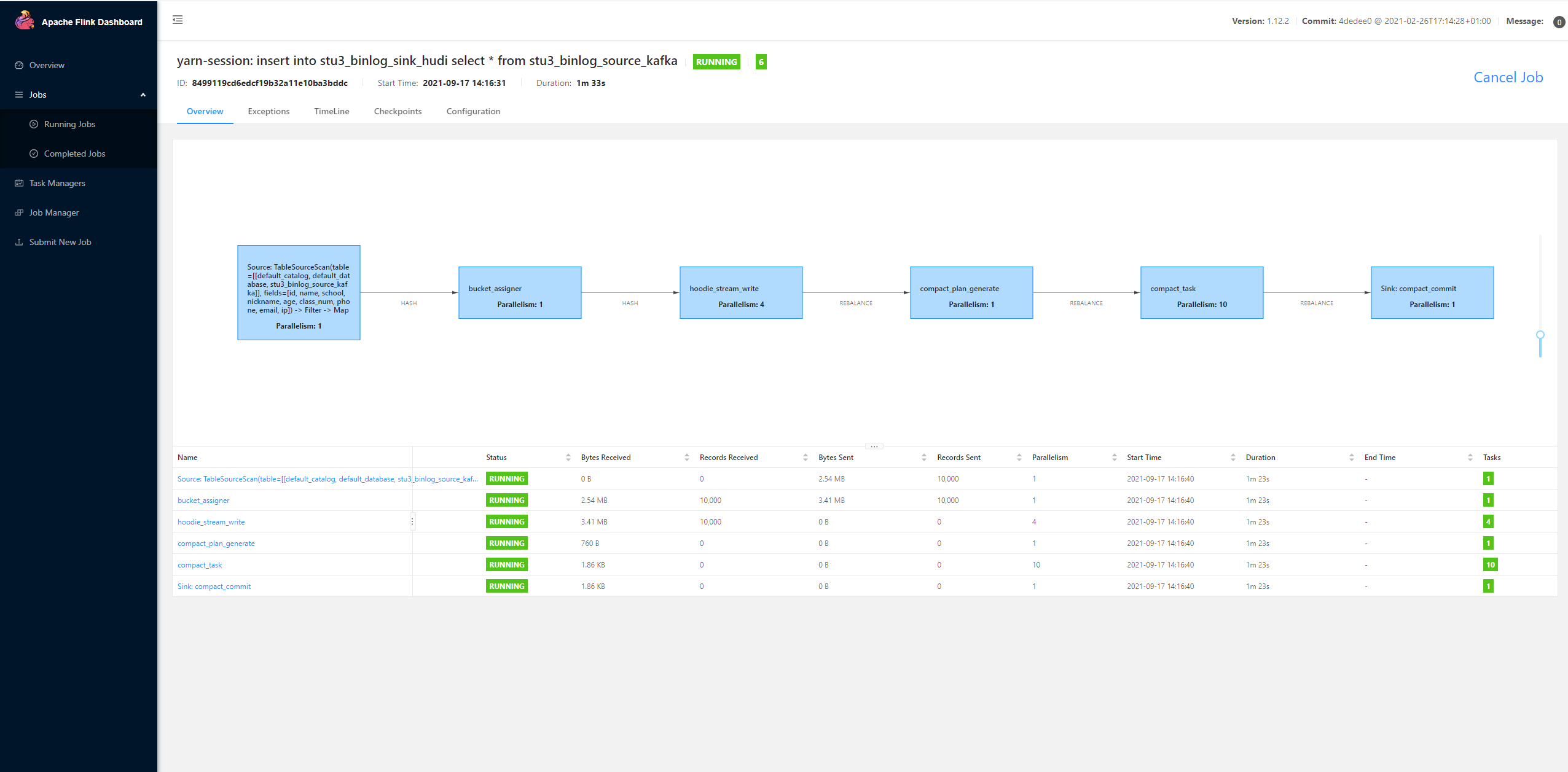
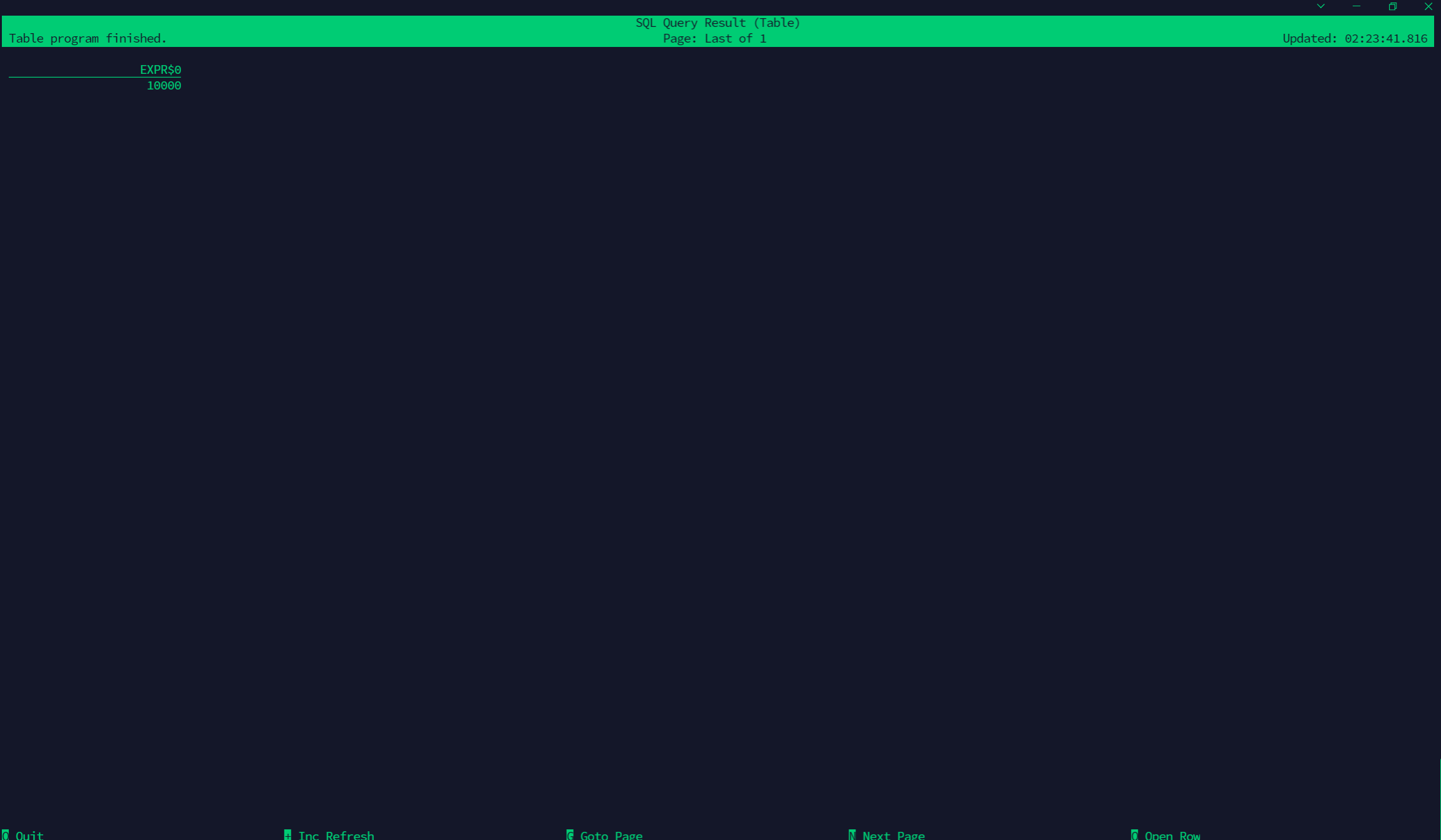
Statistics into hudi
create table stu3_binlog_hudi_view( id bigint not null, name string, school string, nickname string, age int not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) partitioned by (`school`) with ( 'connector' = 'hudi', 'path' = 'hdfs://hadoop:9000/tmp/stu3_binlog_sink_hudi', 'table.type' = 'MERGE_ON_READ', 'write.precombine.field' = 'school' ); select count(*) from stu3_binlog_hudi_view; Copy
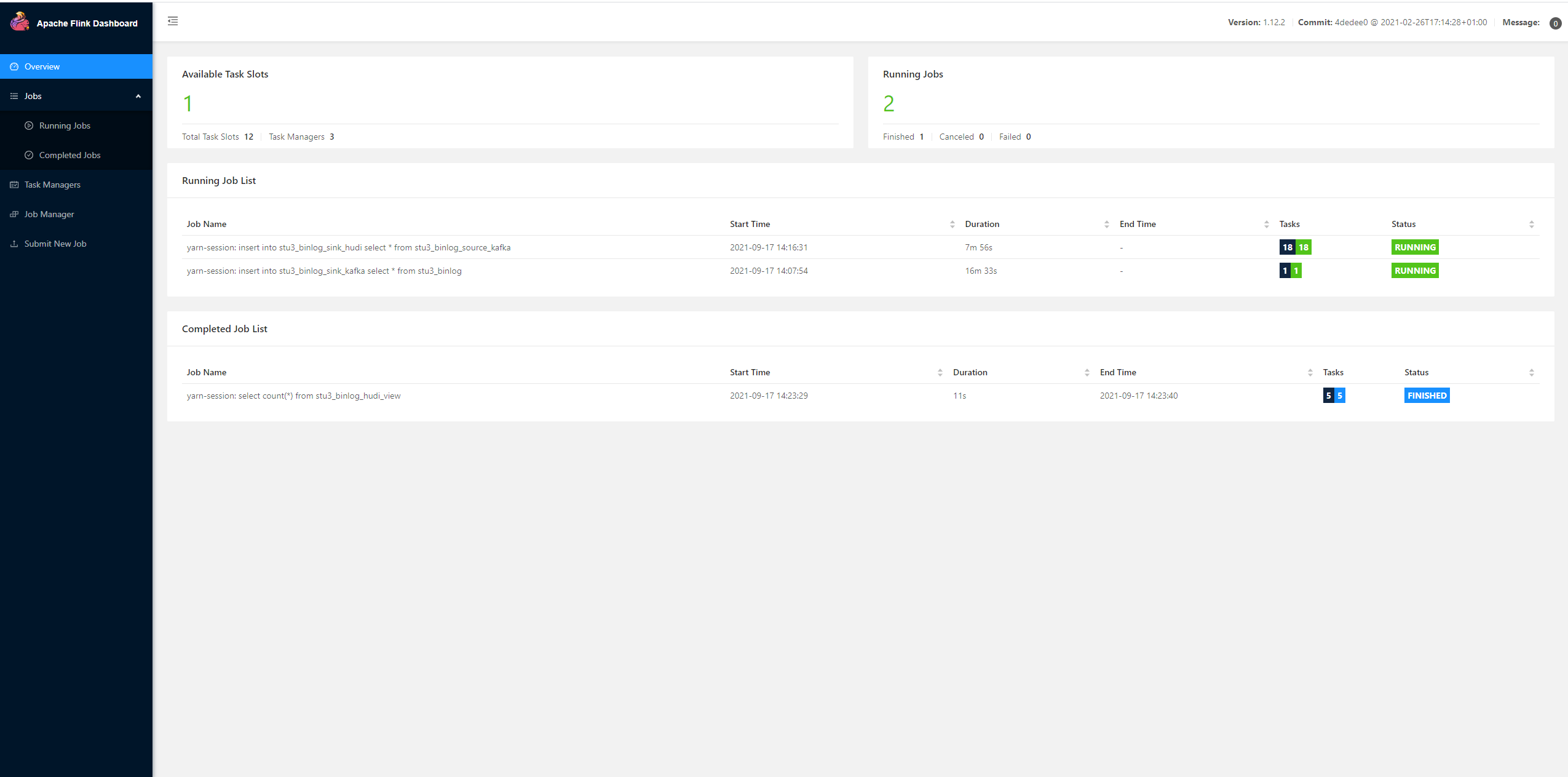
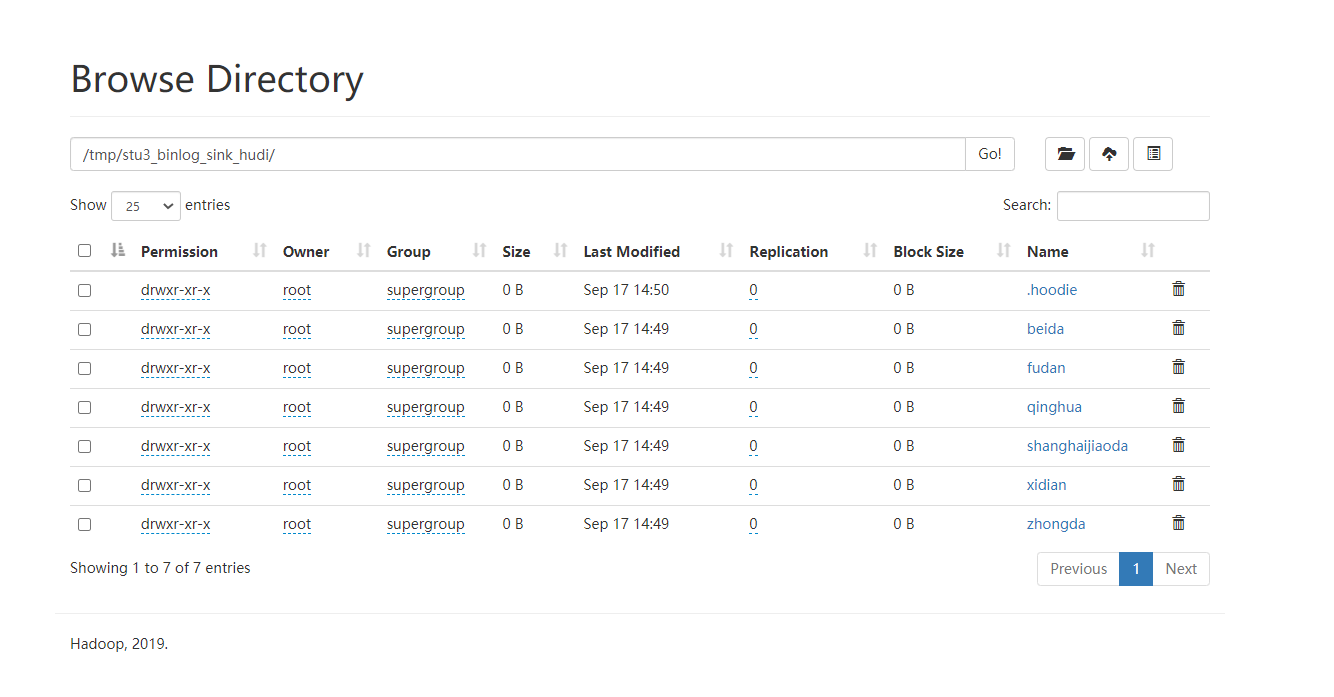
hdfs viewing hudi data
View the data entering the lake in real time
Next, we use datafaker to generate the test data again.
Modify meta Txt is
id||int||Self increasing id[:inc(id,10001)] name||varchar(20)||Student name school||varchar(20)||School name[:enum(qinghua,beida,shanghaijiaoda,fudan,xidian,zhongda)] nickname||varchar(20)||Student nickname[:enum(tom,tony,mick,rich,jasper)] age||int||Student age[:age] class_num||int||Class size[:int(10, 100)] phone||bigint||Telephone number[:phone_number] email||varchar(64)||Home network mailbox[:email] ip||varchar(32)||IP address[:ipv4]Copy
Generate 100000 pieces of data
datafaker rdb mysql+mysqldb://root:Pass-123-root@hadoop:3306/test?charset=utf8 stu3 100000 --meta meta.txt Copy
Real time viewing of data entering the lake
create table stu3_binlog_hudi_streaming_view( id bigint not null, name string, school string, nickname string, age int not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) partitioned by (`school`) with ( 'connector' = 'hudi', 'path' = 'hdfs://hadoop:9000/tmp/stu3_binlog_sink_hudi', 'table.type' = 'MERGE_ON_READ', 'write.precombine.field' = 'school', 'read.streaming.enabled' = 'true' ); select * from stu3_binlog_hudi_streaming_view;Copy
This article is the original article of "xiaozhch5", a blogger from big data to artificial intelligence. It follows the CC 4.0 BY-SA copyright agreement. Please attach the original source link and this statement for reprint.
Original link: https://lrting.top/backend/2049/