State:
State refers to the intermediate calculation result or metadata attribute of the calculation node in the process of flow calculation. For example, in the process of aggregation, the intermediate aggregation result should be recorded in the state. For example, when Apache Kafka is the data source, we should also record the offset of the read record. These state data will be persisted (inserted or updated) in the calculation process. So the state in Apache Flink is a time-dependent snapshot of the internal data (calculated data and metadata properties) of the Apache Flink task.
State classification: Keyed State and Operator State
Keyed State
Keyed State is based on key. It is always bound with key. The state between key and key has no relationship and will not affect each other
Operator State
Operator state is based on operator. Each operation has a state, and each operation will not affect each other. For example, Kafka Connector in Flink uses operator state. It will save all the (partition, offset) mappings of consuming topic in each connector instance.
Raw State and Managed State
- Raw is the original state: the user manages the specific data structure of the state by himself. When the framework is doing checkpoint, it uses byte [] to read and write the state content, and knows nothing about its internal data structure.
- Managed State: the Managed State, which is managed by the Flink framework, such as ValueState, ListState, MapState, etc.
Keyed State ---- Managed State
- ValueState: this keeps a value that can be updated and retrieved (as mentioned above, the scope is the key of the input element, so each key seen by the operation may have a value). The value can be set to update(T) and retrieved using T value().
Example:
package flinkscala.State.Keyed_State import org.apache.flink.api.common.functions.RichFlatMapFunction import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.api.common.typeinfo.TypeInformation import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala._ import org.apache.flink.util.Collector object valueStateTest { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.fromCollection(List( (1L, 3L), (1L, 5L), (1L, 7L), (1L, 4L), (1L, 2L), (1L, 6L), (1L, 2L), (1L, 9L), (1L, 2L), (1L, 3L) )).keyBy(_._1) .flatMap(new CountWindowAverage()) .print() env.execute("average Test") } } class CountWindowAverage extends RichFlatMapFunction[(Long,Long),(Long,Long)]{ //Define a ValueState that holds (number of elements, sum of elements) private var sum: ValueState[(Long,Long)] = _ override def flatMap(value: (Long, Long), out: Collector[(Long, Long)]): Unit = { //Access the ValueState first, and extract the sum in the ValueState //Of course, if it is empty, i.e. for the first time, it is initialized to 0, 0 var tmpCurrentSum = sum.value() val surrentSum = if(tmpCurrentSum !=null){ tmpCurrentSum }else {(0L,0L)} /* * Number of elements + 1, elements and + elements currently in * */ val newSum = (surrentSum._1+1,surrentSum._2+value._2) //Update State sum.update(newSum) //If two elements are reached, the average is calculated once if(newSum._1>=2){ out.collect((value._1,newSum._2/newSum._1)) sum.clear()//Emptying state } } override def open(parameters: Configuration): Unit ={ sum = getRuntimeContext .getState( new ValueStateDescriptor[(Long, Long)]("average",createTypeInformation[(Long,Long)]) ) } }
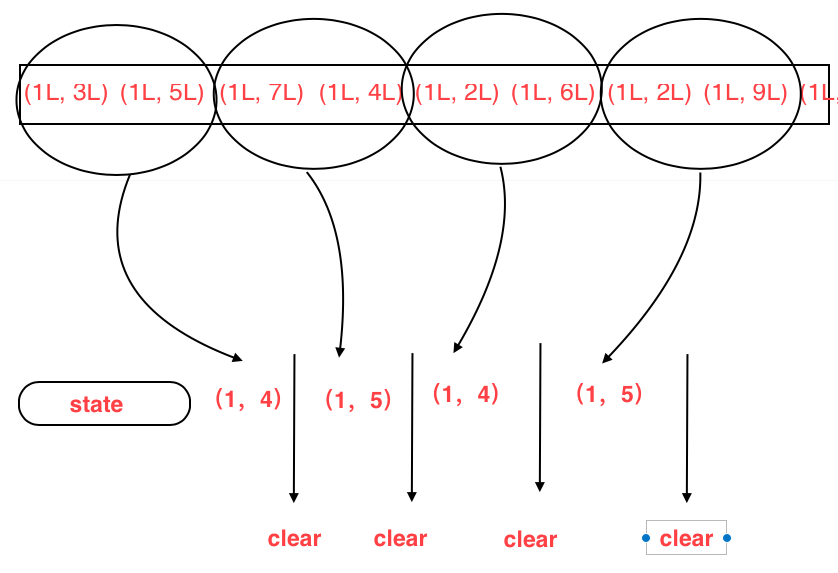
ListState: this keeps the list of elements. You can append elements and retrieve all currently stored elements of Iterable. Using add(T) or add element addAll(List), you can use to retrieve Iterable Iterable get(). You can also override the existing list update(List) using the following methods
ReducingState: This preserves a value that represents a collection of all values added to the state. The interface is similar to ListState, but using the new element add(T) will use the specified simplification to summarize ReduceFunction.
Aggregatingstate < in, out >: This preserves a value that represents a collection of all values added to the state. In contrast to ReducingState, the aggregation type may be different from the type of the element added to the state. The interface is the same as for, ListState but with the added element add(IN) is an AggregateFunction with the specified aggregation.
Foldingstate < T, ACC >: This preserves a value that represents a collection of all values added to the state. In contrast to ReducingState, the aggregation type may be different from the type of the element added to the state. This interface is similar to ListState but uses the added element add(T) to collapse to a collection FoldFunction using the specified. Deprecated in 1.4 and replaced with AggregatingState
Mapstate < UK, UV >: this keeps a list of mappings. You can put key value pairs in state and retrieve all currently stored mappings for Iterable. Use put(UK, UV) or add map putall (map < UK, UV >). You can use to retrieve the value get(UK) associated with the user key. For mapping, key and value iteratable views can use retrieved entries(), keys(), and values() respectively. You can also use isEmpty() to check if this mapping contains any key value mappings.
We can get the state through the getstate method of getRunTimeContext. A state is bound to a handle StateDescriptor. Different states hold different values. In this case, multiple states may be needed. The corresponding state can be obtained through StateDescriptor.
State Time-To-Live (TTL)
For a state, we can sometimes set its age, or expire, that is, it will automatically clear when it reaches a certain time, or do related operations, which is a bit like the expiration in Redis.
import org.apache.flink.api.common.state.StateTtlConfig import org.apache.flink.api.common.state.ValueStateDescriptor import org.apache.flink.api.common.time.Time val ttlConfig = StateTtlConfig //This is used to configure the expiration time for survival .newBuilder(Time.seconds(1)) //Configure when to refresh the status TTL: OnCreateAndWrite - only when creating and writing access, OnReadAndWrite - when there is read access .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) //Configure state visibility to configure whether to clear default values that have not expired( .setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) .build val stateDescriptor = new ValueStateDescriptor[String]("text state", classOf[String]) stateDescriptor.enableTimeToLive(ttlConfig)
Clean up expiration status
val ttlConfig = StateTtlConfig .newBuilder(Time.seconds(1)) .disableCleanupInBackground//Prevent background state from being cleaned up .build
Managed Operator State
As mentioned earlier, the operation state is based on the operator, and then managed, i.e. using the value state that Flink already has, etc
To use managed operation state, stateful function can realize more general CheckpointedFunction interface, or listchecked < T extensions serializable > interface.
CheckpointedFunction
Whenever a checkpoint has to be executed, snapshot state() is called. The corresponding initializeState() is called each time a user-defined function is initialized void snapshotState(FunctionSnapshotContext context) throws Exception; void initializeState(FunctionInitializationContext context) throws Exception; Whether it's when the function is initialized for the first time or when it's actually recovered from a previous checkpoint. Therefore, initializeState() is not only the place to initialize different types of States, but also the place to contain state recovery logic.
Currently, List style managed operator states are supported. The state should be a serializable object of a List independent of each other,
- Ever split distribution: each operator returns a list of status elements. The entire state is logically a concatenation of all lists. When restoring / redistributing, the list is evenly divided into as many child lists as possible because there are parallel operators. Each operator gets a sublist that can be empty or contain one or more elements. For example, if the checkpoint state of the operator contains elements element1 and element2 when the parallelism is 1, element1 may end in operator instance 0 when the parallelism is increased to 2, and element2 will go to operator instance 1.
- Union reduction: each operator returns a list of status elements. Logically, the entire state is a concatenation of all lists. At restore / redistribute, each operator gets a complete list of state elements.
Ever split distribution demonstration
package flinkscala.State.Operatior_State import org.apache.flink.api.common.state.{ListState, ListStateDescriptor} import org.apache.flink.api.common.typeinfo.{TypeHint, TypeInformation} import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext} import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction import org.apache.flink.streaming.api.functions.sink.SinkFunction import scala.collection.mutable.ListBuffer object opratorTest { def main(args: Array[String]): Unit = { } } class BufferingSink(threshold: Int = 0) extends SinkFunction[(String,Int)] with CheckpointedFunction{ private var checkpointedState: ListState[(String,Int)] = _ private val bufferedElements = ListBuffer[(String,Int)]() override def invoke(value: (_root_.scala.Predef.String, Int), context: _root_.org.apache.flink.streaming.api.functions.sink.SinkFunction.Context[_]): Unit = { bufferedElements += value if(bufferedElements.size == threshold){ for(element <- bufferedElements){ //Send it here to Sink } //Empty after sending bufferedElements.clear() } } override def snapshotState(context: FunctionSnapshotContext): Unit = { checkpointedState.clear() for (element <- bufferedElements) { checkpointedState.add(element) } } override def initializeState(context: FunctionInitializationContext): Unit = { val descriptor = new ListStateDescriptor[(String,Int)]( "buffered-elements", TypeInformation.of(new TypeHint[(String,Int)] {}) ) checkpointedState = context.getOperatorStateStore.getListState(descriptor) if(context.isRestored){ for(element <- checkpointedState.get()){ bufferedElements += element } } } }
ListCheckpointed
The ListCheckpointed interface is a more limited variant of CheckpointedFunction, which only supports list style States and uses even split reallocation schemes when restoring. It also needs to implement two methods:
List<T> snapshotState(long checkpointId, long timestamp) throws Exception; void restoreState(List<T> state) throws Exception;
A list of objects should be returned to the checkpoint on the snapshot state() operator, and restoreState must process such a list when recovering. If the state is not repartitioned, you can return the snapshot state () of Collections.singletonList(MY_STATE) at any time.

