01 introduction
In the previous blog, we have a certain understanding of the use of Source in Flink's program model. Interested students can refer to the following:
- Flink tutorial (01) - Flink knowledge map
- Flink tutorial (02) - getting started with Flink
- Flink tutorial (03) - Flink environment construction
- Flink tutorial (04) - getting started with Flink
- Flink tutorial (05) - simple analysis of Flink principle
- Flink tutorial (06) - Flink batch streaming API (Source example)
This article continues to explain the Transformation of Flink program model.
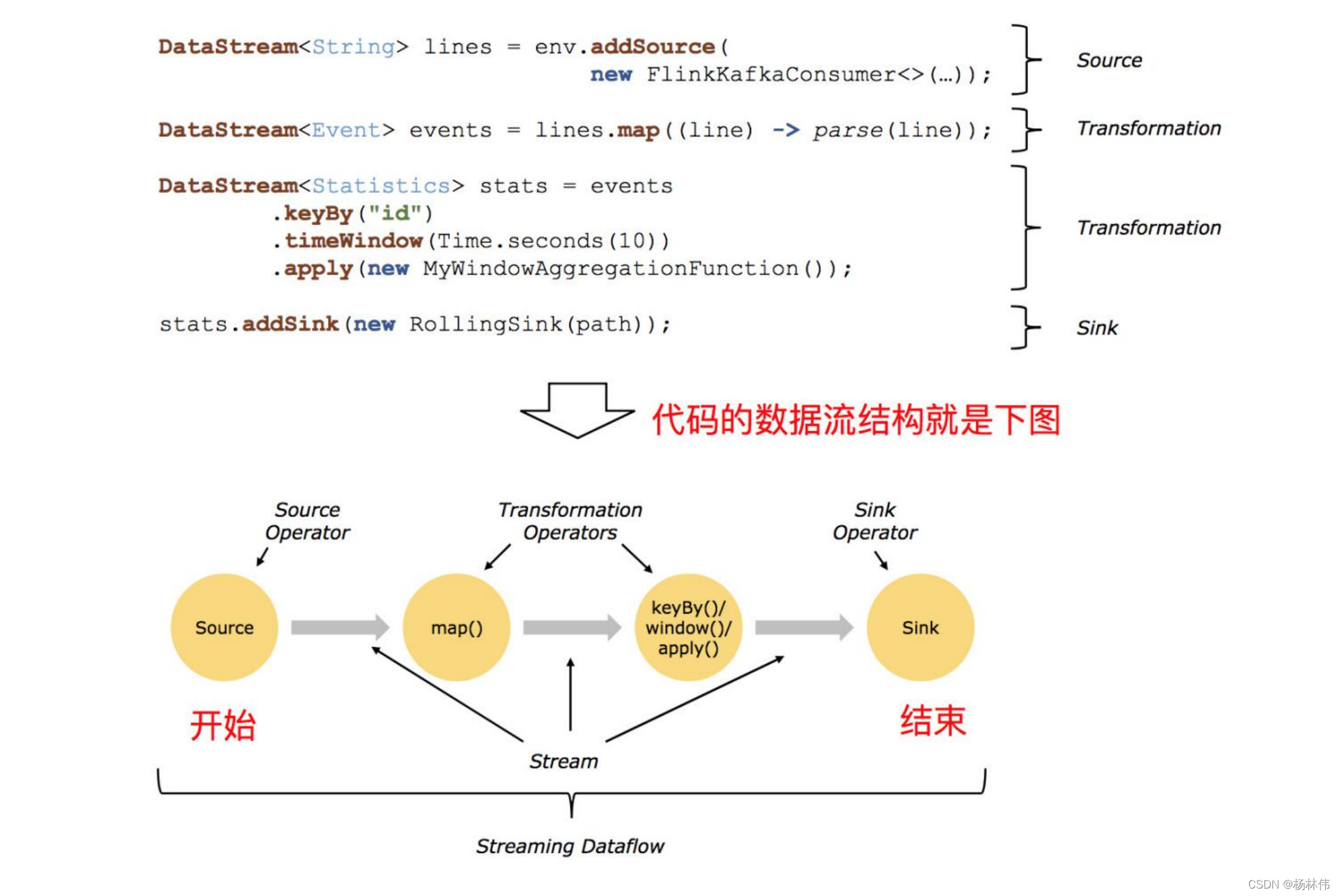
02 Transformation
The official API document of Transformation is in: https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/
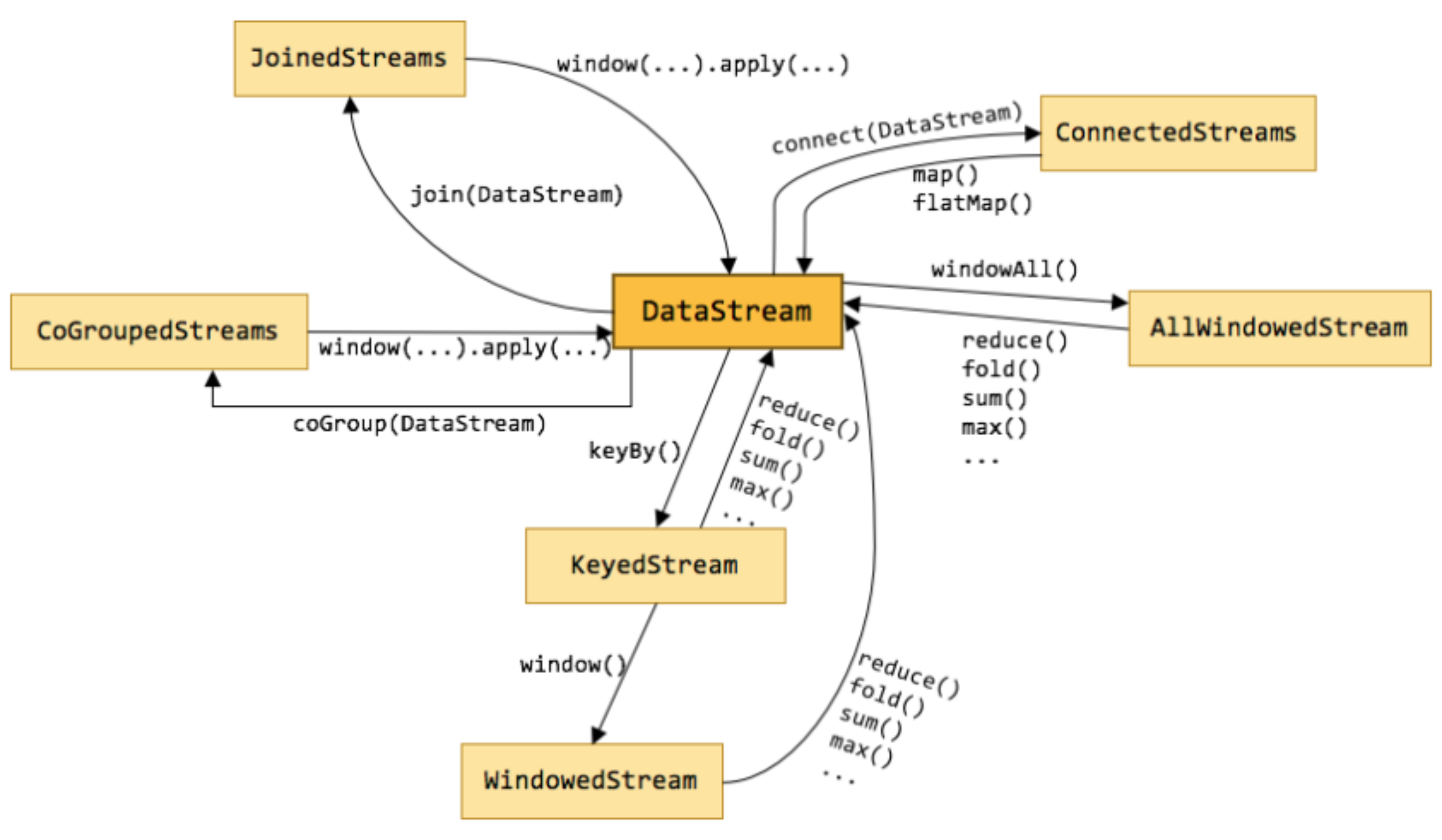
The operation overview is shown in the figure below:
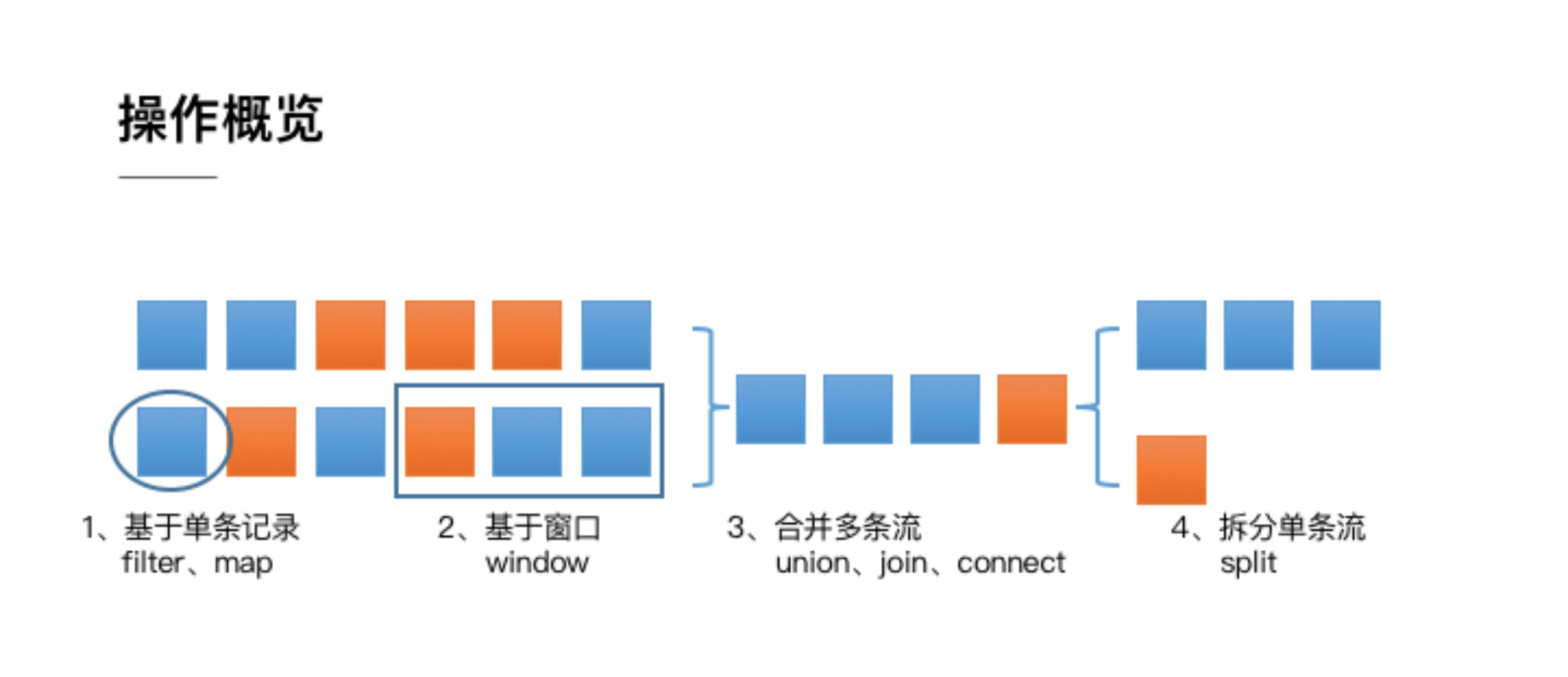
Generally speaking, operations on streaming data can be divided into four categories:
- The first type is "operation for a single record": for example, Filter out unqualified records (Filter operation), or make a conversion for each record (Map operation);
- The second type is "operation on multiple records": for example, to count the total order turnover within an hour, you need to add the turnover of all order records within an hour. In order to support this type of operation, you have to associate the required records through Window for processing;
- The third type is "operate on multiple streams and convert them into a single stream": for example, multiple streams can be combined through Union, Join, Connect and other operations. The merging logic of these operations is different, but they will eventually produce a new unified stream, so that some cross stream operations can be carried out;
- The fourth category is "DataStream also supports Split operations symmetrical to merging": that is, Split a stream into multiple streams according to certain rules (Split operation), and each stream is a subset of the previous stream, so that we can deal with different streams differently.
2.1 basic operation
2.1.1 API analysis
| classification | describe | Sketch Map |
|---|---|---|
| map | The function acts on each element in the collection and returns the result after the action | 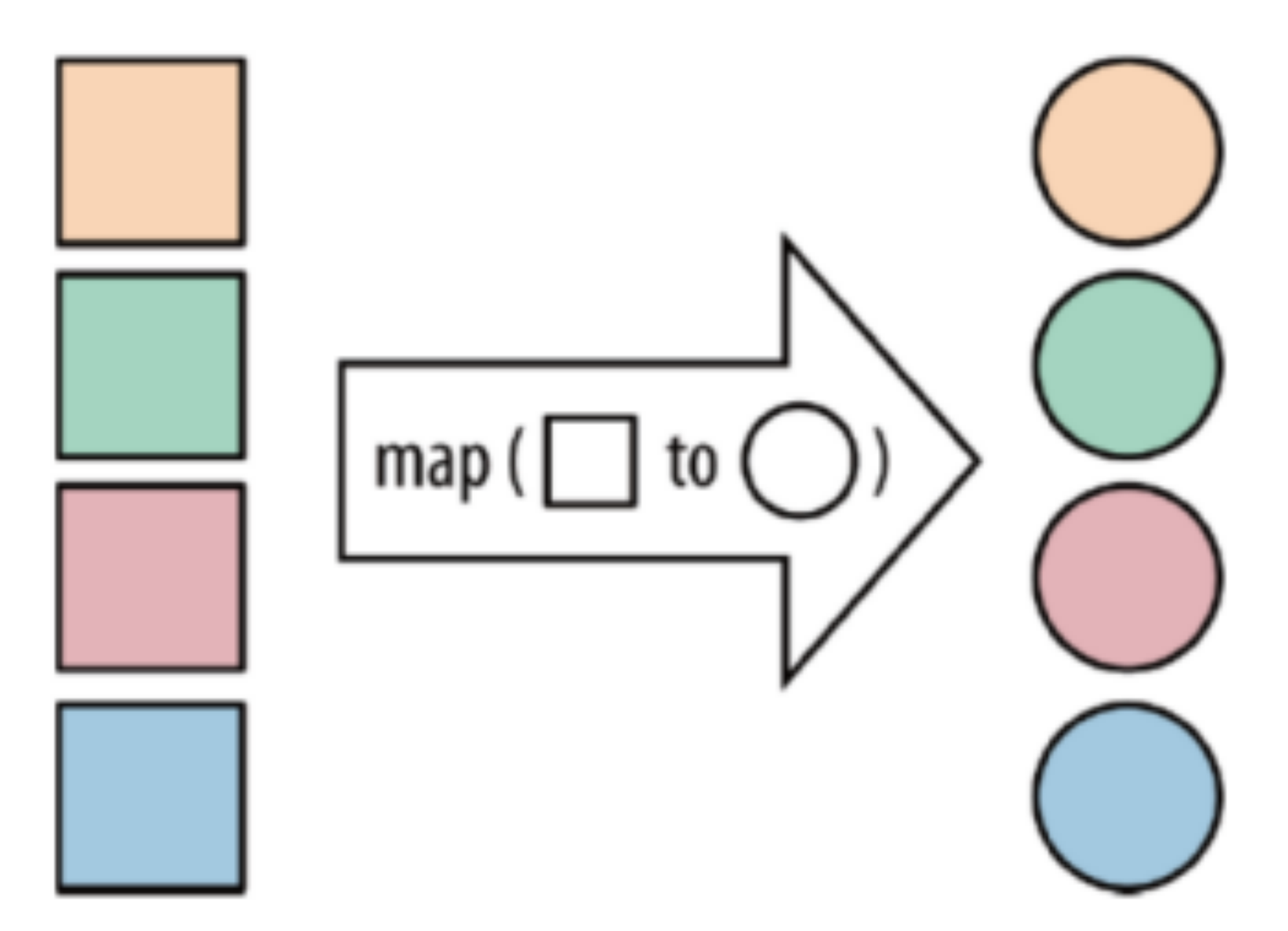 |
| flatMap | Each element in the collection becomes one or more elements and returns the flattened result | 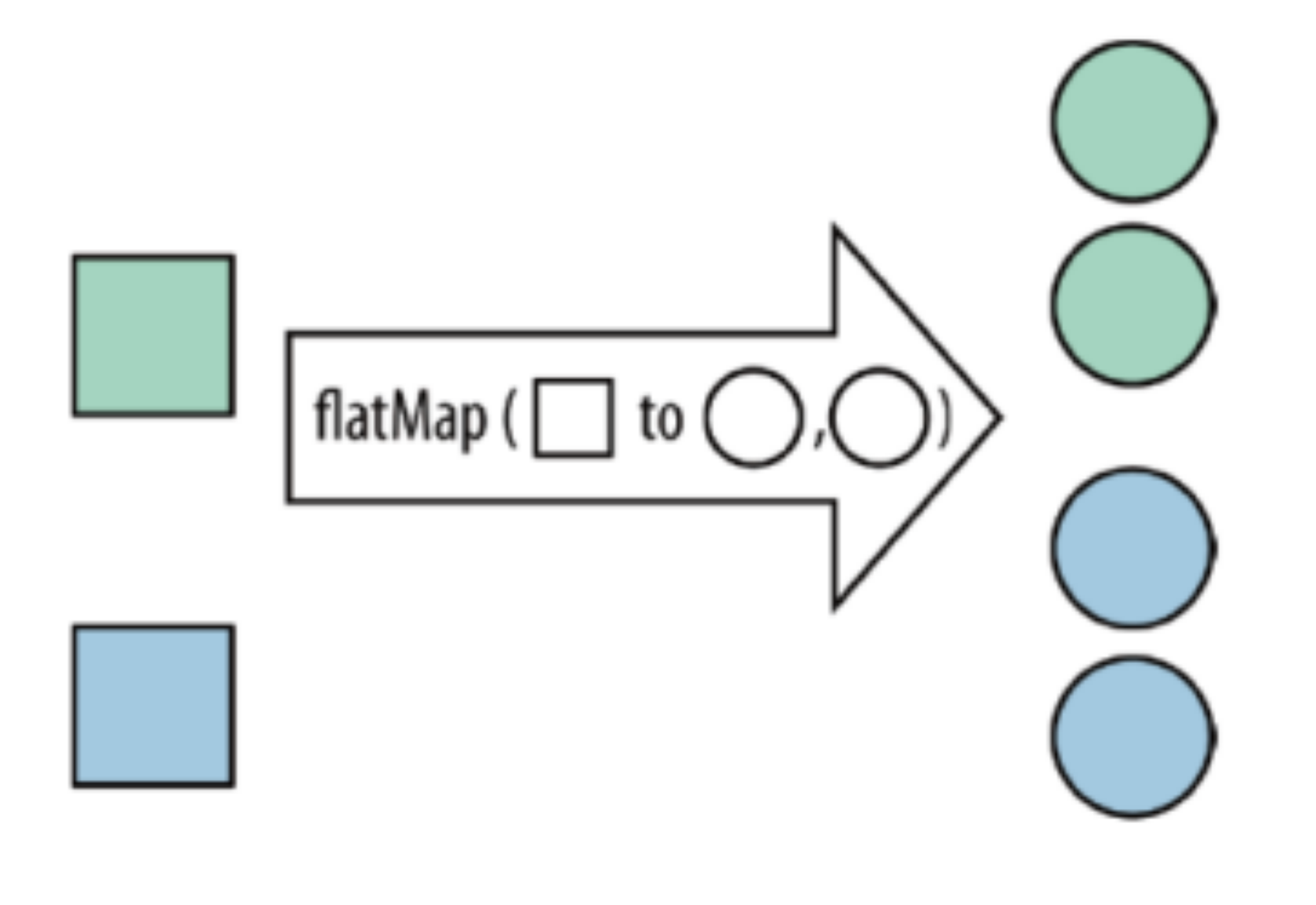 |
| keyBy | Group the data in the stream according to the specified key, as demonstrated in the previous introductory case (Note: there is no groupBy in stream processing, but keyBy) | 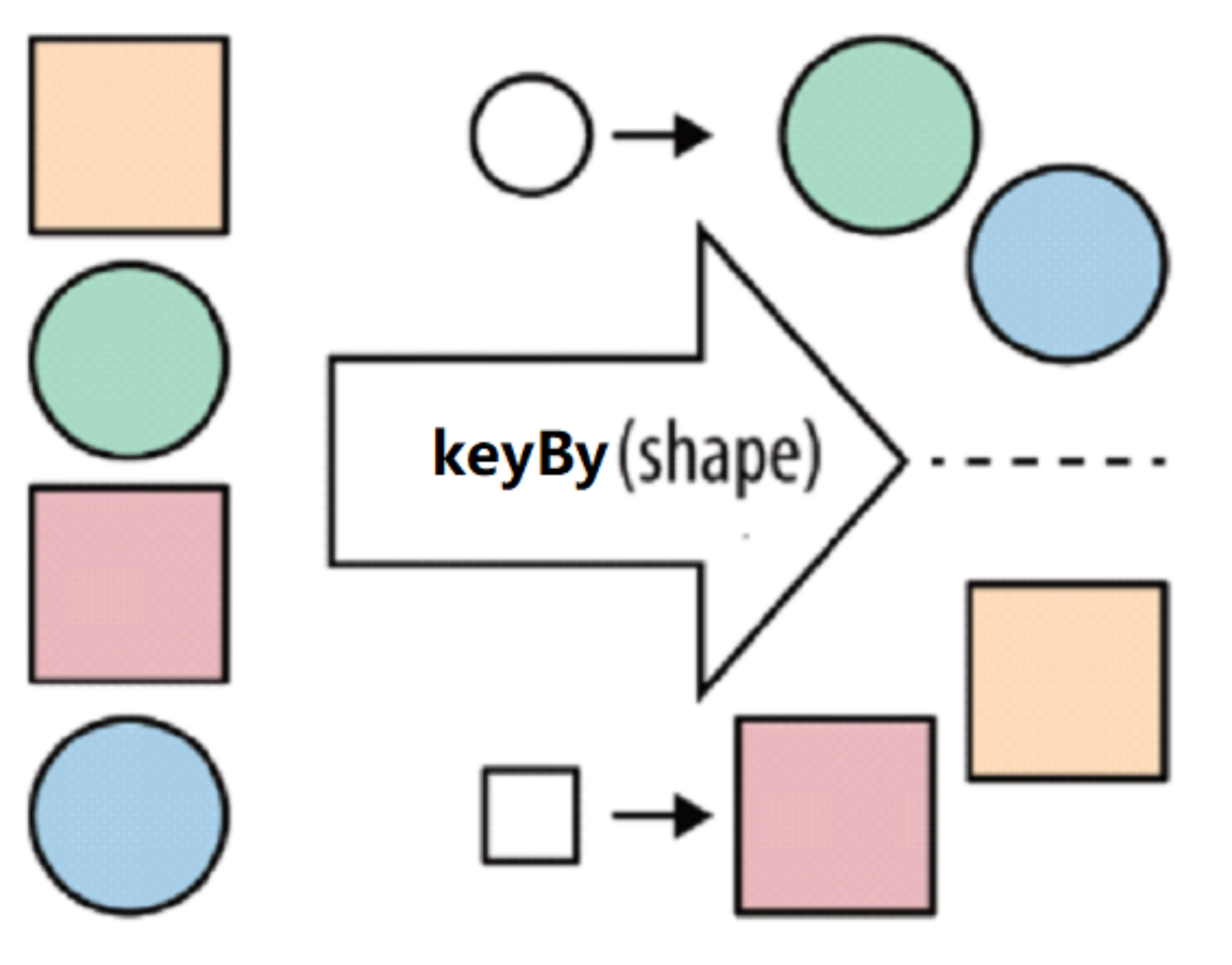 |
| filter | Filter the elements in the collection according to the specified conditions, and filter out the elements that return true / meet the conditions | 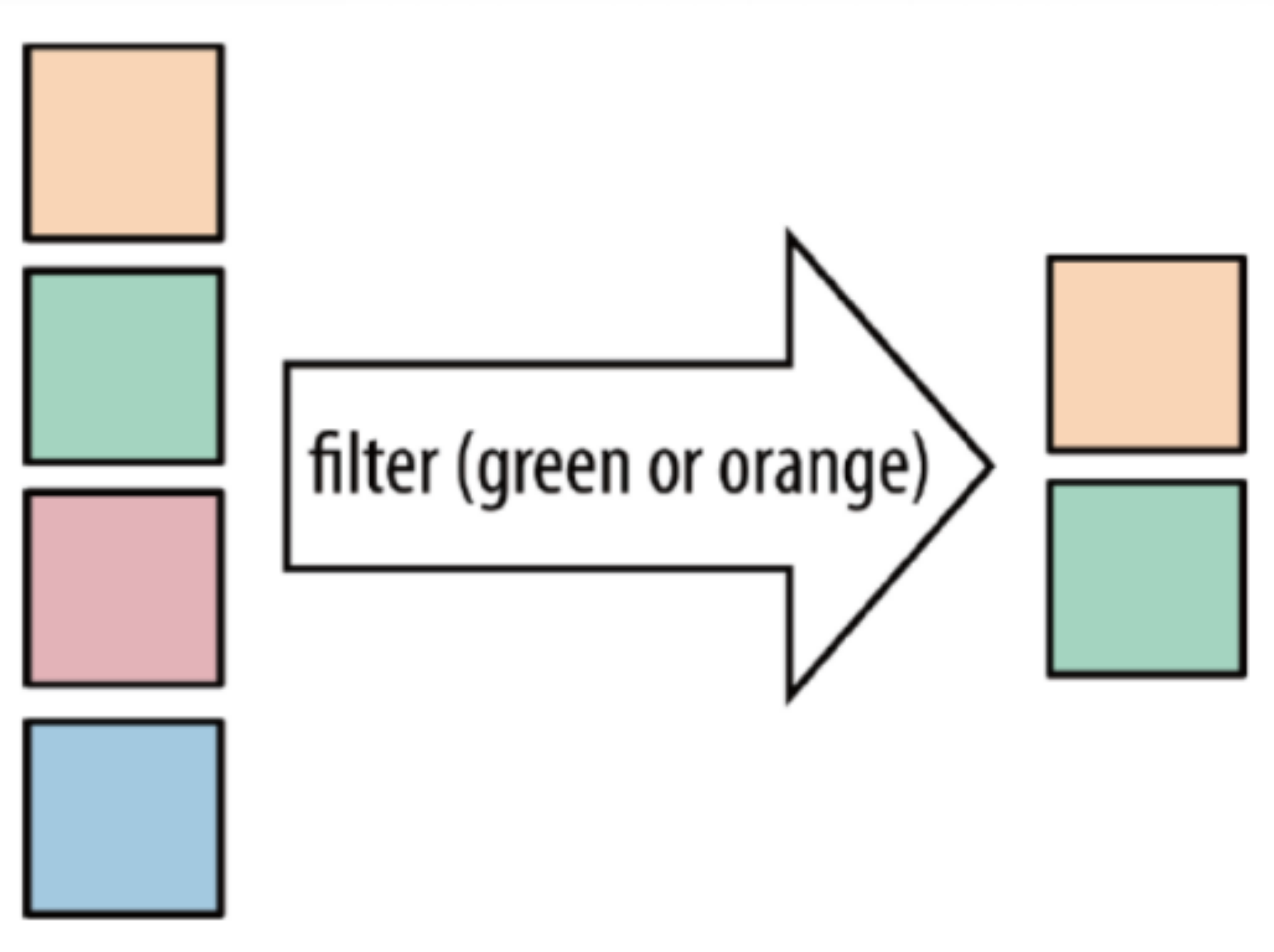 |
| sum | Sums the elements in the collection according to the specified fields | nothing |
| reduce | Aggregate elements in a collection | 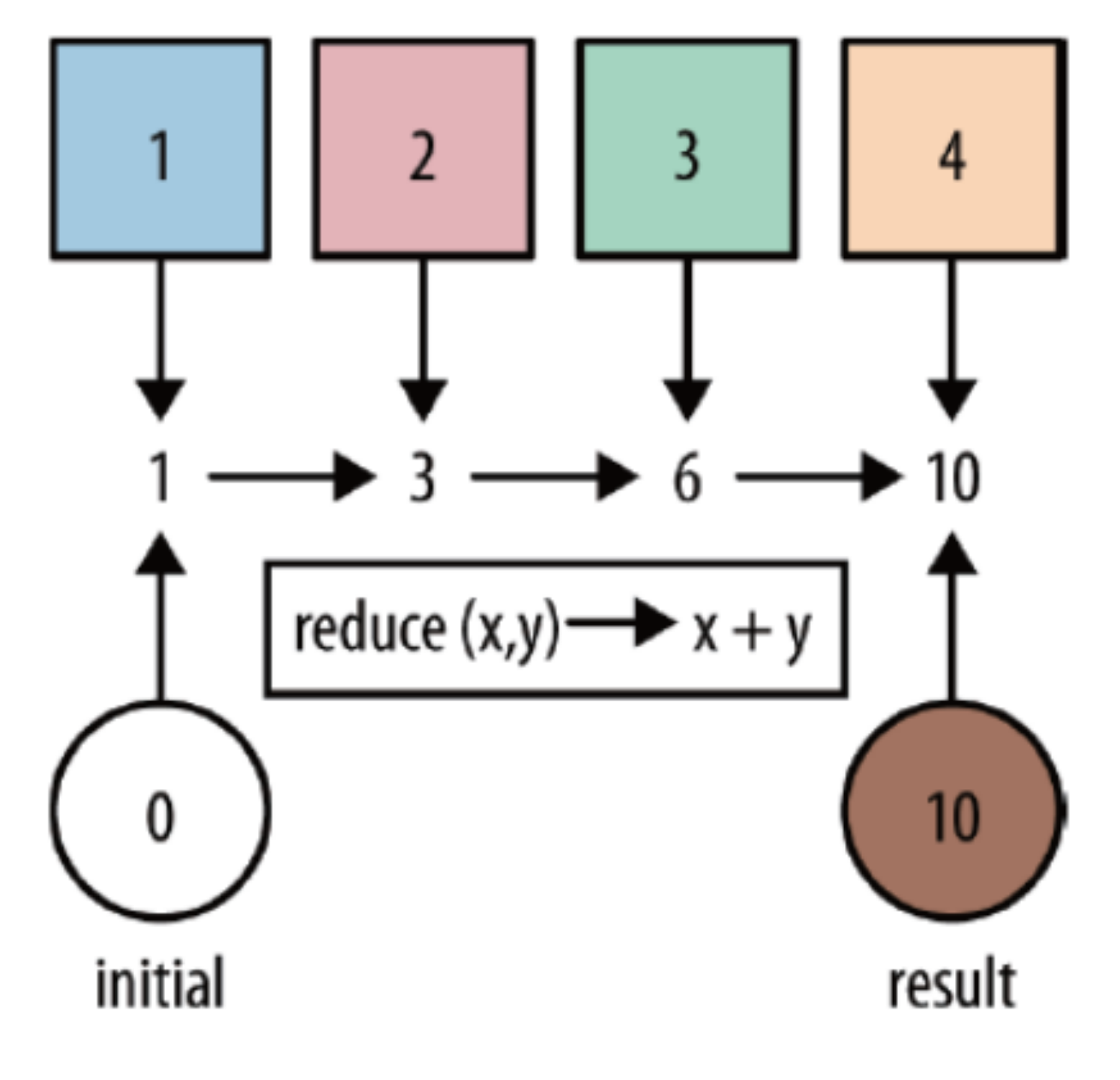 |
2.1.2 example code
The example code is as follows:
/**
* Transformation-basic operation
*
* @author : YangLinWei
* @createTime: 2022/3/7 3:36 afternoon
*/
public class TransformationDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
DataStream<String> linesDS = env.fromElements("ylw hadoop spark", "ylw hadoop spark", "ylw hadoop", "ylw");
//3. Data processing - transformation
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value is row by row data
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//Collect and return the cut words one by one
}
}
});
DataStream<String> filtedDS = wordsDS.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return !value.equals("ylw");
}
});
DataStream<Tuple2<String, Integer>> wordAndOnesDS = filtedDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value is the word that comes in one by one
return Tuple2.of(value, 1);
}
});
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
DataStream<Tuple2<String, Integer>> result1 = groupedDS.sum(1);
DataStream<Tuple2<String, Integer>> result2 = groupedDS.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value1.f1);
}
});
//4. Output result - sink
result1.print("result1");
result2.print("result2");
//5. Trigger execute
env.execute();
}
}
Operation results:

2.2 consolidation
2.2.1 union
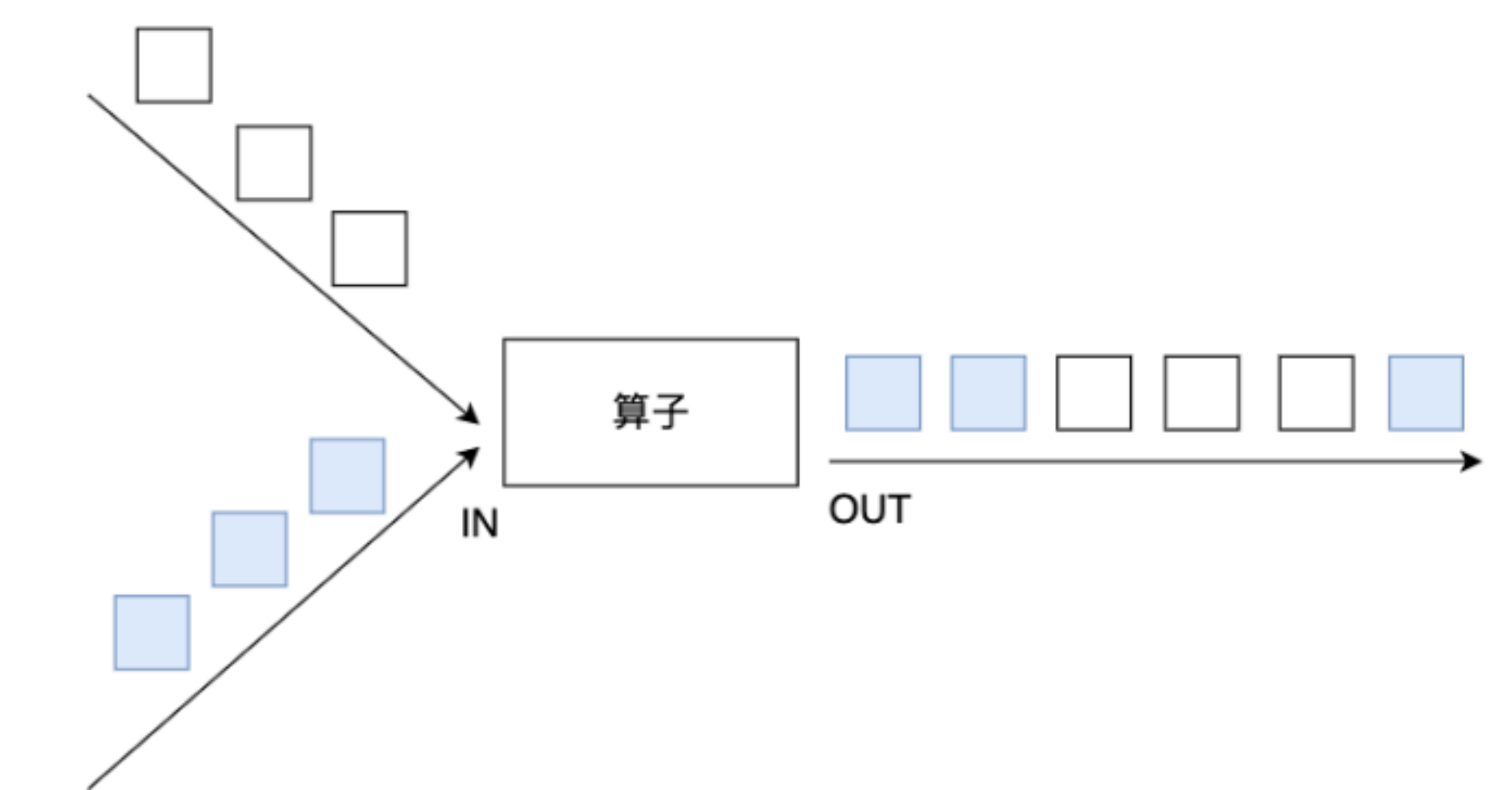
Union: union operator can merge multiple data streams of the same type and generate data streams of the same type, that is, multiple DataStream[T] can be merged into a new DataStream[T]. The data will be merged according to the First In First Out mode without de duplication.
2.2.2 connect
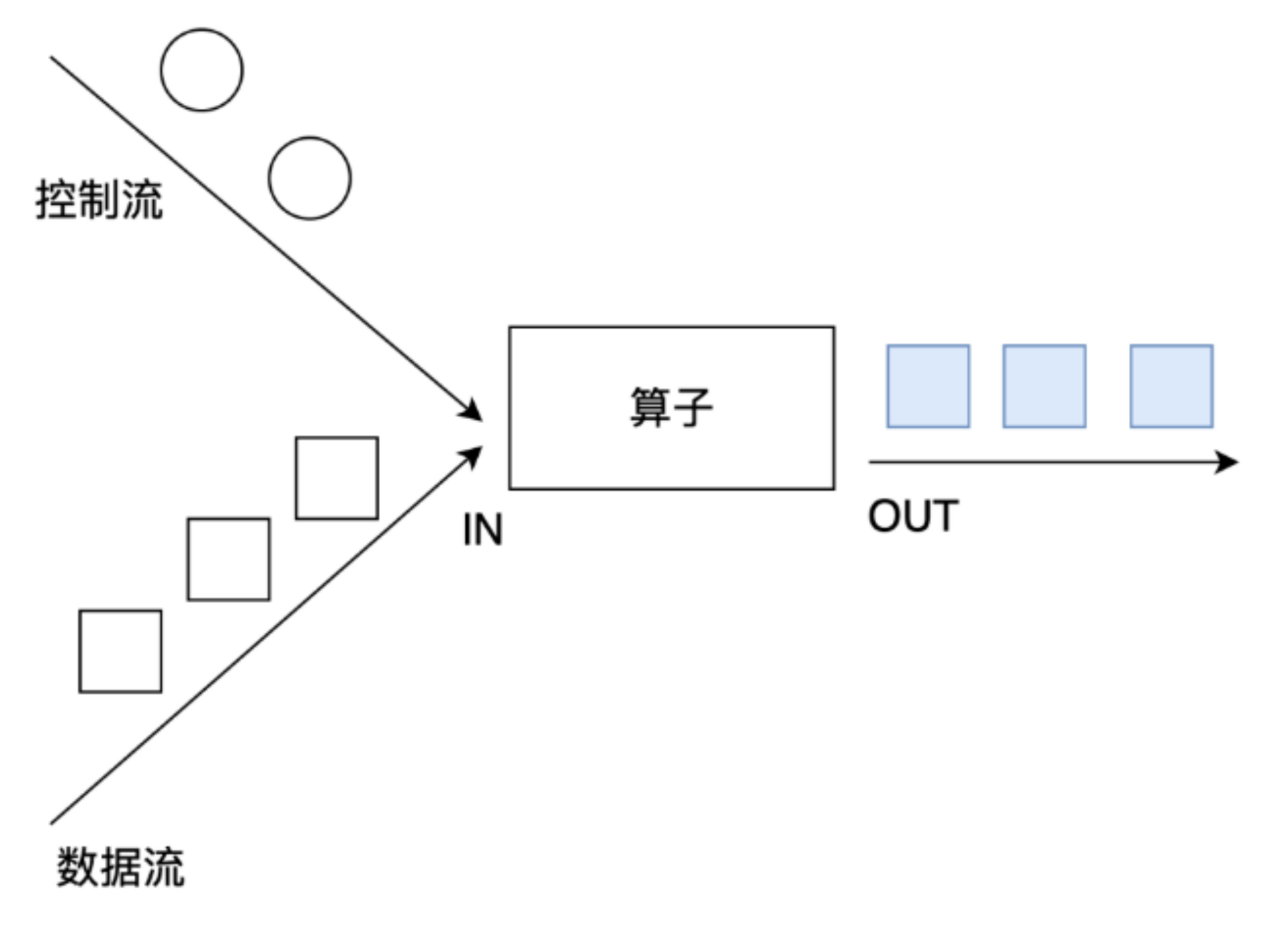
Connect: connect provides a function similar to union, which is used to connect two data streams. The difference between it and union is:
- Connect can only connect two data streams, and union can connect multiple data streams.
- The data types of the two data streams connected by connect can be inconsistent, and the data types of the two data streams connected by union must be consistent.
- Two datastreams are converted into ConnectedStreams after being connected. ConnectedStreams will apply different processing methods to the data of the two streams, and the state can be shared between the two streams.
2.2.3 example code
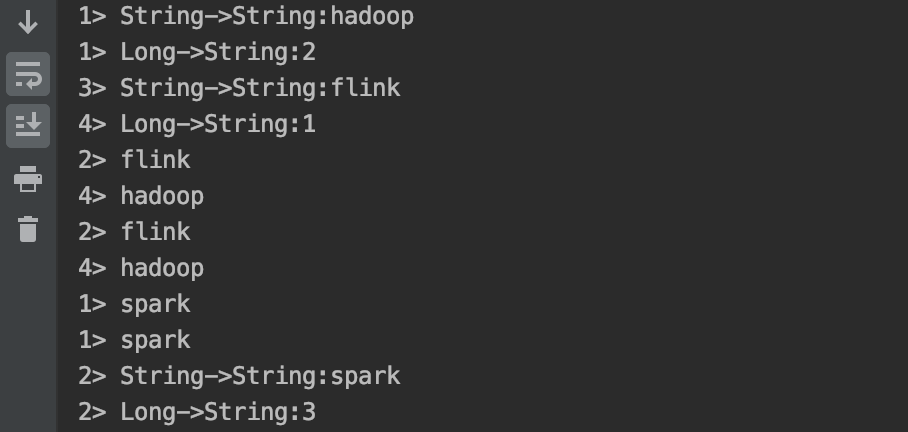
Now there is a requirement: union two streams of String type and connect one stream of String type and one stream of Long type.
Example code:
/**
* Transformation- union And connect
*
* @author : YangLinWei
* @createTime: 2022/3/7 3:44 afternoon
*/
public class TransformationDemo02 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");
DataStream<String> ds2 = env.fromElements("hadoop", "spark", "flink");
DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);
//3.Transformation
DataStream<String> result1 = ds1.union(ds2);//Merge without redoing https://blog.csdn.net/valada/article/details/104367378
ConnectedStreams<String, Long> tempResult = ds1.connect(ds3);
//interface CoMapFunction<IN1, IN2, OUT>
DataStream<String> result2 = tempResult.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String value) throws Exception {
return "String->String:" + value;
}
@Override
public String map2(Long value) throws Exception {
return "Long->String:" + value.toString();
}
});
//4.Sink
result1.print();
result2.print();
//5.execute
env.execute();
}
}
Operation results:
2.3 disassembly
2.3.1 API
API used for splitting:
- Split is to divide a stream into multiple streams (Note: the split function has expired and is removed);
- Select is to obtain the corresponding data after diversion;
- Side Outputs: you can use the process method to process the data in the stream and collect the data into different outputtags according to different processing results.
2.3.2 example code
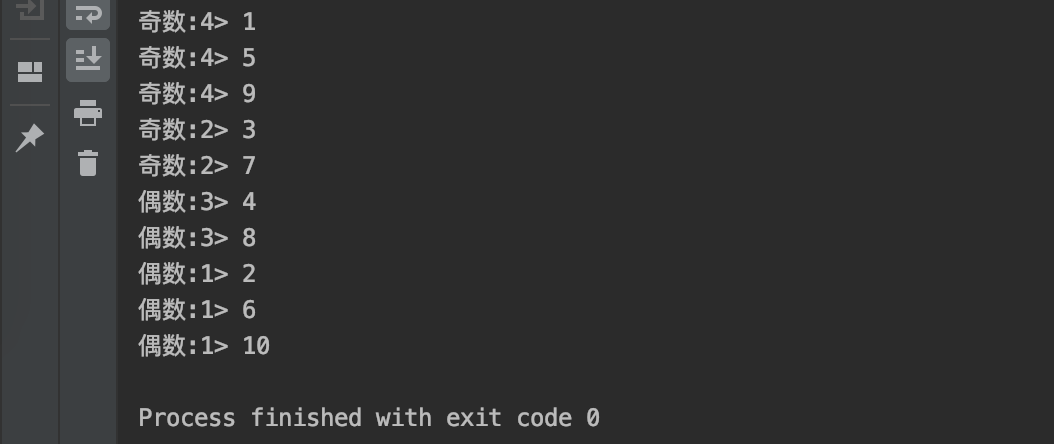
Demand: the data in the convection is shunted according to odd and even numbers, and the shunted data is obtained.
The example code is as follows:
/**
* Transformation -split
*
* @author : YangLinWei
* @createTime: 2022/3/7 3:50 afternoon
*/
public class TransformationDemo03 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStreamSource<Integer> ds = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//3.Transformation
/*SplitStream<Integer> splitResult = ds.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
//value It's the number coming in
if (value % 2 == 0) {
//even numbers
ArrayList<String> list = new ArrayList<>();
list.add("Even ");
return list;
} else {
//Odd number
ArrayList<String> list = new ArrayList<>();
list.add("Odd ");
return list;
}
}
});
DataStream<Integer> evenResult = splitResult.select("Even ");
DataStream<Integer> oddResult = splitResult.select("Odd ");*/
//Define two output labels
OutputTag<Integer> tag_even = new OutputTag<Integer>("even numbers", TypeInformation.of(Integer.class));
OutputTag<Integer> tag_odd = new OutputTag<Integer>("Odd number") {
};
//Process the data in ds
SingleOutputStreamOperator<Integer> tagResult = ds.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception {
if (value % 2 == 0) {
//even numbers
ctx.output(tag_even, value);
} else {
//Odd number
ctx.output(tag_odd, value);
}
}
});
//Take out the marked data
DataStream<Integer> evenResult = tagResult.getSideOutput(tag_even);
DataStream<Integer> oddResult = tagResult.getSideOutput(tag_odd);
//4.Sink
evenResult.print("even numbers");
oddResult.print("Odd number");
//5.execute
env.execute();
}
}
Operation results:
2.4 zoning
2.4.1 rebalance zoning
Similar to repartition in Spark, but with more powerful functions, it can directly solve data skew.
Flink also has data skew. For example, there are about 1 billion pieces of data to be processed. In the process of processing, the situation as shown in the figure may occur. In case of data skew, the other three machines will not complete the task until the execution of machine 1 is completed:
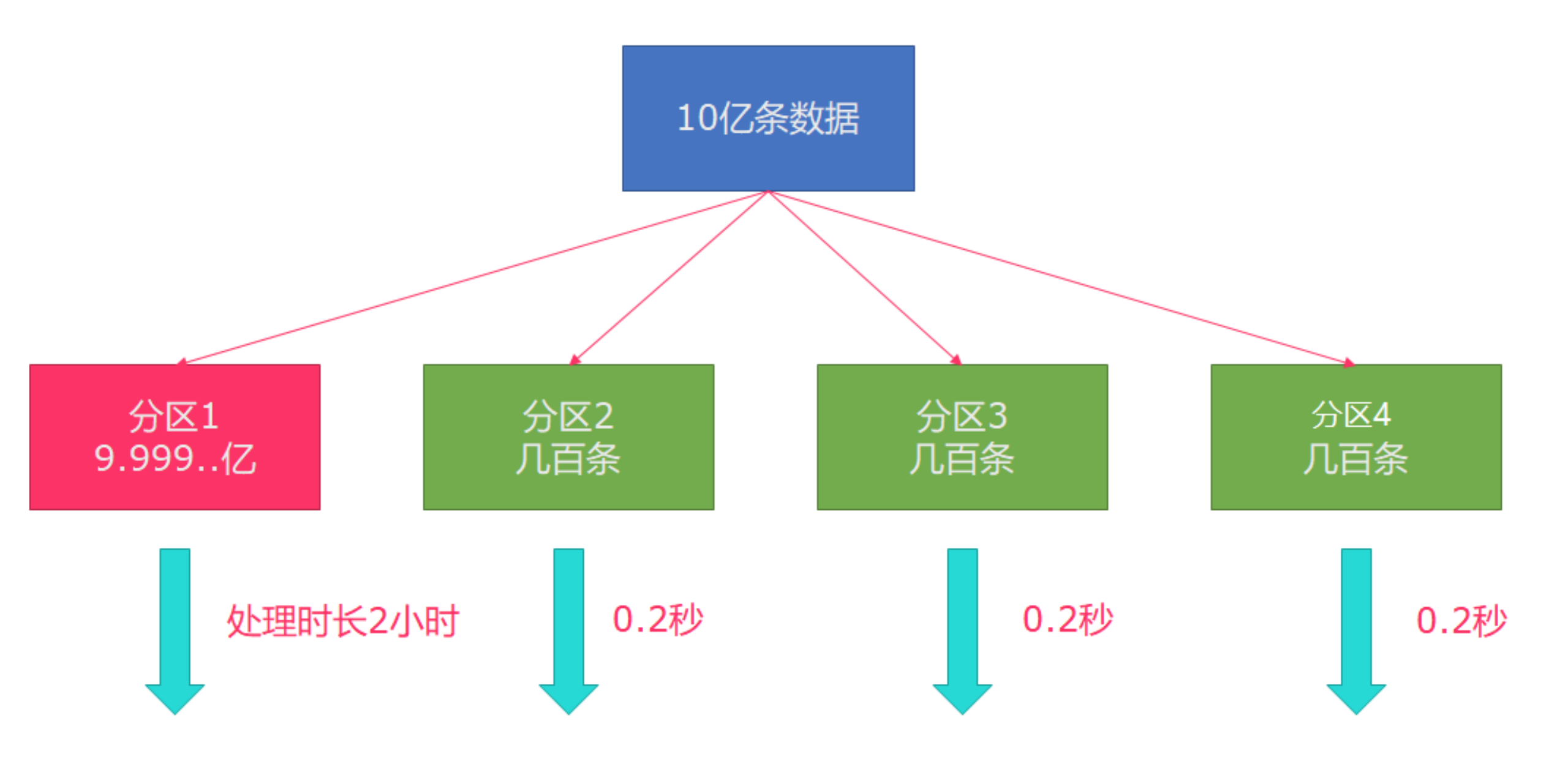
Therefore, in actual work, a better solution to this situation is rebalance (the internal round robin method is used to evenly disperse the data):
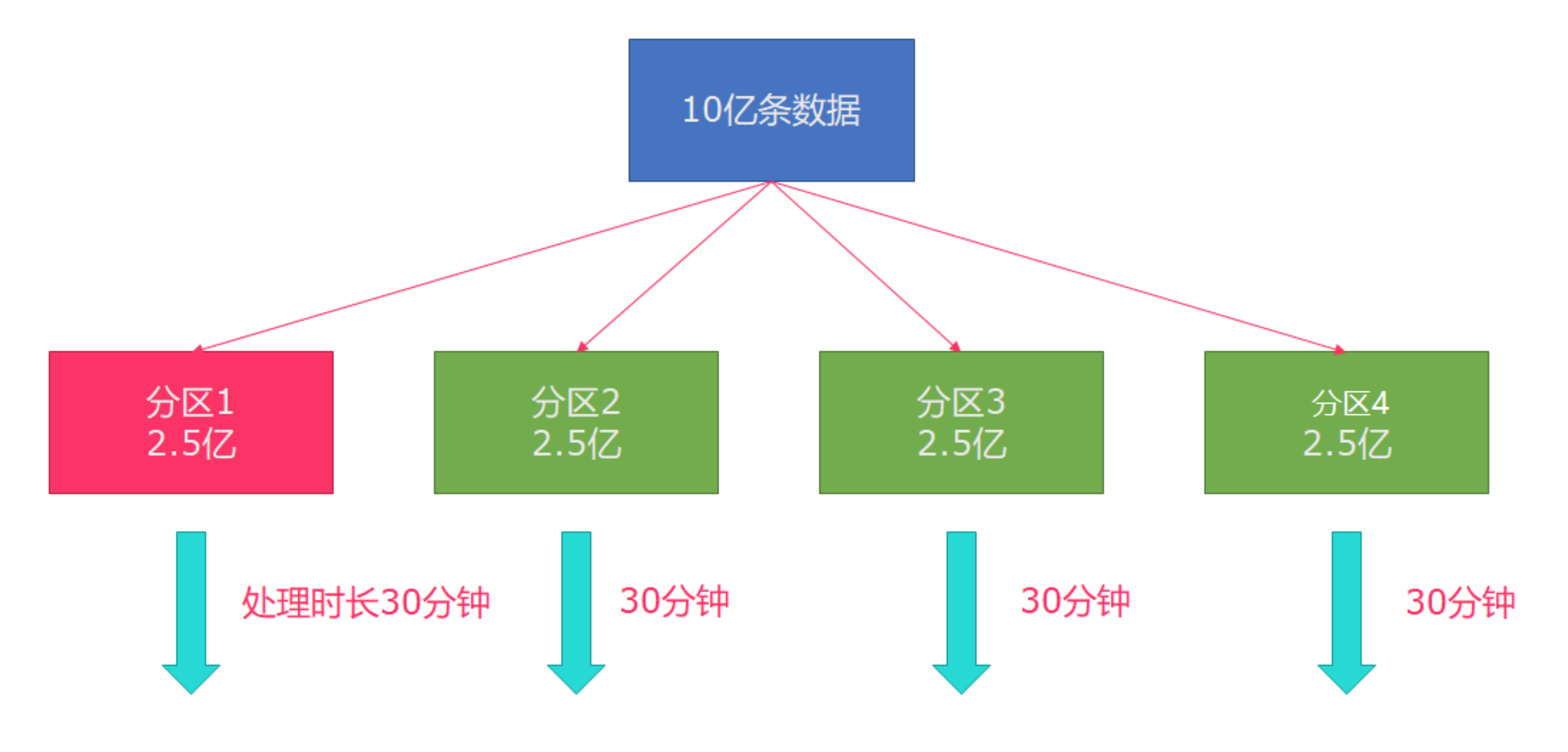
The example code is as follows:
/**
* Transformation -rebalance
* @author : YangLinWei
* @createTime: 2022/3/7 4:05 afternoon
*/
public class TransformationDemo04 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC).setParallelism(3);
//2.source
DataStream<Long> longDS = env.fromSequence(0, 100);
//3.Transformation
//The following operations are equivalent to randomly distributing the data. There may be data skew
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long num) throws Exception {
return num > 10;
}
});
//Next, use the map operation to convert the data into (partition number / subtask number, data)
//Rich means multi-functional. There are more API s than MapFunction for us to use
DataStream<Tuple2<Integer, Integer>> result1 = filterDS
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//Get partition number / subtask number
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
DataStream<Tuple2<Integer, Integer>> result2 = filterDS.rebalance()
.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
//Get partition number / subtask number
int id = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(id, 1);
}
}).keyBy(t -> t.f0).sum(1);
//4.sink
//result1.print();// Data skew is possible
result2.print();//rebalance and repartition balance are carried out before output to solve the problem of data skew
//5.execute
env.execute();
}
}
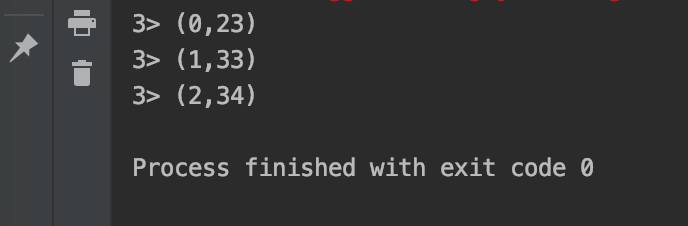
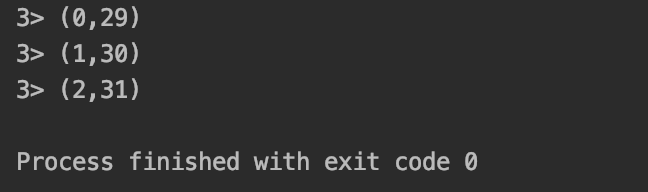
The operation results are as follows:
-
Data skew occurs:
-
Using rebalance:
2.4.2 other partitions
| type | describe |
|---|---|
| dataStream.global(); | Send all to the first task |
| dataStream.broadcast(); | radio broadcast |
| dataStream.forward(); | When the concurrency of upstream and downstream is the same, send one-to-one |
| dataStream.shuffle(); | Random uniform distribution |
| dataStream.reblance(); | Round robin (rotation) |
| dataStream.recale(); | Local round robin |
| dataStream.partitionCustom(); | Custom unicast |
explain:
- Receive partition: Based on the parallelism of upstream and downstream operators, records are output to each instance of downstream operators in a circular manner.
give an example:
- If the upstream parallelism is 2 and the downstream parallelism is 4, the upstream parallelism outputs the record to the two downstream parallelism in a circular manner; The other parallel degree upstream outputs the record to the other two parallel degrees downstream in a circular manner.
- If the upstream parallelism is 4 and the downstream parallelism is 2, the two upstream parallelism will output the record to one downstream parallelism; The other two parallelism degrees upstream output the record to another parallelism degree downstream.
The example code is as follows:
/**
* Transformation -partiton
*
* @author : YangLinWei
* @createTime: 2022/3/7 4:17 afternoon
*/
public class TransformationDemo05 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.Source
DataStream<String> linesDS = env.fromElements("hello me you her", "hello me you", "hello me", "hello");
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
//3.Transformation
DataStream<Tuple2<String, Integer>> result1 = tupleDS.global();
DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast();
DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward();
DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle();
DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance();
DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale();
DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new Partitioner<String>() {
@Override
public int partition(String key, int numPartitions) {
return key.equals("hello") ? 0 : 1;
}
}, t -> t.f0);
//4.sink
//result1.print();
//result2.print();
//result3.print();
//result4.print();
//result5.print();
//result6.print();
result7.print();
//5.execute
env.execute();
}
}
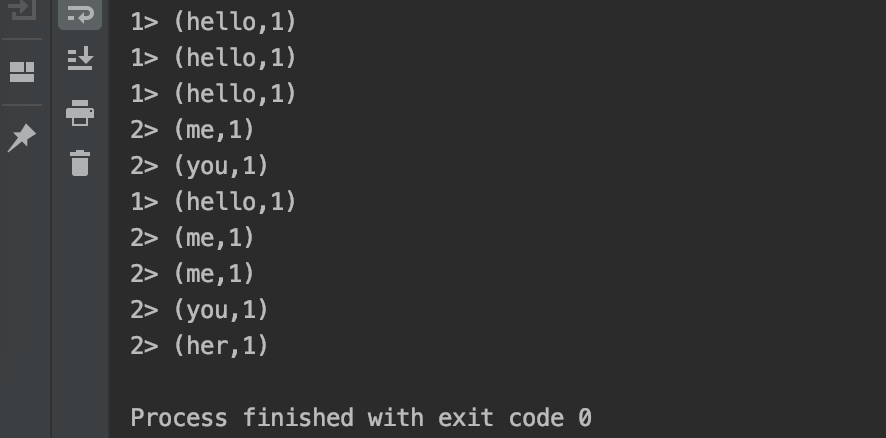
The operation results are as follows:
03 end
This article mainly explains the usage of Transformation in Flink batch streaming API. Thank you for reading. The end of this article!