In flink, StreamingFileSink is an important sink for writing streaming data to the file system. It supports writing data in row format (json, csv, etc.) and column format (orc, parquet).
Hive is a broad data storage, while ORC, as a special optimized column storage format of hive, plays an important role in the storage format of hive. Today, we will focus on using StreamingFileSink to write streaming data to the file system in ORC format, which is supported by Flink version 1.11.
Introduction to StreamingFileSink
StreamingFileSink provides two static methods to construct the corresponding sink, forRowFormat to construct the sink for writing row format data, and forBulkFormat to construct the sink for writing column format data.
Let's look at the method forBulkFormat.
/**
* Creates the builder for a {@link StreamingFileSink} with bulk-encoding format.
*
* @param basePath the base path where all the buckets are going to be created as
* sub-directories.
* @param writerFactory the {@link BulkWriter.Factory} to be used when writing elements in the
* buckets.
* @param <IN> the type of incoming elements
* @return The builder where the remaining of the configuration parameters for the sink can be
* configured. In order to instantiate the sink, call {@link BulkFormatBuilder#build()}
* after specifying the desired parameters.
*/
public static <IN> StreamingFileSink.DefaultBulkFormatBuilder<IN> forBulkFormat(
final Path basePath, final BulkWriter.Factory<IN> writerFactory) {
return new StreamingFileSink.DefaultBulkFormatBuilder<>(
basePath, writerFactory, new DateTimeBucketAssigner<>());
}
forBulkFormat has two parameters, the first is a path written to, and the second is an implementation BulkWriter used to create writer s. Factory class for Factory interface.
Write orc factory class
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-orc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Flnk gives us the factory class OrcBulkWriterFactory written in orc format, so let's take a brief look at some of its variables.
@PublicEvolving
public class OrcBulkWriterFactory<T> implements BulkWriter.Factory<T> {
private static final Path FIXED_PATH = new Path(".");
private final Vectorizer<T> vectorizer;
private final Properties writerProperties;
private final Map<String, String> confMap;
private OrcFile.WriterOptions writerOptions;
public OrcBulkWriterFactory(Vectorizer<T> vectorizer) {
this(vectorizer, new Configuration());
}
public OrcBulkWriterFactory(Vectorizer<T> vectorizer, Configuration configuration) {
this(vectorizer, null, configuration);
}
public OrcBulkWriterFactory(Vectorizer<T> vectorizer, Properties writerProperties, Configuration configuration) {
...................
}
.............
}
Vectorization operation
Flnk uses hive's VectorizedRowBatch to write data in ORC format, so the input data needs to be organized into VectorizedRowBatch objects, and the function of this transformation is accomplished by the variable in OrcBulkWriterFactory, which is also the abstract class Vectorizer class. The main method to achieve this is org.apache.flink.orc.vector.Vectorizer#vectorize method.
In flink, a RowData Vectorizer is provided that supports the RowData input format. In method vectorize, data in RowData format is converted to VectorizedRowBatch type according to different types.
@Override
public void vectorize(RowData row, VectorizedRowBatch batch) {
int rowId = batch.size++;
for (int i = 0; i < row.getArity(); ++i) {
setColumn(rowId, batch.cols[i], fieldTypes[i], row, i);
}
}
Construct OrcBulkWriterFactory
The factory class provides a total of three construction methods, and we see that the most complete one accepts three parameters. The first one is the Vectorizer object we mentioned above, the second one is a configuration property written in orc format, and the third one is a configuration file for hadoop.
Written configuration from https://orc.apache.org/docs/hive-config.html Can be as follows.
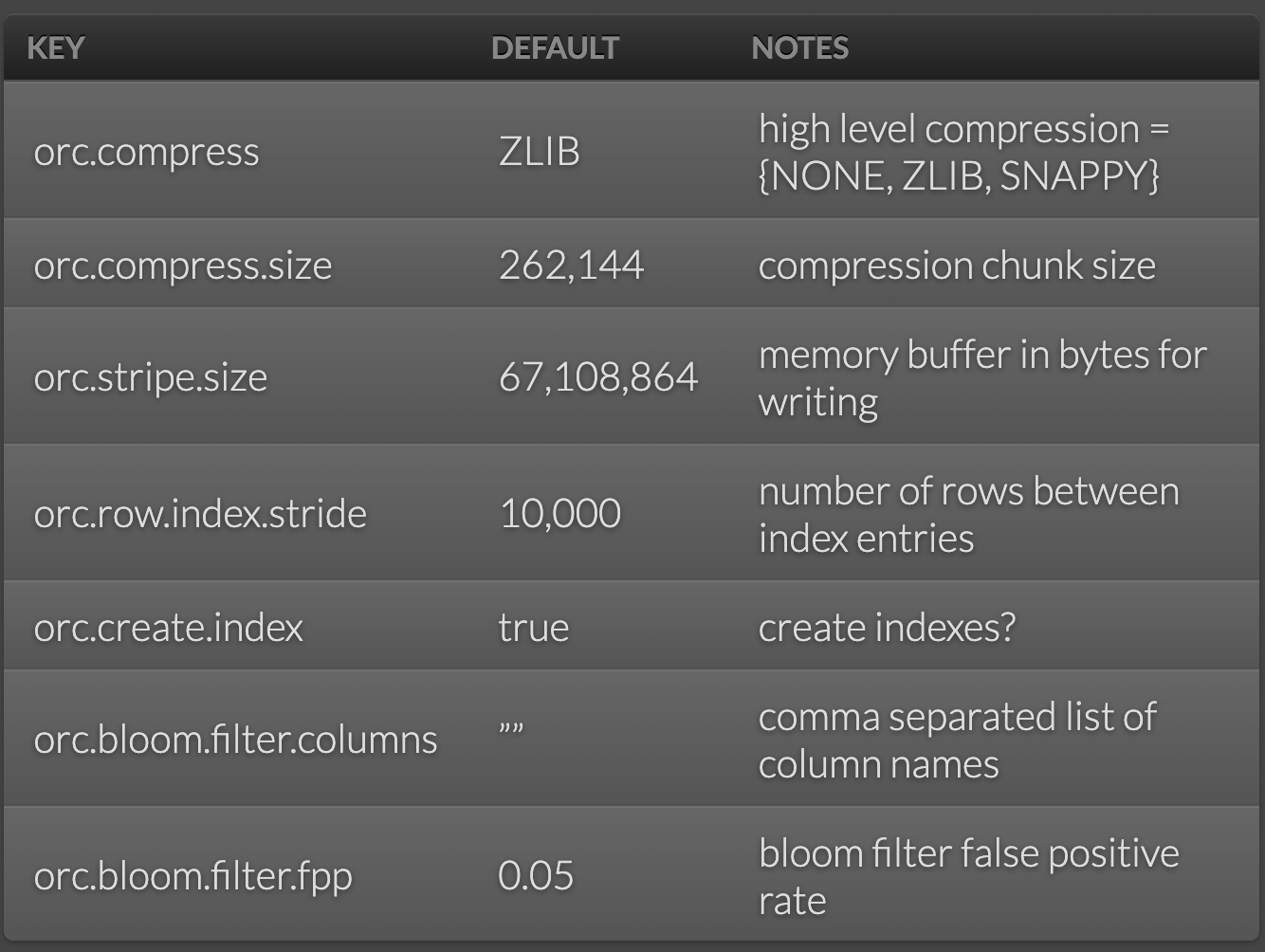
Instance Explanation
Construct source
First, we customize a source to simulate the generation of RowData data, which is also simpler, mainly to generate random numbers of type int and double.
public static class MySource implements SourceFunction<RowData>{
@Override
public void run(SourceContext<RowData> sourceContext) throws Exception{
while (true){
GenericRowData rowData = new GenericRowData(2);
rowData.setField(0, (int) (Math.random() * 100));
rowData.setField(1, Math.random() * 100);
sourceContext.collect(rowData);
Thread.sleep(10);
}
}
@Override
public void cancel(){
}
}
Construct OrcBulkWriterFactory
Next, define the parameters required to construct the OrcBulkWriterFactory.
//Writing attributes in orc format
final Properties writerProps = new Properties();
writerProps.setProperty("orc.compress", "LZ4");
//Define type and field name
LogicalType[] orcTypes = new LogicalType[]{new IntType(), new DoubleType()};
String[] fields = new String[]{"a1", "b2"};
TypeDescription typeDescription = OrcSplitReaderUtil.logicalTypeToOrcType(RowType.of(
orcTypes,
fields));
//Construct factory class OrcBulkWriterFactory
final OrcBulkWriterFactory<RowData> factory = new OrcBulkWriterFactory<>(
new RowDataVectorizer(typeDescription.toString(), orcTypes),
writerProps,
new Configuration());
Construct StreamingFileSink
StreamingFileSink orcSink = StreamingFileSink
.forBulkFormat(new Path("file:///tmp/aaaa"), factory)
.build();