Dimension table is a concept in data warehouse. The dimension attribute in dimension table is to observe data and supplement the information of fact table. In the real-time data warehouse, there are also the concepts of dimension table and fact table. The fact table is usually kafka's real-time stream data, and the dimension table is usually stored in external devices (such as MySQL and HBase). For each streaming data, you can associate an external dimension table data source to provide data association query for real-time calculation. The dimension table may change constantly. When joining the dimension table, you need to indicate the time when this record is associated with the dimension table snapshot.
This paper mainly introduces
- 1. Difference between flow table and dimension table
- 2. Data flow analysis of flow table and dimension table join
- 3. Data flow analysis of dual stream join
- 4. Code examples and scenarios
1. Difference between flow table and dimension table:
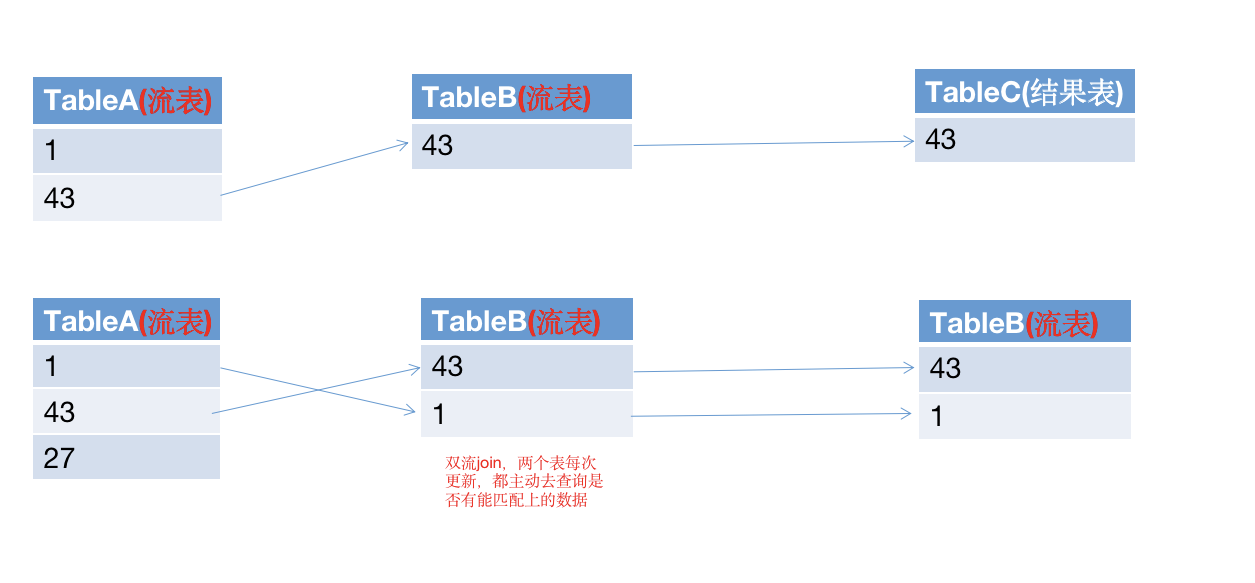
Flow table: the table mapped by real-time flow data. In the join query, each piece of data will take the initiative to query whether there is matching data in the dimension table
Dimension table: dimension information tables are generally passively queried in external storage (Redis, Mysql). At present, the dimension table JOIN of Flink SQL only supports the association of dimension table snapshots at the current time
2. Flow table and dimension table join:

3. Flow table and flow table Association (dual flow jion):
4. Code example (FlinkSQL)
Flow table and dimension table join
Scenario:
The flow table is the user's behavior data, which records the user's learning content, learning duration and other information
Dimension table is student information data (name, mobile phone number)
If the cpt table has A real-time stream data from the learning record of classmate A, the student table does not have the student's information, and the obtained name and mobile phone number are null. When the student table is updated with A's information, the subsequent real-time stream data can be associated to obtain A's name and mobile phone number, but the real-time stream data before the student table is updated is still unavailable (this should be noted)
sql
establish kafka Data source, flow table
table_env.execute_sql(
CREATE TABLE cpt(
content_id string,
student_uid string,
course_id string,
content_type int,
study_time bigint,
chapter_id string,
section_id string,
progress int,
updated_at string,
created_at string,
playback_time int,
ptime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'stream_content_study_progress',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 't1',
'scan.startup.mode'='earliest-offset',
'format' = 'json'
)
establish Redis Dimension table
table_env.execute_sql(
create table student(
uid string,
mobile string,
name string,
PRIMARY KEY (uid) NOT ENFORCED
)with(
'connector'='redis',
'ip'='localhost',
'password'='',
'port'='6379',
'table'='user',
'database'='1'
)
Flow table and dimension table join
table_env.execute_sql(
insert into res
select
t.student_uid as uid,
student.mobile as mobile,
t.course_id as courseId,
t.study_time as viewingTime,
unix_timestamp(t.updated_at)*1000 as updateTime,
from cpt as t
left join student for system_time as of t.ptime on t.student_uid=student.uid
)
Flow table and flow table join
Scenario: the scenario described above can be well solved by double flow join. Both are flow tables. When any one of the two tables receives data, it will query whether there is matching data (including history) in the other table
table_env.execute_sql(
CREATE TABLE cpt(
content_id string,
student_uid string,
course_id string,
content_type int,
study_time bigint,
chapter_id string,
section_id string,
progress int,
updated_at string,
created_at string,
playback_time int,
ptime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'stream_content_study_progress',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 't1',
'scan.startup.mode'='earliest-offset',
'format' = 'json'
)
Creating a flow table is actually a dimension table
table_env.execute_sql(
create table student(
uid string,
mobile string,
name string,
PRIMARY KEY (uid) NOT ENFORCED
)with(
'connector' = 'kafka',
'topic' = 'stream_student',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 't1',
'scan.startup.mode'='earliest-offset',
'format' = 'json'
)
Shuangliu join
table_env.execute_sql(
insert into res
select
t.student_uid as uid,
student.mobile as mobile,
t.course_id as courseId,
t.study_time as viewingTime,
unix_timestamp(t.updated_at)*1000 as updateTime,
from cpt as t
left join student t.student_uid=student.uid
)