Catalog
2.3.1. Official Case - Monitoring Port
2.3.2, Real-time monitoring of individual appended files
2.3.3, Multiple files under Real-time Monitoring Directory
1. What is Flume?
1.1. Definition of flume
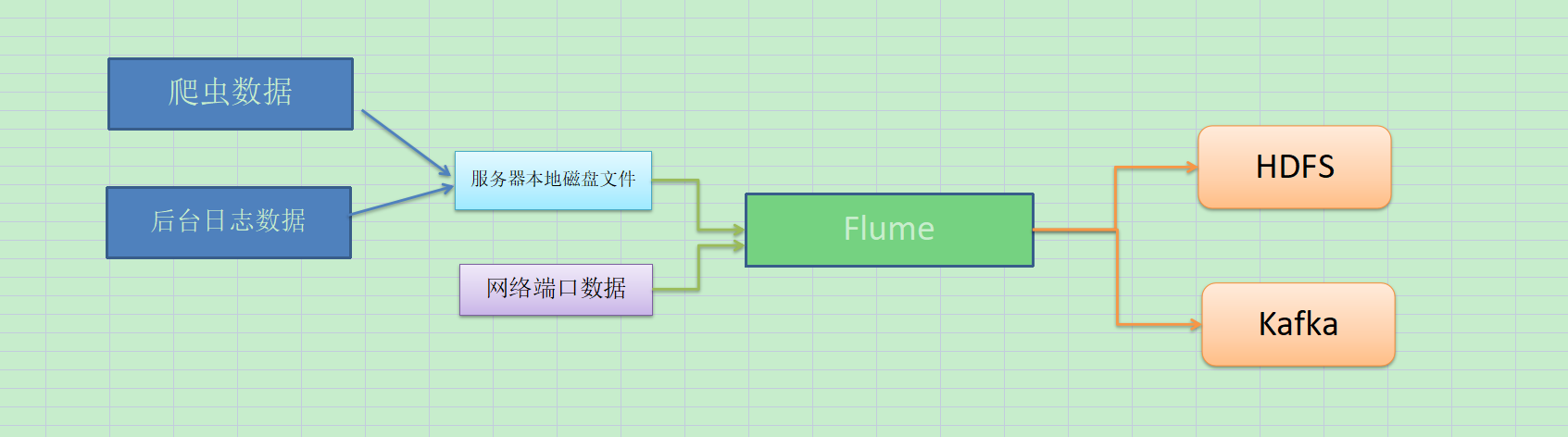
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
In short
Flume is a highly available, highly reliable, distributed system for collecting, aggregating, and transferring massive logs from Cloudera.
The main role of Flume:
1.2, architecture of flume
Official Web Diagram
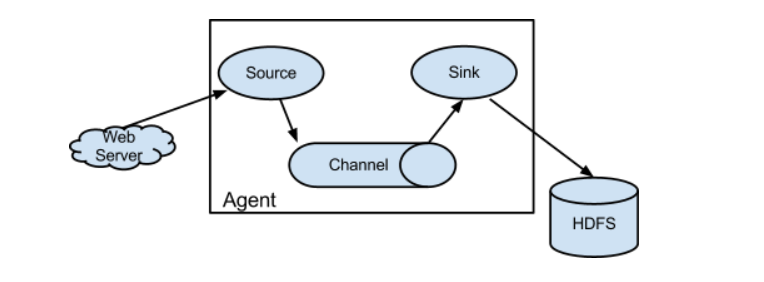
[1]Agent
An agent is a jvm process that sends data from source to destination in the form of events.
An agent consists mainly of three parts (source sink channel)
[2]Source
ource is the component responsible for receiving data to the Flume Agent. The Source component can handle various types and formats of log data, including avro, thrift, exec, jms, spooling directory, netcat, taildir, sequence generator, syslog, http, legacy.
[3]Sink
(ii) Sink continuously polls Channel for events and removes them in batches and writes them in batches to a storage or indexing system or is sent to another Flume Agent. Sink component destinations include hdfs, logger, avro, thrift, ipc, file, HBase, solr, custom
[4]Channel
Channel is a buffer between Source and Link. Therefore, Channel allows Source and Link to operate at different rates. Channel is thread-safe and can handle several Source write operations and several Sink read operations simultaneously.
flume comes with two channels: Memory Channel and File Channel.
-
Memory Channel is an in-memory queue. Memory Channel works in situations where you don't need to be concerned about data loss. If you need to be concerned about data loss, Memory Channel should not be used because program death, machine downtime, or restart can cause data loss.
-
File Channel writes all events to disk. Therefore, data will not be lost if the program is shut down or the machine is down.
[5]Event
Transport unit, the basic unit of Flume data transmission, that sends data from source to destination as an Event.
The event consists of a Header and a Body, which stores some properties of the event in a K-V structure and a Body in an array of bytes.
The core of Flume operation is Agent. Flume runs in agent as its smallest independent unit. An agent is a JVM.
2. Introduction to Flume
2.1, Download flume
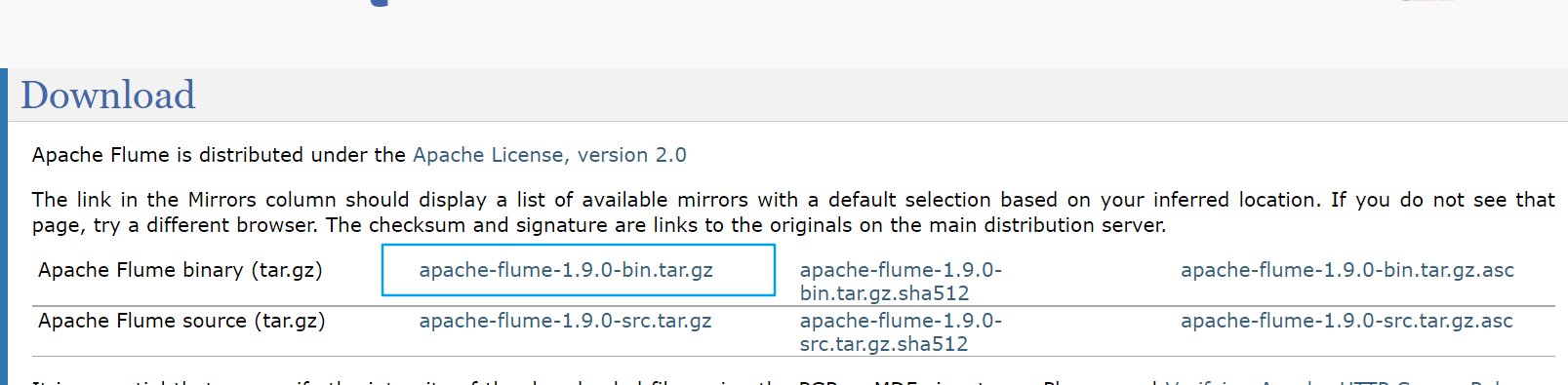
(1) Flume website address: Welcome to Apache Flume — Apache Flume
(2) Download address: Download — Apache Flume
2.2. Install flume
[1] Upload apache-flume-1.9.0-bin.tar.gz to the/opt/software directory of linux
[2] Unzip apache-flume-1.9.0-bin.tar.gz to/opt/module/directory
[3] Modify the name of apache-flume-1.9.0-bin to flume-1.9.0
[4] Remove guava-11.0.2.jar from lib folder to be compatible with Hadoop 3.1.3
cd /opt/module/flume-1.9.0/lib ll | grep guava rm -rf guava-11.0.2.jar
At this point, flume can be used as a running case to try
2.3. Small flume cases
2.3.1. Official Case - Monitoring Port
Official case description:
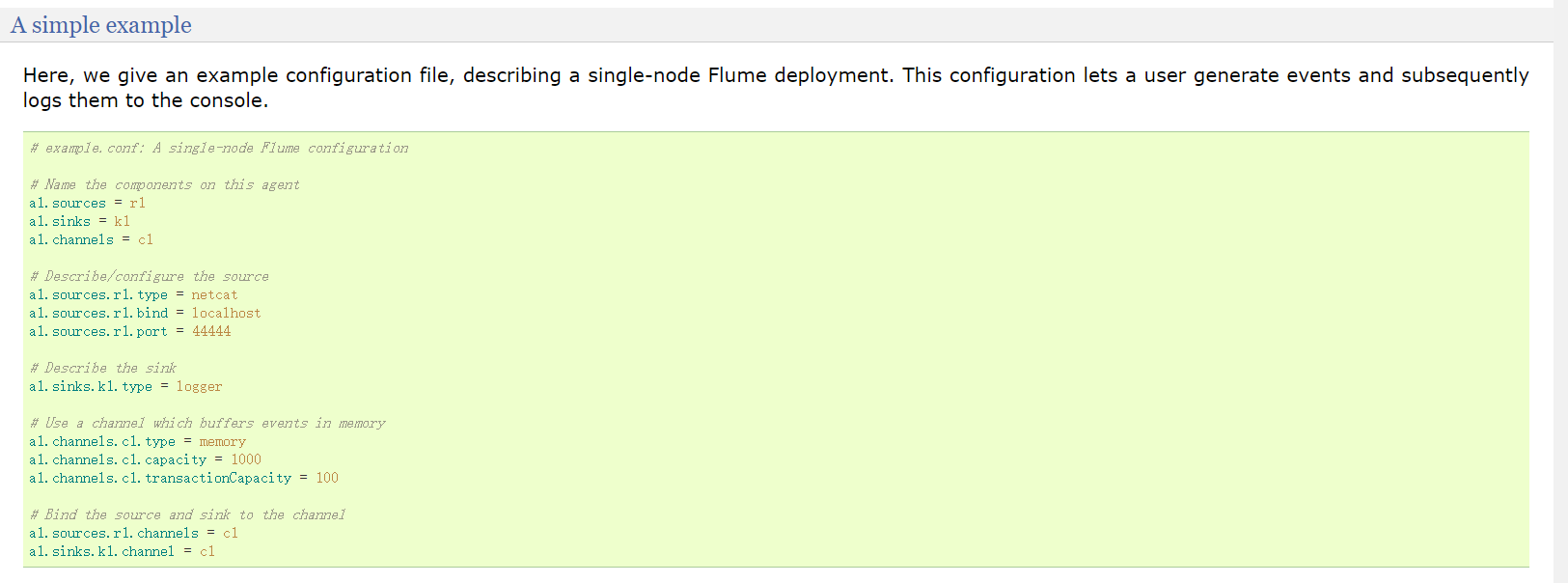
Use Flume to listen on a port, collect the port data, and print to the console.
1. Environmental preparation
[1] Install netcat
sudo yum install -y nc
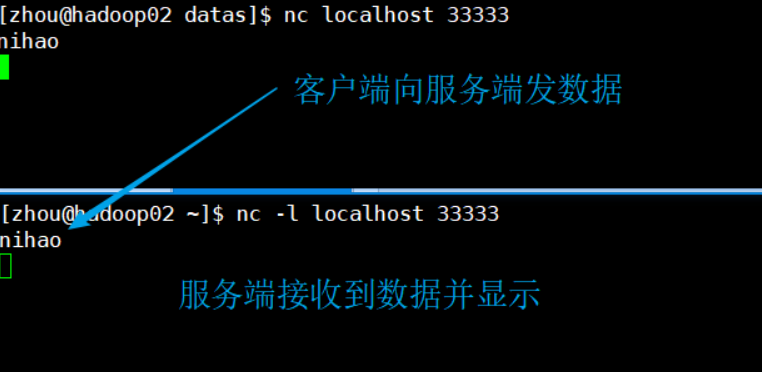
[2] test nc
nc can start server or client
NC-L localhost 33333 #Open Server
nc localhost 33333 #Client Access
[3] Create a datas folder in the flume directory and enter the datas folder
2. Coding
[1] Create the file flume-netcat-logger.conf in the datas directory
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
[2] Determine if port 44444 is occupied
sudo netstat -nlp | grep 44444
[3] Open flume monitoring window
#First Writing Method bin/flume-ng agent --conf conf/ --name a1 --conf-file datas/flume-netcat-logger.conf -Dflume.root.logger=INFO,console #Second Writing bin/flume-ng agent -c conf/ -n a1 -f datas/flume-netcat-logger.conf -Dflume.root.logger=INFO,console

[4] Send content to port 44444 of this machine using netcat tools
nc localhost 44444
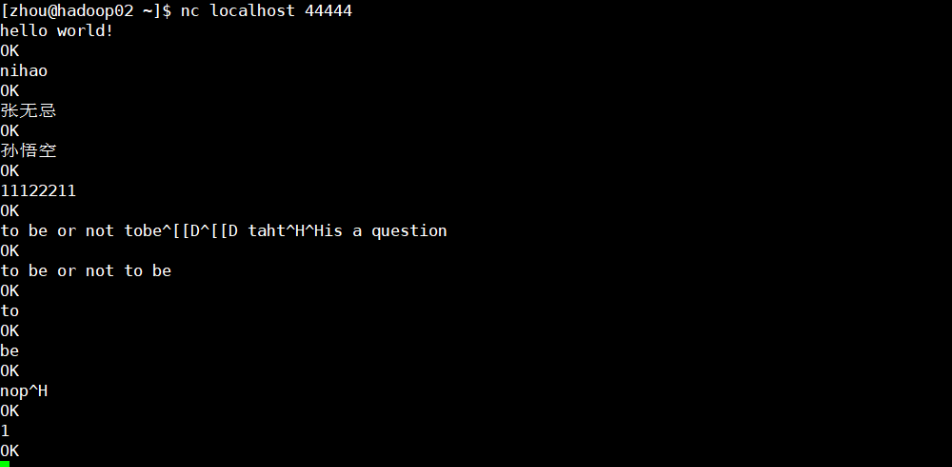
[5] Watch data reception on the flume monitor page
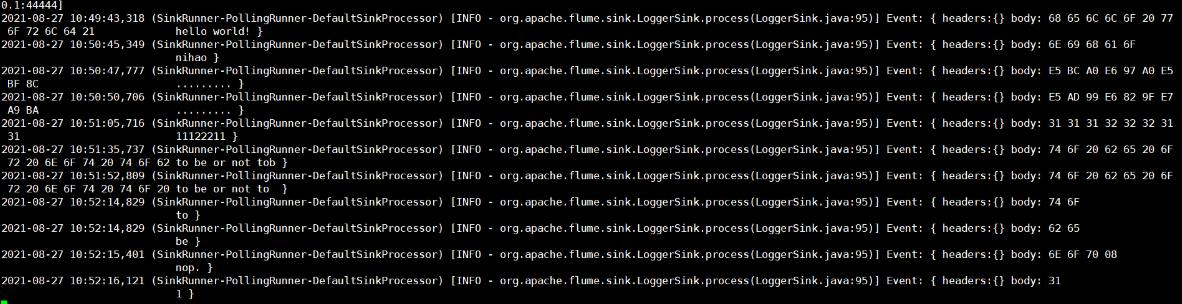
2.3.2, Real-time monitoring of individual appended files
Requirements: Monitor hive logs in real time and upload them to HDFS
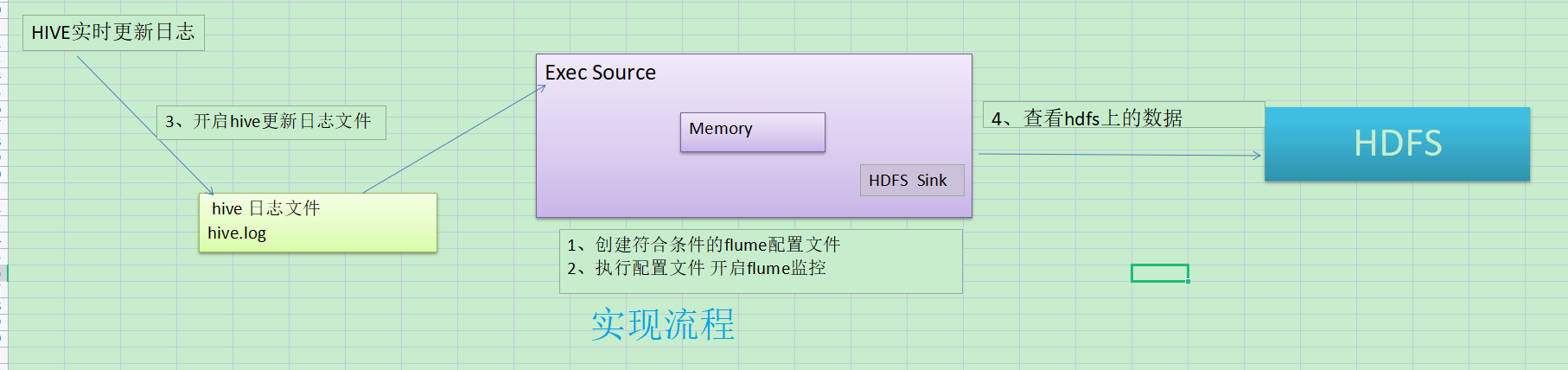
Implementation steps:
1. Now print the data to the console:
[1] Flume relies on Hadoop-related jar packages to export data to HDFS
Check the / etc/profile.d/my_env.sh file to make sure that Hadoop and Java environment variables are configured correctly
[2] Create a flume-file-hdfs.conf file in the datas directory and add the following:
#AGent_name a1.sources = r1 a1.sinks = k1 a1.channels = c1 #Sources a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive-3.1.2/logs/hive.log #Channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #sinks a1.sinks.k1.type = logger #combination a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
[3] Start flume monitoring
bin/flume-ng agent -c conf/ -f datas/flume-exec-logger.conf -n a1 -Dflume.root.logger=INFO,console
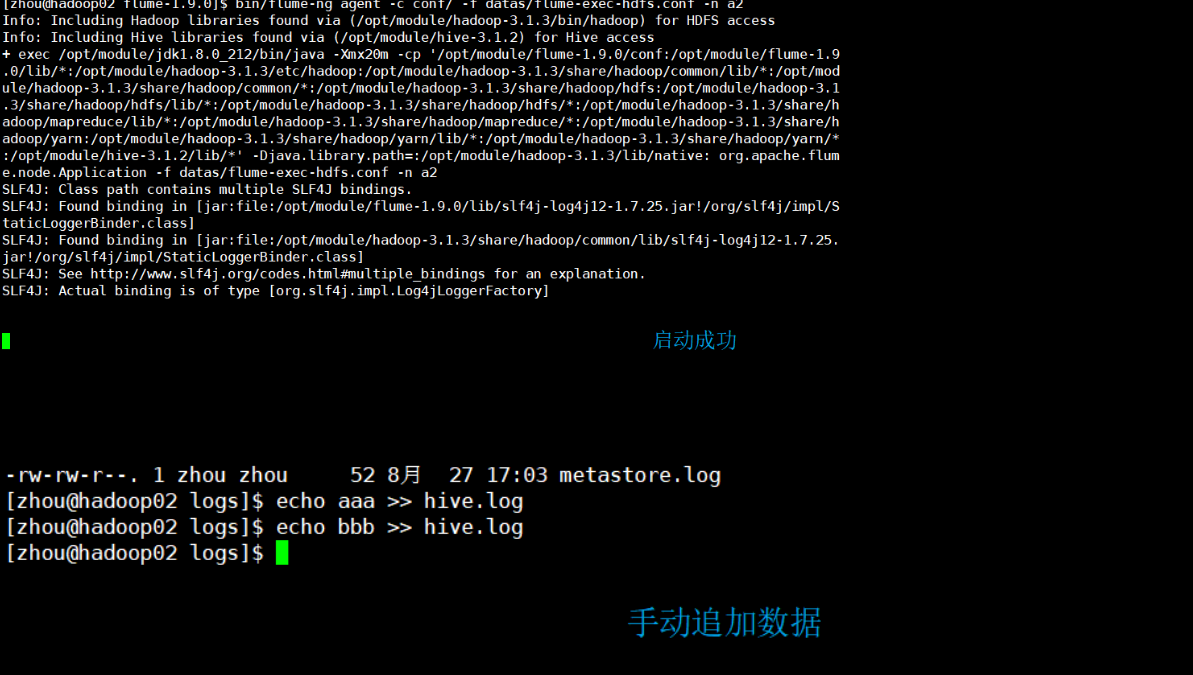
[4] Manually append data to the hive.log file and view the monitoring window
echo aaa >> hive.log
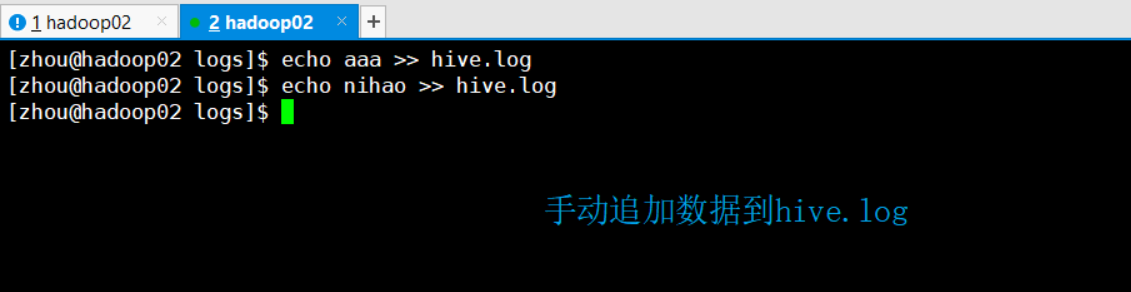
[5] View the monitoring window

Add data to hive.log dynamically
[1] Start hive Start hdoop first Start hive
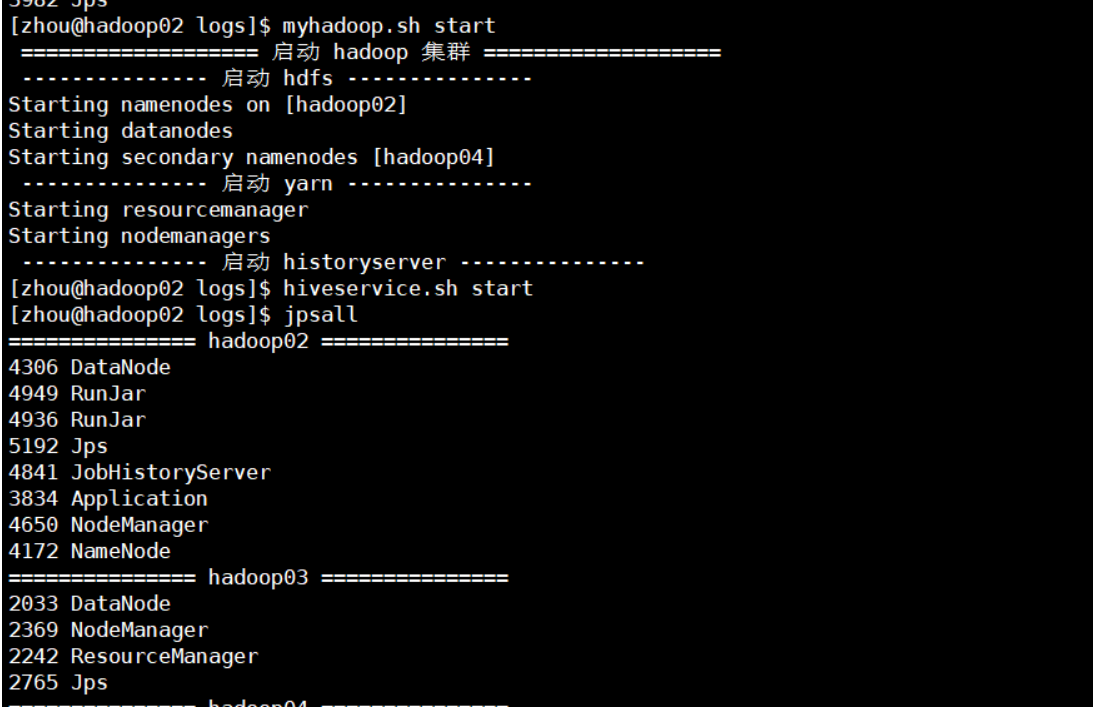
[2] connect hive to observe flume monitoring changes
beeline -u jdbc:hive2://hadoop02:10000 -n zhou
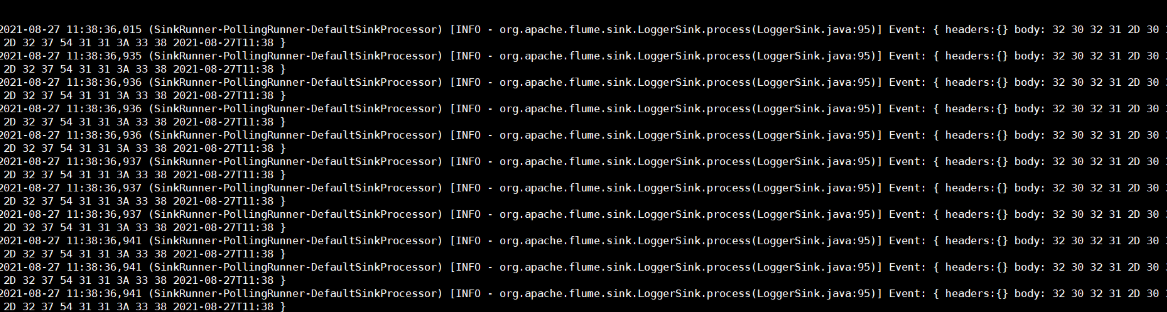
[3] Execute commands in the hive window
use mydb;

This shows that hive.log is updated when we operate hive. Because we monitor the hive.log file, when new data is appended to hive.log, it is monitored and printed to the console
2. Export data to hdfs
[1] Modify or create a new profile
# Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /opt/module/hive-3.1.2/logs/hive.log # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop02:8020/flume/%Y%m%d/%H #Prefix for uploading files a2.sinks.k2.hdfs.filePrefix = logs- #Whether to scroll folders according to time a2.sinks.k2.hdfs.round = true #How much time unit to create a new folder a2.sinks.k2.hdfs.roundValue = 1 #Redefine time units a2.sinks.k2.hdfs.roundUnit = hour #Whether to use local timestamps a2.sinks.k2.hdfs.useLocalTimeStamp = true #How many Event s to flush to HDFS once a2.sinks.k2.hdfs.batchSize = 100 #Set file type to support compression a2.sinks.k2.hdfs.fileType = DataStream #How often to generate a new file a2.sinks.k2.hdfs.rollInterval = 60 #Set scroll size for each file a2.sinks.k2.hdfs.rollSize = 134217700 #File scrolling is independent of the number of Event s a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2
[2] HDFS is started before flume is started
bin/flume-ng agent -c conf/ -f datas/flume-exec-hdfs.conf -n a2
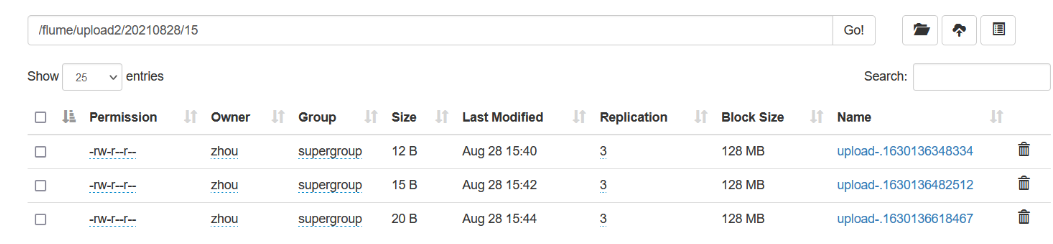
[3] View on hdfs
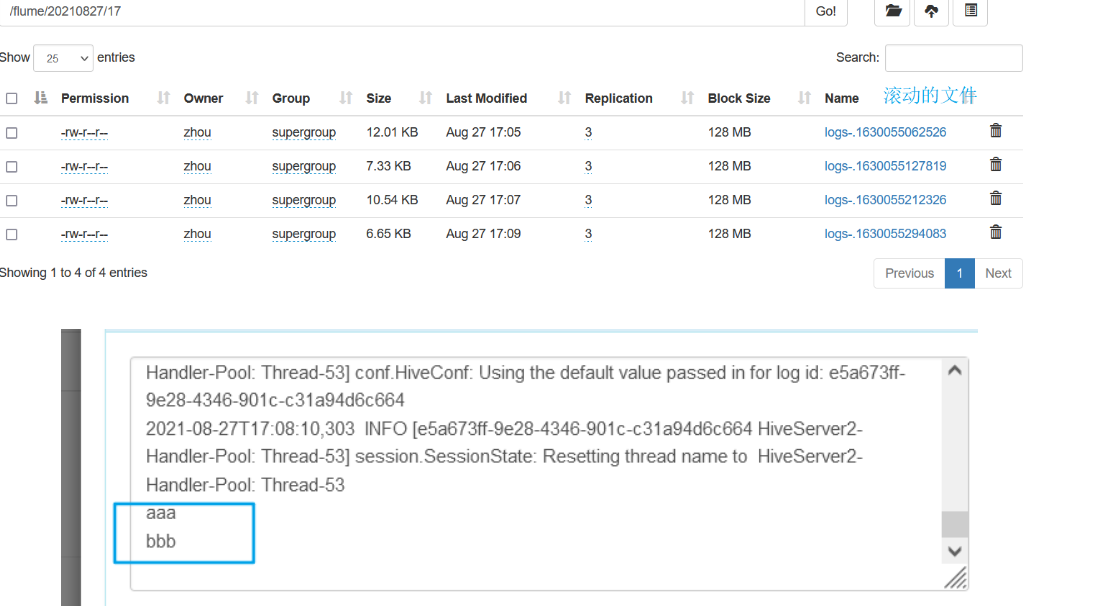
[4] Turn on hive to update hive.log automatically
2.3.3, Multiple files under Real-time Monitoring Directory
-
Exec source is suitable for monitoring a real-time appended file and cannot be used for breakpoint continuation.
-
Spooldir Source is good for synchronizing new files, but not for monitoring and synchronizing real-time logged files
-
Taildir Source is designed to listen for multiple files that are appended in real time and enable breakpoint continuation
Requirements: Use Flume to monitor the real-time appending of files to the entire directory and upload them to HDFS
Steps to achieve:
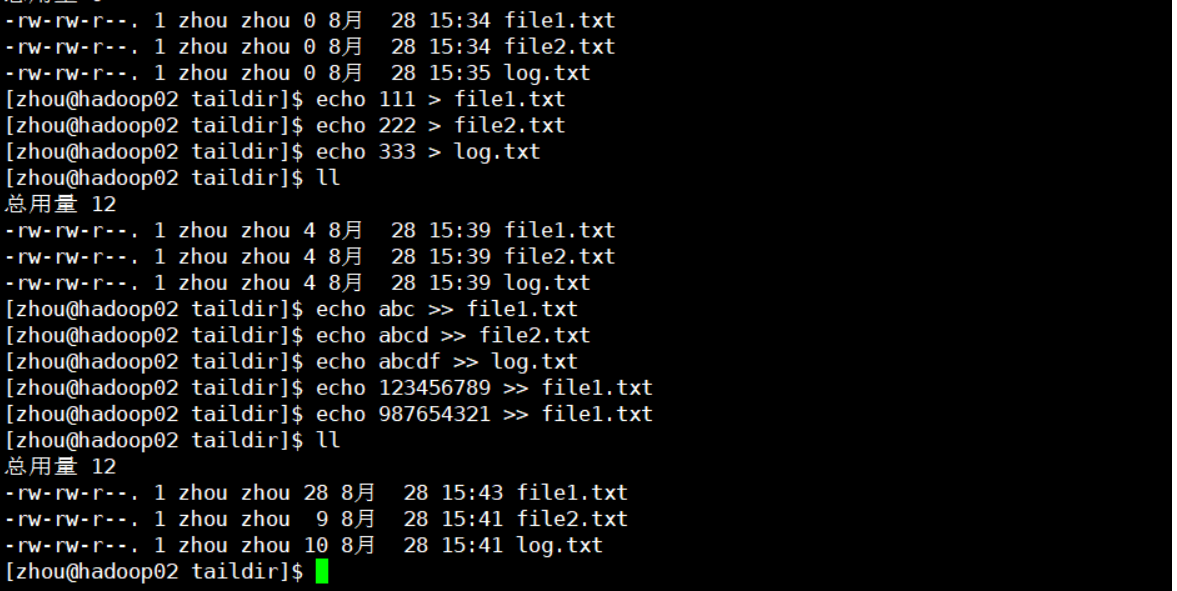
[1] Create a monitored directory
I'm monitoring the taildir directory here. This directory needs to be created in advance
mkdir taildir cd taildir touch file1.txt touch file2.txt
[2] Create file flume-taildir-hdfs.conf
a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = TAILDIR a3.sources.r3.positionFile = /opt/module/flume-1.9.0/datas/position/tail_dir.json a3.sources.r3.filegroups = f1 f2 a3.sources.r3.filegroups.f1 = /opt/module/flume-1.9.0/datas/taildir/.*file.* a3.sources.r3.filegroups.f2 = /opt/module/flume-1.9.0/datas/taildir/.*log.* # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop02:8020/flume/upload2/%Y%m%d/%H #Prefix for uploading files a3.sinks.k3.hdfs.filePrefix = upload- #Whether to scroll folders according to time a3.sinks.k3.hdfs.round = true #How much time unit to create a new folder a3.sinks.k3.hdfs.roundValue = 1 #Redefine time units a3.sinks.k3.hdfs.roundUnit = hour #Whether to use local timestamps a3.sinks.k3.hdfs.useLocalTimeStamp = true #How many Event s to flush to HDFS once a3.sinks.k3.hdfs.batchSize = 100 #Set file type to support compression a3.sinks.k3.hdfs.fileType = DataStream #How often to generate a new file a3.sinks.k3.hdfs.rollInterval = 60 #Set the scroll size for each file to approximately 128M a3.sinks.k3.hdfs.rollSize = 134217700 #File scrolling is independent of the number of Event s a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
[3] Start flume monitoring
bin/flume-ng agent -c conf -f datas/flume-taildir-hdfs.conf -n a3
[4] Append content to the file
[5] View hdfs