The slicing rules of MyCat are configured in conf directory Defined in rule.xml file;
Environmental preparation:
- Back up the contents in schema.xml and configure it Logical library;
<schema name="PARTITION_DB" checkSQLschema="false" sqlMaxLimit="100"> <table name="" dataNode="dn1,dn2,dn3" rule=""/> </schema> <dataNode name="dn1" dataHost="host1" database="partition_db" /> <dataNode name="dn2" dataHost="host2" database="partition_db" /> <dataNode name="dn3" dataHost="host3" database="partition_db" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.192.157:3306" user="root" password="itcast"></writeHost> </dataHost> <dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM2" url="192.168.192.158:3306" user="root" password="itcast"></writeHost> </dataHost> <dataHost name="host3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM3" url="192.168.192.159:3306" user="root" password="itcast"></writeHost> </dataHost>
- In the database of three nodes of MySQL, create database partition_db
create database partition_db DEFAULT CHARACTER SET utf8mb4;
1, Take mold and slice
<tableRule name="mod-long"> <rule> <columns>id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <property name="count">3</property> </function>
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| count | Number of data nodes |
2, Range slicing
The partition to which the data belongs is determined according to the correspondence between the specified field and its configured range and the data node. The configuration is as follows:
<tableRule name="auto-sharding-long"> <rule> <columns>id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule> <function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> <property name="defaultNode">0</property> </function>
autopartition-long.txt The configuration is as follows:
# range start-end ,data node index # K=1000,M=10000. 0-500M=0 500M-1000M=1 1000M-1500M=2
Meaning: value between 0 and 5 million, stored in data node 0; The data between 5 million and 10 million is stored in No. 1 data node; 10-15 million data nodes are stored in node 2;
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| type | The default value is 0; 0 represents integer and 1 represents String |
| defaultNode | The default node is used by the default node: when enumerating fragments, if an unrecognized enumeration value is encountered, it will be routed to the default node; If there is no default value, an error will be reported if an unrecognized value is encountered. |
Test:
to configure
<table name="tb_log" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"/>
data
1). Create table CREATE TABLE `tb_log` ( id bigint(20) NOT NULL COMMENT 'ID', operateuser varchar(200) DEFAULT NULL COMMENT 'full name', operation int(2) DEFAULT NULL COMMENT '1: insert, 2: delete, 3: update , 4: select', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_log (id,operateuser ,operation) values(1,'Tom',1); insert into tb_log (id,operateuser ,operation) values(2,'Cat',2); insert into tb_log (id,operateuser ,operation) values(3,'Rose',3); insert into tb_log (id,operateuser ,operation) values(4,'Coco',2); insert into tb_log (id,operateuser ,operation) values(5,'Lily',1);
3, Enumeration fragmentation
By configuring possible enumeration values in the configuration file, the specified data is distributed to different data nodes. This rule applies to Businesses such as province or status split data are configured as follows:
<tableRule name="sharding-by-intfile"> <rule> <columns>status</columns> <algorithm>hash-int</algorithm> </rule> </tableRule> <function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"> <property name="mapFile">partition-hash-int.txt</property> <property name="type">0</property> <property name="defaultNode">0</property> </function>
partition-hash-int.txt, as follows:
1=0 2=1 3=2
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| type | The default value is 0; 0 represents integer and 1 represents String |
| defaultNode | Default node; Less than 0 indicates that the default node is not set, and greater than or equal to 0 indicates that the default node is set; Use of default node: when enumerating fragments, if an unrecognized enumeration value is encountered, it will be routed to the default node; If there is no default value, an error will be reported if an unrecognized value is encountered. |
Test:
to configure
<table name="tb_user" dataNode="dn1,dn2,dn3" rule="sharding-by-enum-status"/>
data
1). Create table CREATE TABLE `tb_user` ( id bigint(20) NOT NULL COMMENT 'ID', username varchar(200) DEFAULT NULL COMMENT 'full name', status int(2) DEFAULT '1' COMMENT '1: not enabled, 2: Enabled, 3: Closed', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_user (id,username ,status) values(1,'Tom',1); insert into tb_user (id,username ,status) values(2,'Cat',2); insert into tb_user (id,username ,status) values(3,'Rose',3); insert into tb_user (id,username ,status) values(4,'Coco',2); insert into tb_user (id,username ,status) values(5,'Lily',1);
4, Range modulus algorithm
The algorithm first divides the range, calculates the partition group, and then calculates the module in the group.
Advantages: it combines the advantages of range partition and modulus partition. The use of modulus in the slice group can ensure that the data distribution in the group is relatively uniform, and the use of range slice between slice groups can take into account the characteristics of range slice.
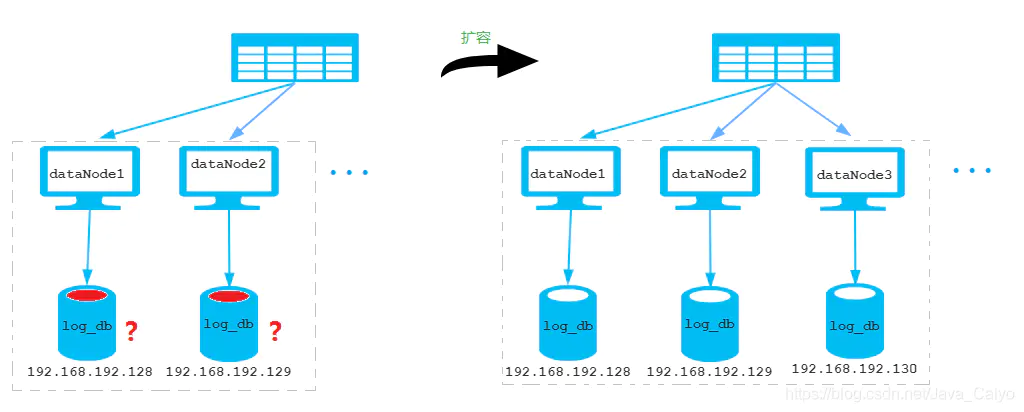
Disadvantages: when the data range is a fixed value (non incremental value), it is inconvenient to expand, for example dataNode Group size When expanding from 2 to 4, data migration is required to complete; As shown in the figure:
The configuration is as follows:
<tableRule name="auto-sharding-rang-mod"> <rule> <columns>id</columns> <algorithm>rang-mod</algorithm> </rule> </tableRule> <function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod"> <property name="mapFile">autopartition-range-mod.txt</property> <property name="defaultNode">0</property> </function>
autopartition-range-mod.txt configuration format:
#range start-end , data node group size 0-500M=1 500M1-2000M=2
In the above configuration file, the range before the equal sign represents a slice group, and the number after the equal sign represents the number of slices owned by the slice group;
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the name of the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| defaultNode | Default node; Data that does not contain the above rules is stored in the defaultNode node, which starts from 0 |
Test:
to configure
<table name="tb_stu" dataNode="dn1,dn2,dn3" rule="auto-sharding-rang-mod"/>
data
1). Create table CREATE TABLE `tb_stu` ( id bigint(20) NOT NULL COMMENT 'ID', username varchar(200) DEFAULT NULL COMMENT 'full name', status int(2) DEFAULT '1' COMMENT '1: not enabled, 2: Enabled, 3: Closed', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_stu (id,username ,status) values(1,'Tom',1); insert into tb_stu (id,username ,status) values(2,'Cat',2); insert into tb_stu (id,username ,status) values(3,'Rose',3); insert into tb_stu (id,username ,status) values(4,'Coco',2); insert into tb_stu (id,username ,status) values(5,'Lily',1); insert into tb_stu (id,username ,status) values(5000001,'Roce',1); insert into tb_stu (id,username ,status) values(5000002,'Jexi',2); insert into tb_stu (id,username ,status) values(5000003,'Mini',1);
5, Fixed fragment hash algorithm
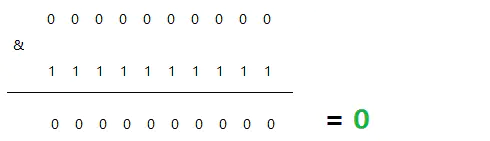
The algorithm is similar to the decimal modular operation, but it is a binary operation. For ex amp le, take the binary lower 10 bits of id and 1111 Bit & operation.
Minimum:
Maximum:
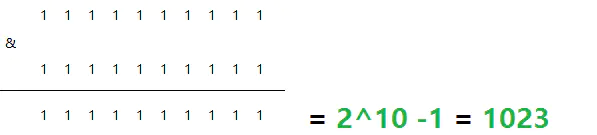
Advantages: this strategy is flexible and can be evenly or unevenly distributed. The allocation proportion and capacity of each node are determined by partitionCount and partitionLength Two parameters determine
Disadvantages: it is similar to taking mold and slicing.
The configuration is as follows:
<tableRule name="sharding-by-long-hash"> <rule> <columns>id</columns> <algorithm>func1</algorithm> </rule> </tableRule> <function name="func1" class="org.opencloudb.route.function.PartitionByLong"> <property name="partitionCount">2,1</property> <property name="partitionLength">256,512</property> </function>
The fragmentation strategy configured in the example wants to divide the data level into three parts, with the first two accounting for 25% and the third accounting for 50%.
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the name of the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| partitionCount | List of pieces |
| partitionLength | Slice range list |
Constraints:
- Slice length: the default maximum is 2 ^ 10, 1024;
- The array length of count and length must be consistent;
- Correspondence of two groups of data: (partitionCount[0]partitionLength[0])= (partitionCount[1]partitionLength[1])
The above is divided into three zones: 0-255,256-511,512-1023
Test:
to configure
<table name="tb_brand" dataNode="dn1,dn2,dn3" rule="sharding-by-long-hash"/>
data
1). Create table CREATE TABLE `tb_brand` ( id int(11) NOT NULL COMMENT 'ID', name varchar(200) DEFAULT NULL COMMENT 'name', firstChar char(1) COMMENT 'Initials', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_brand (id,name ,firstChar) values(1,'Seven wolves','Q'); insert into tb_brand (id,name ,firstChar) values(529,'Eight wolves','B');insert into tb_brand (id,name ,firstChar) values(1203,'Nine wolves','J'); insert into tb_brand (id,name ,firstChar) values(1205,'Ten wolves','S'); insert into tb_brand (id,name ,firstChar) values(1719,'Six wolves','L');
6, Modular Range Algorithm
The algorithm first takes the module, and then divides it according to the range of the module value.
Advantages: it can independently determine the node distribution of data after modeling
Disadvantages: the dataNode partition node is built in advance, which is troublesome when it needs to be expanded.
The configuration is as follows:
<tableRule name="sharding-by-pattern"> <rule> <columns>id</columns> <algorithm>sharding-by-pattern</algorithm> </rule> </tableRule> <function name="sharding-by-pattern" class="io.mycat.route.function.PartitionByPattern"> <property name="mapFile">partition-pattern.txt</property> <property name="defaultNode">0</property> <property name="patternValue">96</property> </function>
partition-pattern.txt is configured as follows:
0-32=0 33-64=1 65-96=2
In the mapFile configuration file, 1-32 represents the distribution after id%96. If it is 1-32, it is on slice 0; If 33-64, on slice 1; If 65-96, on slice 2.
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| defaultNode | Default node; If the id is not a number and cannot be modulo, it will be assigned to the defaultNode |
| patternValue | Modular cardinality |
Test:
to configure
<table name="tb_mod_range" dataNode="dn1,dn2,dn3" rule="sharding-by-pattern"/>
data
1). Create table CREATE TABLE `tb_mod_range` ( id int(11) NOT NULL COMMENT 'ID', name varchar(200) DEFAULT NULL COMMENT 'name', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_mod_range (id,name) values(1,'Test1'); insert into tb_mod_range (id,name) values(2,'Test2'); insert into tb_mod_range (id,name) values(3,'Test3'); insert into tb_mod_range (id,name) values(4,'Test4'); insert into tb_mod_range (id,name) values(5,'Test5');
Note: the modulo range algorithm can only perform modulo operations for digital types; If it is a string, the module cannot be taken and divided;
7, Modular Range Algorithm for string hash
Similar to the modulus range algorithm, the algorithm supports Values Symbols For letter mold taking, first intercept the length of prefixLength Substring of, in pairs of each character in the substring The ASCII code is summed, and then the sum value is evaluated Modular operation( sum%patternValue), you can calculate the number of slices of the substring.
Advantages: it can independently determine the node distribution of data after modeling
Disadvantages: the 'dataNode' partition node is built in advance, which is troublesome when it needs to be expanded.
The configuration is as follows:
<tableRule name="sharding-by-prefixpattern"> <rule> <columns>id</columns> <algorithm>sharding-by-prefixpattern</algorithm> </rule> </tableRule> <function name="sharding-by-prefixpattern" class="io.mycat.route.function.PartitionByPrefixPattern"> <property name="mapFile">partition-prefixpattern.txt</property> <property name="prefixLength">5</property> <property name="patternValue">96</property> </function>
partition-prefixpattern.txt is configured as follows:
# range start-end ,data node index # ASCII # 48-57=0-9 # 64,65-90=@,A-Z # 97-122=a-z ###### first host configuration 0-32=0 33-64=1 65-96=2
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| prefixLength | Number of bits intercepted; Obtain the sum of all ASCII codes in the first prefixLength bit in this field, and calculate the modulus sum%patternValue. The obtained value is the number of slices within the general distribution range; |
| patternValue | Modular cardinality |
For example:
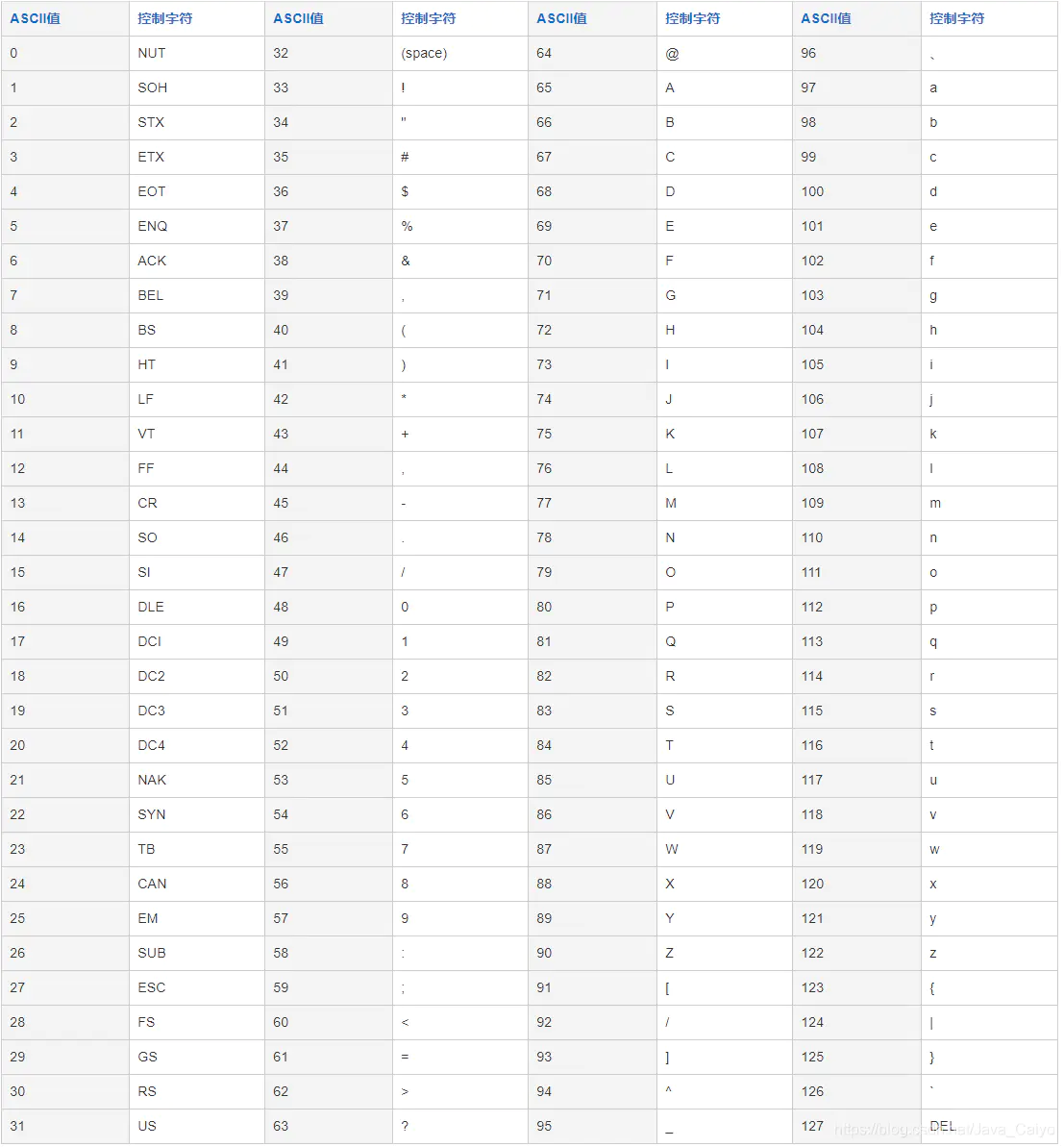
character string : gf89f9a Intercept the first 5 bits of the string ASCII Cumulative operation of : g - 103 f - 102 8 - 56 9 - 57 f - 102 sum Sum : 103 + 102 + + 56 + 57 + 102 = 420 Seeking module : 420 % 96 = 36
appendix ASCII code table :
Test:
to configure
<table name="tb_u" dataNode="dn1,dn2,dn3" rule="sharding-by-prefixpattern"/>
data
1). Create table
CREATE TABLE `tb_u` (
username varchar(50) NOT NULL COMMENT 'user name',
age int(11) default 0 COMMENT 'Age',
PRIMARY KEY (`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2). insert data
insert into tb_u (username,age) values('Test100001',18); insert into tb_u (username,age) values('Test200001',20); insert into tb_u (username,age) values('Test300001',19); insert into tb_u (username,age) values('Test400001',25); insert into tb_u (username,age) values('Test500001',22);
The slicing rules of MyCat are configured in conf directory Defined in rule.xml file;
Environmental preparation:
- Back up the contents in schema.xml and configure it Logical library;
<schema name="PARTITION_DB" checkSQLschema="false" sqlMaxLimit="100"> <table name="" dataNode="dn1,dn2,dn3" rule=""/> </schema> <dataNode name="dn1" dataHost="host1" database="partition_db" /> <dataNode name="dn2" dataHost="host2" database="partition_db" /> <dataNode name="dn3" dataHost="host3" database="partition_db" /> <dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.192.157:3306" user="root" password="itcast"></writeHost> </dataHost> <dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM2" url="192.168.192.158:3306" user="root" password="itcast"></writeHost> </dataHost> <dataHost name="host3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM3" url="192.168.192.159:3306" user="root" password="itcast"></writeHost> </dataHost>
- In the database of three nodes of MySQL, create database partition_db
create database partition_db DEFAULT CHARACTER SET utf8mb4;
1, Take mold and slice
<tableRule name="mod-long"> <rule> <columns>id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule> <function name="mod-long" class="io.mycat.route.function.PartitionByMod"> <property name="count">3</property> </function>
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| count | Number of data nodes |
2, Range slicing
The partition to which the data belongs is determined according to the correspondence between the specified field and its configured range and the data node. The configuration is as follows:
<tableRule name="auto-sharding-long"> <rule> <columns>id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule> <function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> <property name="defaultNode">0</property> </function>
autopartition-long.txt The configuration is as follows:
# range start-end ,data node index # K=1000,M=10000. 0-500M=0 500M-1000M=1 1000M-1500M=2
Meaning: value between 0 and 5 million, stored in data node 0; The data between 5 million and 10 million is stored in No. 1 data node; 10-15 million data nodes are stored in node 2;
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| type | The default value is 0; 0 represents integer and 1 represents String |
| defaultNode | The default node is used by the default node: when enumerating fragments, if an unrecognized enumeration value is encountered, it will be routed to the default node; If there is no default value, an error will be reported if an unrecognized value is encountered. |
Test:
to configure
<table name="tb_log" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"/>
data
1). Create table CREATE TABLE `tb_log` ( id bigint(20) NOT NULL COMMENT 'ID', operateuser varchar(200) DEFAULT NULL COMMENT 'full name', operation int(2) DEFAULT NULL COMMENT '1: insert, 2: delete, 3: update , 4: select', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_log (id,operateuser ,operation) values(1,'Tom',1); insert into tb_log (id,operateuser ,operation) values(2,'Cat',2); insert into tb_log (id,operateuser ,operation) values(3,'Rose',3); insert into tb_log (id,operateuser ,operation) values(4,'Coco',2); insert into tb_log (id,operateuser ,operation) values(5,'Lily',1);
3, Enumeration fragmentation
By configuring possible enumeration values in the configuration file, the specified data is distributed to different data nodes. This rule applies to Businesses such as province or status split data are configured as follows:
<tableRule name="sharding-by-intfile"> <rule> <columns>status</columns> <algorithm>hash-int</algorithm> </rule> </tableRule> <function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"> <property name="mapFile">partition-hash-int.txt</property> <property name="type">0</property> <property name="defaultNode">0</property> </function>
partition-hash-int.txt, as follows:
1=0 2=1 3=2
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| type | The default value is 0; 0 represents integer and 1 represents String |
| defaultNode | Default node; Less than 0 indicates that the default node is not set, and greater than or equal to 0 indicates that the default node is set; Use of default node: when enumerating fragments, if an unrecognized enumeration value is encountered, it will be routed to the default node; If there is no default value, an error will be reported if an unrecognized value is encountered. |
Test:
to configure
<table name="tb_user" dataNode="dn1,dn2,dn3" rule="sharding-by-enum-status"/>
data
1). Create table CREATE TABLE `tb_user` ( id bigint(20) NOT NULL COMMENT 'ID', username varchar(200) DEFAULT NULL COMMENT 'full name', status int(2) DEFAULT '1' COMMENT '1: not enabled, 2: Enabled, 3: Closed', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_user (id,username ,status) values(1,'Tom',1); insert into tb_user (id,username ,status) values(2,'Cat',2); insert into tb_user (id,username ,status) values(3,'Rose',3); insert into tb_user (id,username ,status) values(4,'Coco',2); insert into tb_user (id,username ,status) values(5,'Lily',1);
4, Range modulus algorithm
The algorithm first divides the range, calculates the partition group, and then calculates the module in the group.
Advantages: it combines the advantages of range partition and modulus partition. The use of modulus in the slice group can ensure that the data distribution in the group is relatively uniform, and the use of range slice between slice groups can take into account the characteristics of range slice.
Disadvantages: when the data range is a fixed value (non incremental value), it is inconvenient to expand, for example dataNode Group size When expanding from 2 to 4, data migration is required to complete; As shown in the figure:
The configuration is as follows:
<tableRule name="auto-sharding-rang-mod"> <rule> <columns>id</columns> <algorithm>rang-mod</algorithm> </rule> </tableRule> <function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod"> <property name="mapFile">autopartition-range-mod.txt</property> <property name="defaultNode">0</property> </function>
autopartition-range-mod.txt configuration format:
#range start-end , data node group size 0-500M=1 500M1-2000M=2
In the above configuration file, the range before the equal sign represents a slice group, and the number after the equal sign represents the number of slices owned by the slice group;
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the name of the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| defaultNode | Default node; Data that does not contain the above rules is stored in the defaultNode node, which starts from 0 |
Test:
to configure
<table name="tb_stu" dataNode="dn1,dn2,dn3" rule="auto-sharding-rang-mod"/>
data
1). Create table CREATE TABLE `tb_stu` ( id bigint(20) NOT NULL COMMENT 'ID', username varchar(200) DEFAULT NULL COMMENT 'full name', status int(2) DEFAULT '1' COMMENT '1: not enabled, 2: Enabled, 3: Closed', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_stu (id,username ,status) values(1,'Tom',1); insert into tb_stu (id,username ,status) values(2,'Cat',2); insert into tb_stu (id,username ,status) values(3,'Rose',3); insert into tb_stu (id,username ,status) values(4,'Coco',2); insert into tb_stu (id,username ,status) values(5,'Lily',1); insert into tb_stu (id,username ,status) values(5000001,'Roce',1); insert into tb_stu (id,username ,status) values(5000002,'Jexi',2); insert into tb_stu (id,username ,status) values(5000003,'Mini',1);
5, Fixed fragment hash algorithm
The algorithm is similar to the decimal modular operation, but it is a binary operation. For ex amp le, take the binary lower 10 bits of id and 1111 Bit & operation.
Minimum:
Maximum:
Advantages: this strategy is flexible and can be evenly or unevenly distributed. The allocation proportion and capacity of each node are determined by partitionCount and partitionLength Two parameters determine
Disadvantages: it is similar to taking mold and slicing.
The configuration is as follows:
<tableRule name="sharding-by-long-hash"> <rule> <columns>id</columns> <algorithm>func1</algorithm> </rule> </tableRule> <function name="func1" class="org.opencloudb.route.function.PartitionByLong"> <property name="partitionCount">2,1</property> <property name="partitionLength">256,512</property> </function>
The fragmentation strategy configured in the example wants to divide the data level into three parts, with the first two accounting for 25% and the third accounting for 50%.
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the name of the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| partitionCount | List of pieces |
| partitionLength | Slice range list |
Constraints:
- Slice length: the default maximum is 2 ^ 10, 1024;
- The array length of count and length must be consistent;
- Correspondence of two groups of data: (partitionCount[0]partitionLength[0])= (partitionCount[1]partitionLength[1])
The above is divided into three zones: 0-255,256-511,512-1023
Test:
to configure
<table name="tb_brand" dataNode="dn1,dn2,dn3" rule="sharding-by-long-hash"/>
data
1). Create table CREATE TABLE `tb_brand` ( id int(11) NOT NULL COMMENT 'ID', name varchar(200) DEFAULT NULL COMMENT 'name', firstChar char(1) COMMENT 'Initials', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_brand (id,name ,firstChar) values(1,'Seven wolves','Q'); insert into tb_brand (id,name ,firstChar) values(529,'Eight wolves','B');insert into tb_brand (id,name ,firstChar) values(1203,'Nine wolves','J'); insert into tb_brand (id,name ,firstChar) values(1205,'Ten wolves','S'); insert into tb_brand (id,name ,firstChar) values(1719,'Six wolves','L');
6, Modular Range Algorithm
The algorithm first takes the module, and then divides it according to the range of the module value.
Advantages: it can independently determine the node distribution of data after modeling
Disadvantages: the dataNode partition node is built in advance, which is troublesome when it needs to be expanded.
The configuration is as follows:
<tableRule name="sharding-by-pattern"> <rule> <columns>id</columns> <algorithm>sharding-by-pattern</algorithm> </rule> </tableRule> <function name="sharding-by-pattern" class="io.mycat.route.function.PartitionByPattern"> <property name="mapFile">partition-pattern.txt</property> <property name="defaultNode">0</property> <property name="patternValue">96</property> </function>
partition-pattern.txt is configured as follows:
0-32=0 33-64=1 65-96=2
In the mapFile configuration file, 1-32 represents the distribution after id%96. If it is 1-32, it is on slice 0; If 33-64, on slice 1; If 65-96, on slice 2.
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| defaultNode | Default node; If the id is not a number and cannot be modulo, it will be assigned to the defaultNode |
| patternValue | Modular cardinality |
Test:
to configure
<table name="tb_mod_range" dataNode="dn1,dn2,dn3" rule="sharding-by-pattern"/>
data
1). Create table CREATE TABLE `tb_mod_range` ( id int(11) NOT NULL COMMENT 'ID', name varchar(200) DEFAULT NULL COMMENT 'name', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2). insert data insert into tb_mod_range (id,name) values(1,'Test1'); insert into tb_mod_range (id,name) values(2,'Test2'); insert into tb_mod_range (id,name) values(3,'Test3'); insert into tb_mod_range (id,name) values(4,'Test4'); insert into tb_mod_range (id,name) values(5,'Test5');
Note: the modulo range algorithm can only perform modulo operations for digital types; If it is a string, the module cannot be taken and divided;
7, Modular Range Algorithm for string hash
Similar to the modulus range algorithm, the algorithm supports Values Symbols For letter mold taking, first intercept the length of prefixLength Substring of, in pairs of each character in the substring The ASCII code is summed, and then the sum value is evaluated Modular operation( sum%patternValue), you can calculate the number of slices of the substring.
Advantages: it can independently determine the node distribution of data after modeling
Disadvantages: the 'dataNode' partition node is built in advance, which is troublesome when it needs to be expanded.
The configuration is as follows:
<tableRule name="sharding-by-prefixpattern"> <rule> <columns>id</columns> <algorithm>sharding-by-prefixpattern</algorithm> </rule> </tableRule> <function name="sharding-by-prefixpattern" class="io.mycat.route.function.PartitionByPrefixPattern"> <property name="mapFile">partition-prefixpattern.txt</property> <property name="prefixLength">5</property> <property name="patternValue">96</property> </function>
partition-prefixpattern.txt is configured as follows:
# range start-end ,data node index # ASCII # 48-57=0-9 # 64,65-90=@,A-Z # 97-122=a-z ###### first host configuration 0-32=0 33-64=1 65-96=2
Configuration Description:
| attribute | describe |
|---|---|
| columns | Identifies the table field to be fragmented |
| algorithm | Specify the corresponding relationship between slicing function and function |
| class | Specify the class corresponding to the sharding algorithm |
| mapFile | Corresponding external profile |
| prefixLength | Number of bits intercepted; Obtain the sum of all ASCII codes in the first prefixLength bit in this field, and calculate the modulus sum%patternValue. The obtained value is the number of slices within the general distribution range; |
| patternValue | Modular cardinality |
For example:
character string : gf89f9a Intercept the first 5 bits of the string ASCII Cumulative operation of : g - 103 f - 102 8 - 56 9 - 57 f - 102 sum Sum : 103 + 102 + + 56 + 57 + 102 = 420 Seeking module : 420 % 96 = 36
appendix ASCII code table :
Test:
to configure
<table name="tb_u" dataNode="dn1,dn2,dn3" rule="sharding-by-prefixpattern"/>
data
1). Create table
CREATE TABLE `tb_u` (
username varchar(50) NOT NULL COMMENT 'user name',
age int(11) default 0 COMMENT 'Age',
PRIMARY KEY (`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2). insert data
insert into tb_u (username,age) values('Test100001',18); insert into tb_u (username,age) values('Test200001',20); insert into tb_u (username,age) values('Test300001',19); insert into tb_u (username,age) values('Test400001',25); insert into tb_u (username,age) values('Test500001',22);