Puppeteer It is a node released by the chrome development team in 2017 JS package, as well as Headless Chrome. Used to simulate the operation of Chrome browser. It provides an advanced API to control Headless Chrome or Chromium through the DevTools protocol. It can also be configured to use full (non headless) chrome or Chromium.
Before learning about puppeter, let's have a look Chrome DevTool Protocol and Headless Chrome.
What is the Chrome DevTool Protocol
- CDP is based on WebSocket and uses WebSocket to realize fast data channel with browser kernel.
- CDP is divided into multiple domains (DOM, Debugger, Network, Profiler, Console...), Related Commands and Events are defined in each domain.
- We can package some tools based on CDP to debug and analyze Chrome browser. For example, our commonly used "Chrome developer tool" is implemented based on CDP.
- Many useful tools are implemented based on CDP, such as Chrome developer tools,chrome-remote-interface,Puppeteer Wait.
What is Headless Chrome
- You can run Chrome in an interface free environment.
- Operate Chrome through the command line or program language.
- Without human intervention, the operation is more stable.
- When starting Chrome, add the parameter -- headless to start Chrome in headless mode.
- What parameters can be added when chrome starts? You can click here see.
In a word, Headless Chrome is the non interface form of Chrome browser. You can run your program using all the features supported by chrome without opening the browser.
What is a puppeter
- The puppeter is a node JS tool engine.
- Puppeter provides a series of API s to control the behavior of Chromium/Chrome browser through Chrome DevTools Protocol.
- By default, puppeter starts Chrome with headless. You can also start Chrome with interface through parameter control.
- Puppeter is bound to the latest Chromium version by default. You can also set the binding of different versions yourself.
- Puppeter allows us to realize the communication with the browser without knowing too much about the underlying CDP protocol.
What can puppeter do
Official introduction: most of the operations you can manually perform in the browser can be completed with puppeter! Example:
- Generate screenshots and PDF s of the page.
- Crawl to SPA or SSR website.
- Automated form submission, UI testing, keyboard input, etc.
- Create the latest automated test environment. Use the latest JavaScript and browser functions to run tests directly in the latest version of Chrome.
- Capture the timeline trace of the site to help diagnose performance problems.
- Test the Chrome extension.
- ...
Puppeter API hierarchy
The API hierarchy in puppeter is basically consistent with that of browser. The following describes several commonly used classes:
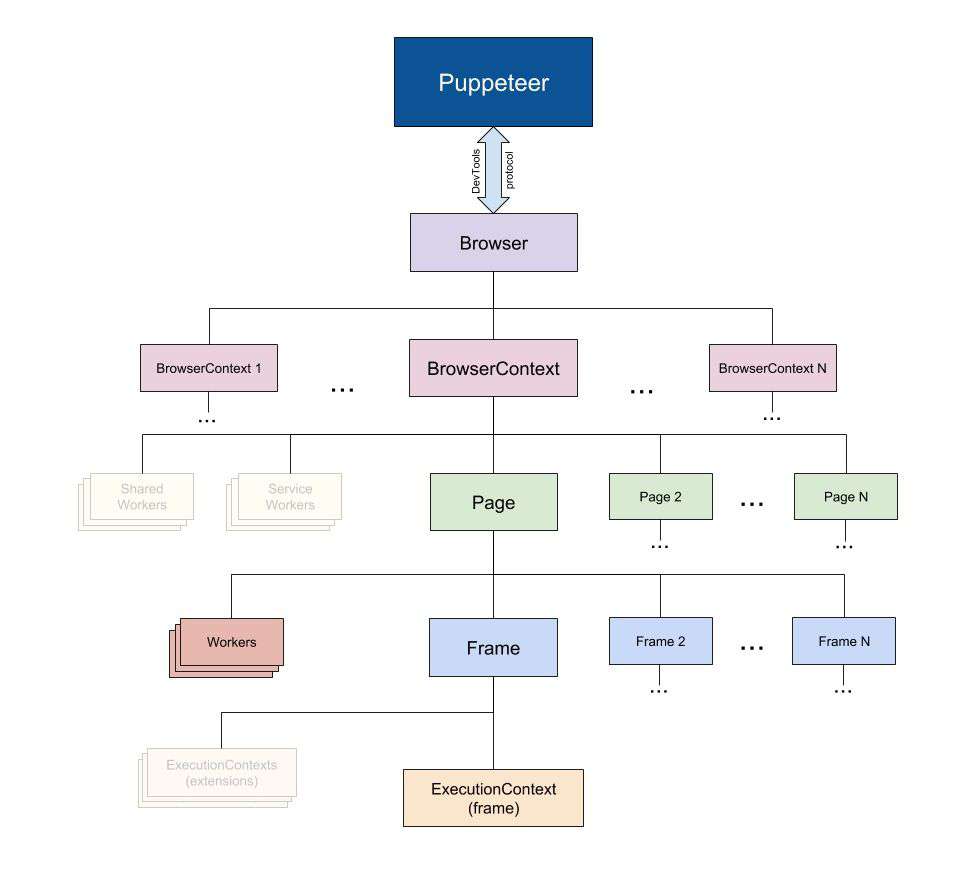
- Browser: corresponding to a browser instance, a browser can contain multiple browsercontexts
- BrowserContext: a context session corresponding to the browser. Just like a browser in stealth mode after opening an ordinary Chrome, BrowserContext has an independent session (cookies and cache s are not shared independently). A BrowserContext can contain multiple pages
- Page: represents a Tab page through BrowserContext newPage()/browser.newPage(), browser Newpage() will use the default BrowserContext when creating a page. A page can contain multiple frames
- Frame: a frame. Each page has a main frame (page. Main frame ()), or multiple sub frames, which are mainly created by iframe tags
- ExecutionContext: it is the execution environment of javascript. Each Frame has a default javascript execution environment
- ElementHandle: an element node corresponding to DOM. Through this instance, we can click on the element and fill in the form. We can get the corresponding element through selector, xPath, etc
- JsHandle: corresponds to the javascript object in the dom. ElementHandle inherits from JsHandle. Since we cannot directly operate the object in the DOM, it is encapsulated into JsHandle to realize relevant functions
- CDPSession: it can communicate directly with the native CDP through session The send function sends a message directly through session On receives messages, which can realize functions not involved in the puppeter API
- Coverage: get JavaScript and CSS code coverage
- Tracing: grab performance data for analysis
- Response: the response received by the page
- Request: the request sent by the page
Puppeter installation and environment
Note: in V1 Before 18.1, the puppeter needs at least node V6 4.0. From V1 18.1 to v2 Version 1.0 depends on Node 8.9.0 +. From v3 From 0.0, the puppeter starts to rely on Node 10.18.1 +. To use async / await , only node v7 6.0 or later.
The puppeter is a node JS package, so the installation is simple:
npm install puppeteer // perhaps yarn add puppeteer
npm may report an error when installing the puppeter! This is caused by the Internet. You can visit foreign websites or install cnpm using Taobao image.
When you install puppeter, it will download the latest version of Chromium. Starting from version 1.7.0, the official release of the puppeteer-core Software package. By default, no browser will be downloaded. It is used to start an existing browser or connect to a remote browser. Note that the installed version of puppeter core is compatible with the browser you intend to connect to.
Use of puppeter
Case1: screenshot
Using puppeter, we can take a screenshot of a page or an element in the page:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
//Set the size of the visual area. The default page size is 800x600 resolution
await page.setViewport({width: 1920, height: 800});
await page.goto('https://www.baidu.com/');
//Screenshot of the whole page
await page.screenshot({
path: './files/baidu_home.png', //Picture saving path
type: 'png',
fullPage: true //Screenshot while scrolling
// clip: {x: 0, y: 0, width: 1920, height: 800}
});
//Screenshot of an element of the page
let element = await page.$('#s_lg_img');
await element.screenshot({
path: './files/baidu_logo.png'
});
await page.close();
await browser.close();
})();How do we get an element in the page?
- page.$('#uniqueId'): get the first element corresponding to a selector
- page.$$('div '): get all elements corresponding to a selector
- page.$x('//img'): get all elements corresponding to an xPath
- page.waitForXPath('//img'): wait for an element corresponding to an xPath to appear
- page.waitForSelector('#uniqueId'): wait for the element corresponding to a selector to appear
Case2: simulate user operation
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
slowMo: 100, //Slow down
headless: false, //Turn on Visualization
defaultViewport: {width: 1440, height: 780},
ignoreHTTPSErrors: false, //Ignore https error
args: ['--start-fullscreen'] //Open page in full screen
});
const page = await browser.newPage();
await page.goto('https://www.baidu.com/');
//Enter text
const inputElement = await page.$('#kw');
await inputElement.type('hello word', {delay: 20});
//Click the search button
let okButtonElement = await page.$('#su');
//Wait until the page Jump is completed. Generally, when you click a button to jump, you need to wait for page The jump is successful only when waitfornavigation() is completed
await Promise.all([
okButtonElement.click(),
page.waitForNavigation()
]);
await page.close();
await browser.close();
})();So what functions are provided by ElementHandle to operate elements?
- elementHandle.click(): click an element
- elementHandle.tap(): simulate finger touch and click
- elementHandle.focus(): focus on an element
- elementHandle.hover(): hover the mouse over an element
- elementHandle.type('hello '): enter text in the input box
Case3: embedding javascript code
The most powerful function of puppeter is that you can execute any javascript code you want to run in the browser. The following code is an example of Baidu home page news recommendation crawling data.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.baidu.com/');
//Through page Evaluate executes code in the browser
const resultData = await page.evaluate(async () => {
let data = {};
const ListEle = [...document.querySelectorAll('#hotsearch-content-wrapper .hotsearch-item')];
data = ListEle.map((ele) => {
const urlEle = ele.querySelector('a.c-link');
const titleEle = ele.querySelector('.title-content-title');
return {
href: urlEle.href,
title: titleEle.innerText,
};
});
return data;
});
console.log(resultData)
await page.close();
await browser.close();
})();What functions can execute code in a browser environment?
- page. Evaluate (pagefunction [,... Args]): execute the function in the browser environment
- page. Evaluatehandle (pagefunction [,... Args]): execute the function in the browser environment and return the JsHandle object
- page.$$ Eval (selector, pagefunction [,... Args]): pass all elements corresponding to the selector into the function and execute it in the browser environment
- page.$ Eval (selector, pagefunction [,... Args]): pass the first element corresponding to the selector into the function and execute it in the browser environment
- page. Evaluate on new Document (pagefunction [,... Args]): when creating a new Document, it will be executed in the browser environment before all scripts on the page are executed
- page.exposeFunction(name, puppeteerFunction): register a function on the window object, which is executed in the Node environment, and has the opportunity to call Node. in the browser environment. JS related function library
Case4: request interception
In some scenarios, it is necessary to intercept unnecessary requests to improve performance. We can listen to the request event of Page and intercept the request. The premise is to turn on the request interception Page setRequestInterception(true).
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const blockTypes = new Set(['image', 'media', 'font']);
await page.setRequestInterception(true); //Turn on request interception
page.on('request', request => {
const type = request.resourceType();
const shouldBlock = blockTypes.has(type);
if(shouldBlock){
//Block requests directly
return request.abort();
}else{
//Rewrite request
return request.continue({
//You can override URLs, method s, postData, and headers
headers: Object.assign({}, request.headers(), {
'puppeteer-test': 'true'
})
});
}
});
await page.goto('https://www.baidu.com/');
await page.close();
await browser.close();
})();What events are provided on the page?
- page.on('close ') page closes
- page.on('console') console API called
- page. Error on ('error ') page
- page.on('load ') page loaded
- page.on('request ') received request
- page.on('requestfailed ') request failed
- page.on('requestfinished ') request succeeded
- page.on('response ') received a response
- page.on('workercreated ') create webWorker
- page.on('workerdestroyed ') destroy webWorker
Case5: get WebSocket response
Currently, puppeter does not provide a native API interface for processing WebSocket s, but we can obtain it through the lower layer Chrome DevTool Protocol (CDP)
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
//Create CDP session
let cdpSession = await page.target().createCDPSession();
//Enable Network debugging and listen for Network related events in Chrome DevTools Protocol
await cdpSession.send('Network.enable');
//Listen to the webSocketFrameReceived event and get the corresponding data
cdpSession.on('Network.webSocketFrameReceived', frame => {
let payloadData = frame.response.payloadData;
if(payloadData.includes('push:query')){
//Parse payloadData and get the data pushed by the server
let res = JSON.parse(payloadData.match(/\{.*\}/)[0]);
if(res.code !== 200){
console.log(`call websocket Interface error:code=${res.code},message=${res.message}`);
}else{
console.log('Get websocket Interface data:', res.result);
}
}
});
await page.goto('https://netease.youdata.163.com/dash/142161/reportExport?pid=700209493');
await page.waitForFunction('window.renderdone', {polling: 20});
await page.close();
await browser.close();
})();Case6: how to grab elements in iframe
A frame contains an Execution Context. We cannot execute functions across frames. There can be multiple frames in a page, mainly generated through iframe tag embedding. Most of the functions on the page are actually page mainFrame(). An abbreviation of XX. Frame is a tree structure. We can use frame Childframes() traverses all frames. If you want to execute the function in other frames, you must obtain the corresponding frame for corresponding processing
The following is an iframe embedded in the login window when logging in to mailbox 188. When we get the iframe and log in with the following code
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false, slowMo: 50});
const page = await browser.newPage();
await page.goto('https://www.188.com');
for (const frame of page.mainFrame().childFrames()){
//Find the iframe corresponding to the login page according to the url
if (frame.url().includes('passport.188.com')){
await frame.type('.dlemail', 'admin@admin.com');
await frame.type('.dlpwd', '123456');
await Promise.all([
frame.click('#dologin'),
page.waitForNavigation()
]);
break;
}
}
await page.close();
await browser.close();
})();Case7: page performance analysis
Puppeter provides a tool for page Performance analysis. At present, the function is still relatively weak, and we can only obtain the data of one page Performance. How to analyze needs our own analysis according to the data, It is said that a major revision will be made in version 2.0: - a browser can only trace once at a time - in devTools' Performance, you can upload the corresponding json file and view the analysis results - we can write a script to parse trace Automatic analysis of the data in json - through tracing, we can get the page loading speed and the execution Performance of the script
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.tracing.start({path: './files/trace.json'});
await page.goto('https://www.google.com');
await page.tracing.stop();
/*
continue analysis from 'trace.json'
*/
browser.close();
})();Case8: file upload and download
In automated testing, we often encounter the need for file upload and download, so how to implement it in puppeter?
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
//Set download path through CDP session
const cdp = await page.target().createCDPSession();
await cdp.send('Page.setDownloadBehavior', {
behavior: 'allow', //Allow all download requests
downloadPath: 'path/to/download' //Set download path
});
//Click the button to trigger the download
await (await page.waitForSelector('#someButton')).click();
//Wait for the file to appear, and judge whether the file appears by rotation
await waitForFile('path/to/download/filename');
//When uploading, the corresponding inputElement must be a < input > element
let inputElement = await page.waitForXPath('//input[@type="file"]');
await inputElement.uploadFile('/path/to/file');
browser.close();
})();Case9: jump to new tab page processing
When clicking a button to jump to a new Tab Page, a new Page will be opened. At this time, how can we get the Page instance corresponding to the changed Page? The created event on the target Browser can be used to monitor the new Page:
let page = await browser.newPage();
await page.goto(url);
let btn = await page.waitForSelector('#btn');
//Before clicking the button, define a Promise in advance to return the Page object of the new tab
const newPagePromise = new Promise(res =>
browser.once('targetcreated',
target => res(target.page())
)
);
await btn.click();
//After clicking the button, wait for the new tab object
let newPage = await newPagePromise;Case10: simulate different devices
Puppeter provides the function of simulating different devices, among which puppeter The configuration information of many devices is defined on the devices object, which mainly includes viewport and userAgent, and then through the function page Simulate to realize the simulation of different devices
const puppeteer = require('puppeteer');
const iPhone = puppeteer.devices['iPhone 6'];
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.emulate(iPhone);
await page.goto('https://www.baidu.com');
await browser.close();
});Performance and optimization
- About shared memory:
Chrome Default use /dev/shm Shared memory, but docker default/dev/shm Only 64 MB,Obviously, it is not enough. There are two ways to solve it: - start-up docker Add parameters when --shm-size=1gb To increase /dev/shm Shared memory, but swarm Not currently supported shm-size parameter - start-up Chrome Add parameter - disable-dev-shm-usage,No use /dev/shm Shared memory
- Try to use the same browser instance to realize cache sharing
- Intercept unnecessary resources by request
- Like opening Chrome by ourselves, too many tab pages are bound to get stuck, so we must effectively control the number of tab pages
- When a Chrome instance starts for a long time, it is inevitable that there will be memory leakage, page crash and other phenomena, so it is necessary to restart the Chrome instance regularly
- In order to speed up performance, turn off unnecessary configurations, such as: - no sandbox (sandbox function), -- Disable extensions (extender), etc
- Try to avoid using page Waiffor (1000), let the program decide by itself, the effect will be better
- Because the Websocket used when connecting to the Chrome instance will cause the problem of Websocket sticky session