Dynamic table is the core concept of Flink Table and SQL API to deal with bounded and unbounded data.
In Flink, a dynamic table is only a logical concept. Instead of storing data, it stores the specific data of the table in an external system (such as database, key value pair storage system, message queue) or file.
Dynamic source and dynamic write can read and write data from external systems. In the following description, dynamic source and dynamic write can be reduced to connector. Next, let's see how to customize the connector.
Code address: https://git.lrting.top/xiaozhch5/flink-table-sql-connectors.git
Overview
In many cases, the implementer does not need to create a new connector from scratch, but wants to modify the existing connector slightly or hook to the existing stack. In other cases, implementers may want to create specialized connectors.
This section is helpful for both use cases. It explains the general architecture of table connectors from pure declarations in the API to run-time code that will be executed on the cluster.
Solid arrows show how objects are converted from one phase to the next during the conversion process.
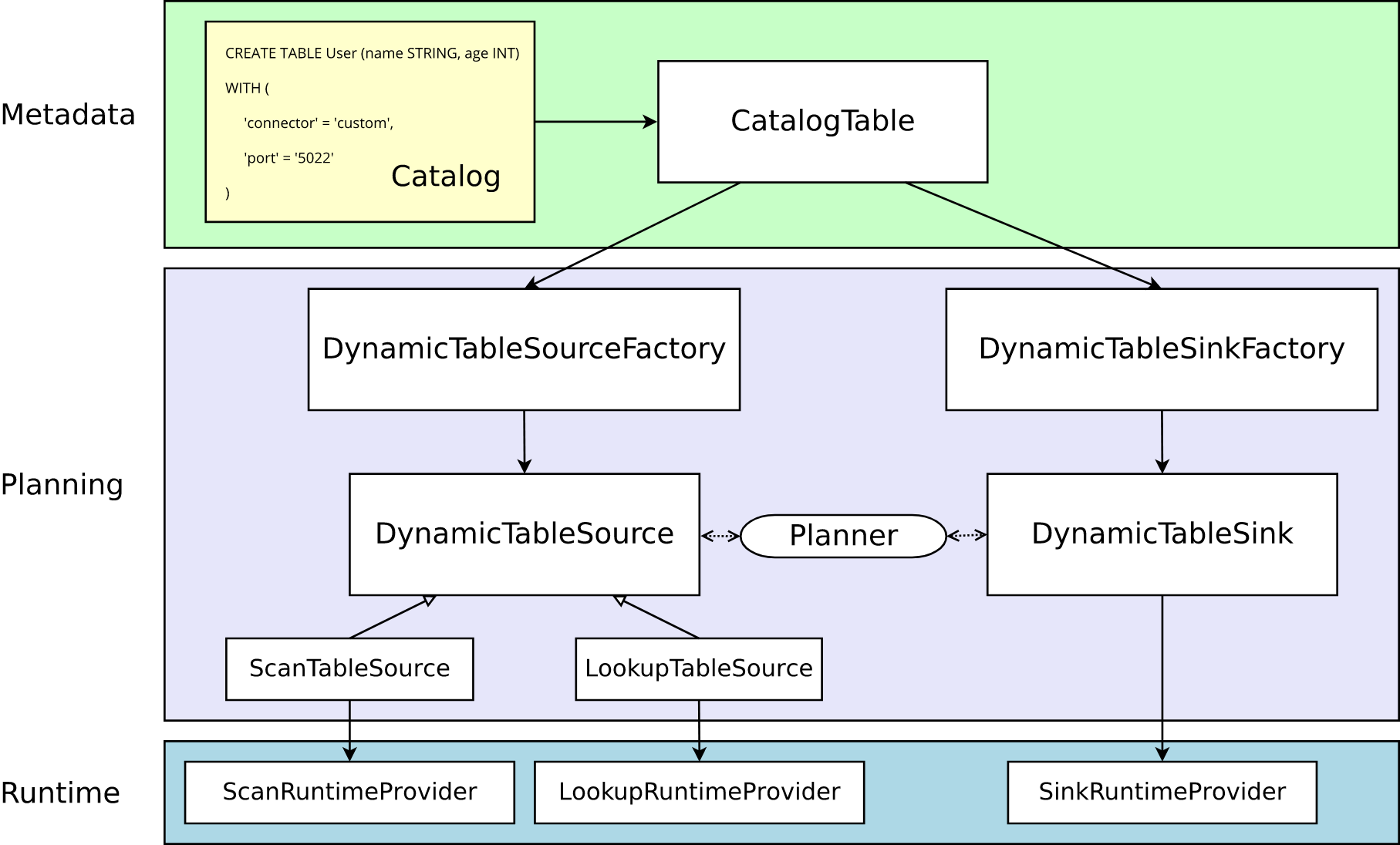
Metadata
Table API and SQL are both declarative APIs. This includes the statement of the table. Therefore, executing the CREATE TABLE statement will cause the metadata in the target directory to be updated.
For most catalog implementations, the physical data in the external system will not be modified for such operations. Connector specific dependencies do not have to exist in the classpath. The options declared in the WITH clause are neither verified nor interpreted.
The metadata of a dynamic table (created by DDL or provided by catalog) is represented as an instance of CatalogTable. If necessary, the table name will be internally resolved to CatalogTable.
Planning
When planning and optimizing a table program, you need to resolve the CatalogTable into DynamicTableSource (for reading in the SELECT query) and DynamicTableSink (for writing in the INSERT INTO statement).
DynamicTableSourceFactory and DynamicTableSink factory provide connector specific logic to convert metadata of CatalogTable into instances of DynamicTableSource and DynamicTableSink. In most cases, the purpose of the factory is to validate options (for example, "port" = "5022" in the example), configure encoding / decoding formats (if required), and create parametric instances of table connectors.
By default, instances of DynamicTableSourceFactory and DynamicTableSinkFactory are discovered using Java's service provider interface (SPI). The connector option (for example, 'connector' = 'custom' in the example) must correspond to a valid factory identifier.
Although it may not be obvious in class naming, DynamicTableSource and DynamicTableSink can also be regarded as stateful factories, which will eventually produce specific runtime implementations to read / write actual data.
The planner uses source and receiver instances to perform connector specific two-way communication until the best logical planning is found. Depending on the optionally declared capability interface (such as SupportsProjectionPushDown or supportsoversite), the planner may apply changes to the instance, thereby changing the generated runtime implementation.
Runtime
Once the logical planning is complete, the planner obtains the runtime implementation from the table connector. Runtime logic is implemented in Flink's core connector interface, such as InputFormat or SourceFunction.
These interfaces are grouped at another level of abstraction into subclasses of ScanRuntimeProvider, LookupRuntimeProvider, and SinkRuntimeProvider.
For example, OutputFormatProvider (org.apache. ORG) flink .api.common.io.OutputFormat) and SinkFunctionProvider (providing org. Apache. Flick. Streaming. API. Functions. Sink. Sinkfunction) are concrete instances of SinkRuntimeProvider, which can be processed by the planner.
Fully custom connectors
In this section, we define a socket connector from scratch.
Runtime defined data source
SocketSourceFunction opens a socket and consumes bytes. It splits records by the given byte delimiter (default \ n) and delegates decoding to the pluggable DeserializationSchema. The source function can only work when the parallelism is 1.
package com.zh.ch.bigdata.flink.connectors.socket;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.ResultTypeQueryable;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.table.data.RowData;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.InetSocketAddress;
import java.net.Socket;
public class SocketSourceFunction extends RichSourceFunction<RowData> implements ResultTypeQueryable<RowData> {
private final String hostname;
private final int port;
private final byte byteDelimiter;
private final DeserializationSchema<RowData> deserializer;
private volatile boolean isRunning = true;
private Socket currentSocket;
public SocketSourceFunction(String hostname, int port, byte byteDelimiter, DeserializationSchema<RowData> deserializer) {
this.hostname = hostname;
this.port = port;
this.byteDelimiter = byteDelimiter;
this.deserializer = deserializer;
}
@Override
public TypeInformation<RowData> getProducedType() {
return deserializer.getProducedType();
}
@Override
public void run(SourceContext<RowData> sourceContext) throws Exception {
while (isRunning) {
// open and consume from socket
try (final Socket socket = new Socket()) {
currentSocket = socket;
socket.connect(new InetSocketAddress(hostname, port), 0);
try (InputStream stream = socket.getInputStream()) {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
int b;
while ((b = stream.read()) >= 0) {
// buffer until delimiter
if (b != byteDelimiter) {
buffer.write(b);
}
// decode and emit record
else {
sourceContext.collect(deserializer.deserialize(buffer.toByteArray()));
buffer.reset();
}
}
}
} catch (Throwable t) {
t.printStackTrace(); // print and continue
}
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
try {
currentSocket.close();
} catch (Throwable t) {
// ignore
}
}
}Table Source and Decoding Format
Next, we define the dynamic table data source
This section explains how to convert from an instance of the planning layer to a runtime instance delivered to the cluster.
SocketDynamicTableSource
SocketDynamicTableSource is used during planning. In our example, we did not implement any available capability interfaces. Therefore, the main logic can be found in getScanRuntimeProvider(...), where we instantiate the required SourceFunction and its deserialization schema for runtime use. Both instances are parameterized to return the internal data structure (that is, RowData).
package com.zh.ch.bigdata.flink.connectors.socket;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.connector.source.ScanTableSource;
import org.apache.flink.table.connector.source.SourceFunctionProvider;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.RowKind;
public class SocketDynamicTableSource implements ScanTableSource {
private final String hostname;
private final int port;
private final byte byteDelimiter;
private final DecodingFormat<DeserializationSchema<RowData>> decodingFormat;
private final DataType producedDataType;
public SocketDynamicTableSource(String hostname,
int port,
byte byteDelimiter,
DecodingFormat<DeserializationSchema<RowData>> decodingFormat,
DataType producedDataType) {
this.hostname = hostname;
this.port = port;
this.byteDelimiter = byteDelimiter;
this.decodingFormat = decodingFormat;
this.producedDataType = producedDataType;
}
@Override
public ChangelogMode getChangelogMode() {
// define that this format can produce INSERT and DELETE rows
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.build();
}
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext scanContext) {
// create runtime classes that are shipped to the cluster
final DeserializationSchema<RowData> deserializer = decodingFormat.createRuntimeDecoder(
scanContext,
producedDataType);
final SourceFunction<RowData> sourceFunction = new SocketSourceFunction(
hostname,
port,
byteDelimiter,
deserializer);
return SourceFunctionProvider.of(sourceFunction, false);
}
@Override
public DynamicTableSource copy() {
return null;
}
@Override
public String asSummaryString() {
return "socket table source";
}
}Factories
Finally, define the dynamic table factory, and define the factory in SocketDynamicTableFactory_ Identifier is socket. SocketDynamicTableFactory converts the catalog table to a table source. Because the table source needs decoding format, for convenience, we use the provided FactoryUtil discovery format.
package com.zh.ch.bigdata.flink.connectors.socket;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DeserializationFormatFactory;
import org.apache.flink.table.factories.DynamicTableSourceFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.types.DataType;
import java.util.HashSet;
import java.util.Set;
public class SocketDynamicTableFactory implements DynamicTableSourceFactory {
private static final String FACTORY_IDENTIFIER = "socket";
public static final ConfigOption<String> HOSTNAME = ConfigOptions.key("hostname")
.stringType()
.noDefaultValue();
public static final ConfigOption<Integer> PORT = ConfigOptions.key("port")
.intType()
.noDefaultValue();
public static final ConfigOption<Integer> BYTE_DELIMITER = ConfigOptions.key("byte-delimiter")
.intType()
.defaultValue(10); // corresponds to '\n'
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// either implement your custom validation logic here ...
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// discover a suitable decoding format
final DecodingFormat<DeserializationSchema<RowData>> decodingFormat = helper.discoverDecodingFormat(
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
// validate all options
helper.validate();
// get the validated options
final ReadableConfig options = helper.getOptions();
final String hostname = options.get(HOSTNAME);
final int port = options.get(PORT);
final byte byteDelimiter = (byte) (int) options.get(BYTE_DELIMITER);
// derive the produced data type (excluding computed columns) from the catalog table
final DataType producedDataType =
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
// create and return dynamic table source
return new SocketDynamicTableSource(hostname, port, byteDelimiter, decodingFormat, producedDataType);
}
@Override
public String factoryIdentifier() {
return FACTORY_IDENTIFIER;
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(HOSTNAME);
options.add(PORT);
options.add(FactoryUtil.FORMAT); // use pre-defined option for format
return options;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(BYTE_DELIMITER);
return options;
}
}At meta-inf / services / org apache. flink. table. factories. Write com. In factory zh. ch.bigdata. flink. connectors. socket. SocketDynamicTableFactory
We will use most of the interfaces mentioned above to enable the following DDL:
CREATE TABLE UserScores (name STRING, score INT) WITH ( 'connector' = 'socket', 'hostname' = 'localhost', 'port' = '9999', 'byte-delimiter' = '10', 'format' = 'csv', 'csv.allow-comments' = 'true', 'csv.ignore-parse-errors' = 'true' );
Because this format supports change log semantics, we can take updates at runtime and create an update view that can continuously evaluate change data:
SELECT name, SUM(score) FROM UserScores GROUP BY name;
Use the following command to fetch data in the terminal:
> nc -lk 9999 Alice,12 Bob,5 Alice,12 Alice,18
Full code address:
https://git.lrting.top/xiaozhch5/flink-table-sql-connectors.git
Extend existing connectors
This section describes the available interfaces for extending Flink's table connector.
Dynamic table factory
The dynamic table factory is used to configure dynamic table connectors for external storage systems based on catalog and session information.
org. apache. flink. table. factories. The dynamictablesourcefactory can be implemented to construct a DynamicTableSource.
org. apache. flink. table. factories. The DynamicTableSink factory can be implemented to construct a DynamicTableSink.
By default, the value of the connector option is used as the factory identifier and Java's service provider interface to discover the factory.
In the JAR file, you can add a reference to the new implementation to the service file:
META-INF/services/org.apache.flink.table.factories.Factory
The framework checks for a single matching factory uniquely identified by the factory identifier and the requested base class, such as DynamicTableSourceFactory.
If necessary, the catalog implementation can bypass the factory discovery process. To do this, the directory needs to return an implementation org apache. flink. table. catalog. An instance of the requested base class in the catalog #getfactory.
Dynamic table source
By definition, a dynamic table can change over time.
When reading a dynamic table, the content can be considered as:
- A change log (limited or unlimited), and all changes will continue to be used until the change log runs out. This is represented by the ScanTableSource interface.
- A constantly changing or very large external table whose contents are usually not fully read, but query a single value when necessary. This is represented by the LookupTableSource interface.
A class can implement both interfaces at the same time. The planner determines their use based on the specified query.
Scan Table Source
ScanTableSource scans all rows from an external storage system at run time.
The scanned rows do not have to contain only inserts, but also updates and deletions. Therefore, the table source can be used to read (limited or unlimited) change logs. The returned change log pattern indicates a set of changes that the scheduler can expect at run time.
For a regular batch scenario, the source can issue a limited insert only row stream.
For conventional streaming schemes, the source can issue an unlimited insert only row stream.
For change data capture (CDC) scenarios, the source can issue bounded or unbounded streams with inserted, updated, and deleted rows.
Table sources can implement more capability interfaces, such as SupportsProjectionPushDown, which may change instances during planning. All capabilities are available at org apache. flink. table. connector. source. The capabilities package is found and listed in the source capabilities table.
The runtime implementation of ScanTableSource must generate internal data structures. Therefore, the record must be in org apache. flink. table. data. Sent as rowdata. The framework provides a runtime converter, so the source can still process common data structures and perform the conversion at the end.
Lookup Table Source
LookupTableSource finds rows of an external storage system through one or more keys at run time.
Compared with ScanTableSource, the source does not have to read the entire table, and can lazily obtain a single value from an external table (which may change constantly) when necessary.
Compared with ScanTableSource, LookupTableSource currently only supports issuing insert only changes.
Further capabilities are not supported. For more information, see org apache. flink. table. connector. source. Documents for lookuptablesource.
The runtime implementation of LookupTableSource is TableFunction or AsyncTableFunction. This function will be called at run time with the value of the given lookup key.
Source Abilities
Interface | Description |
|---|---|
SupportsFilterPushDown | Enables to push down the filter into the DynamicTableSource. For efficiency, a source can push filters further down in order to be close to the actual data generation. |
SupportsLimitPushDown | Enables to push down a limit (the expected maximum number of produced records) into a DynamicTableSource. |
SupportsPartitionPushDown | Enables to pass available partitions to the planner and push down partitions into a DynamicTableSource. During the runtime, the source will only read data from the passed partition list for efficiency. |
SupportsProjectionPushDown | Enables to push down a (possibly nested) projection into a DynamicTableSource. For efficiency, a source can push a projection further down in order to be close to the actual data generation. If the source also implements SupportsReadingMetadata, the source will also read the required metadata only. |
SupportsReadingMetadata | Enables to read metadata columns from a DynamicTableSource. The source is responsible to add the required metadata at the end of the produced rows. This includes potentially forwarding metadata column from contained formats. |
SupportsWatermarkPushDown | Enables to push down a watermark strategy into a DynamicTableSource. The watermark strategy is a builder/factory for timestamp extraction and watermark generation. During the runtime, the watermark generator is located inside the source and is able to generate per-partition watermarks. |
SupportsSourceWatermark | Enables to fully rely on the watermark strategy provided by the ScanTableSource itself. Thus, a CREATE TABLE DDL is able to use SOURCE_WATERMARK() which is a built-in marker function that will be detected by the planner and translated into a call to this interface if available. |
At present, the above interfaces are only applicable to ScanTableSource, not LookupTableSource.
Dynamic table Sink
By definition, a dynamic table can change over time.
When writing a dynamic table, you can always treat the content as a change log (limited or unlimited), in which all changes are written out continuously until the change log runs out. The returned change log mode indicates the change set that the receiver accepts at run time.
For a regular batch scenario, the receiver can accept only inserting rows and writing out bounded streams.
For conventional streaming schemes, the receiver can only accept inserting rows only, and can write unbounded streams.
For change data capture (CDC) scenarios, the receiver can write out bounded or unbounded streams using insert, update, and delete rows.
The table receiver can implement more capability interfaces, such as supportsoversite, which may change the instance during planning. All capabilities are available at org apache. flink. table. connector. sink. The capabilities package is found and listed in the sink capabilities table.
The runtime implementation of DynamicTableSink must use an internal data structure. Therefore, records must be accepted as org apache. flink. table. data. RowData. The framework provides a run-time converter, so the receiver can still work on a common data structure and perform the conversion at the beginning.
Sink Abilities
Interface | Description |
|---|---|
SupportsOverwrite | Enables to overwrite existing data in a DynamicTableSink. By default, if this interface is not implemented, existing tables or partitions cannot be overwritten using e.g. the SQL INSERT OVERWRITE clause. |
SupportsPartitioning | Enables to write partitioned data in a DynamicTableSink. |
SupportsWritingMetadata | Enables to write metadata columns into a DynamicTableSource. A table sink is responsible for accepting requested metadata columns at the end of consumed rows and persist them. This includes potentially forwarding metadata columns to contained formats. |
Encoding / Decoding Formats
Some table connectors accept different formats for encoding and decoding keys and / or values.
The format works like the pattern dynamictablesourcefactory - > dynamictablesource - > scanruntimeprovider, where the factory is responsible for converting options and the source is responsible for creating runtime logic.
Because formats may reside in different modules, they are discovered using a Java service provider interface similar to a table factory. To discover format factories, dynamic table factories search for factories corresponding to factory identifiers and connector specific base classes.
For example, the Kafka table source requires deserialization schema as the runtime interface for the decoding format. Therefore, the Kafka table source factory uses value The value of the format option to discover the DeserializationFormatFactory.
The following format factories are currently supported:
org.apache.flink.table.factories.DeserializationFormatFactory org.apache.flink.table.factories.SerializationFormatFactory
The format factory converts options to EncodingFormat or DecodingFormat. These interfaces are another factory that generates specialized format runtime logic for a given data type.
For example, for a Kafka table source factory, the DeserializationFormatFactory will return an EncodingFormat that can be passed to the Kafka table source.
Reference link: https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sourcessinks/
This article is the original article of "xiaozhch5", a blogger from big data to artificial intelligence. It follows the CC 4.0 BY-SA copyright agreement. Please attach the original source link and this statement for reprint.
Original link: https://lrting.top/backend/3514/