catalogue
1, Fundamentals of database system
1.1.2 SQL language classification
1.1.3 data independence (physical independence, logical independence)
1.2.1 entity, attribute, code (key), entity type, entity set, relation
1.2.2 ER diagram and relationship model
1.2.3.ER to logical structure model
1.3 structure of database system
3. Modify table structure -- DDL
5. Insert, modify and delete data -- DML
3. Data processing function (single line processing function)
5. Multi line processing function (aggregate function or grouping function)
7. Connection query (multi table query)
1. Cartesian product phenomenon
1. SQL language classification
Indexes are classified by storage type: clustered and nonclustered
7, Stored procedures and triggers
1.1 stored procedure classification:
2.1 classification of triggers
2.2 two virtual tables of trigger
1, Fundamentals of database system
1.1 concept
1.1.1 basic cheese
Database DB, database management system DBMS (mysql,oracle,sqlsever...), Structured query language SQL
DBMS->SQL->DB
1.1.2 SQL language classification
1. DQL data query language (select)
2. DML data operation language (add insert, delete and update to table} data)
3. DDL data definition language (operation table structure: add create delete alter)
4. TCL transaction control statement transaction commit transaction rollback
5. DCL data control language (permission)
1.1.3 data independence (physical independence, logical independence)
Physical: the user application is independent of the physical storage of data in the database
Logic: the user application is independent of the logical structure of the data in the database
1.2 conceptual model
1.2.1 entity, attribute, code (key), entity type, entity set, relation
Relational database adopts relational model
1.2.2 ER diagram and relationship model
I Draw ER diagram
1. Rectangular box - solid
2. Ellipse - properties
3. Diamond - indicates contact
II Contact: one to one, one to many, many to many
eg1:
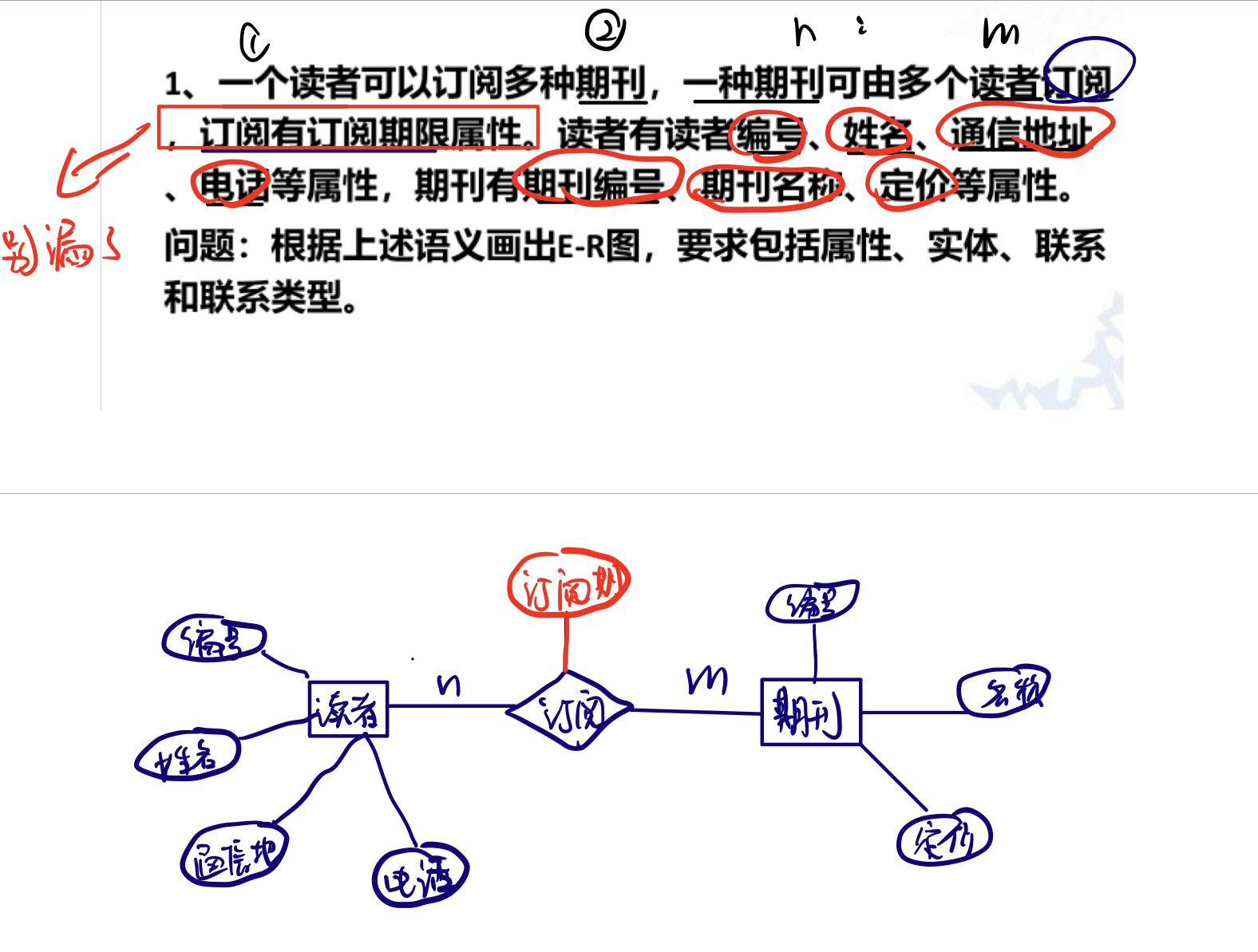
1.2.3.ER to logical structure model
eg2:
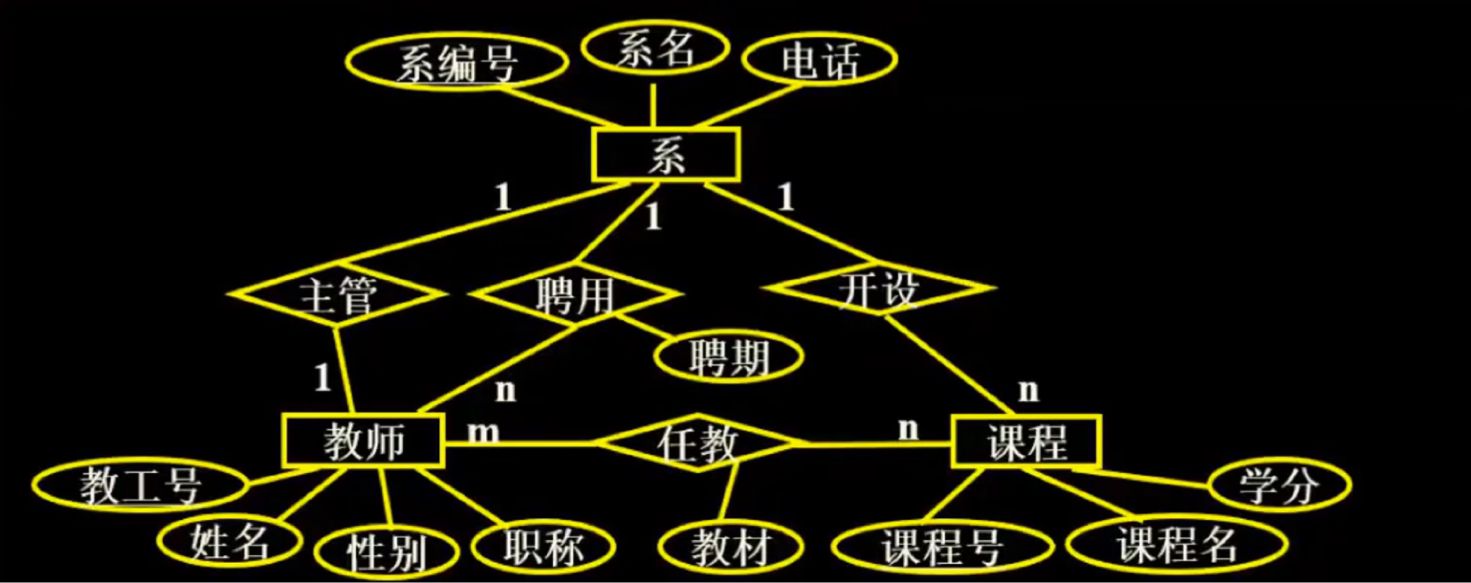
Step 1: convert entity type to relation mode:
Department (department number, department name, telephone)
Teacher (teaching staff number, name, gender, professional title)
Course (course number, course name, credit)
Step 2: Contact Transformation:
(1) 1: 1
Add a primary key to either party
Department (department number, department name, telephone, Faculty number (Department))
(2) 1: n
Add the primary key of 1 in Party n
Teacher (Faculty number, name, gender, professional title, department number)
Course (course number, course name, credit, department number)
(2) n: m
Relation is transformed into relation model - > m PK + n PK + self attribute
Teaching (teaching staff number, course number, teaching demolition)
Therefore, the m:n relationship will generate another relationship:

1.3 structure of database system
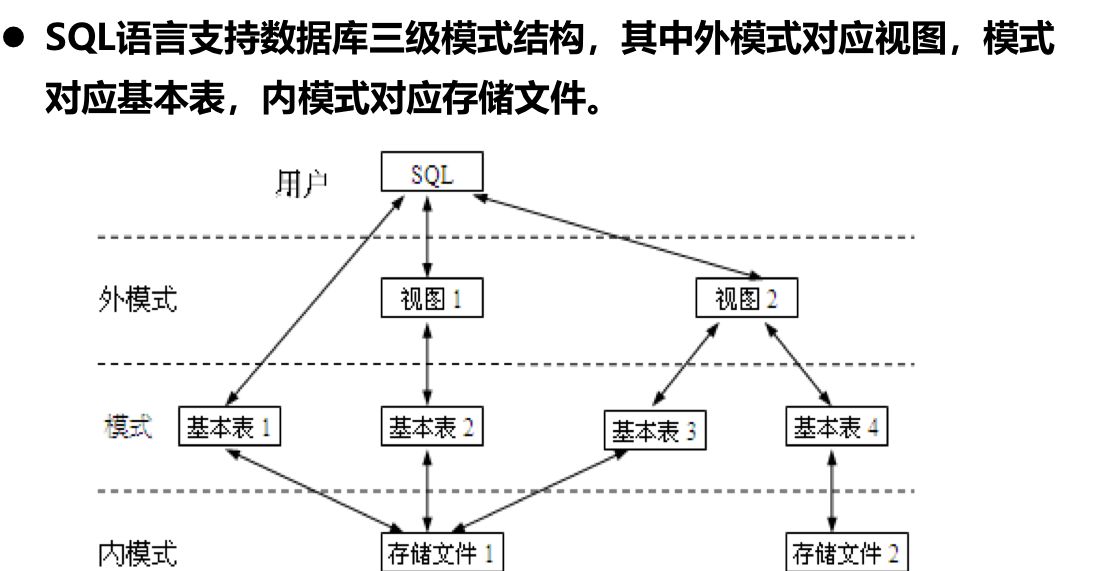
1. External mode: View
2. Mode: basic table
3. Internal mode: storage mode and physical structure of data
2, Relational database
1. Basic cheese
1.1 concept:
1. Candidate code (key): if the value of an attribute group in the relationship can uniquely identify a tuple (a row in the table), but its subset cannot, it becomes the attribute group as a candidate code.
Just like a student table (id, name, age, sex, deptno), id can uniquely identify a tuple, so id can be used as a candidate code. Since id can be used as a candidate code, the combination of id and name can also identify a meta group, so
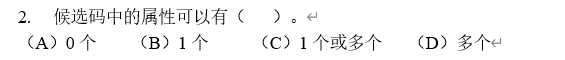
One or more
2. primary key
1.2 relationship integrity
1. Entity integrity: if attribute A is the primary attribute of the basic relationship, A cannot be null (primary key)
2. Referential integrity: master and slave (foreign key)
3, Data definition
1. Data type
(note that the double of mysql is decimal in SQL sever)
2. Create table - DDL
SQL sever
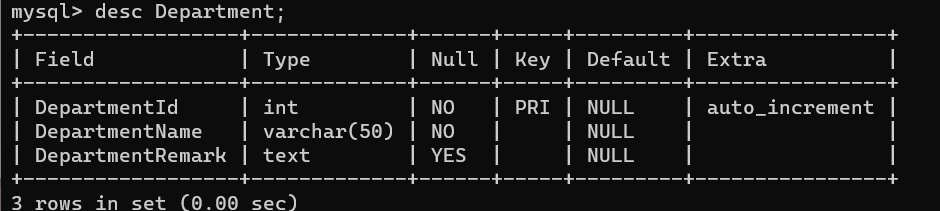
use mydb --Judge whether the table exists drop table if exists Department --Create table (Department, rank, employee) create table Department--department ( --Department number,Primary key,Identification Seed:Automatic growth identity(Initial value, growth step) DepartmentId int primary key identity(1,1), --Department name DepartmentName varchar(50) not null, --Department description DepartmentRemark text )
(auto_increment in mysql indicates that the seed is self increment)
use mydb drop table if exists Department; create table Department ( DepartmentId int primary key auto_increment, DepartmentName varchar(50) not null, DepartmentRemark text );
Similarly, we will create another employee table, PEOPLE and Product
--staff
--staff
create table PEOPLE
(
empno int not null identity,
empid int not null primary key,
ename varchar(10),
job varchar(9),
mgr int,
hiredate date default NULL,
sal decimal(7,2),
comm decimal(7,2),
deptno int foreign key references Department(DepartmentId)
)
--product
create table Product
(
ID int identity(1,1) primary key not null,
prono varchar(50) unique not null,
typeid int foreign key references Department(DepartmentId),
price decimal(18,2) check (price between 100 and 180000) default(100.00) not null,
countpro int
)3. Modify table structure -- DDL
--(1)Add column alter table Department add LOC varchar(50) --(2)Delete column alter table Department drop column DepartmentRemark --(3)Modify column alter table Department alter column DepartmentName varchar(30)
mysql seems to use modify to change the table. Anyway, OvO will hardly appear when changing the table structure. Understand
mysql> alter table Department alter column loc varchar(20);
4. constraint
Primary key constraint (primary key), foreign key constraint (foreign key), unique constraint (unique), check constraint (check)mysql has no check constraint, and the default value constraint (default)
Ensure data integrity = add constraints to the table when creating the table
Classification of integrity:
-
Physical integrity:
primary key constraint
Unique constraint
auto_increment, identity
-
Domain integrity:
Non NULL constraint (not null)
Default value constraint (default)
check constraints
-
Referential integrity: foreign key constraint
When creating tables:
create table Product ( ID int identity(1,1) primary key not null, prono varchar(50) unique not null, typeid int foreign key references Department(DepartmentId), price decimal(18,2) check (price between 100 and 180000) default(100.00) not null, countpro int )
After table creation:
create table ProductT ( ID int identity(1,1) not null, prono varchar(50) not null, typeid int , price decimal(18,2) not null, ) --(4)Add constraints, --alter table Table name add constraint Constraint name check() --alter table Table name add constraint Constraint name primary key(field) --alter table Table name add constraint Constraint name unique(field) --alter table Table name add constraint Constraint name default Default value for field --alter table Table name add constraint Constraint name foreign key(field) references surface(field) -- Main table From table alter table ProductT add constraint CK_price check(price between 100 and 180000) alter table ProductT add constraint PK_ID primary key(ID) alter table ProductT add constraint UN_prono unique(prono) alter table ProductT add constraint DF_price default 100.0 for price alter table ProductT add constraint FK_typeid foreign key(typeid) references Department(DepartmentId)
5. Insert, modify and delete data -- DML
--Add Department
insert into Department (DepartmentName, LOC ) values ( 'ACCOUNTING', 'NEW YORK');
insert into Department (DepartmentName, LOC ) values ('RESEARCH', 'DALLAS');
insert into Department (DepartmentName, LOC ) values ('SALES', 'CHICAGO');
insert into Department (DepartmentName, LOC ) values ('OPERATIONS', 'BOSTON');
--Add employee
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 3);
insert into PEOPLE(empid , ename, job, mgr, hiredate, sal, comm,deptno) values( 7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, NULL, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, NULL, 1);
insert into PEOPLE(empid , ename, job, mgr, hiredate, sal, comm,deptno) values( 7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, NULL, 2);
insert into PEOPLE(empid , ename, job, mgr, hiredate, sal, comm,deptno) values( 7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000, NULL, 1);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500, 0, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, NULL, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, NULL, 1); --modify update PEOPLE set sal = 1000.00,deptno =2 where empno=12 --Salary increase in department 3 300 update PEOPLE set sal = sal+300 where deptno=3 --delete delete from PEOPLE where empno=15
Note: delete from deletes only 15 data, and the 15 flag does not disappear. Er, that is to say, add another statement, his empno employee number is not 15, but 16

Also, the where condition should be added to updata and delete, otherwise it will crack
Of course, you can also use truncate table__ Clear the data of the table and use drop table__ Just kill a table
4, Inquiry
1. Simple query
select field as new name from table
select field * (+, -, /, operation) 2 * from table
select * from table -- query all
select distinct (field) -- a query that removes duplicate values

2. Condition query
Syntax: select field 1, field 2... from table where condition
2.1 common operators:
Note: if and and or have priority problems at the same time
eg. query employees whose salary is greater than 2500 and department number is 1 or 2
select * from PEOPLE where sal>2500 and (deptno=2 or deptno =1)
and has high priority
2.2 fuzzy query
like has four matching patterns:
1,% 0 or more
--1,Intermediate containing o select * from PEOPLE where ename like'%o%' --2,It starts with S select * from PEOPLE where ename like'S%' --3,The end is N select * from PEOPLE where ename like'%N'
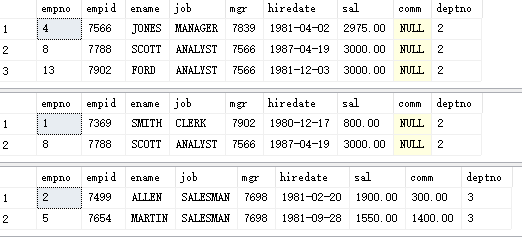
2,_ Match single character
--Consistent matching length select * from PEOPLE where ename like'_____' select * from PEOPLE where ename like'__R_'
3, [] range matching
--matching[]There are --5 And the third is in a reach p between select * from PEOPLE where ename like'__[a-p]__'
4, [^] is not in this range
Contrary to the one above
3. Data processing function (single line processing function)
One input and one output
Common:
1. Upper (column string): capitalize the contents of the string
2. Lower (column string): lowercase all the contents of the string
3. Rand (): random number within 100
4. Process control
case
when......then......
when......then......
else......
end
select *, case when sal between 0 and 1000 then 'low' when sal between 1000 and 3000 then 'middle level' else 'high-level' end as 'Employee level' from PEOPLE
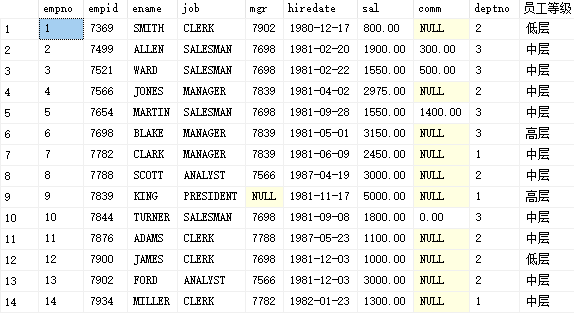
Of course, it's OK
if
begin
......
end
else
begin
......
end
4. Sort order by
Specify sorting: desc (descending), asc (ascending)
select * from PEOPLE order by sal desc select * from PEOPLE order by sal asc --Sort by multiple fields, ascending by salary and descending by department number select * from PEOPLE order by sal asc,deptno desc
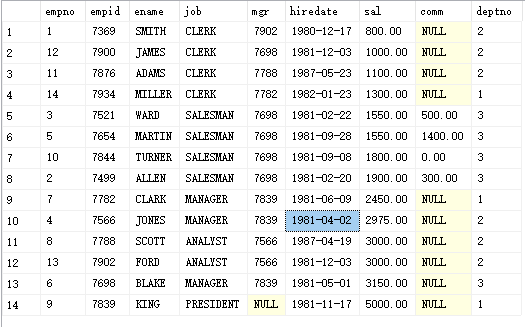
5. Multi line processing function (aggregate function or grouping function)
Count count sum avg average max min Min
Note: grouping functions can only be used after grouping
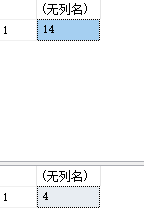
1. Difference between count(*) and count (field)
select count(*) from PEOPLE--Total rows of statistical table select count(comm) from PEOPLE--The field is not empty null Number of
6. group by
1. Execution sequence
Like select from ...... group by ......
Group before query, that is, group by before select
However, if you want to group and condition queries, their execution order is unusual
select ......from ......
where......
group by .....
order by......
Such commands are executed in the following order:
from—>where—>group by—>select—>order by
The condition is to execute before grouping
eg1: find out the salary and salary of each position
Idea: group according to jobs, and then sum wages
select job,sum(sal)as'Wages and salaries of all units' from PEOPLE group by job
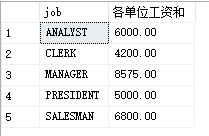
The above statement first groups PEOPLE by job (analyze, Clark...) Then sum
Then select
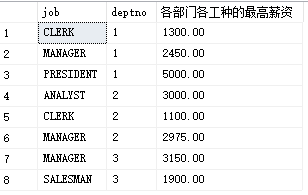
eg2: find out the maximum salary of deptno , different job positions , in each department
(different positions in different departments) - > joint grouping of two fields
Idea: first group each department and work, and then take the maximum value
select job,deptno,max(sal)as'Maximum salary of each department and type of work' from PEOPLE group by job,deptno
eg3: find out the maximum salary of each deptno job in each department after December 20, 1980
where is the data after December 12, 1980
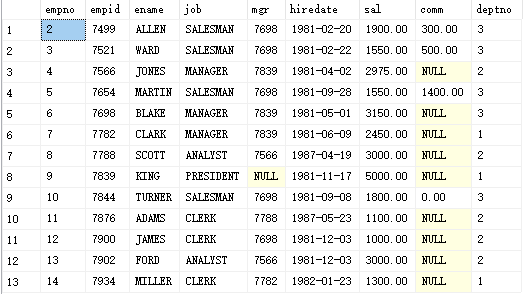
Then group each department and work, and then take the maximum value
select job,deptno,max(sal)as'Maximum salary of each department and type of work' from PEOPLE where hiredate>1980-12-20 group by job,deptno
2. HAVING keyword
If we want to find departments with an average salary of more than 2000 for each department, we may think:
select deptno from PEOPLE where avg(sal)>2000 group by deptno;
However, avg is a grouping function. After grouping, where is before group by, so it cannot be written like this
If you want to add conditions after grouping, use having
select deptno,avg(sal)as'average wage' from PEOPLE group by deptno having avg(sal)>2000
from—>where—>group by—>having->select—>order by
The count(*) mentioned earlier, after grouping, represents the grouped table
select deptno,avg(sal)as'average wage' from PEOPLE group by deptno having count(*)>=4
It represents the average salary of departments with more than four inquiries
7. Connection query (multi table query)
Classification: inner connection {equivalent query, non equivalent query, self connection}, outer connection {left outer connection, right outer connection, complete outer connection}
1. Cartesian product phenomenon
Multiplication of two sets
When two tables are connected for query without any restrictions, the number of final query results is the product of the number of two tables
select ename ,DepartmentId from Department,PEOPLE
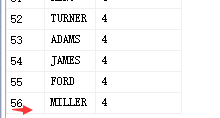
14 * 4 = 56
To avoid Cartesian product, add conditions
select ename ,DepartmentName from Department d,PEOPLE e where d.DepartmentId=e.deptno
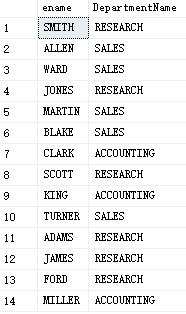
2. Internal connection
2.1 equivalent connection
The previous sentence is equivalent connection
select e.ename ,d.DepartmentName from Department d,PEOPLE e where d.DepartmentId=e.deptno
This syntax is the syntax of sql92. In order to enhance the computing power of the table, sql99 syntax introduces join on
But join is not necessary for join tables

Although where is a 92 syntax, where can also implement table joins
select e.ename ,d.DepartmentName from Department d inner join --inner Represents an internal connection, which can be ignored without writing PEOPLE e on d.DepartmentId=e.deptno
The purpose is to let where do other things
2.2 non equivalent connection
select e.ename ,d.DepartmentName,e.sal from Department d join --inner Represents an internal connection, which can be ignored without writing PEOPLE e on e.sal between 1000 and 1200
2.3 self connection
Is to connect with yourself
eg: query the superior leader of an employee. The employee name and the corresponding leader name are required to be displayed
select a.ename as'Employee name',b.ename as'Leader name' from PEOPLE a join PEOPLE b on a.mgr=b.empid
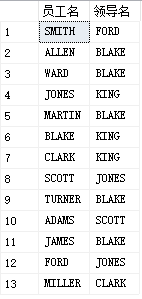
Only 13 lines, because king has no leader
3. External connection
1. Right external connection (the right is the main table)
right join on all rows in the right table
select a.ename as'Employee name',b.ename as'Leader name' from PEOPLE a right join PEOPLE b on a.mgr=b.empid
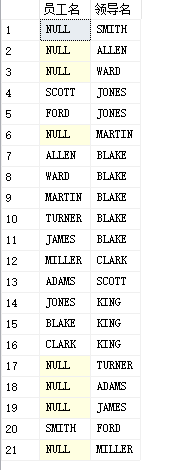
2. Left external connection (the left is the main table)
left join on all rows in the left table
select a.ename as'Employee name',b.ename as'Leader name' from PEOPLE a left join PEOPLE b on a.mgr=b.empid
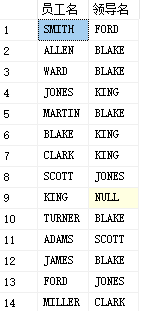
3. Full external connection (the two tables should be displayed whether they conform to the relationship or not)
All rows of the left and right tables are full join on
select a.ename as'Employee name',b.ename as'Leader name' from PEOPLE a full join PEOPLE b on a.mgr=b.empid
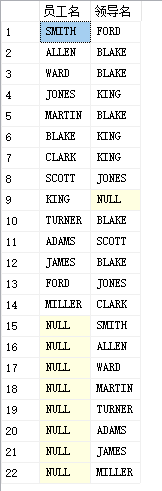
Leaders without employees are the lowest level employees, and employees without leaders are the highest level
8. Nested query (sub query)
Select statements are nested in select statements. The nested select statements are called subqueries (subqueries cannot contain order by)
Subqueries can appear in three places
1. After select
2. from back
3. Behind where
select...(select)
from...(select)
where(select)
1. Sub query after select
eg: find out the Department name of each employee, display the employee name, Department Name:
select ename, (select d.DepartmentName from Department d where e.deptno=d.DepartmentId) as dname from PEOPLE e
You can see that the external PEOPLE e is connected with the Department in the subquery
2. Sub query after from
The sub query after from can treat the results of the sub query as a table (equivalent to a view)
eg: find out the salary grade of the average salary of each position
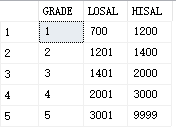
Five levels
a registration form:
CREATE TABLE salgrade ( GRADE INT, LOSAL INT, HISAL INT ); INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES ( 1, 700, 1200); INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES ( 2, 1201, 1400); INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES ( 3, 1401, 2000); INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES ( 4, 2001, 3000); INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES ( 5, 3001, 9999);
Step 1: find the average salary of each position
select job,avg(sal)as 'average wage'from PEOPLE group by job
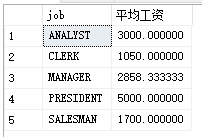
Part II: regard it as a table and connect it with the registration form
select t.job,s.GRADE from (select job,avg(sal)as 'average wage'from PEOPLE group by job) t join SALGRADE s on t.average wage between s.LOSAL and s.HISAL
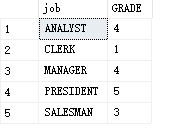
3. Sub query after where
A set is returned, and another query set can be determined by comparing with this set
eg: find employees with higher than average salary
select ename from PEOPLE where sal>(select avg(sal)from PEOPLE)
1. in subquery (find a range)
In and not in can only return one column of data
eg: find employees who do not work in New York
--List departments in new york Employees --1,Subquery select ename from PEOPLE where deptno not in (select DepartmentId from Department where loc='new york') --2,join query select e.ename from PEOPLE e join Department d on e.deptno=d.DepartmentId where d.loc!='new york'
2. Comparison sub query
All all
Does any contain
eg: find employees in New York who are paid less than all CHICAGO employees
Idea: first use the in sub query to find out all employees of NEWYORK, then use the connection query to check the wages of CHICAGO employees (return a column of CHICAGO employee salary table), and finally find the employees whose wages of New York employees are less than those of all CHICAGO employees
--lookup new york Than all CHICAGO Employees with low wages select ename,sal from PEOPLE where deptno in (select DepartmentId from Department where loc='new york') and sal < all(select e.sal from PEOPLE e join Department d on e.deptno=d.DepartmentId where d.loc='CHICAGO') --lookup new york Does it contain ratio CHICAGO Employees with low wages select ename,sal from PEOPLE where deptno in (select DepartmentId from Department where loc='new york') and sal < any(select e.sal from PEOPLE e join Department d on e.deptno=d.DepartmentId where d.loc='CHICAGO')
Of course, you can also connect directly, and then where
3. exists subquery
Returns true or false. If the subquery result exists, returns true, and if it does not exist, it is false
eg: query whether there are employees with salary grade of 5
Idea: the sal of the parent table enters the sub query and matches with salgrade until the level 5 returns true
--Query whether there are employees with salary grade equal to 5 select ename,sal from PEOPLE e where exists( --External parent table is e select * from SALGRADE s where (e.sal between s.LOSAL and s.HISAL) and (s.GRADE=5) )
You can see that the sub query of exists is to put the fields of the parent table into the sub query for query one by one
9. Other clauses
1,into
The query results are added to a table (table copy)
select field into new table from original table where condition
2. union - > and
Join tables. Multiple tables are joined together
3. except and intersect
1. Excel refers to the data that exists in the first set but does not exist in the second set—— Complement
eg: find employees whose job is CLERK but salary level is less than 2
--Find work as CLERK But the salary level is less than 2 select ename,sal from PEOPLE where job='CLERK' except select e.ename,e.sal from PEOPLE e join salgrade s on e.sal between s.LOSAL and s.HISAL where s.GRADE>=2
2. INTERSECT refers to the data existing in both sets. - > intersection
eg: find employees whose job is CLERK and salary level is 2
--Find work as CLERK Employees with salary level 2 select ename,sal from PEOPLE where job='CLERK' intersect select e.ename,e.sal from PEOPLE e join salgrade s on e.sal between s.LOSAL and s.HISAL where s.GRADE=2
eg:
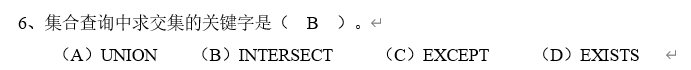
4,with as
This thing is really like a view. The result of the select is regarded as a table, which can be used directly after the query
10. view
External mode, virtual table, look at data from different angles
Note: the addition, deletion, modification and query of the view will cause the data of the original table to be changed
Function: simplify sql language
Create view
create view view name
as
select...
We create a view of employee leadership
create view People_view as select a.ename as 'Employee name',b.ename as 'Leader name'from PEOPLE a join PEOPLE b on a.mgr =b.empid; drop view People_view
Then delete the view

You can create a new view from another view
11. Cursor
Pointer used to query data
12. Pagination top
top indicates the first few rows of the query
Here you can use top to query the previous behavior pages
--Query one page select top 5 * from PEOPLE --Query the second page (except the first five lines) select top 5 * from PEOPLE where empno not in(select top 5 empno from PEOPLE) --Top 50 queries%Data select top 50 percent * from PEOPLE
5, T-SQL
1. SQL language classification
1. DQL data query language (select)
2. DML data operation language (add insert, delete and update to table} data)
3. DDL data definition language (operation table structure: add create delete alter)
4. TCL transaction control statement transaction commit transaction rollback
5. DCL data control language (permission)
2. Usage of data type
3. Variable
1. Local variable: starts with @
declare @ variable data type
Assignment 1, set @ variable=
2. select @ variable = -- it is generally used to assign the data found in the table to the variable
When the expression returns multiple values, using SET will make an error, and SELECT will take the last value
declare @a decimal(20,2) select @a= sal from PEOPLE print @a

Tip: if MySQL is not in begin End cannot be used. You can directly set @ variable
2. Global variable: it starts with @ @ and is defined and maintained by the system
4. Operator
5. Process control
1. Select branch structure
if ...
begin
...
end
else
begin
...
end
--perhaps
case
when...then...
when...then...
when...then...
else
endWe rank our employees
select Employee name,job,Leader name,sal, case when sal between 800 and 1000 then 'bottom' when sal between 100 and 3000 then 'middle level' else 'high-level' end Employee level from People_view;
2. Circular statement
This is the same as C
while condition
begin
...
end6, Index
Improve query efficiency
1. Classification
Indexes are classified by storage type: clustered and nonclustered
Difference: a clustered index can be understood as a dictionary sorted in 26 alphabetical order. If you find a that begins with a, go to a
A nonclustered index can be understood as a partial search. It takes the characteristics of the word as the key value to give the address. For example, 'Fu, Dan, Bao' is stored next to a single person. When you find 'Fu', you will give you a page, which is the location of 'Fu'. Similarly, 'Dan' is the same as' Bao ', but they are not directly above or below Fu, which is a nonclustered index
There can be at most one clustered index in a table, but there can be one or more non clustered indexes - > a clustered index is a primary key
2. Create index
create (unique) clustered (nonclustered) index index name on table (field)
create unique nonclustered index empno_clustered on PEOPLE(empno)
You can also composite index multiple fields

7, Stored procedures and triggers
1. Stored procedure
Stored procedure: a collection of sql statements or a set of sql statements to complete a specific function
1.1 stored procedure classification:
1. System stored procedures (names are prefixed with sp_)
2. User defined stored procedure: it is created by the user. You can import parameters or return values
1,2 stored procedure cheese:
Difference from function: it can be called by external programs, such as java and c++
Execute: execute / execute, (call for MySQL) stored procedure name, parameter 1, parameter 2
1,3 create stored procedure:
1. Simple design of stored procedures
create proc Stored procedure name
parameter list
as
begin
...
end
go
exec Stored procedure name, parameter 1, parameter 2--Don't use parentheses--Query whether there are employees with salary grade equal to 5
select ename,sal from PEOPLE e where exists( --External parent table is e
select * from SALGRADE s where
(e.sal between s.LOSAL and s.HISAL)
and (s.GRADE=5)
)
--Create the above stored procedure
create proc proc_Findsal
as
begin
select ename,sal from PEOPLE e where exists
( --External parent table is e
select * from SALGRADE s where
(e.sal between s.LOSAL and s.HISAL)
and (s.GRADE=5)
)
end
go
exec proc_Findsal2. Create a stored procedure with parameters:
eg: create a stored procedure to add products
select * from ProductT drop proc proc_insert_pro create proc proc_insert_pro @prono varchar(50),@typeid int,@price decimal(18,2) as insert into ProductT(prono,typeid,price) values(@prono ,@typeid ,@price) select * from ProductT go exec proc_insert_pro 'shirt',1,100.00
3. Stored procedures using wildcard parameters:
eg: find the employee with 'A' in the leader's name
create proc proc_like @name_like varchar(30)= '%a%'--Parameter defaults as select a.JOB,a.empid,a.SAL,a.ename as 'Employee name',b.ename as 'Leader name'from PEOPLE a join PEOPLE b on a.mgr =b.empid where b.ename like @name_like go exec proc_like exec proc_like '%c%'
The default value of the parameter is the same as the default value of the parameter of c and python functions. If the stored procedure is called without introducing parameters, the internal parameters are called with the default value
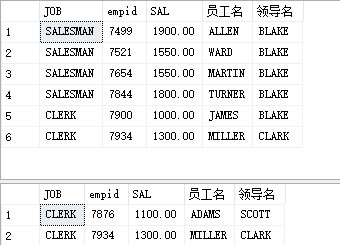
4. With return value (only integer can be returned, not string...)
create proc proc_return @bool int =0, @check varchar(4)='no' as if(@bool=1 and @check='yes') begin select top 50 percent * from PEOPLE return 1 end else if(@bool=0) return -1 else return -1 go declare @a int,@b int exec @a= proc_return 1,'yes' exec @b= proc_return print @a print @b

5. Use the OUTPUT cursor parameter - supplemented later
2. Trigger
Because of what happened, what happened automatically, just like someone slapped you, and you hit back at that moment

Touch publishing is a special stored procedure. The difference is that it is not called by exec, but is automatically executed by triggering events
This event is the operation on the table: change the structure DDL and data DML
2.1 classification of triggers
DDL trigger
General DDL statements are less likely to appear, and DDL triggers are less likely to appear
So we study DML triggers
There are two categories of DML triggers:
1. After trigger: after someone slaps you, you call back - > execute the trigger after all operations are successful
2. instead of trigger: if someone wants to slap you, you predict it in advance, and you slap him in advance -- > do not execute the original addition, deletion and modification, but execute the trigger
2.2 two virtual tables of trigger
inserted table delete delete table
| Operations on tables | inserted | deleted |
| insert | Store inserted data | nothing |
| update | Store updated data | Store updated data |
| delete | nothing | Store deleted data |
Therefore, trigger is also a special transaction, which can be rolled back
2.3 after trigger
create trigger Trigger Name
on Table name
after(for) operation(insert,update,delete)
as
...T-SQL sentence
go
1,after insert
eg add employee information. If the employee department number cannot be queried in the Department table, a new Department will be automatically added
--Add employee information if employee department number is in Department If it cannot be found in the table, a new Department will be added automatically
create trigger trigger_insert_new
on PEOPLE --Because you are adding an employee to the employee table
for insert
as
if not exists(select* from Department where DepartmentId=(select deptno from inserted))
insert into Department(DepartmentName,loc) values('New Department','newloc')
go
--Test trigger
alter table PEOPLE drop constraint FK__PEOPLE__deptno__76619304--Delete the foreign key constraint first, or you can't add it
insert into PEOPLE(empid,ename,job,sal,deptno) values(9999,'fran','boss',99999.99,5)
delete from PEOPLE where ename='fran'
select * from Department
select * from PEOPLE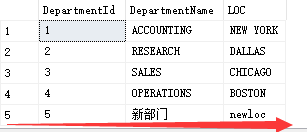

You can see that two pieces of data have been added
2,after update
eg1: after modifying a department, the department number of the employee table is also updated synchronously
Because the deptno of the original department table is an identification column and cannot be modified, I created a new department table
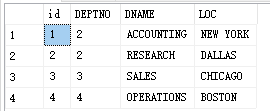
CREATE TABLE DEPT ( id int not null primary key identity, DEPTNO int not null , DNAME VARCHAR(14) , LOC VARCHAR(13), ); INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES ( 1, 'ACCOUNTING', 'NEW YORK'); INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES ( 2, 'RESEARCH', 'DALLAS'); INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES ( 3, 'SALES', 'CHICAGO'); INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES ( 4, 'OPERATIONS', 'BOSTON'); select * from dept --After modifying the Department, the department number of the employee table is also updated synchronously create trigger triggrr_update on dept for update as if update(DEPTNO) update PEOPLE set deptno=(select deptno from inserted)--New number where deptno =(select deptno from deleted)--Old number go update DEPT set DEPTNO =2 where DEPTNO=1

The new number updated here should be taken from the inserted table, and the old number should be taken from the deleted table
update() function: test whether the field is updated or insert ed. If yes, it returns true, and if no, it returns false
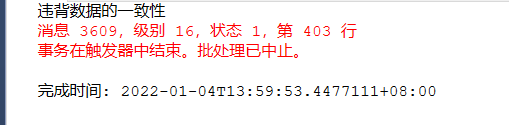
eg: if the loc of the Department is modified, the modification operation will be cancelled
--If you modify the Department's loc Then cancel the modification operation create trigger triggrr_update_rollback on dept for update as if update(loc) begin print 'Violation of data consistency' rollback transaction end go update DEPT set loc ='loctemp' where loc='NEW YORK'
3,after delete
eg -- after deleting a department, delete the employees in the Department
--After deleting a department, delete the employees in the Department create trigger triggrr_delete on dept for delete as delete from PEOPLE where deptno =(select deptno from deleted) go delete from DEPT where DEPTNO=1
Note that delete cannot use update() to determine whether to change
2.4 instead of trigger
Trigger before operation
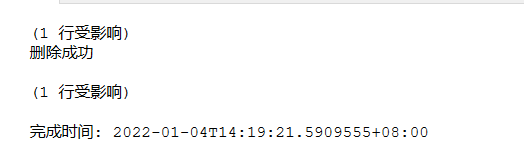
eg before deleting a department, judge whether there are people in the Department. If there are no people to delete, if there are people, it will not be deleted
--Before deleting a department, judge whether there are people in the Department. If there are no people, it will not be deleted alter trigger triggrr_delete_instead on dept instead of delete as if not exists(select * from PEOPLE where deptno=(select deptno from deleted)) begin delete from Dept where deptno=(select deptno from deleted) print 'Delete succeeded' end else print 'Cannot delete' go delete from DEPT where DEPTNO=4
Conclusion:
Write this just to review the final exam. In fact, there are a lot of things that haven't been written. I just wrote a lot of knowledge points with a few tables
Uh...
Most of them are written on SQL sever. There must be time later to add mysql to make a difference