Conditional generation countermeasure network CGAN
CGAN is one of the earliest GAN innovations that make the generation of target data possible. It can be said to be the most influential one. Next, it introduces the working mode of CGAN and how to implement its small-scale version with MNIST dataset.
CGAN principle
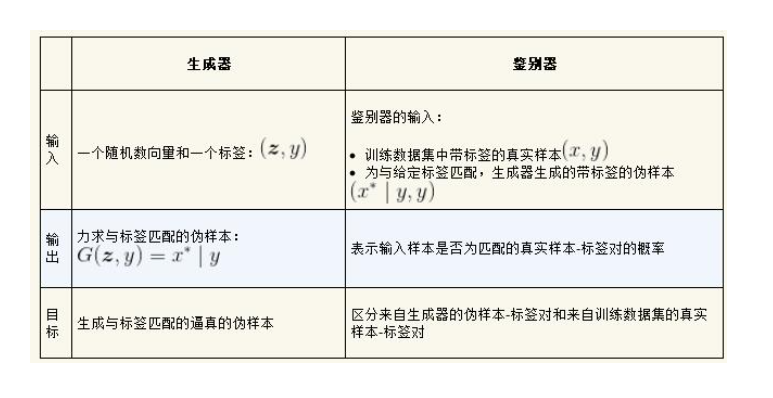
The generator learns to generate realistic samples for each tag in the training data set, while the discriminator learns to distinguish between true sample tag pairs and false sample tag pairs. The discriminator of semi supervised GAN not only distinguishes real samples from pseudo samples, but also assigns correct labels to each real sample; The discriminator in CGAN does not learn to identify which sample is which class. It only accepts false samples and rejects false samples.
For example, whether sample 1 is true or false, the discriminator of CGAN rejects the pair (sample 1 and tag 2). In order to deceive the discriminator, it is not enough for CGAN generator to only generate realistic data, and the generated sample also needs to match with the tag. After fully training the generator, you can specify the samples you want CGAN to synthesize by passing the required tags.
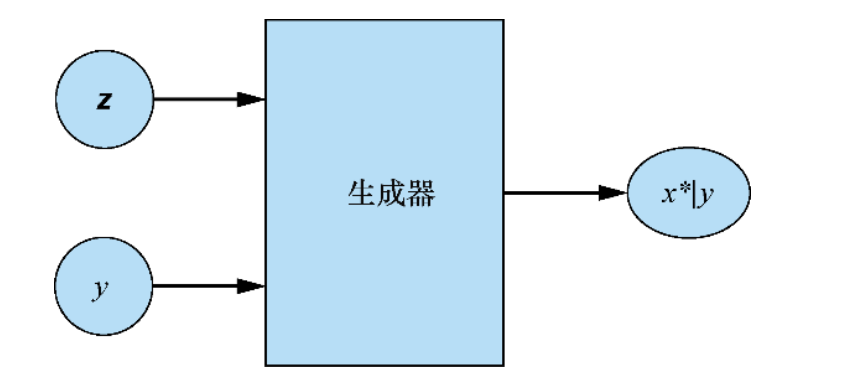
Generator of CGAN
Use noise z and label y to synthesize a sample x*|y
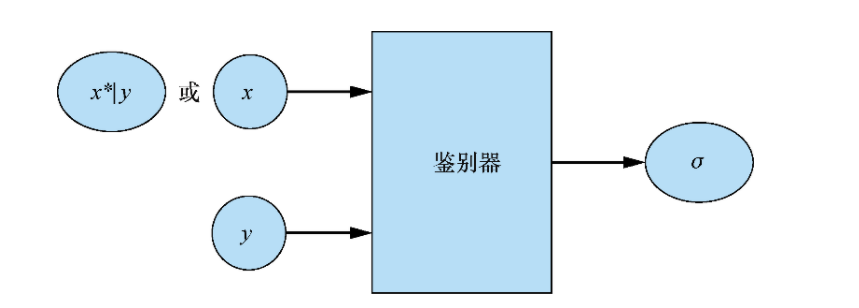
Discriminator of CGAN
Accept real samples with labels (x,y) and pseudo samples with labels (x*|y,y). On the real sample label pair, the discriminator learns how to identify real data and how to identify matching pairs. In the samples generated by the generator, the discriminator learns to identify pseudo sample tag pairs to distinguish them from real sample tag pairs.
The output of the discriminator indicates the probability that the input is a real matching pair. Its goal is to learn to accept all real sample label pairs and reject all pseudo samples and all samples that do not match the label.
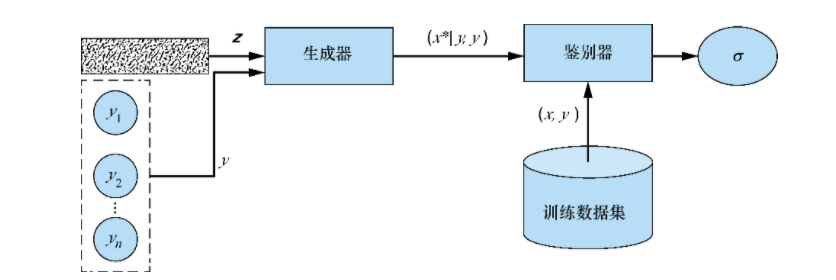
Architecture diagram and summary
For each pseudo sample, the same tag y is passed to both the generator and the discriminator. In addition, the discriminator is trained on the real sample with mismatch label to reject the mismatched pair; Its ability to identify mismatches is trained to receive only by-products of real matching pairs.
Implementation of CGAN
# Import package %matplotlib inline import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from keras import backend as K from tensorflow.keras.datasets import mnist from keras.layers import Embedding, Multiply, Dropout, Lambda, Concatenate, Input, Dense, Flatten, Reshape, Activation, BatchNormalization from keras.layers.advanced_activations import LeakyReLU from keras.layers.convolutional import Conv2D, Conv2DTranspose from keras.models import Sequential, Model from keras.optimizers import Adam from keras.utils import to_categorical
Using TensorFlow backend.
# Model input dimension img_rows = 28 img_cols = 28 channels = 1 # Image size img_shape = (img_rows, img_cols, channels) # Noise vector size z_dim = 100 num_classes = 10
Construction generator
(1) Use Keras's Embedding layer to convert the label y (an integer from 0 to 9) to a size of Z_ Dense vector of dim (length of random noise vector).
(2) The label and noise vector z are embedded in the joint representation using the Multiply layer of Keras. As the name suggests, this layer multiplies the corresponding terms of two equal length vectors and outputs a single vector as the product of the result.
(3) Taking the obtained vector as input, the rest of the CGAN generator network is retained to synthesize the image.
def build_generator(z_dim):
model = Sequential()
model.add(Dense(256 * 7 * 7, input_dim=z_dim))
model.add(Reshape((7, 7, 256)))
model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(64, kernel_size=3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding='same'))
model.add(Activation('tanh'))
return model
def build_cgan_genertator(z_dim):
z = Input(shape=(z_dim, ))
label = Input(shape=(1,), dtype='int32')
label_embedding = Embedding(num_classes, z_dim, input_length=1)(label)
label_embedding = Flatten()(label_embedding)
joined_representation = Multiply()([z, label_embedding])
generator = build_generator(z_dim)
conditioned_img = generator(joined_representation)
return Model([z, label], conditioned_img)
Construct discriminator of CGAN
Steps:
(1) Take a label (an integer from 0 to 9) and use Keras's Embedding layer to change the label to a size of 28 × twenty-eight × 1 = dense vector of 784 (length of flattened image).
(2) Adjust the embedded label to the image size (28 × twenty-eight × 1).
(3) The reshaped embedded label is connected to the corresponding image to generate a shape (28 × twenty-eight × 2) Joint representation of. You can think of it as an image with an embedded label "pasted" on the top.
(4) The image label joint representation is input into the discriminator network of CGAN. Note that in order for the training to proceed normally, the model input size must be adjusted to (28) × twenty-eight × 2) To correspond to the new input shape.
def build_discriminator(img_shape):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=(img_shape[0], img_shape[1], img_shape[2]+1),padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2D(64, kernel_size=3, strides=2, input_shape=img_shape,padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2D(128, kernel_size=3, strides=2, input_shape=img_shape,padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
return model
def build_cgan_discriminator(img_shape):
img = Input(shape=img_shape)
label = Input(shape=(1, ), dtype='int32')
label_embedding = Embedding(num_classes, np.prod(img_shape), input_length=1)(label)
label_embedding = Flatten()(label_embedding)
label_embedding = Reshape(img_shape)(label_embedding) # Adjust the label to the same dimension as the input image
concatenated = Concatenate(axis= -1)([img, label_embedding])# Link an image to its embedded label
discriminator = build_discriminator(img_shape)
classification = discriminator(concatenated)
return Model([img, label], classification)
Build the whole model
def build_cgan(generator, discriminator):
z = Input(shape=(z_dim, ))
label = Input(shape=(1, ))
img = generator([z, label])
classification = discriminator([img, label])
model = Model([z, label], classification)
return model
discriminator = build_cgan_discriminator(img_shape)
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(), metrics=['accuracy'])
generator = build_cgan_genertator(z_dim)
discriminator.trainable = False
cgan = build_cgan(generator, discriminator)
cgan.compile(loss='binary_crossentropy', optimizer=Adam())
train
losses = []
accuracies = []
def train(iterations, batch_size, sample_interval):
(X_train, y_train), (_, _) = mnist.load_data('./MNIST')
X_train = X_train / 127.5 - 1.0
X_train = np.expand_dims(X_train, axis=3)
real = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for iteration in range(iterations):
idx = np.random.randint(0, X_train.shape[0], batch_size)
# print(X_train.shape[0])
imgs, labels = X_train[idx], y_train[idx]
z = np.random.normal(0, 1, (batch_size, z_dim))
gen_imgs = generator.predict([z, labels])
# print(imgs.shape)
d_loss_real = discriminator.train_on_batch([imgs, labels], real)
d_loss_fake = discriminator.train_on_batch([gen_imgs, labels], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
z = np.random.normal(0, 1, (batch_size, z_dim))
labels = np.random.randint(0, num_classes, batch_size).reshape(-1, 1)
g_loss = cgan.train_on_batch([z, labels], real)
if (iteration + 1) % sample_interval == 0:
losses.append((d_loss[0], g_loss))
accuracies.append(100.0 * d_loss[1])
print("%d [D loss: %f, acc.: %.2f%%] [G loss:%f]"%(iteration + 1, d_loss[0], 100.0 * d_loss[1], g_loss))
sample_images()
def sample_images (image_grid_rows=2, image_grid_columns=5):
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, z_dim))
labels = np.arange(0, 10).reshape(-1, 1)
gen_imgs = generator.predict([z, labels])
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(image_grid_rows,image_grid_columns,figsize=(10,4),sharey=True,sharex=True)
cnt = 0
for i in range(image_grid_rows):
for j in range(image_grid_columns):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
axs[i,j].set_title("Digit: %d" % labels[cnt])
cnt +=1
iterations = 12000 batch_size = 32 sample_interval = 1000 train(iterations, batch_size, sample_interval)
1000 [D loss: 0.000204, acc.: 100.00%] [G loss:9.885448] 2000 [D loss: 0.000059, acc.: 100.00%] [G loss:9.908726] 3000 [D loss: 0.230777, acc.: 90.62%] [G loss:4.183795] 4000 [D loss: 0.040735, acc.: 98.44%] [G loss:3.380749] 5000 [D loss: 0.192189, acc.: 90.62%] [G loss:3.410103] 6000 [D loss: 0.134279, acc.: 98.44%] [G loss:3.005539] 7000 [D loss: 0.412724, acc.: 82.81%] [G loss:1.312850] 8000 [D loss: 0.211682, acc.: 90.62%] [G loss:3.666016] 9000 [D loss: 0.080928, acc.: 98.44%] [G loss:7.182220] 10000 [D loss: 0.107635, acc.: 98.44%] [G loss:2.332113] 11000 [D loss: 0.194184, acc.: 93.75%] [G loss:3.737709] 12000 [D loss: 0.191671, acc.: 89.06%] [G loss:4.127837]
Training 1000 times

6000 training sessions
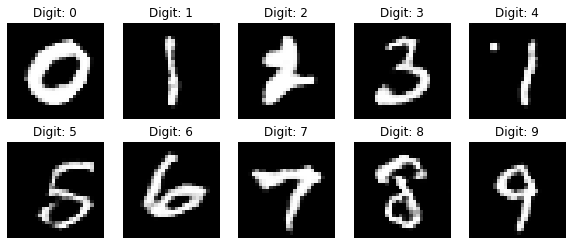
1200 training sessions
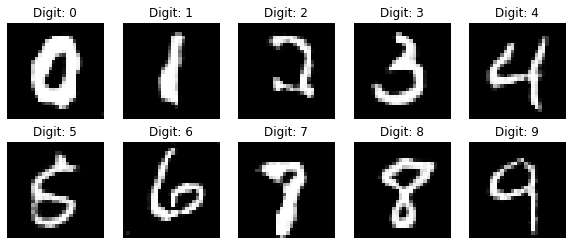
Summary
CGAN realizes not only generating samples similar to real samples, but also generating a qualified real sample. The function of GAN is further improved by adding the input of generator discriminator.
Github address: https://github.com/yunlong-G/tensorflow_learn/blob/master/GAN/CGAN.ipynb