When the application algorithm uses the GeminiGraph framework, first instantiate the Graph class through the constructor. The specific work done by Gemini in the instantiation process is introduced line by line below.
//constructor
Graph() {
threads = numa_num_configured_cpus(); //Returns the number of CPUs in the system
sockets = numa_num_configured_nodes(); //Returns the number of memory nodes in the system
threads_per_socket = threads / sockets; //Indicates the number of memory nodes allocated to each cpu
init();
}init() initialization mainly includes numa related initialization, omp related initialization and MPI related initialization.
Next, the meaning of each piece of code is described in detail line by line.
void init() {
edge_data_size = std::is_same<EdgeData, Empty>::value ? 0 : sizeof(EdgeData);
unit_size = sizeof(VertexId) + edge_data_size;
edge_unit_size = sizeof(VertexId) + unit_size;
assert( numa_available() != -1 );
assert( sizeof(unsigned long) == 8 ); // assume unsigned long is 64-bit
char nodestring[sockets*2+1];
nodestring[0] = '0';
for (int s_i=1;s_i<sockets;s_i++) {
nodestring[s_i*2-1] = ',';
nodestring[s_i*2] = '0'+s_i;
}
struct bitmask * nodemask = numa_parse_nodestring(nodestring);
numa_set_interleave_mask(nodemask);
omp_set_dynamic(0);
omp_set_num_threads(threads);
thread_state = new ThreadState * [threads];
local_send_buffer_limit = 16;
local_send_buffer = new MessageBuffer * [threads];
for (int t_i=0;t_i<threads;t_i++) {
thread_state[t_i] = (ThreadState*)numa_alloc_onnode( sizeof(ThreadState), get_socket_id(t_i));
local_send_buffer[t_i] = (MessageBuffer*)numa_alloc_onnode( sizeof(MessageBuffer), get_socket_id(t_i));
local_send_buffer[t_i]->init(get_socket_id(t_i));
}
#pragma omp parallel for
for (int t_i=0;t_i<threads;t_i++) {
int s_i = get_socket_id(t_i);
assert(numa_run_on_node(s_i)==0);
#ifdef PRINT_DEBUG_MESSAGES
// printf("thread-%d bound to socket-%d\n", t_i, s_i);
#endif
}
#ifdef PRINT_DEBUG_MESSAGES
// printf("threads=%d*%d\n", sockets, threads_per_socket);
// printf("interleave on %s\n", nodestring);
#endif
MPI_Comm_rank(MPI_COMM_WORLD, &partition_id);
MPI_Comm_size(MPI_COMM_WORLD, &partitions);
send_buffer = new MessageBuffer ** [partitions];
recv_buffer = new MessageBuffer ** [partitions];
for (int i=0;i<partitions;i++) {
send_buffer[i] = new MessageBuffer * [sockets];
recv_buffer[i] = new MessageBuffer * [sockets];
for (int s_i=0;s_i<sockets;s_i++) {
send_buffer[i][s_i] = (MessageBuffer*)numa_alloc_onnode( sizeof(MessageBuffer), s_i);
send_buffer[i][s_i]->init(s_i);
recv_buffer[i][s_i] = (MessageBuffer*)numa_alloc_onnode( sizeof(MessageBuffer), s_i);
recv_buffer[i][s_i]->init(s_i);
}
}
alpha = 8 * (partitions - 1);
MPI_Barrier(MPI_COMM_WORLD);
}- 2-4: respectively represents the vertex data size, the data size of one vertex and one edge, and the size of two edges of one vertex. EdgeData is the type passed in when calling graph, sizeof(Empty)==1; VertexId is of type unsigned (int by default). edge_unit_size is the size of two edges of a vertex.
- 6-7: assert is used to calculate the expression first. If its value is false (i.e. 0), it first prints an error message to stderr, and then terminates the program by calling abort. numa_available(): judge whether your computer supports numa, but it seems that it is supported after linux 2.4;
- 9-16: sockets = NUMA defined in Graph() constructor_ num_ configured_ nodes(); That is, the number of memory nodes in the system. nodestring is the incremental string of "0,1,2,3,4,5,..., sockets-2, sockets-1, sockets".
- 15: nodemask is a bit mask that is transformed by parsing the string list of nodes.
- 16: Numa_set_interleave_mask() sets the memory interleaving mask of the current task to nodemask. All new memory allocations are paged interleaved on all nodes in the interleaving mask.
- 18: omp_set_dynamic(0); The number of threads in the current thread group (team) that are not dynamically allocated.
- 19: Call OMP in the serial code area_ set_ num_ Threads to set the number of threads in the current thread group (team)
- 20-27: memory allocation
- 24,25: Numa_alloc_onnode() allocates memory on the specified node. The size parameter will be rounded to a multiple of the system page size. get_socket_id() get the memory node number
- 28-35: check whether the memory node on each thread is allocated successfully
- 31: Numa_run_on_node() runs the current task and its subtasks on a specific node.
- 41: get the current parallel process number and assign it to partition_id
- 42: get the number of parallel processes and assign it to partitions
- 43-54: initialization of communication array; MessageBuffer* [partitions] [sockets]; numa-aware; 3D array.
- 56: used for the synchronization of all processes in a communication subsystem. When calling a function, the process will be in a waiting state until all processes in the communication subsystem call the function.
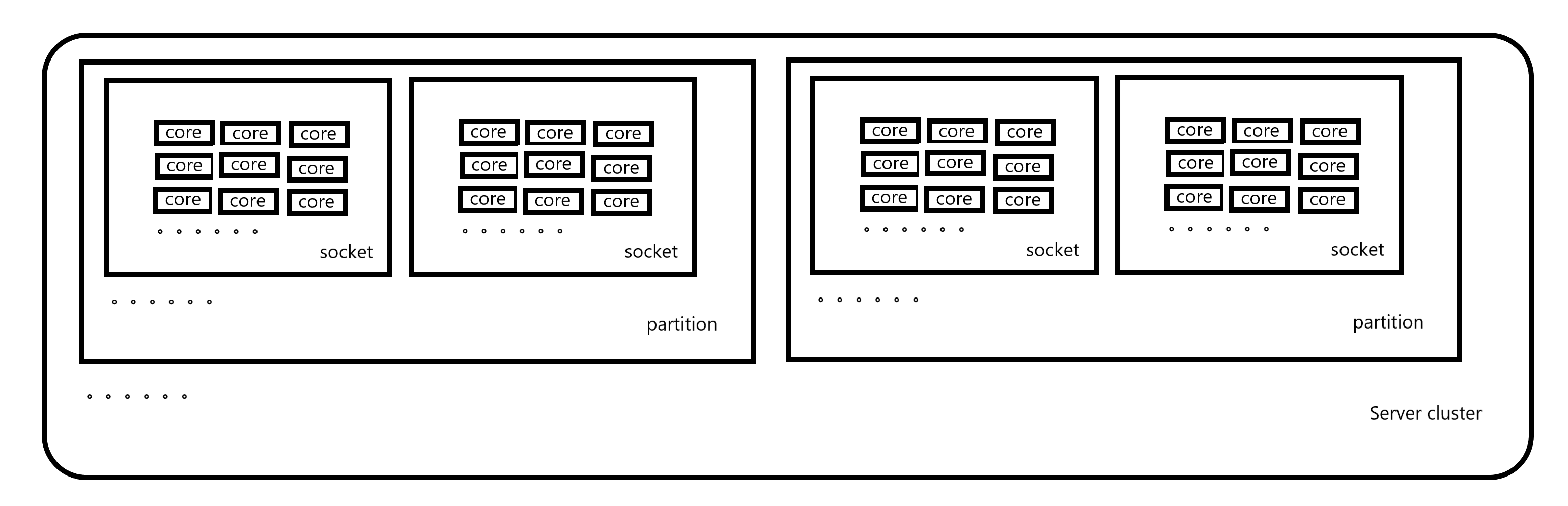
Where Server cluster is a Server cluster, such as a Supercomputing Center;
There are multiple servers in the server cluster, such as a host, that is, partition in the above figure. The number of parallel processes obtained in MPI is the same as the number of servers. The value of partitions is the number of servers in the server cluster;
There are multiple slots in a server (host), that is, the number of slots in the system returned by numa_num_configured_nodes(), that is, sockets;
There are multiple cores in each slot, that is, the number of cores in the system returned by numa_num_configured_cpus(), that is, threads.
MessageBuffer [partitions] [sockets] [threads] constructed from this; numa-aware; 3D array.
I am a rookie. If there is any mistake, please discuss it in the comment area.