Last time, we got the product information of Amazon. Naturally, we need to take a look at the comments. Users' comments can intuitively reflect whether the current commodity value is worth buying, and Amazon's scoring information can also obtain the weight of scoring.

Amazon's comment area is composed of user ID, score and comment title, region, time and comment body. That's what we got this time.
1, Analyze Amazon's comment requests
First, open the Network in developer mode and Clear the screen to make a request:
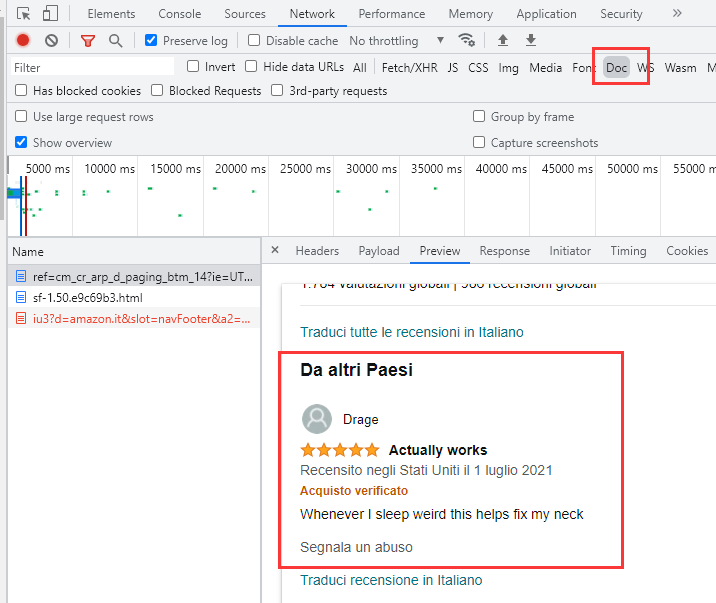
You will find that the get request in Doc just has the comment information we want.
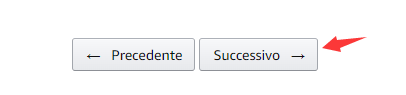
But the real comment data is not all here. The page turns down and there is a page turning button:
Click page turning request to the next page. A new request is added in the Fetch/XHR tab. There is no new get request in the Doc tab just now. It is found that all comments are XHR type requests.

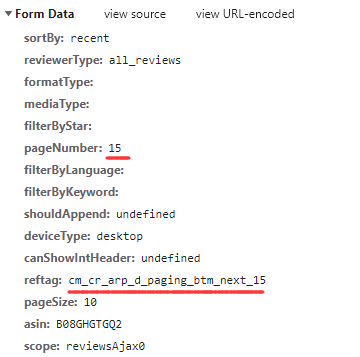
Get the link and payload data of the post request, which contains the parameters to control page turning. The real comment request has been found.
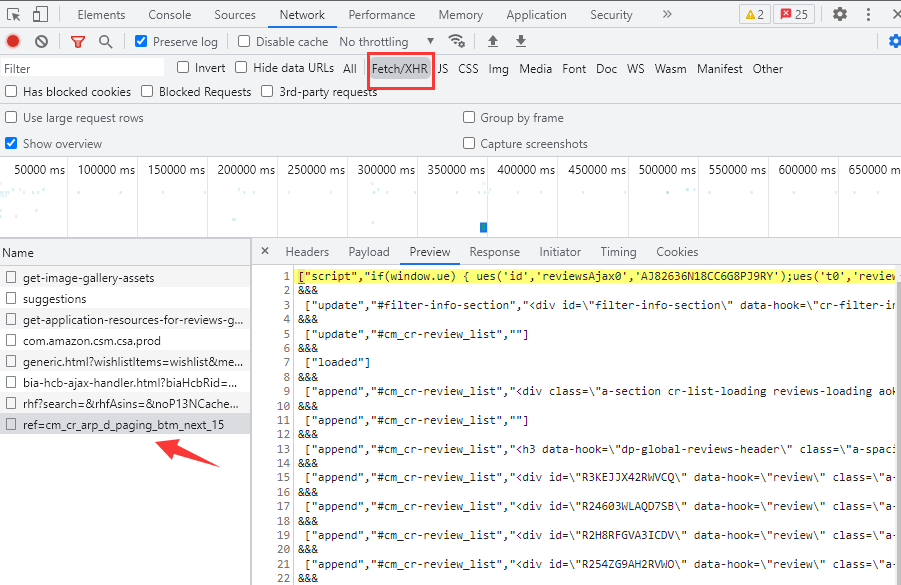
This pile is the unprocessed information. Among the unprocessed information of these requests, the information with data hook = \ "review \" is the information with comments. After analysis, let's write the request step by step.
2, Get Amazon comments
First, put together the post parameters required by the request to request links for automatic page turning in the future, and then post request links with parameters:
headers = {
'authority': 'www.amazon.it',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
}
page = 1
post_data = {
"sortBy": "recent",
"reviewerType": "all_reviews",
"formatType": "",
"mediaType": "",
"filterByStar": "",
"filterByLanguage": "",
"filterByKeyword": "",
"shouldAppend": "undefined",
"deviceType": "desktop",
"canShowIntHeader": "undefined",
"pageSize": "10",
"asin": "B08GHGTGQ2",
}
# Page turning key payload parameter assignment
post_data["pageNumber"] = page,
post_data["reftag"] = f"cm_cr_getr_d_paging_btm_next_{page}",
post_data["scope"] = f"reviewsAjax{page}",
# Page turning link assignment
spiderurl=f'https://www.amazon.it/hz/reviewsrender/ajax/reviews/get/ref=cm_cr_getr_d_paging_btm_next_{page}'
res = requests.post(spiderurl,headers=headers,data=post_data)
if res and res.status_code == 200:
res = res.content.decode('utf-8')
print(res)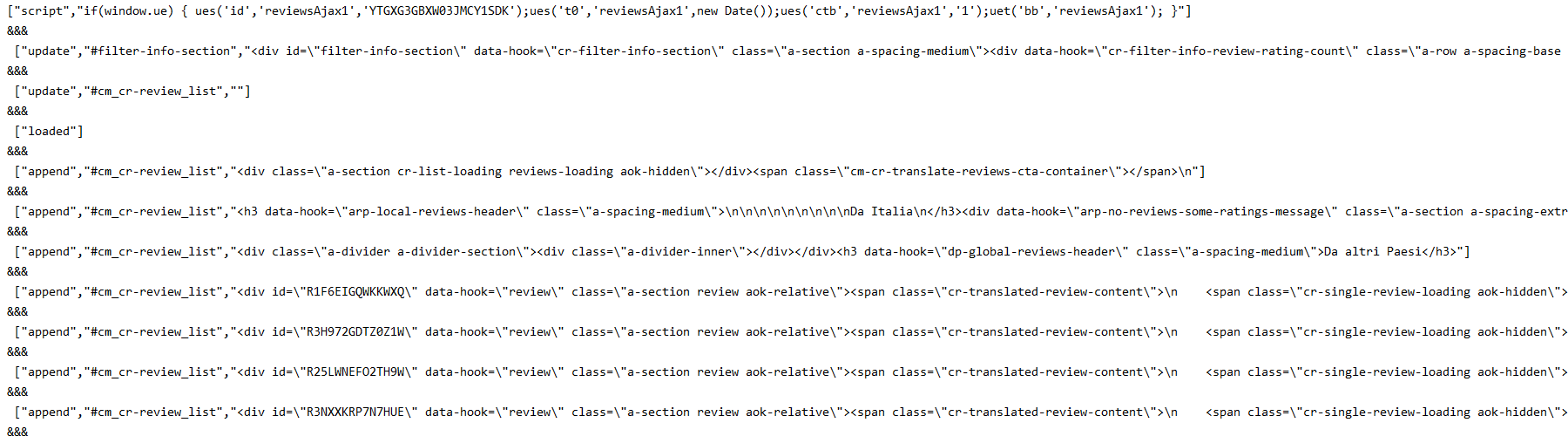
Now that we have obtained this pile of unprocessed information, we will start to process these data.
3, Amazon comments processing
According to the information in the above figure, the information in each section is separated by "& & &", and each piece of information after separation is separated by "," ":

Therefore, use python's split method to separate the string into a list:
# Return value string processing
contents = res.split('&&&')
for content in contents:
infos = content.split('","')The data separated by ', "' is split to generate a new list. The comment content is the last element of the list. Remove the" \ "," \ n "and redundant symbols, and you can select them for processing through css/xpath:
for content in contents:
infos = content.split('","')
info = infos[-1].replace('"]','').replace('\\n','').replace('\\','')
# Comment content judgment
if 'data-hook="review"' in info:
sel = Selector(text=info)
data = {}
data['username'] = sel.xpath('//span[@class="a-profile-name"]/text()').extract_first() # username
data['point'] = sel.xpath('//span[@class="a-icon-alt"]/text()').extract_first() # score
data['date'] = sel.xpath('//span[@data-hook="review-date"]/text()').extract_first() # date address
data['review'] = sel.xpath('//span[@data-hook="review-title"]/span/text()').extract_first() # evaluation title
data['detail'] = sel.xpath('//span[@data-hook="review-body"]').extract_first() # evaluation content
image = sel.xpath('div[@class="review-image-tile-section"]').extract_first()
data['image'] = image if image else "not image" #picture
print(data)4, Code integration
4.1 agent settings
Stable IP proxy is the most powerful tool for your data acquisition. At present, there is still no stable access to Amazon in China, and there will be connection failure. I use it here ipidea Amazon in Italy can obtain the proxy through account secret and api, and the speed is very stable.
Address: http://www.ipidea.net/?utm-source=csdn&utm-keyword=?wb
The following method of proxy acquisition:
# api get ip
def getApiIp(self):
# Get and only get one ip ------ Italy
api_url = 'http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=it&port=1'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('Acquisition failed')
except:
print('Acquisition failed')4.2 while loop page turning
The while loop turns pages. The maximum number of comments is 99 pages. After 99 pages, break out of the while loop:
def getPLPage(self):
while True:
# Page turning key payload parameter assignment
self.post_data["pageNumber"]= self.page,
self.post_data["reftag"] = f"cm_cr_getr_d_paging_btm_next_{self.page}",
self.post_data["scope"] = f"reviewsAjax{self.page}",
# Page turning link assignment
spiderurl = f'https://www.amazon.it/hz/reviews-render/ajax/reviews/get/ref=cm_cr_getr_d_paging_btm_next_{self.page}'
res = self.getRes(spiderurl,self.headers,'',self.post_data,'POST',check)#Self encapsulated request method
if res:
res = res.content.decode('utf-8')
# Return value string processing
contents = res.split('&&&')
for content in contents:
infos = content.split('","')
info = infos[-1].replace('"]','').replace('\\n','').replace('\\','')
# Comment content judgment
if 'data-hook="review"' in info:
sel = Selector(text=info)
data = {}
data['username'] = sel.xpath('//span[@class="a-profile-name"]/text()').extract_first() # username
data['point'] = sel.xpath('//span[@class="a-icon-alt"]/text()').extract_first() # score
data['date'] = sel.xpath('//span[@data-hook="review-date"]/text()').extract_first() # date address
data['review'] = sel.xpath('//span[@data-hook="review-title"]/span/text()').extract_first() # evaluation title
data['detail'] = sel.xpath('//span[@data-hook="review-body"]').extract_first() # evaluation content
image = sel.xpath('div[@class="review-image-tile-section"]').extract_first()
data['image'] = image if image else "not image" #picture
print(data)
if self.page <= 99:
print('Next Page')
self.page += 1
else:
breakFinal integration code:
# coding=utf-8
import requests
from scrapy import Selector
class getReview():
page = 1
headers = {
'authority': 'www.amazon.it',
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
}
post_data = {
"sortBy": "recent",
"reviewerType": "all_reviews",
"formatType": "",
"mediaType": "",
"filterByStar": "",
"filterByLanguage": "",
"filterByKeyword": "",
"shouldAppend": "undefined",
"deviceType": "desktop",
"canShowIntHeader": "undefined",
"pageSize": "10",
"asin": "B08GHGTGQ2",
}
#post_ The asin parameter in data is currently written in
#"https://www.amazon.it/product-reviews/B08GHGTGQ2?ie=UTF8&pageNumber=1&reviewerType=all_reviews&pageSize=10&sortBy=recent"
#In this link, the possibility of asin value change is not excluded. For example, you can get the get request
def getPLPage(self):
while True:
# Page turning key payload parameter assignment
self.post_data["pageNumber"]= self.page,
self.post_data["reftag"] = f"cm_cr_getr_d_paging_btm_next_{self.page}",
self.post_data["scope"] = f"reviewsAjax{self.page}",
# Page turning link assignment
spiderurl = f'https://www.amazon.it/hz/reviews-render/ajax/reviews/get/ref=cm_cr_getr_d_paging_btm_next_{self.page}'
res = self.getRes(spiderurl,self.headers,'',self.post_data,'POST',check)#Self encapsulated request method
if res:
res = res.content.decode('utf-8')
# Return value string processing
contents = res.split('&&&')
for content in contents:
infos = content.split('","')
info = infos[-1].replace('"]','').replace('\\n','').replace('\\','')
# Comment content judgment
if 'data-hook="review"' in info:
sel = Selector(text=info)
data = {}
data['username'] = sel.xpath('//span[@class="a-profile-name"]/text()').extract_first() # username
data['point'] = sel.xpath('//span[@class="a-icon-alt"]/text()').extract_first() # score
data['date'] = sel.xpath('//span[@data-hook="review-date"]/text()').extract_first() # date address
data['review'] = sel.xpath('//span[@data-hook="review-title"]/span/text()').extract_first() # evaluation title
data['detail'] = sel.xpath('//span[@data-hook="review-body"]').extract_first() # evaluation content
image = sel.xpath('div[@class="review-image-tile-section"]').extract_first()
data['image'] = image if image else "not image" #picture
print(data)
if self.page <= 99:
print('Next Page')
self.page += 1
else:
break
# api get ip
def getApiIp(self):
# Get and only get one ip ------ Italy
api_url = 'http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=it&port=1'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('Acquisition failed')
except:
print('Acquisition failed')
#The method of sending a request specifically. The agent requests three times and returns an error if it fails three times
def getRes(self,url,headers,proxies,post_data,method,check):
if proxies:
for i in range(3):
try:
# post request to proxy
if method == 'POST':
res = requests.post(url,headers=headers,data=post_data,proxies=proxies)
# get request to proxy
else:
res = requests.get(url, headers=headers,proxies=proxies)
if res:
return res
except:
print(f'The first{i}Error in request')
else:
return None
else:
for i in range(3):
proxies = self.getApiIp() if check == '1' else self.getAccountIp()
try:
# post request of request agent
if method == 'POST':
res = requests.post(url, headers=headers, data=post_data, proxies=proxies)
# get request from request broker
else:
res = requests.get(url, headers=headers, proxies=proxies)
if res:
return res
except:
print(f"The first{i}Error in request")
else:
return None
if __name__ == '__main__':
getReview().getPLPage()summary
This Amazon comment acquisition is two pits: one is the XHR request method for comment information, and the other is the processing of comment information. After analysis, the data acquisition is still very simple. Find the correct request method, and a stable IP agent will get twice the result with half the effort. Find the common ground of the information for processing, and the problem will be solved.