Web crawler, it sounds mysterious, but it is also so. In short, as long as the website has open port, users can visit the website, no matter how good the anti climbing mechanism of the website is, as long as your technology is enough, there will always be a chance to crack it.
In other words, it's not that your website is secure, it's that your information is not valuable. I accidentally found another website a few days ago. The reason for choosing this website is that there are many video materials in this website, which are rare.
Generally speaking, as long as there is something on the website that can be grabbed down, it depends on whether it has value or not. You can read my previous articles:
- Crawling pictures: Crawler notes (python+requests) for the list of King glory Heroes
- Crawling text: Capture the weather data of all cities in the current period of China Weather Network (python+xpath)
- Simulated landing: Log in to a school intranet using python (operate the browser to log in)
- Mass mailing: Crawling news of a news website and realizing the function of automatic mass mailing (python3+SMTP)
Of course, all the websites I have crawled are open service-oriented websites, which do not involve privacy information. Here I want to say:
Every new technology is like a knife. There is nothing wrong with the knife itself. The key is who uses the knife and what is its purpose.
Learning crawler technology can let us know the operation mechanism of web crawler, so as to improve everyone's security awareness. On the other hand, by learning crawler technology, we can improve our interest in python learning.
Here are the final results: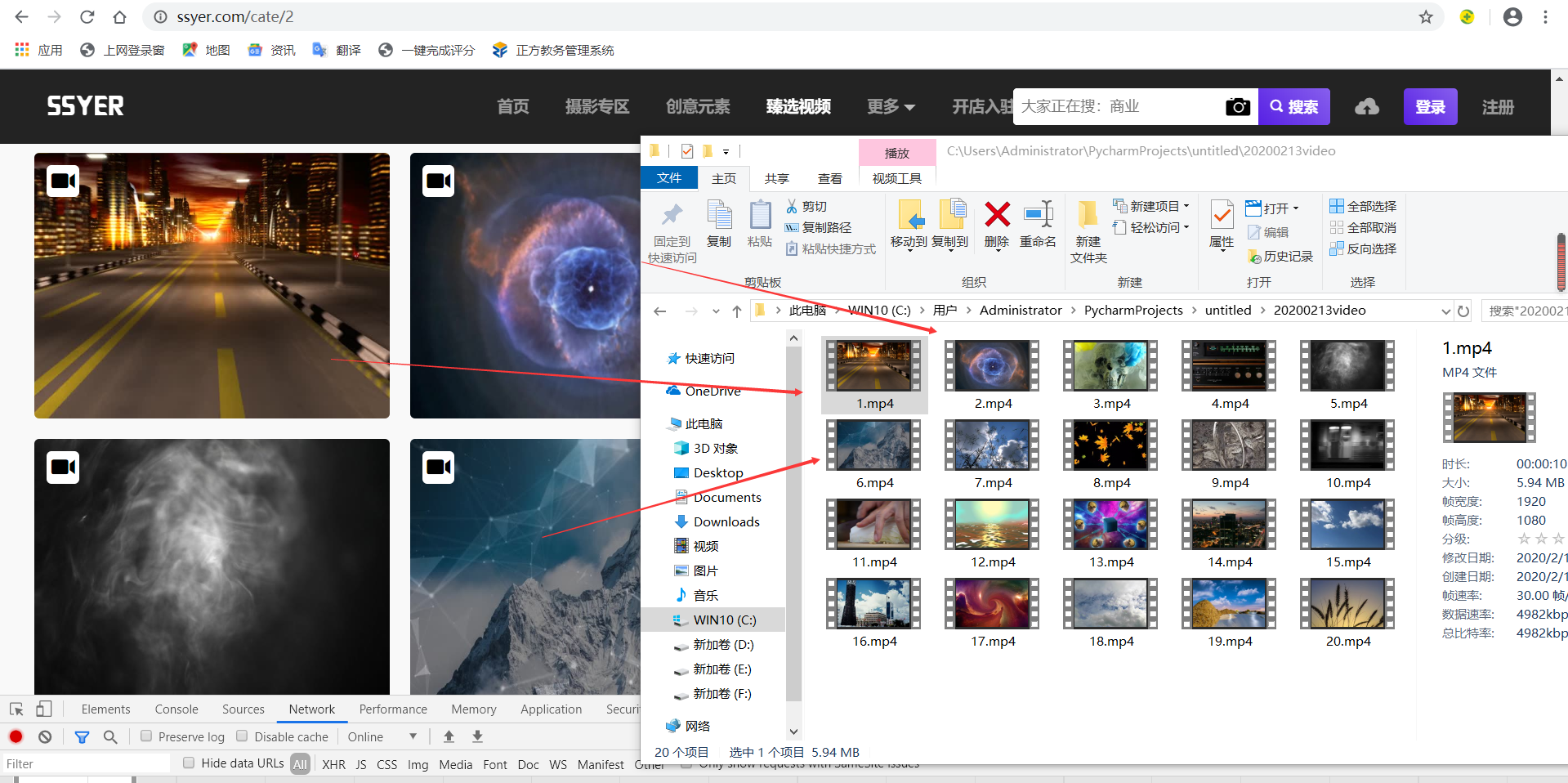
Is it convenient to use crawlers, Download dozens of videos in minutes, and automatically name them?
If we download manually, we still need to log in and repeat all kinds of operations. Ten minutes is not necessarily a solution. Besides, if there are many videos to download, isn't it very troublesome?
This is the advantage of reptiles. Let's talk about the specific methods below
I use Google browser here. Press and hold F12, or right-click to enter the check interface to open it, because what we need is not in the HTML code (if it is, we can use xpath):
So we found the Network option: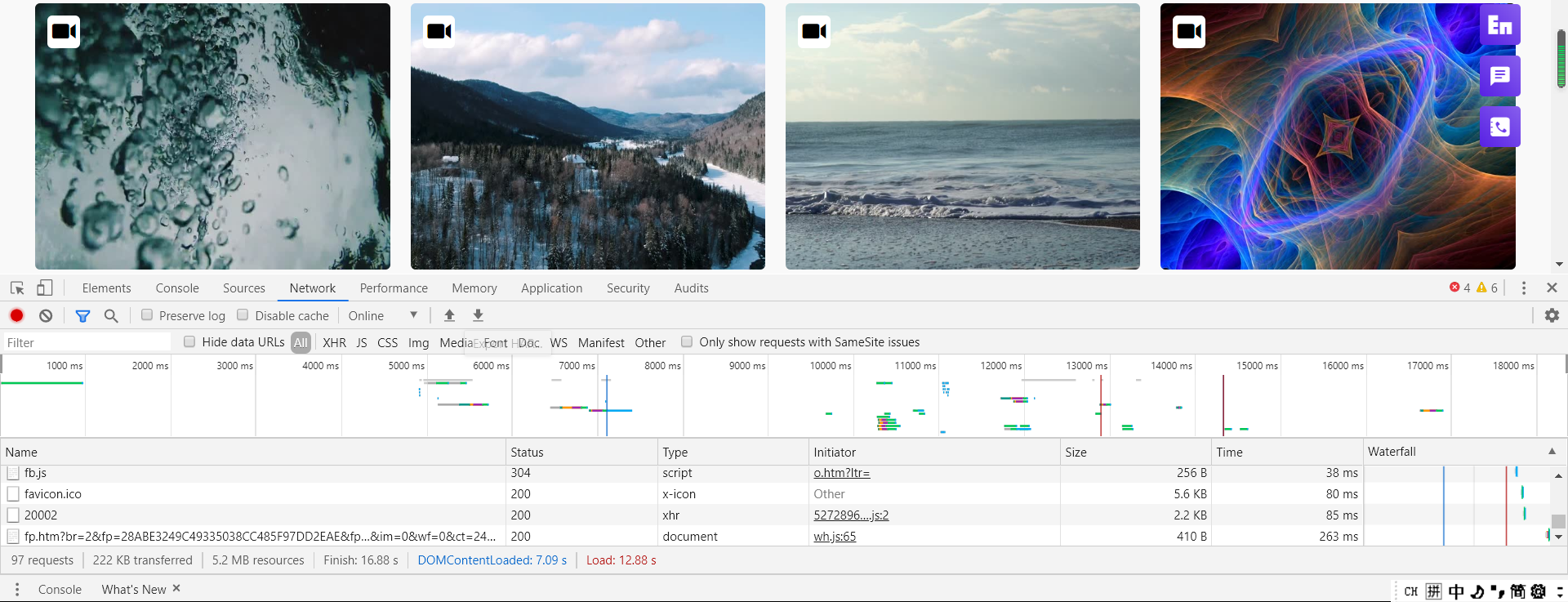
Press Ctrl+R to refresh the interface. You can see that there are many columns below. This is the data returned by the web page. The video we need is in this column. Scroll down: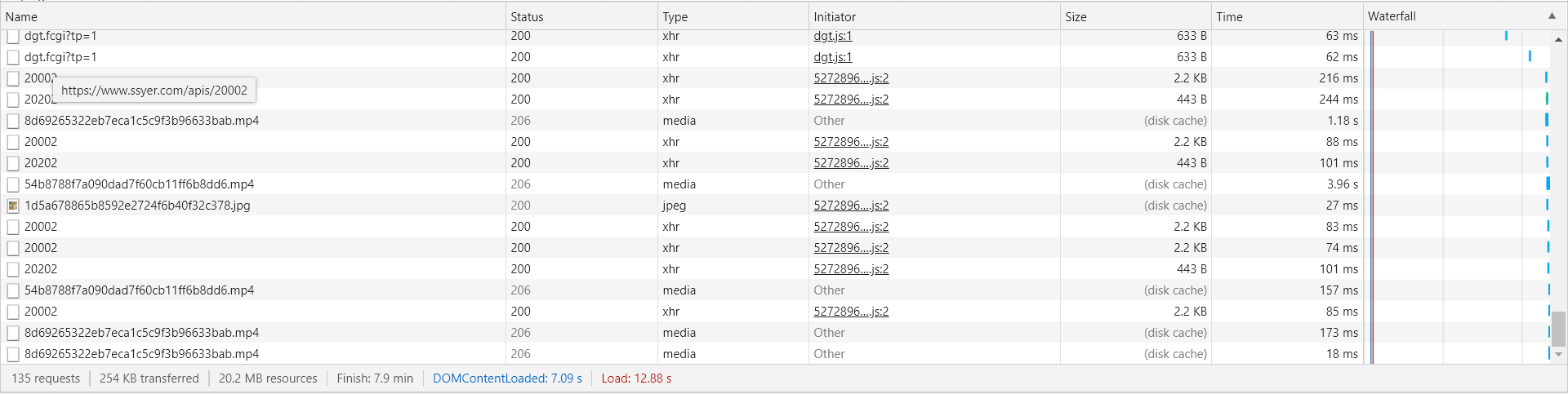
You can see that there are many. MP4 suffixes. I think this should be what we want. Click here to have a look: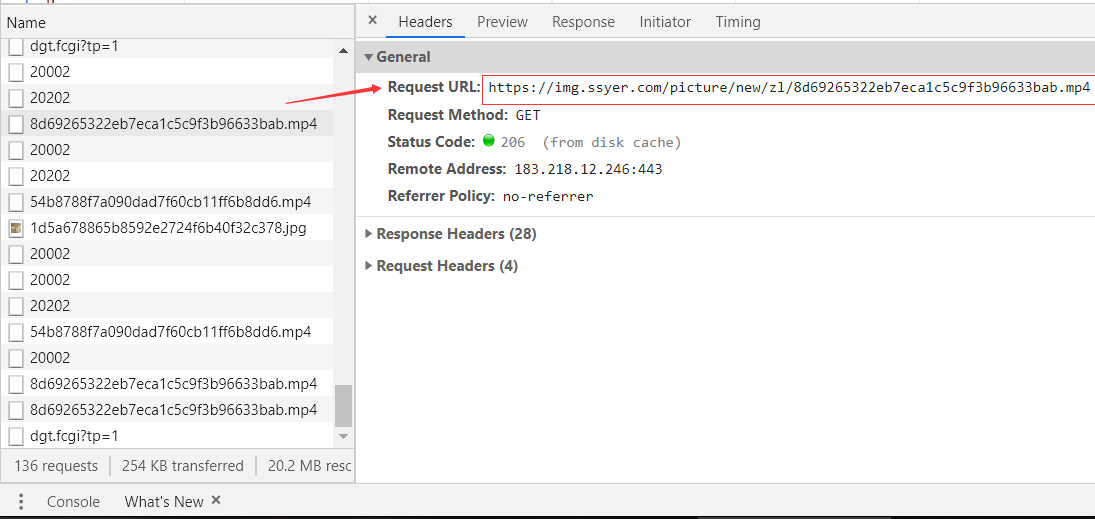
Look at the url here. Let's copy it and open it with a browser: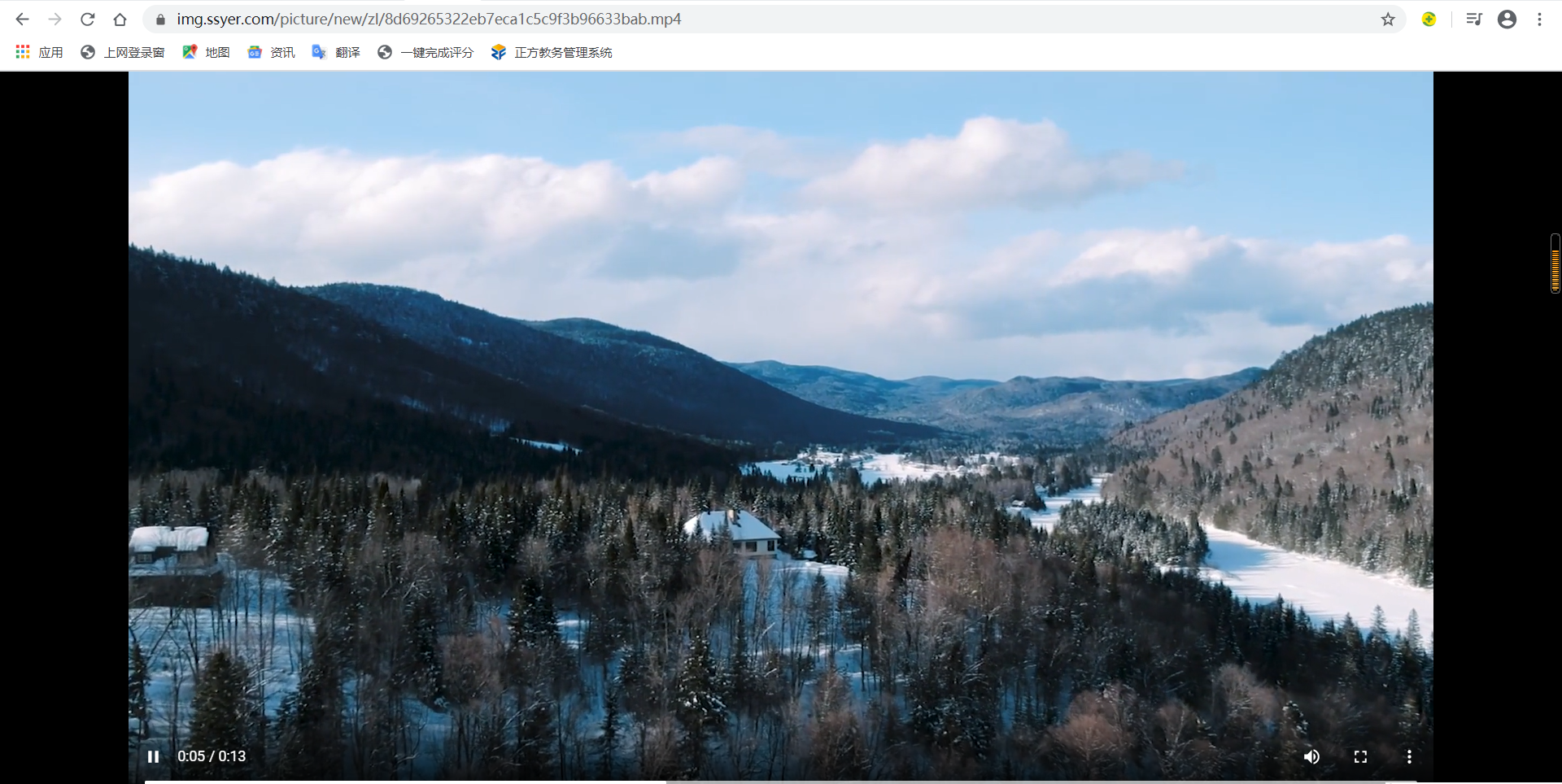
It can be seen that it's really a video, and this video is what we want. However, it's not enough to have only one video. Since it's a batch download, we must find other lists to store these addresses, so we'll look for it again: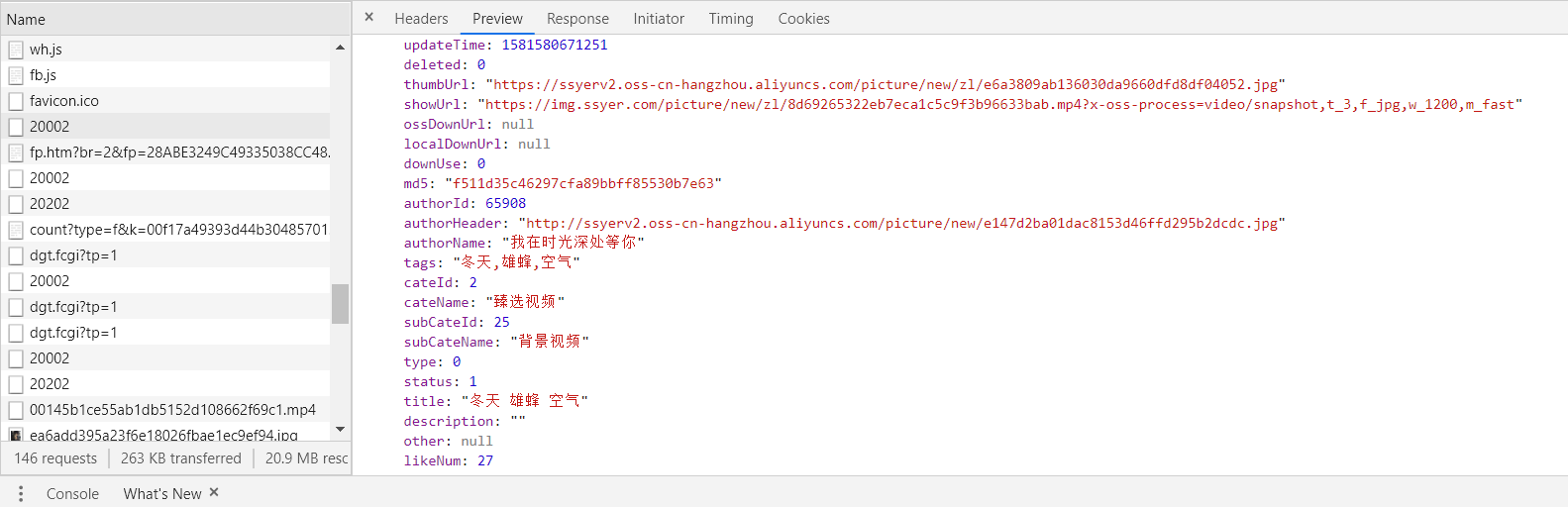
We have found that this 20002 has appeared many times. We can look at it separately. We can see that there is a common point. All 20002 have data, but the data in it is limited. It seems that this data is not the same. Then we will look for it further: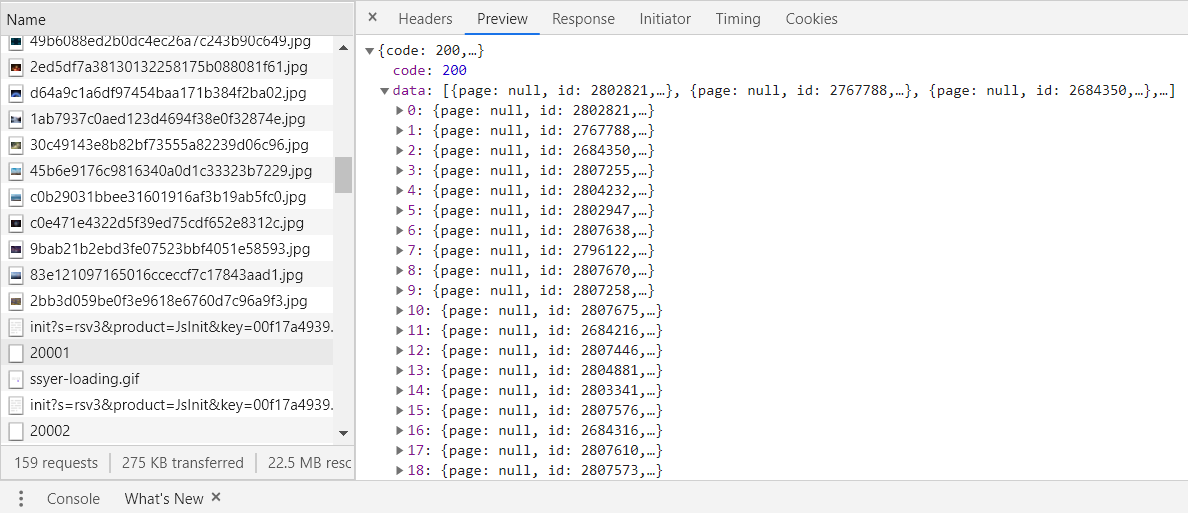
It seems to be approaching. Let's see that there are a lot of data in it. Open it and have a look: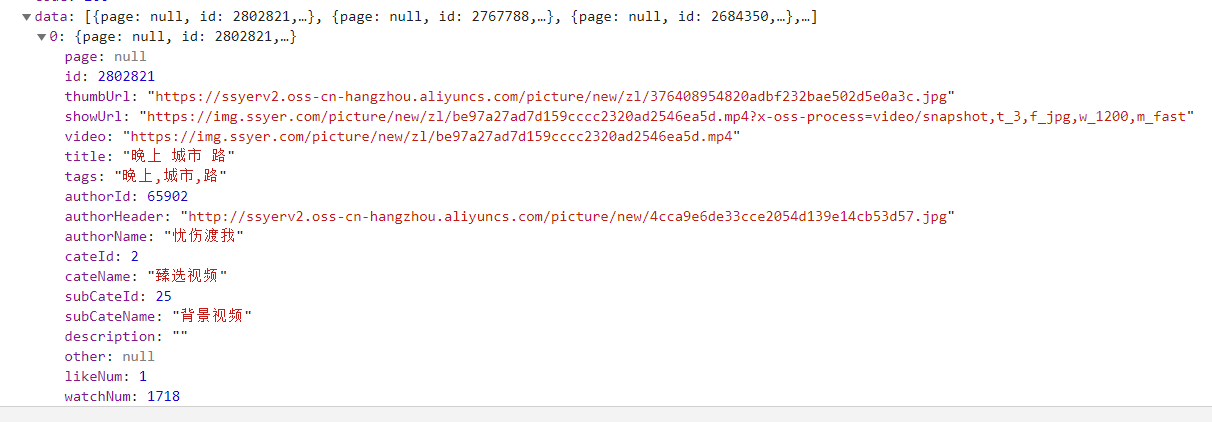
Well, there's something we want. We find his url address in the headers and open it with a browser: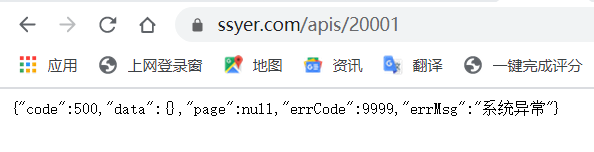
An exception occurred because the request here needs to carry parameters. We found a parsing tool in GitHub: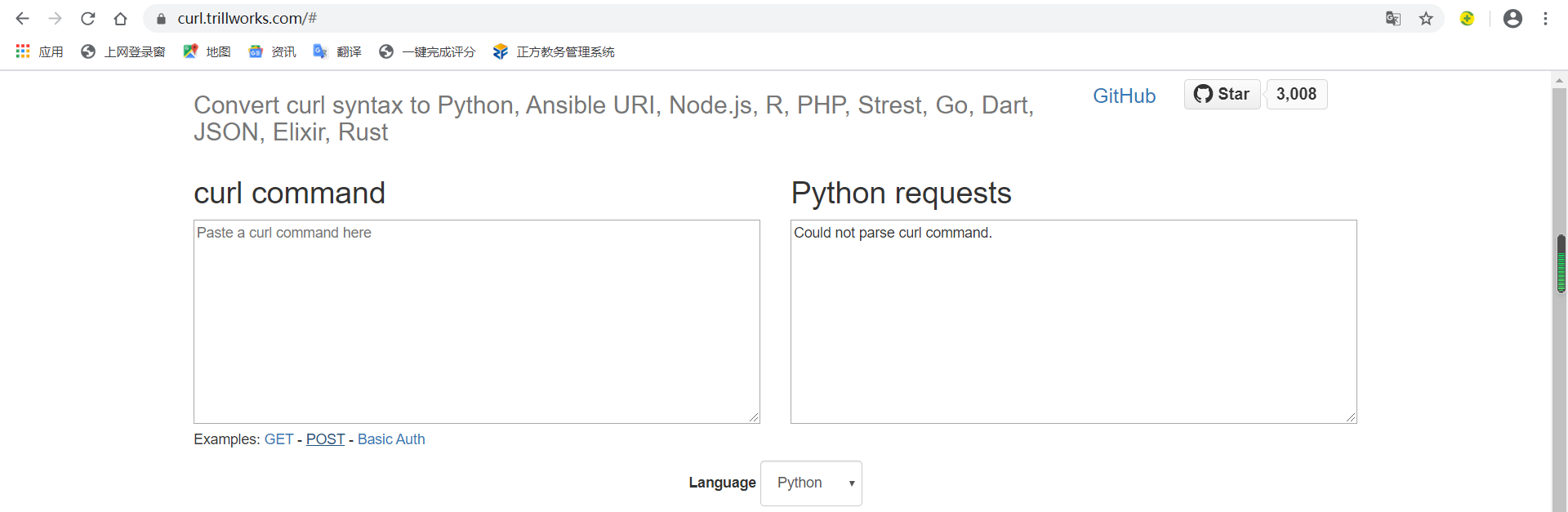
https://curl.trillworks.com/
Go back to the web page: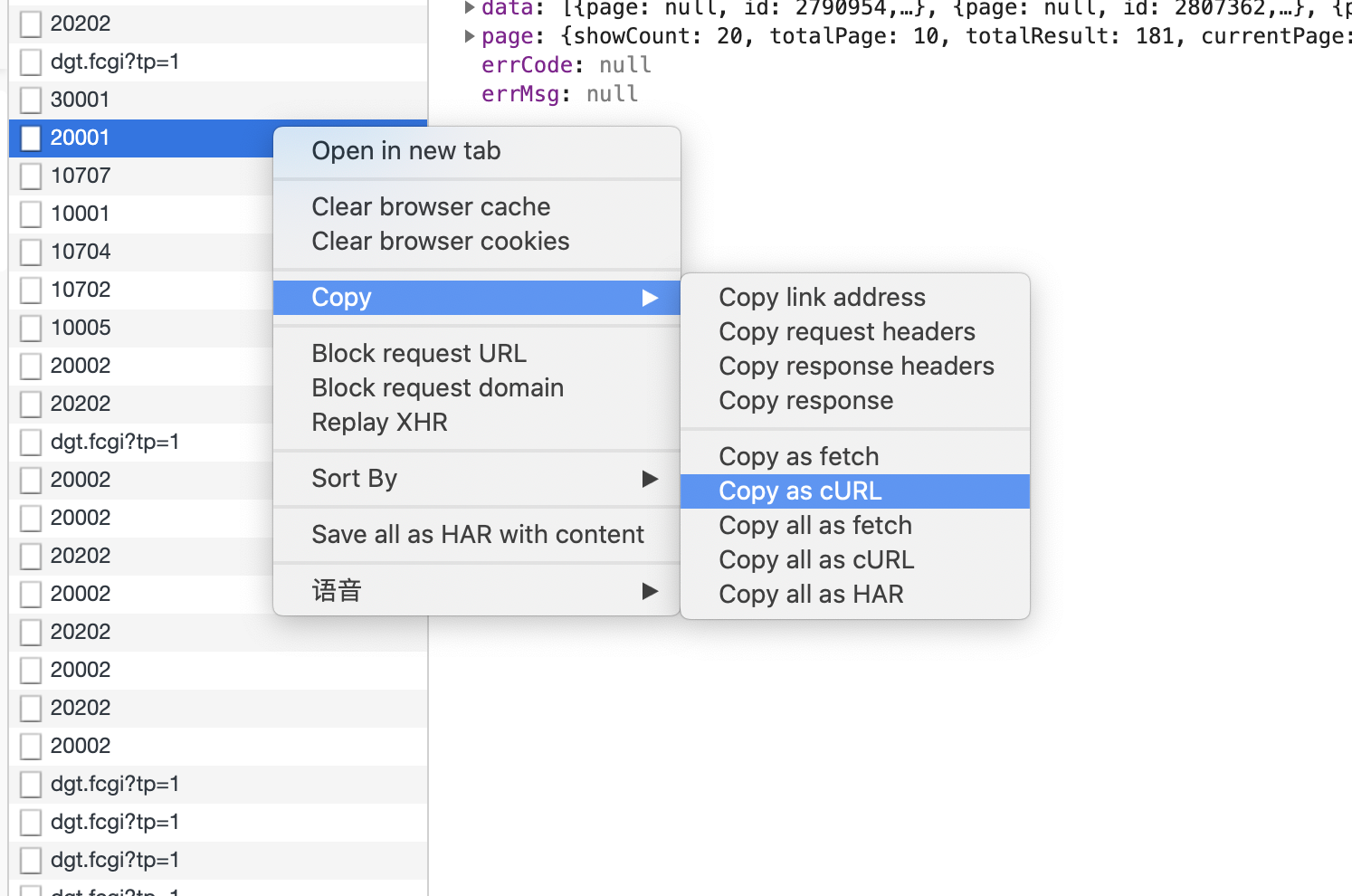
Copy cURL and paste it into curl command: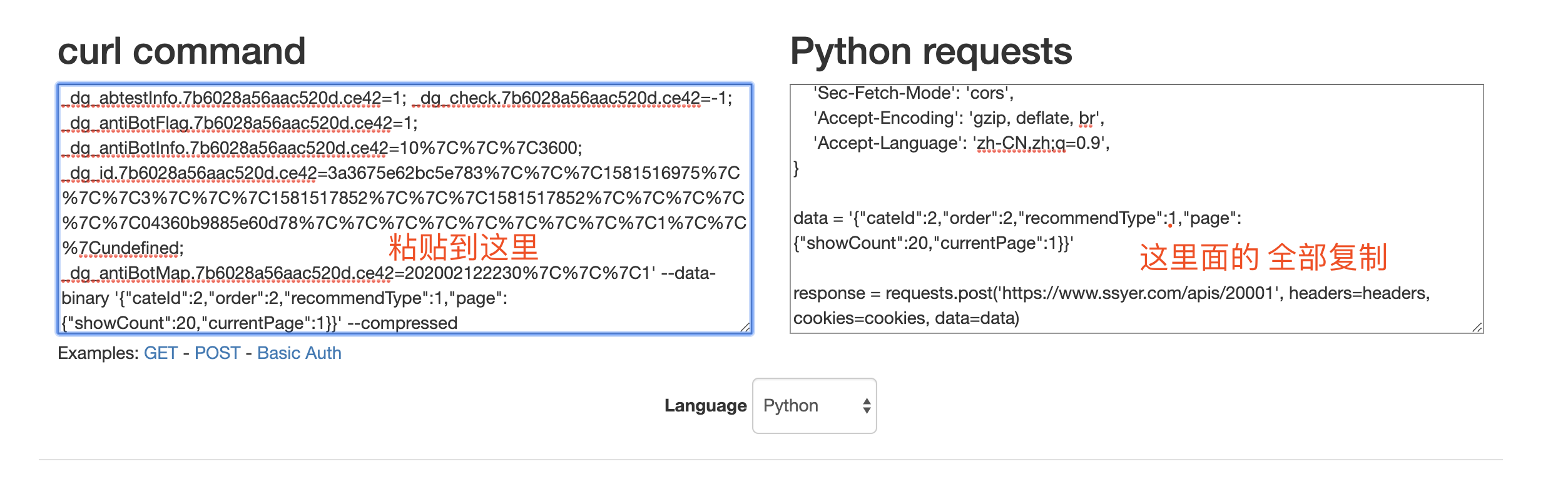
Copy all the python request on the right to the python editor:
import requests cookies = { 'BAIDU_SSP_lcr': 'https://www.baidu.com/link?url=kzwk2tY6VdLzGcc1Nfo9AWYgrzw-jxD1wVstT4gKkku&wd=&eqid=90bb793e00089362000000065e43d96c', '_dg_playback.7b6028a56aac520d.ce42': '1', '_dg_abtestInfo.7b6028a56aac520d.ce42': '1', '_dg_check.7b6028a56aac520d.ce42': '-1', '_dg_antiBotFlag.7b6028a56aac520d.ce42': '1', '_dg_antiBotInfo.7b6028a56aac520d.ce42': '10%7C%7C%7C3600', 'SESSION': 'OTIyZGE2ZTgtMjM0Yi00NmZjLWEyM2MtMmJiYTVhMzEwZWJj', '_dg_id.7b6028a56aac520d.ce42': 'bdbb5697b510c5bc%7C%7C%7C1581504892%7C%7C%7C9%7C%7C%7C1581509404%7C%7C%7C1581509342%7C%7C%7C%7C%7C%7C53b348475c9a517a%7C%7C%7C%7C%7C%7Chttps%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Dkzwk2tY6VdLzGcc1Nfo9AWYgrzw-jxD1wVstT4gKkku%26wd%3D%26eqid%3D90bb793e00089362000000065e43d96c%7C%7C%7C1%7C%7C%7Cundefined', } headers = { 'Connection': 'keep-alive', 'Accept': 'application/json', 'Sec-Fetch-Dest': 'empty', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36', 'Content-Type': 'application/json', 'Origin': 'https://www.ssyer.com', 'Sec-Fetch-Site': 'same-origin', 'Sec-Fetch-Mode': 'cors', 'Accept-Language': 'zh-CN,zh;q=0.9', } data = '{"cateId":2,"order":2,"recommendType":1,"page":{"showCount":20,"currentPage":2}}' response = requests.post('https://www.ssyer.com/apis/20001', headers=headers, cookies=cookies, data=data) print(response)
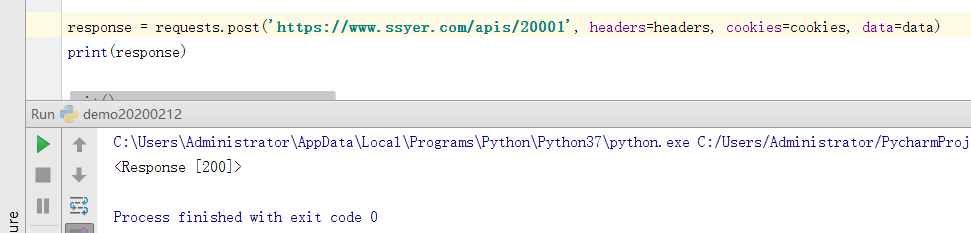
200 means the request is successful. Let's analyze it here:
After the response, add. text:
response = requests.post('https://www.ssyer.com/apis/20001', headers=headers, cookies=cookies, data=data).text
It can be seen that what we want is in it, as long as we extract it:
response = requests.post('https://www.ssyer.com/apis/20001', headers=headers, cookies=cookies, data=data) json_datas = response.json() json_data = json_datas['data']
Here we save the downloaded video in a folder called "20200213video":
video_path = '20200213video' if not os.path.exists(video_path): os.mkdir(video_path)
Next, use a loop to extract and download:
for item in range(len(json_data)): print(json_data[item]['video']) print("Downloading section%s One video"%(item+1)) file_path = video_path+'/'+ '%s'%(item+1) +'.mp4' urlretrieve(json_data[item]['video'],file_path,cbk)
Briefly speaking, urlretrieve() in the last sentence is the function responsible for downloading files. The download address is on the left side of the bracket, and the saved address is in the middle. The third is to check the download progress:
def cbk(a,b,c): '''Callback function a:Downloaded data block b:Block size c:Size of the remote file ''' per=100.0*a*b/c if per>100: per=100 print('%.2f%%' % per)
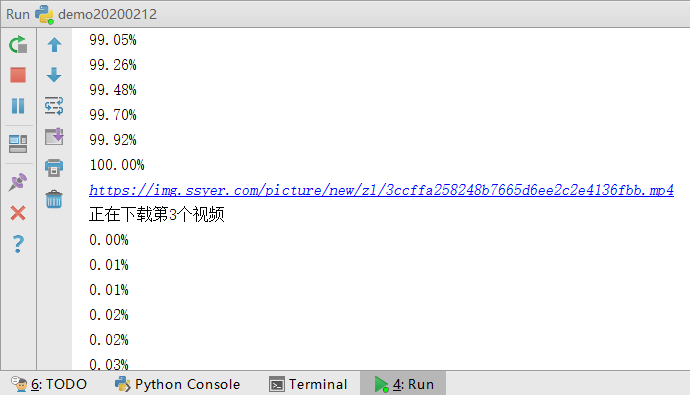
But downloading a video only takes a few seconds, which seems to be more than enough, so this step can also be avoided: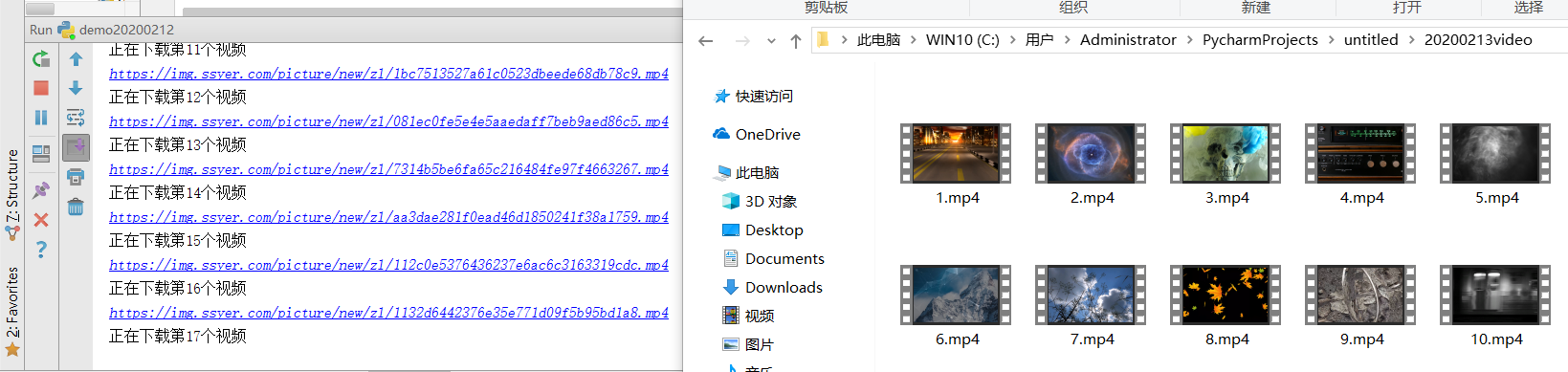
We can play the following video:
Make sure you have eyes. It's a video that can be played. Today's content is over here. If you have any questions, please leave a message in the comment area!

