Picture of Hummingbird Net--Introduction
Play fresh today, using a new library aiohttp to speed up our crawls.
Installation module routine
pip install aiohttp
After running, wait, install, want to further study, then the official documents are necessary: https://aiohttp.readthedocs.io/en/stable/
Now you can start writing code.
The page we want to crawl is selected this time
http://bbs.fengniao.com/forum/forum_101_1_lastpost.html
Open the page and we can easily get the page number
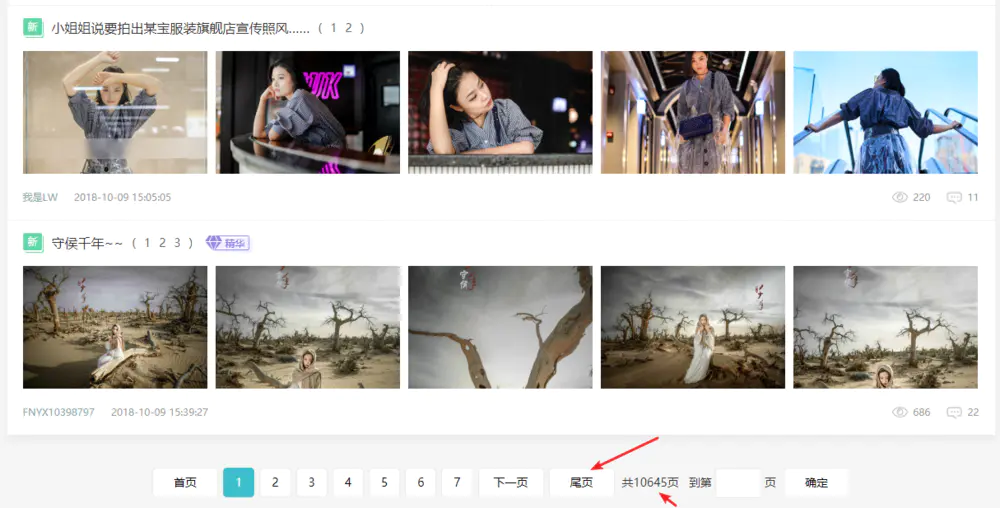
It has been a long time since I could see the page number so easily.

Try to access this page with aiohttp, the introduction of modules, nothing special, just import
If we need to write crawls using Asyncio + Aiohttp asynchronous IO, then note that you need to precede the asynchronous method with async
Next, try to get the web source code of the address above.
The code first declares a function of fetch_img_url with a parameter that can also be written directly to death.
Instead of prompting, search for relevant information yourself ('<<)
aiohttp.ClientSession() as session: Create a session object and use it to open a Web page.Session can do many things, such as post, get, put, etc.
await response.text() in code waiting for web data to return
asyncio.get_event_loop creates a thread, and the run_until_complete method is responsible for scheduling tasks in tasks.Tasks can be a separate function or a list.
import aiohttp
import asyncio
async def fetch_img_url(num):
url = f'http://bbs.fengniao.com/forum/forum_101_{num}_lastpost.html'#String Stitching
# Or write directly as url ='http://bbs.fengniao.com/forum/forum_101_1_lastpost.html'
print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6726.400 QQBrowser/10.2.2265.400',
}
async with aiohttp.ClientSession() as session:
# Get Round-robin Map Address
async with session.get(url,headers=headers) as response:
try:
html = await response.text() # Get Web Source
print(html)
except Exception as e:
print("Basic Error")
print(e)
# You can copy this part directly
loop = asyncio.get_event_loop()
tasks = asyncio.ensure_future(fetch_img_url(1))
results = loop.run_until_complete(tasks)
Python Resource Sharing qun 784758214 ,Installation packages are included. PDF,Learn video, here is Python The place where learners gather, zero base, advanced, all welcomeThe last part of the code above can also be written as
loop = asyncio.get_event_loop() tasks = [fetch_img_url(1)] results = loop.run_until_complete(asyncio.wait(tasks))
Okay, if you've got the source code for your work, you're not close to your ultimate goal and you've lost it.
Modify the code to get 10 pages in bulk.
You just need to modify tasks, run it here and see the following results
tasks = [fetch_img_url(num) for num in range(1, 10)]
The following series of actions are very similar to the previous blog, looking for patterns.
Open a page at random
http://bbs.fengniao.com/forum/forum_101_4_lastpost.html
Click on a picture to go to the inside page, click on a picture on the inside page to go to a round-robin page

Click again to enter the picture playback page

Finally, we found all the picture links in the source code on the picture playback page, so the question arises, how can we change from the first link above to the link of the broadcast map???
The following source code is viewed at http://bbs.fengniao.com/forum/pic/slide_101_10408464_893854.html by right-clicking.

Continue to analyze ~~~(= = o)
http://bbs.fengniao.com/forum/forum_101_4_lastpost.html //Change to the link below? http://bbs.fengniao.com/forum/pic/slide_101_10408464_89383854.html
Continuing with the first link, we use the F12 Developer Tool to grab a picture and see it.
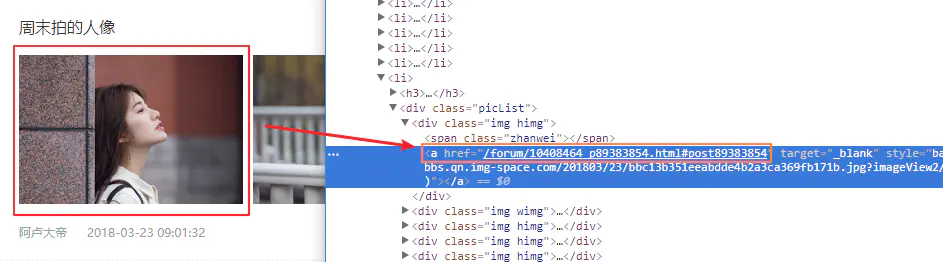
The location of the picture's winning * box, we found the number we want, so good, we just need to match them through regular expressions.
The code is in the following ### location, it should be noted that I used the original regular matching, in the process of writing the regular expression, I found that one step did not exactly match, can only be divided into two steps, you can see the specific details o (o)
- Find all pictures < div class="picList">
- Get the two parts of the number we want
async def fetch_img_url(num):
url = f'http://bbs.fengniao.com/forum/forum_101_{num}_lastpost.html'
print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6726.400 QQBrowser/10.2.2265.400',
}
async with aiohttp.ClientSession() as session:
# Get Round-robin Map Address
async with session.get(url,headers=headers) as response:
try:
###############################################
url_format = "http://bbs.fengniao.com/forum/pic/slide_101_{0}_{1}.html"
html = await response.text() # Get Web Source
pattern = re.compile('<div class="picList">([\s\S.]*?)</div>')
first_match = pattern.findall(html)
href_pattern = re.compile('href="/forum/(\d+?)_p(\d+?)\.html')
urls = [url_format.format(href_pattern.search(url).group(1), href_pattern.search(url).group(2)) for url in first_match]
##############################################
except Exception as e:
print("Basic Error")
print(e)
Python Resource Sharing qun 784758214 ,Installation packages are included. PDF,Learn video, here is Python The place where learners gather, zero base, advanced, all welcomeThe code is complete, we've got the URL we want, so let's go ahead and read the URL's internal information and match the link to the picture we want
async def fetch_img_url(num):
# Copy the code above
async with aiohttp.ClientSession() as session:
# Get Round-robin Map Address
async with session.get(url,headers=headers) as response:
try:
#Copy the code above
################################################################
for img_slider in urls:
try:
async with session.get(img_slider, headers=headers) as slider:
slider_html = await slider.text() # Get Web Source
try:
pic_list_pattern = re.compile('var picList = \[(.*)?\];')
pic_list = "[{}]".format(pic_list_pattern.search(slider_html).group(1))
pic_json = json.loads(pic_list) # The list of pictures is available
print(pic_json)
except Exception as e:
print("Code Debugging Errors")
print(pic_list)
print("*"*100)
print(e)
except Exception as e:
print("Get Picture List Error")
print(img_slider)
print(e)
continue
################################################################
print("{}Operation completed".format(url))
except Exception as e:
print("Basic Error")
print(e)

The final JSON of the picture has been taken, the last step, download the picture, when ~~~, a rapid operation, the picture will be taken down
async def fetch_img_url(num):
# Code to find above
async with aiohttp.ClientSession() as session:
# Get Round-robin Map Address
async with session.get(url,headers=headers) as response:
try:
# Code to find above
for img_slider in urls:
try:
async with session.get(img_slider, headers=headers) as slider:
# Code to find above
##########################################################
for img in pic_json:
try:
img = img["downloadPic"]
async with session.get(img, headers=headers) as img_res:
imgcode = await img_res.read() # Picture reading
with open("images/{}".format(img.split('/')[-1]), 'wb') as f:
f.write(imgcode)
f.close()
except Exception as e:
print("Picture download error")
print(e)
continue
###############################################################
except Exception as e:
print("Get Picture List Error")
print(img_slider)
print(e)
continue
print("{}Operation completed".format(url))
except Exception as e:
print("Basic Error")
print(e)
Python Resource Sharing qun 784758214 ,Installation packages are included. PDF,Learn video, here is Python The place where learners gather, zero base, advanced, all welcomePictures will be generated quickly in the images folder that you wrote in advance
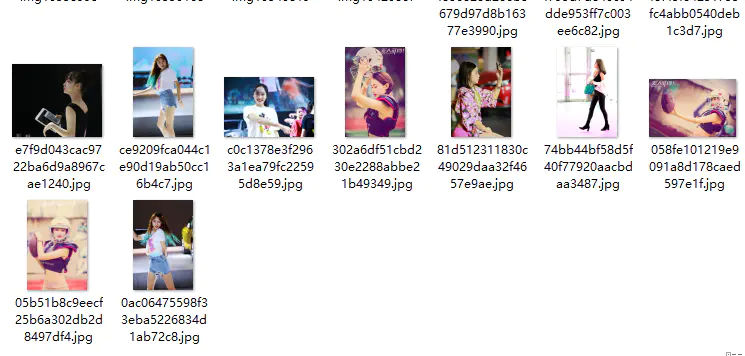
tasks can start a maximum of 1024 protocols, but it is recommended that you start 100 protocols to OK. Too many concurrent operations will overwhelm your home server.
Once you've done that, add some details, such as saving to a specified folder, and OK is done.