Query interface
As a big data storage service, table storage provides a variety of data output interfaces, mainly including: single row read (GetRow), batch GetRow, range read (GetRange), multiple index Search (Search) and channel service data subscription (Tunnel Service). This article will describe the function, use and limitation of range reading in detail.
Function description
The GetRange interface provides the range reading ability of the datastore. Through the interface, the data in the range will be returned page by page in the specified order (positive or negative). Users need to provide the primary keys of the range start and end to limit the range of data. If the total data fails to be returned completely by one request, you can continue to traverse the next page through continuous page turning to get the complete result.
Restrictive conditions
More than 5000 rows of data are returned at a time, or the data size of the returned data is greater than 4 MB. If any of the above conditions are met, the data exceeding the upper limit will be truncated by row level and the data primary key information of the next row will be returned.
API definition
message GetRangeRequest { required string table_name = 1; // Table name required Direction direction = 2; // Return order repeated string columns_to_get = 3; // Return column parameters optional TimeRange time_range = 4; // Return column version number range optional int32 max_versions = 5; // Number of returned column versions optional int32 limit = 6; // Limit on the number of rows returned in a single request required bytes inclusive_start_primary_key = 7; // Range request start primary key required bytes exclusive_end_primary_key = 8; // Range request end primary key optional bytes filter = 10; // Conditional filtering optional string start_column = 11; // Return property column column name start optional string end_column = 12; // Return property column column name end optional bytes token = 13; // obsolete optional string transaction_id = 14; // Transaction ID } message GetRangeResponse { required ConsumedCapacity consumed = 1; // Cu consumption statistics required bytes rows = 2; // Row data results returned optional bytes next_start_primary_key = 3; // Page turning ID, starting primary key of next page optional bytes next_token = 4; // obsolete }
Parameter description
table_name
Table name, scope read interface only requests one table;
direction
Direction or order, range read positive order (primary key from small to large), reverse order (primary key from large to small) return, default setting positive order.
columns_to_get
Return column name, return column field, support all columns return. If the column name is specified but the column does not exist, the whole row of data will not be returned (it does not mean that the row does not exist).
time_range
Version number range. The property value version number returns the range.
max_versions
The maximum number of version numbers, and the maximum number of property value versions.
limit
The number of rows in a single request is limited. If there is conditional filtering or the row data is large, the actual number of rows returned may be less than the parameter, which does not mean there is no data later. Whether the next start primary key in the response is empty is to be judged.
Range setting
The start and end of the boundary are complete primary keys, representing specific range locations. In reverse order, the start primary key must be greater than the end primary key. The scope contains the following two parameters:
- Include start primary key: the starting value of the primary key (including the boundary);
- Exclusive end primary key: the end value of the primary key (excluding the boundary);
filter
Condition filter, which can provide condition filter filter of column value. Support the comparison of column values greater than, less than, equal to, and the and or non mixed conditions of multi column fields.
Wide line reading
Specifies the read parameters of the column name range, and the fields are arranged in string order based on the property columns within the range. There are two parameters as follows:
- Start column: the actual field of the property column;
- End column: the end field of the property column;
transaction_id
Transaction ID, which supports transaction reading. Range query request is a request for a table. If the data range is limited to a partition key, transaction query capability can be provided.
Functions and examples
Leftmost matching
The data storage in the table is based on the orderly arrangement of PrimaryKey. The primary table is a special union index based on primary key. Therefore, data range query follows the leftmost matching principle of union index. That is, if a column provides a specific range value (not a single value) during range query, the range restriction constraint of the next column is invalid. Refer to the following figure for details: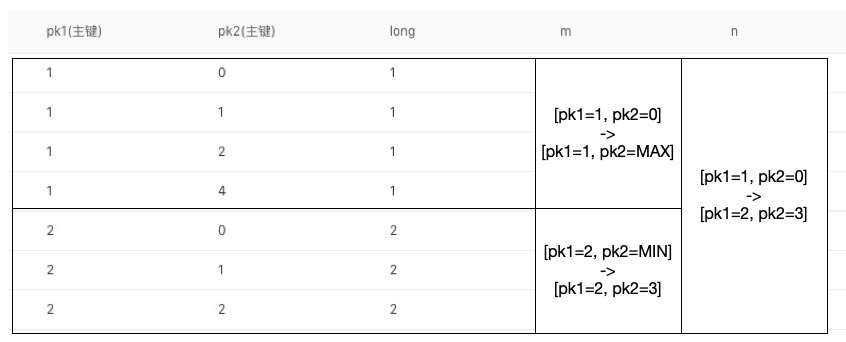
In the above example, the start and end of the primary key in the first column are different, resulting in the restriction in the second column not being effective, and the row with pk2=4 will also appear in the result. Only when the start and end parameters of the current column are the same, the start and end constraints of the column are valid. If users need to query all rows with limited scope of pk2, they should consider creating a secondary index with pk2 as the primary key of the first column of the index.
Continuous page turning
When a single request for range condition data fails to get the full amount of data, the user needs to page continuously based on NextStartPrimaryKey to traverse all hit data. If GetRangeResponse.getNextStartPrimaryKey() is not empty, there must be data. By setting the acquired PrimaryKey to the original request, rebuild it, and then initiate the request again.
- Note: the end of page turning cannot be judged by the number of lines equal to zero.
PrimaryKey nextStartPrimaryKey = null; do { GetRangeResponse getRangeResponse = syncClient.getRange(getRangeRequest); List<Row> pageRowList = getRangeResponse.getRows(); // Determine the existence of the next page, and refactor the request nextStartPrimaryKey = getRangeResponse.getNextStartPrimaryKey(); if (nextStartPrimaryKey != null) { // Determine the existence of the next page, and refactor the request criteria.setInclusiveStartPrimaryKey(nextStartPrimaryKey); getRangeRequest.setRangeRowQueryCriteria(criteria); } } while (nextStartPrimaryKey != null); // Keep turning until there is no next page
iterator
In order to facilitate users to traverse full data, we provide an iterator interface. Users don't need to care about the logic of request construction and result judgment. They just need to build GetRangeIterator with asynchronous Client and request body as parameters. The iterator automatically initiates the request internally. After consuming one page of data, it will automatically initiate the request for the next page;
AsyncClient asyncClient = (AsyncClient) syncClient.asAsyncClient(); GetRangeIterator getRangeIterator = new GetRangeIterator(asyncClient, getRangeRequest); while (getRangeIterator.hasNext()) { Row row = getRangeIterator.next(); }
Filter
The filter conditions of the table storage filter support arithmetic operation (=,! =, >, > =, < AND < =) AND logical operation (NOT, AND, OR). The combination of up to 10 conditions is supported. Through condition combination, limit the constraint of column (including primary key) attribute value. Limit limits the number of results before filtering. After filtering, the actual returned results may be less than limit OR even no data.
SingleColumnValueFilter
Single column conditional filter parameters. Example: Col0 == 0
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("Col0", SingleColumnValueFilter.CompareOperator.EQUAL, ColumnValue.fromLong(0)); // If Col0 does not exist, it will not return.
CompositeColumnValueFilter
Combining multiple arithmetic operation symbols achieves the effect of multi conditional combination filtering. Example: Col0 = = 0 and col1 > = 100
CompositeColumnValueFilter composite1 = new CompositeColumnValueFilter(CompositeColumnValueFilter.LogicOperator.AND); SingleColumnValueFilter single1 = new SingleColumnValueFilter("Col0", SingleColumnValueFilter.CompareOperator.EQUAL, ColumnValue.fromLong(0)); SingleColumnValueFilter single2 = new SingleColumnValueFilter("Col1", SingleColumnValueFilter.CompareOperator.GREATER_THAN, ColumnValue.fromLong(100)); composite1.addFilter(single1); composite1.addFilter(single2);
PassIfMissing
In addition, due to the sparse column attribute, the attribute column of some rows may not exist. At this time, you can use the PassIfMissing parameter to set the desired filtering form.
- True: returns if the column does not exist;
- False: indicates that this column does not exist and does not return.
Example: do not return when the column does not exist
singleColumnValueFilter.setPassIfMissing(false);
Form storage user manual
This paper introduces the basic functions and usage of Tablestore in data management with the interface calling code of Java SDK. The code has been open-source in the Tablestore examples project, and users can run it directly. Based on the sample code and articles, new users can start to use the Tablestore more simply and quickly, and welcome new and old users to use and make suggestions.
Through the continuous output of basic use functions, we will sort out a complete set of user manual (including executable samples), please look forward to it.
Expert services
If you have any questions or need better online support, welcome to join pin group: "open communication group of form storage". Free online expert service is provided in the group, welcome to scan code to join, group number: 23307953