Linux Interrupt Subsystem (3) GIC Interrupt Processing
Remarks:
_1.Kernel version: 5.4
_2.Use tools: Source Insight 4.0
_3.Reference Blog:
Linux interrupt subsystem (1) Interrupt controller and driver analysis
Linux Interrupt Subsystem (2) - General Framework Processing
Hematemesis | Liver flip Linux interrupts all knowledge points
Linux kernel interrupt subsystem (6): ARM interrupt processing
Preparing for interrupt processing
stack preparation for interrupt mode
_ARM processors have a variety of processor mode s, such as user mode (the mode in which the user-space AP is in), supervisor mode (the SVC mode in which most of the kernel-state code is in), IRQ mode (the processor will switch into that mode after an interrupt)For Linux kernels, the ARM processor is mostly in SVC mode during interrupt processing. However, when interrupts actually occur, the ARM processor actually enters IRQ mode, so there will be a short period of IRQ mode operation before the real IRQ exception handling, and then the SVC mode for true IRQ exception handling because of IRQ.The model is just an overrun, so the IRQ model stack is small, with only 12 bytes, as follows:
//Source: arch/arm/kernel/setup.c
struct stack {
u32 irq[3];
u32 abt[3];
u32 und[3];
u32 fiq[3];
} ____cacheline_aligned;
#ifndef CONFIG_CPU_V7M
static struct stack stacks[NR_CPUS];
#endif
_In addition to irq mode, Linux kernels handle abt mode (the mode entered when data abort exception or prefetch abort exception occurs) and und mode (the exception mode entered when the processor encounters an undefined instruction)That is, after a short abt or und model, the stack switches to the stack of the SVC model, which is the core stack of the current thread s at the point where the exception occurred. anyway, in irq mode and SVCThere is always a stack between modes to hold the data, which is the stack of interrupt mode. When the system is initialized, the stack of interrupt mode is set in the cpu_init function:
/*
* cpu_init - initialise one CPU.
*
* cpu_init sets up the per-CPU stacks.
*/
void notrace cpu_init(void)
{
#ifndef CONFIG_CPU_V7M
unsigned int cpu = smp_processor_id(); //Get CPU ID
struct stack *stk = &stacks[cpu]; //Gets the stack pointer for irq abt and und of the CPU
if (cpu >= NR_CPUS) {
pr_crit("CPU%u: bad primary CPU number\n", cpu);
BUG();
}
/*
* This only works on resume and secondary cores. For booting on the
* boot cpu, smp_prepare_boot_cpu is called after percpu area setup.
*/
set_my_cpu_offset(per_cpu_offset(cpu));
cpu_proc_init();
/*
* Define the placement constraint for the inline asm directive below.
* In Thumb-2, msr with an immediate value is not allowed.
*/
#ifdef CONFIG_THUMB2_KERNEL
#Under define PLC "r" //Thumb-2, the msr directive does not allow immediate numbers, only registers
#else
#define PLC "I"
#endif
/*
* setup stacks for re-entrant exception handlers
*/
__asm__ (
"msr cpsr_c, %1\n\t" //Enter CPU into IRQ mode
"add r14, %0, %2\n\t" //r14 Register Save stk->irq
"mov sp, r14\n\t" //Set stack of IRQ mode l to stk->irq
"msr cpsr_c, %3\n\t"
"add r14, %0, %4\n\t"
"mov sp, r14\n\t" //Set the stack of ABT model to stk->abt
"msr cpsr_c, %5\n\t"
"add r14, %0, %6\n\t"
"mov sp, r14\n\t"
"msr cpsr_c, %7\n\t" //Set the stack of und mode to stk->und
"add r14, %0, %8\n\t"
"mov sp, r14\n\t"
"msr cpsr_c, %9" //Set stack of FIQ model to stk->fiq
:
: "r" (stk),
PLC (PSR_F_BIT | PSR_I_BIT | IRQ_MODE),
"I" (offsetof(struct stack, irq[0])),
PLC (PSR_F_BIT | PSR_I_BIT | ABT_MODE),
"I" (offsetof(struct stack, abt[0])),
PLC (PSR_F_BIT | PSR_I_BIT | UND_MODE),
"I" (offsetof(struct stack, und[0])),
PLC (PSR_F_BIT | PSR_I_BIT | FIQ_MODE),
"I" (offsetof(struct stack, fiq[0])),
PLC (PSR_F_BIT | PSR_I_BIT | SVC_MODE)
: "r14");
#endif
}
_For SMP, bootstrap CPU executes the cpu_init function at the time of system initialization to set the kernel stack of irq, abt, und and fiq modes of this CPU. The specific calling sequence is: start_kernel->setup_arch->setup_processor->cpu_init.
_For other CPUs in the system, the bootstrap CPU initializes each online CPU at the end of the system initialization. The specific calling sequence is:
start_kernel--->rest_init--->kernel_init--->kernel_init_freeable--->kernel_init_freeable --->smp_init--->cpu_up--->_cpu_up--->__cpu_up.
The_u cpu_up function is related to the CPU architecture. For ARM, the call sequence is
__cpu_up--->boot_secondary--->smp_ops.smp_boot_secondary(SOC Related Codes)--->secondary_startup--->__secondary_switched--->secondary_start_kernel--->cpu_init.
_In addition to initialization, system power management also requires irq, abt, and und stack settings. If the power management state we set goes into sleep, the CPU will lose the values of irq, abt, and und stack point registers, then during CPU resume, we will call cpu_init to reset these values.
stack preparation for SVC mode
_We often say that the user space and kernel space of a process can run in user space or enter kernel space through system calls for an application. In user space, the user stack is used, that is, when our software engineers write user space programs, the stack of local variables is saved. Once trapped in the kernel, of course, the user cannot be used.Stack, you need to use the kernel stack at this point. The so-called kernel stack is actually the stack you use when you are in the SVC mode l. At the beginning of linux startup, the system only has one process (more precisely, the kernel thread), which is the process with PID equal to 0, called the swapper process (or idle process). The kernel stack of the process is statically defined as follows:
Source code: init/init_task.c
/*
* Set up the first task table, touch at your own risk!. Base=0,
* limit=0x1fffff (=2MB)
*/
struct task_struct init_task
#ifdef CONFIG_ARCH_TASK_STRUCT_ON_STACK
__init_task_data
#endif
= {
#ifdef CONFIG_THREAD_INFO_IN_TASK
.thread_info = INIT_THREAD_INFO(init_task),
.stack_refcount = REFCOUNT_INIT(1),
#endif
.state = 0,
.stack = init_stack,
.usage = REFCOUNT_INIT(2),
.flags = PF_KTHREAD,
.prio = MAX_PRIO - 20,
.static_prio = MAX_PRIO - 20,
.normal_prio = MAX_PRIO - 20,
.policy = SCHED_NORMAL,
.cpus_ptr = &init_task.cpus_mask,
.cpus_mask = CPU_MASK_ALL,
.nr_cpus_allowed= NR_CPUS,
.mm = NULL,
.active_mm = &init_mm,
.restart_block = {
.fn = do_no_restart_syscall,
},
.se = {
.group_node = LIST_HEAD_INIT(init_task.se.group_node),
},
.rt = {
.run_list = LIST_HEAD_INIT(init_task.rt.run_list),
.time_slice = RR_TIMESLICE,
},
.tasks = LIST_HEAD_INIT(init_task.tasks),
#ifdef CONFIG_SMP
.pushable_tasks = PLIST_NODE_INIT(init_task.pushable_tasks, MAX_PRIO),
#endif
#ifdef CONFIG_CGROUP_SCHED
.sched_task_group = &root_task_group,
#endif
.ptraced = LIST_HEAD_INIT(init_task.ptraced),
.ptrace_entry = LIST_HEAD_INIT(init_task.ptrace_entry),
.real_parent = &init_task,
.parent = &init_task,
.children = LIST_HEAD_INIT(init_task.children),
.sibling = LIST_HEAD_INIT(init_task.sibling),
.group_leader = &init_task,
RCU_POINTER_INITIALIZER(real_cred, &init_cred),
RCU_POINTER_INITIALIZER(cred, &init_cred),
.comm = INIT_TASK_COMM,
.thread = INIT_THREAD,
.fs = &init_fs,
.files = &init_files,
.signal = &init_signals,
.sighand = &init_sighand,
.nsproxy = &init_nsproxy,
.pending = {
.list = LIST_HEAD_INIT(init_task.pending.list),
.signal = {{0}}
},
.blocked = {{0}},
.alloc_lock = __SPIN_LOCK_UNLOCKED(init_task.alloc_lock),
.journal_info = NULL,
INIT_CPU_TIMERS(init_task)
.pi_lock = __RAW_SPIN_LOCK_UNLOCKED(init_task.pi_lock),
.timer_slack_ns = 50000, /* 50 usec default slack */
.thread_pid = &init_struct_pid,
.thread_group = LIST_HEAD_INIT(init_task.thread_group),
.thread_node = LIST_HEAD_INIT(init_signals.thread_head),
#ifdef CONFIG_AUDIT
.loginuid = INVALID_UID,
.sessionid = AUDIT_SID_UNSET,
#endif
#ifdef CONFIG_PERF_EVENTS
.perf_event_mutex = __MUTEX_INITIALIZER(init_task.perf_event_mutex),
.perf_event_list = LIST_HEAD_INIT(init_task.perf_event_list),
#endif
#ifdef CONFIG_PREEMPT_RCU
.rcu_read_lock_nesting = 0,
.rcu_read_unlock_special.s = 0,
.rcu_node_entry = LIST_HEAD_INIT(init_task.rcu_node_entry),
.rcu_blocked_node = NULL,
#endif
#ifdef CONFIG_TASKS_RCU
.rcu_tasks_holdout = false,
.rcu_tasks_holdout_list = LIST_HEAD_INIT(init_task.rcu_tasks_holdout_list),
.rcu_tasks_idle_cpu = -1,
#endif
#ifdef CONFIG_CPUSETS
.mems_allowed_seq = SEQCNT_ZERO(init_task.mems_allowed_seq),
#endif
#ifdef CONFIG_RT_MUTEXES
.pi_waiters = RB_ROOT_CACHED,
.pi_top_task = NULL,
#endif
INIT_PREV_CPUTIME(init_task)
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
.vtime.seqcount = SEQCNT_ZERO(init_task.vtime_seqcount),
.vtime.starttime = 0,
.vtime.state = VTIME_SYS,
#endif
#ifdef CONFIG_NUMA_BALANCING
.numa_preferred_nid = NUMA_NO_NODE,
.numa_group = NULL,
.numa_faults = NULL,
#endif
#ifdef CONFIG_KASAN
.kasan_depth = 1,
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
.softirqs_enabled = 1,
#endif
#ifdef CONFIG_LOCKDEP
.lockdep_depth = 0, /* no locks held yet */
.curr_chain_key = INITIAL_CHAIN_KEY,
.lockdep_recursion = 0,
#endif
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
.ret_stack = NULL,
#endif
#if defined(CONFIG_TRACING) && defined(CONFIG_PREEMPTION)
.trace_recursion = 0,
#endif
#ifdef CONFIG_LIVEPATCH
.patch_state = KLP_UNDEFINED,
#endif
#ifdef CONFIG_SECURITY
.security = NULL,
#endif
};
EXPORT_SYMBOL(init_task);
#define THREAD_SIZE_ORDER 1 #define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER) #define THREAD_START_SP (THREAD_SIZE - 8) extern unsigned long init_stack[THREAD_SIZE / sizeof(unsigned long)];
_For ARM platforms, THREAD_SIZE is 8192 byte s, thus occupying two page frames. As initialization progresses, Linux kernels create several kernel threads, while processes in user space also create processes or threads when they enter user space. Linux kernels assign a process when they create processes, including user processes and kernel threads.(or two, configuration-related) page frames, coded as follows:
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
struct task_struct *tsk;
unsigned long *stack;
struct vm_struct *stack_vm_area __maybe_unused;
int err;
if (node == NUMA_NO_NODE)
node = tsk_fork_get_node(orig);
tsk = alloc_task_struct_node(node);
if (!tsk)
return NULL;
stack = alloc_thread_stack_node(tsk, node);
if (!stack)
goto free_tsk;
if (memcg_charge_kernel_stack(tsk))
goto free_stack;
stack_vm_area = task_stack_vm_area(tsk);
err = arch_dup_task_struct(tsk, orig);
/*
* arch_dup_task_struct() clobbers the stack-related fields. Make
* sure they're properly initialized before using any stack-related
* functions again.
*/
tsk->stack = stack;
#ifdef CONFIG_VMAP_STACK
tsk->stack_vm_area = stack_vm_area;
#endif
#ifdef CONFIG_THREAD_INFO_IN_TASK
refcount_set(&tsk->stack_refcount, 1);
#endif
if (err)
goto free_stack;
#ifdef CONFIG_SECCOMP
/*
* We must handle setting up seccomp filters once we're under
* the sighand lock in case orig has changed between now and
* then. Until then, filter must be NULL to avoid messing up
* the usage counts on the error path calling free_task.
*/
tsk->seccomp.filter = NULL;
#endif
setup_thread_stack(tsk, orig);
clear_user_return_notifier(tsk);
clear_tsk_need_resched(tsk);
set_task_stack_end_magic(tsk);
#ifdef CONFIG_STACKPROTECTOR
tsk->stack_canary = get_random_canary();
#endif
if (orig->cpus_ptr == &orig->cpus_mask)
tsk->cpus_ptr = &tsk->cpus_mask;
/*
* One for the user space visible state that goes away when reaped.
* One for the scheduler.
*/
refcount_set(&tsk->rcu_users, 2);
/* One for the rcu users */
refcount_set(&tsk->usage, 1);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
tsk->task_frag.page = NULL;
tsk->wake_q.next = NULL;
account_kernel_stack(tsk, 1);
kcov_task_init(tsk);
#ifdef CONFIG_FAULT_INJECTION
tsk->fail_nth = 0;
#endif
#ifdef CONFIG_BLK_CGROUP
tsk->throttle_queue = NULL;
tsk->use_memdelay = 0;
#endif
#ifdef CONFIG_MEMCG
tsk->active_memcg = NULL;
#endif
return tsk;
free_stack:
free_thread_stack(tsk);
free_tsk:
free_task_struct(tsk);
return NULL;
}
At the bottom is the struct thread_info data structure, and at the top (the high address) is the kernel stack of the process. When the process switches, the entire hardware and software contexts are switched, where the value of the sp register, including the SVC model, is switched to the kernel stack of the new process selected by the scheduling algorithm.
Preparation of anomaly vector table
_For ARM processors, when an exception occurs, the processor pauses the execution of the current instruction, saves the field, and then executes the instruction at the corresponding exception vector. When the exception is processed, the field is restored and the program continues at the original point. All the exception vectors (a total of 8) in the system form an exception vector table.The code for (vector table) is as follows:
//Source: arch/arm/kernel/entry-armv.S .section .vectors, "ax", %progbits .L__vectors_start: W(b) vector_rst W(b) vector_und W(ldr) pc, .L__vectors_start + 0x1000 W(b) vector_pabt W(b) vector_dabt W(b) vector_addrexcptn W(b) vector_irq W(b) vector_fiq
_For this article, we focus on the vector_irq exception vector. The exception vector table may be placed in two places:
(1) The address of the anomaly vector table at 0x0. This setting is called Normal vectors or Low vectors.
(2) The anomaly vector table is located at the address of 0xff0000. This setting is called high vectors. Specifically, whether low or high vectors is controlled by the 13th bit (vector bit) of an SCCLR register called ARM.
_For MMU-enabled ARM Linux, the system uses high vectors. Why not use low vector s?
_For linux, the space between 0 and 3G is user space. If low vector is used, then the anomaly vector table is at 0 address, then it is the location of user space, so Linux uses high vector. Of course, low vector is also possible, so the space where low vector is located belongs to kernel space(That is, the space between 3G and 4G plus the space occupied by Low vectors belongs to the kernel space), but be careful at this point, since all processes share the kernel space, and programs in user space often have null pointer access, memory protection mechanisms should be able to catch this error(Most MUUs do this, for example, by disabling userspace access to the address space of the kernel space and preventing vector tables from being accessed. For null pointer access in the kernel due to program errors, memory protection mechanisms also need to control that vector tables are modified, so the space where vector tables are located is set to read only.
_After using MMU, it is no longer important that the specific anomaly vector table be placed at that physical address. It is important to map it to the virtual address of 0xff0000, which is OK. The code is as follows:
//Source: arch/arm/mm/mmu.c
/*
* Set up the device mappings. Since we clear out the page tables for all
* mappings above VMALLOC_START, except early fixmap, we might remove debug
* device mappings. This means earlycon can be used to debug this function
* Any other function or debugging method which may touch any device _will_
* crash the kernel.
*/
static void __init devicemaps_init(const struct machine_desc *mdesc)
{
struct map_desc map;
unsigned long addr;
void *vectors;
/*
* Allocate the vector page early.
*/
vectors = early_alloc(PAGE_SIZE * 2);//Assign physical page frames to two pages
early_trap_init(vectors);//copy vector table and related help function s to this area
........
/*
* Create a mapping for the machine vectors at the high-vectors
* location (0xffff0000). If we aren't using high-vectors, also
* create a mapping at the low-vectors virtual address.
*/
map.pfn = __phys_to_pfn(virt_to_phys(vectors));
map.virtual = 0xffff0000;
map.length = PAGE_SIZE;
#ifdef CONFIG_KUSER_HELPERS
map.type = MT_HIGH_VECTORS;
#else
map.type = MT_LOW_VECTORS;
#endif
create_mapping(&map);//The page frame that maps 0xff0000
//If the value of SCTLR.V is set to low vectors, then also map memory starting with 0 address
if (!vectors_high()) {
map.virtual = 0;
map.length = PAGE_SIZE * 2;
map.type = MT_LOW_VECTORS;
create_mapping(&map);
}
/* Now create a kernel read-only mapping */
map.pfn += 1;
map.virtual = 0xffff0000 + PAGE_SIZE;
map.length = PAGE_SIZE;
map.type = MT_LOW_VECTORS;
create_mapping(&map); //Map the second page frame starting with high vecotr
/*
* Ask the machine support to map in the statically mapped devices.
*/
if (mdesc->map_io)
mdesc->map_io();
else
debug_ll_io_init();
fill_pmd_gaps();
/* Reserve fixed i/o space in VMALLOC region */
pci_reserve_io();
/*
* Finally flush the caches and tlb to ensure that we're in a
* consistent state wrt the writebuffer. This also ensures that
* any write-allocated cache lines in the vector page are written
* back. After this point, we can start to touch devices again.
*/
local_flush_tlb_all();
flush_cache_all();
/* Enable asynchronous aborts */
early_abt_enable();
}
_Why allocate two page frame s?
_Here the vectors table and kuser helper functions (functions provided by kernel space but used by user space) occupy a page frame, and the stub function for exception handling occupies another page frame. Why is there a stub function? I will talk about it later. In the early_trap_init function, the exception vector table is initialized, with the following code:
void __init early_trap_init(void *vectors_base)
{
#ifndef CONFIG_CPU_V7M
unsigned long vectors = (unsigned long)vectors_base;
extern char __stubs_start[], __stubs_end[];
extern char __vectors_start[], __vectors_end[];
unsigned i;
vectors_page = vectors_base;
/*
* Poison the vectors page with an undefined instruction. This
* instruction is chosen to be undefined for both ARM and Thumb
* ISAs. The Thumb version is an undefined instruction with a
* branch back to the undefined instruction.
*/
// Fill the page frame of the entire vector table with an undefined instruction.
// The initial vector table plus the kuser helper function does not fully fill the page, there are some gaps.
// If not, in extreme cases (program error or HW issue),
// The CPU may finger execution from these gaps, resulting in unknown consequences.
// If no instructions are defined for filling these gaps, the CPU can catch the exception.
for (i = 0; i < PAGE_SIZE / sizeof(u32); i++)
((u32 *)vectors_base)[i] = 0xe7fddef1;
/*
* Copy the vectors, stubs and kuser helpers (in entry-armv.S)
* into the vector page, mapped at 0xffff0000, and ensure these
* are visible to the instruction stream.
*/
// Copy vector table, copy stub function
memcpy((void *)vectors, __vectors_start, __vectors_end - __vectors_start);
memcpy((void *)vectors + 0x1000, __stubs_start, __stubs_end - __stubs_start);
kuser_init(vectors_base);
flush_icache_range(vectors, vectors + PAGE_SIZE * 2);
#else /* ifndef CONFIG_CPU_V7M */
/*
* on V7-M there is no need to copy the vector table to a dedicated
* memory area. The address is configurable and so a table in the kernel
* image can be used.
*/
#endif
}
_Once a copy of the code is involved, we need to care about its link-time address and run-time address when compiling the connection. After the kernel s complete the link, u vectors_start has its link-time address, and if link-time address and run-time address are identical, the code runs without stress.
_However, for vector table s, it is currently copied to another address (for High vector, this is 0xff00000), that is, link-time address and run-time address are different, and if you still want them to run correctly, you need them to be location-independent.
_For a vector table, it must be location-independent. The B branch instruction itself is location-independent and can jump to an offset at the current location. However, not all vectors use branch instruction. For soft interrupts, the directive on the vectors address is "W(ldr) pc, u vectors_start + 0x1000"This directive is compiled by the compiler into ldr pc, [pc, #4080]. In this case, the directive is also location independent, but there is a limitation that offsets must be in the range of 4K, which is why stub section s exist.
Interrupt processing execution
Definition of vectot_irq
//Source: arch/arm/kernel/entry-armv.S /* * Interrupt dispatcher */ vector_stub irq, IRQ_MODE, 4 @ Subtract 4 to ensure that you return the instruction after the interrupt .long __irq_usr @ 0 (USR_26 / USR_32) .long __irq_invalid @ 1 (FIQ_26 / FIQ_32) .long __irq_invalid @ 2 (IRQ_26 / IRQ_32) .long __irq_svc @ 3 (SVC_26 / SVC_32) .long __irq_invalid @ 4 .long __irq_invalid @ 5 .long __irq_invalid @ 6 .long __irq_invalid @ 7 .long __irq_invalid @ 8 .long __irq_invalid @ 9 .long __irq_invalid @ a .long __irq_invalid @ b .long __irq_invalid @ c .long __irq_invalid @ d .long __irq_invalid @ e .long __irq_invalid @ f
vector_stub macro definition
THUMB( .thumb )
/*
* Vector stubs.
*
* This code is copied to 0xffff1000 so we can use branches in the
* vectors, rather than ldr's. Note that this code must not exceed
* a page size.
*
* Common stub entry macro:
* Enter in IRQ mode, spsr = SVC/USR CPSR, lr = SVC/USR PC
*
* SP points to a minimal amount of processor-private memory, the address
* of which is copied into r0 for the mode specific abort handler.
*/
.macro vector_stub, name, mode, correction=0
.align 5
vector_\name:
@ When it's unusual, lr Where the interrupt occurred PC+4,
@ If you subtract 4, you get the break point PC value
.if \correction
sub lr, lr, #\correction
.endif
@
@ Save r0, lr_<exception> (parent PC) and spsr_<exception>
@ (parent CPSR)
@
@ Save in sequence lr,pc,spsr Value of(Hardware has been saved for us CPSR reach SPSR in)
stmia sp, {r0, lr} @ save r0, lr
mrs lr, spsr
@ Because subsequent code will use r0 Registers, so we're going to put r0 On the stack,
@ Only then can the hardware site be completely restored.
str lr, [sp, #8] @ save spsr
@
@ Prepare for SVC32 mode. IRQs remain disabled.
@
@ Prepare to ARM Push to SVC mode
@ It's actually a modification SPSR Value of, SPSR No CPSR,
@ Will not cause processor mode Switch of
mrs r0, cpsr
eor r0, r0, #(\mode ^ SVC_MODE | PSR_ISETSTATE)
msr spsr_cxsf, r0
@
@ the branch table must immediately follow this code
@
and lr, lr, #0x0f @ lr saves the CPSR in the event of an exception, and the value of CPSR.M[3:0] can be obtained by an and operation
THUMB( adr r0, 1f ) @ According to the current PC Value, get lable 1 Address
THUMB( ldr lr, [r0, lr, lsl #2]) @ lr is either the address of u irq_usr or u irq_svc according to the current mode
mov r0, sp @take irq mode Of stack point adopt r0 Function passed to jump
ARM( ldr lr, [pc, lr, lsl #2] )
movs pc, lr @ branch to handler in SVC mode
ENDPROC(vector_\name)
.align 2
@ handler addresses follow this label
1:
.endm
When a break occurs, the code runs in user space
The code for the Interrupt dispatcher is as follows:
Source code: arch/arm/kernel/entry-armv.S /* * Interrupt dispatcher */ vector_stub irq, IRQ_MODE, 4 .long __irq_usr @ 0 (USR_26 / USR_32) .long __irq_invalid @ 1 (FIQ_26 / FIQ_32) .long __irq_invalid @ 2 (IRQ_26 / IRQ_32) .long __irq_svc @ 3 (SVC_26 / SVC_32) .long __irq_invalid @ 4 .long __irq_invalid @ 5 .long __irq_invalid @ 6 .long __irq_invalid @ 7 .long __irq_invalid @ 8 .long __irq_invalid @ 9 .long __irq_invalid @ a .long __irq_invalid @ b .long __irq_invalid @ c .long __irq_invalid @ d .long __irq_invalid @ e .long __irq_invalid @ f
_This is actually a lookup table, according to CPSR.M[3:0]The lookup table therefore has 16 entries, of course only two are valid, corresponding to the jump addresses of user mode l and SVC model. The u irq_invalid of the other entries is also critical, which ensures that interrupts occur in their mode, and the system can catch such errors, providing useful information for debug.
_u irq_usr function definition:
//Source: arch/arm/kernel/entry-armv.S .align 5 __irq_usr: usr_entry @ Save User Site kuser_cmpxchg_check irq_handler @ Interrupt Handling Function get_thread_info tsk @ tsk yes r9,Point to Current thread info data structure mov why, #0 @ why is r8 b ret_to_user_from_irq @ Interrupt Return UNWIND(.fnend ) ENDPROC(__irq_usr)
(1) Save the site when the interrupt occurs. The so-called save site actually saves the hardware context (registers) at the moment the interrupt occurs on the stack of the SVC mode l.
The usr_entry function definition:
//Source: arch/arm/kernel/entry-armv.S
.macro usr_entry, trace=1, uaccess=1
UNWIND(.fnstart )
UNWIND(.cantunwind ) @ don't unwind the user space
sub sp, sp, #PT_REGS_SIZE --------------A
ARM( stmib sp, {r1 - r12} ) --------------B
THUMB( stmia sp, {r0 - r12} )
ATRAP( mrc p15, 0, r7, c1, c0, 0)
ATRAP( ldr r8, .LCcralign)
ldmia r0, {r3 - r5} --------------C
add r0, sp, #S_PC @ here for interlock avoidance --D
mov r6, #-1 @ "" "" "" ""
str r3, [sp] @ save the "real" r0 copied
@ from the exception stack
ATRAP( ldr r8, [r8, #0])
@
@ We are now ready to fill in the remaining blanks on the stack:
@
@ r4 - lr_<exception>, already fixed up for correct return/restart
@ r5 - spsr_<exception>
@ r6 - orig_r0 (see pt_regs definition in ptrace.h)
@
@ Also, separately save sp_usr and lr_usr
@
stmia r0, {r4 - r6} --------------E
ARM( stmdb r0, {sp, lr}^ ) -------F
THUMB( store_user_sp_lr r0, r1, S_SP - S_PC )
.if \uaccess
uaccess_disable ip
.endif
@ Enable the alignment trap while in kernel mode
ATRAP( teq r8, r7)
ATRAP( mcrne p15, 0, r8, c1, c0, 0)
@
@ Clear FP to mark the first stack frame
@
zero_fp
.if \trace
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
ct_user_exit save = 0
.endif
.endm
_A: By the time the code is executed here, ARM processing has switched to SVC mode. Once it enters SVC mode, the registers seen by the ARM processor have changed, where SP has become sp_svc. Therefore, subsequent stack operations are pushed into the kernel stack (or SVC stack) of the process at the moment the interrupt occurs.How many register values are saved? The answer is given by S_FRAME_SIZE, which is 18 registers. r0-r15 plus CPSR only have 17. Keep this question first, and we'll answer it later.
_B: The stack first pushed r1-r12, so why not process r0 here? Because r0 was polluted when IRQ model cut to SVC model, however, the original r0 was on the stack of the saved IRQ model. Do r13 (sp) and r14 (lr) need to be saved, of course, and saved later. To execute here, the layout of the kernel stack is as follows:
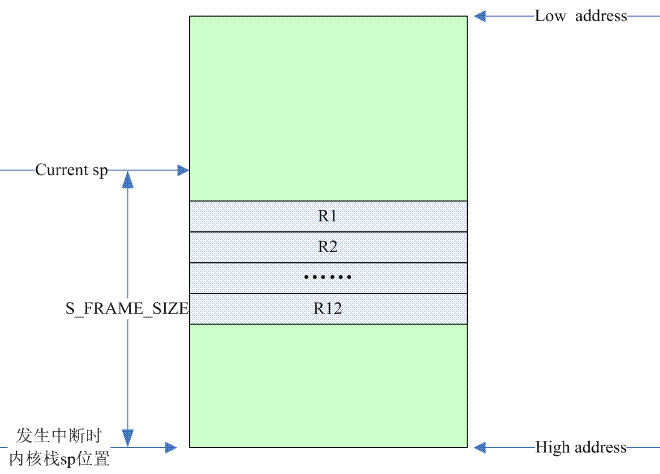
_stmib has ib for increment before, so when you press R1, the stack pointer will increase by 4, most importantly to reserve the position of r0. The SP in stmib sp, {r1 - r12} directive has no modifier for'!', indicating that the stack pointer will not really be updated after the stack is complete, so SP keeps its original value.
_C: Note that here r0 points to the irq stack, so r3 is the r0 value at the time of interruption, r4 is the PC value at the site of interruption, and r5 is the C PSR value at the site of interruption.
_D: Assign r0 to the value of S_PC. According to the definition of struct pt_regs, which reflects the arrangement of registers stored on the kernel stack, the order from low address to high address is:
ARM_r0 ARM_r1 ARM_r2 ARM_r3 ARM_r4 ARM_r5 ARM_r6 ARM_r7 ARM_r8 ARM_r9 ARM_r10 ARM_fp ARM_ip ARM_sp ARM_lr ARM_pc<---------add r0, sp, #The S_PC directive makes r0 point to this location ARM_cpsr ARM_ORIG_r0
Why assign r0? kernel therefore does not want to modify the value of sp and keeps sp pointing to the top of the stack.
_E: Save the values of the remaining registers on the kernel stack, which are r0, PC, CPSR, and orig r0, according to the code. Executing here, the layout of the kernel stack is shown in the following figure
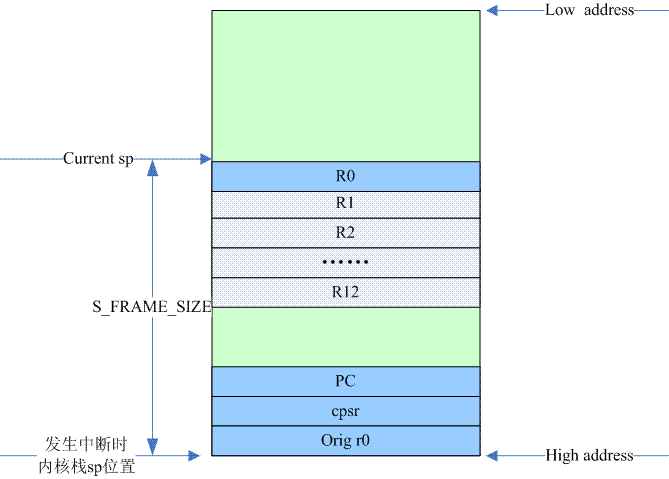
R0, PC, and CPSR come from the stack of the IRQ mode l. In fact, this operation is to move from the irq stack to the kernel stack on the interrupt site.
_F: There are two registers left on the kernel stack that are SP and LR at the time of interrupt. At this time, R0 points to the address where the PC register is saved (add r0, sp, #S_PC), stmdb r0, {sp, lr}^ "db"Is decrement before, so press SP and LR into the remaining two locations in the stack. Note that we save the moment the interrupt occurs (for this section, this is the SP and LR of the user model at that time), and the'^'symbol in the instruction indicates the register accessing the user model.
(2) Core processing irq_handler
There are two configurations for handling_irq_handler. One is configuring CONFIG_MULTI_IRQ_HANDLER. In this case, linux kernels allow run time to set irq handler. If we need a linux kernelImage supports multiple platforms, which requires configuring this option. Another is the traditional linux approach where irq_handler is actually arch_irq_handler_default, with the following code:
//Source: arch/arm/kernel/entry-armv.S .macro irq_handler #ifdef CONFIG_GENERIC_IRQ_MULTI_HANDLER ldr r1, =handle_arch_irq mov r0, sp @Settings passed to machine Defined handle_arch_irq Parameters badr lr, 9997f @Set Return Address ldr pc, [r1] #else arch_irq_handler_default #endif 9997: .endm
_For case one, the machine-related code needs to set the handle_arch_irq function pointer, where the assembly instruction only needs to call the irq handler provided by the machine code (of course, be prepared for parameter passing and return address setting).
Case two is slightly more complex (and it seems that kernel s are using fewer and fewer of them), and the code is as follows:
//Source: arch/arm/include/asm/entry-macro-multi.S
.macro arch_irq_handler_default
get_irqnr_preamble r6, lr
1: get_irqnr_and_base r0, r2, r6, lr
movne r1, sp
@
@ routine called with r0 = irq number, r1 = struct pt_regs *
@ Two parameters are required, one is irq number(Save in r0)
@ The other is struct pt_regs *(Save in r1 Medium)
@ Return Address is set to Symbol 1, that is, it needs to be constantly parsed irq Status Register
@Content, get IRQ number,Until all irq number Finished processing
badrne lr, 1b
bne asm_do_IRQ
#ifdef CONFIG_SMP
/*
* XXX
*
* this macro assumes that irqstat (r2) and base (r6) are
* preserved from get_irqnr_and_base above
*/
ALT_SMP(test_for_ipi r0, r2, r6, lr)
ALT_UP_B(9997f)
movne r1, sp
badrne lr, 1b
bne do_IPI
#endif
9997:
.endm
_The code here is already machine-related, so let's just briefly describe it. Machine-related means that it is related to the interrupt controller in the system. get_irqnr_preamble is to prepare for interrupt handling. Some platforms do not need this step at all and are simply defined as empty.There are four parameters: r0 holds the parsed irq number, r2 is the value of the irq status register, r6 is the base address of the irq controller, and lr is the scratch register.
_For the ARM platform, we recommend the first method, because logically, interrupt processing is to convert to an IRQ number based on the current state of the hardware interrupt system, then call the IRQ number's handler. Obtain IRQ as an old ARM by macro definitions such as get_irqnr_and_base The method used by the SOC system is to assume that there is an interrupt controller on the SOC, and the relationship between hardware state and IRQ number is very simple. However, in fact, the hardware interrupt system on the ARM platform has become more and more complex, requiring the introduction of interrupt controller cascade, IRQConcepts such as domain, therefore, have more advantages with the first method, as detailed below: handle_arch_irq execution process.
When an interrupt occurs, the code runs in kernel space
If the interrupt occurs in kernel space, the code jumps to u irq_svc to execute:
.align 5 __irq_svc: svc_entry @ Save the scene at the moment the interrupt occurs on the kernel stack irq_handler @ Specific interrupt handling, same as user mode Processing #ifdef CONFIG_PREEMPT @ and preempt-related processing ldr r8, [tsk, #TI_PREEMPT] @ get preempt count ldr r0, [tsk, #TI_FLAGS] @ get flags teq r8, #0 @ if preempt count != 0 movne r0, #0 @ force flags to 0 tst r0, #_TIF_NEED_RESCHED blne svc_preempt #endif svc_exit r5, irq = 1 @ return from exception UNWIND(.fnend ) ENDPROC(__irq_svc)
_The code to save the scene is similar to the code to save it in user mode, so it's not described in detail here, just some comments are embedded in the code below.
//Source: arch/arm/kernel/entry-armv.S
.macro svc_entry, stack_hole=0, trace=1, uaccess=1
UNWIND(.fnstart )
UNWIND(.save {r0 - pc} )
sub sp, sp, #(SVC_REGS_SIZE + \stack_hole - 4) @ sp points to the location of r1 in struct pt_regs
#ifdef CONFIG_THUMB2_KERNEL
SPFIX( str r0, [sp] ) @ temporarily saved
SPFIX( mov r0, sp )
SPFIX( tst r0, #4 ) @ test original stack alignment
SPFIX( ldr r0, [sp] ) @ restored
#else
SPFIX( tst sp, #4 )
#endif
SPFIX( subeq sp, sp, #4 )
stmia sp, {r1 - r12} @ Register stacking
ldmia r0, {r3 - r5}
add r7, sp, #S_SP - 4 @ here for interlock avoidance @ r7 points to the location of r12 in struct pt_regs
mov r6, #-1 @ "" "" """@ orig r0 set to-1
add r2, sp, #(SVC_REGS_SIZE + \stack_hole - 4) @ r2 is where stacks are found at the moment they interrupt
SPFIX( addeq r2, r2, #4 )
str r3, [sp, #-4]!save the "real" r0 copied @Save r0, notice one!, sp will add 4, then sp will point to the R0 position at the top of the stack
@ from the exception stack
mov r3, lr @ Preservation svc mode Of lr reach r3
@
@ We are now ready to fill in the remaining blanks on the stack:
@
@ r2 - sp_svc
@ r3 - lr_svc
@ r4 - lr_<exception>, already fixed up for correct return/restart
@ r5 - spsr_<exception>
@ r6 - orig_r0 (see pt_regs definition in ptrace.h)
@
stmia r7, {r2 - r6}
get_thread_info tsk
uaccess_entry tsk, r0, r1, r2, \uaccess
.if \trace
#ifdef CONFIG_TRACE_IRQFLAGS
bl trace_hardirqs_off
#endif
.endif
.endm
_So far, the complete hardware context has been saved on the kernel stack. In fact, it is not only complete, but also redundant because there is a member of orig_r0. The so-called original r0 is the R0 value at the moment of interrupt. By theory, both ARM_r0 and ARM_ORIG_r0 should be the R0 of user space.
_Why should two R0 values be saved? Why does interrupt save -1 to the position of ARM_ORIG_r0? Understanding this problem requires skipping the topic of interrupt handling. Let's look at ARM's system calls. For system calls, it and interrupt handling are both cpu exception handling categories, but one obvious difference is that system calls need to pass parameters and return results.
_What if such parameter passes? For ARM, of course, registers, especially returns results, are stored in r0. For ARM, r0-r7 is a variety of CPUModes are the same, so it's convenient to pass parameters. Therefore, when you enter a system call, you save all the registers on the kernel stack where the system call occurred. On the one hand, you save the hardware context; on the other hand, you get the parameters of the system call. When you return, you put the return value in R0 to OK.
_As described above, R0 serves two purposes, passing parameters and returning results. When the result of a system call is placed at r0, the parameter values passed through R0 are overwritten. Originally, this is nothing, but there are occasions where these two values are required:
_1, ptrace (related to debugger, not described in detail here)
_2, system call restart (related to signal, not described in detail here)
Because of this, there are two copies of R0 in the hardware context register, ARM_r0 is the passed parameter, and a copy is made to ARM_ORIG_r0. When the system call returns, ARM_r0 is the return value of the system call.
_OK, let's go back to the topic of interrupts. In fact, ARM_ORIG_r0 is not used in interrupt processing, but to prevent system call restart, you can assign values to non-system call numbers.
handle_arch_irq execution process
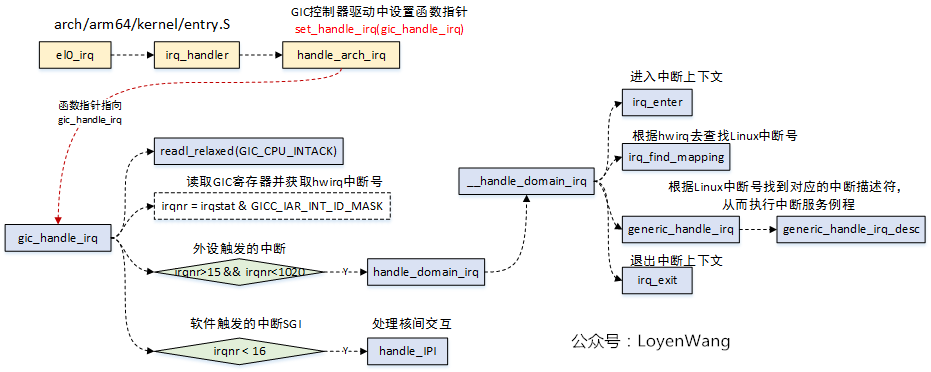
Note: Use A53's practice here for reference.
Registration of handle_arch_irq:
//Source: drivers/irqchip/irq-gic.c
static int __init __gic_init_bases(struct gic_chip_data *gic,
struct fwnode_handle *handle)
{
char *name;
int i, ret;
......
if (gic == &gic_data[0]) {
/*
* Initialize the CPU interface map to all CPUs.
* It will be refined as each CPU probes its ID.
* This is only necessary for the primary GIC.
*/
for (i = 0; i < NR_GIC_CPU_IF; i++)
gic_cpu_map[i] = 0xff;
#ifdef CONFIG_SMP
set_smp_cross_call(gic_raise_softirq);//Sets the callback function for the SMP kernel subtraction interaction for IPI
#endif
cpuhp_setup_state_nocalls(CPUHP_AP_IRQ_GIC_STARTING,
"irqchip/arm/gic:starting",
gic_starting_cpu, NULL);
set_handle_irq(gic_handle_irq);//Set related irq handler, entry for exception handling
if (static_branch_likely(&supports_deactivate_key))
pr_info("GIC: Using split EOI/Deactivate mode\n");
}
......
return ret;
}
Implementation of gic_handle_irq:
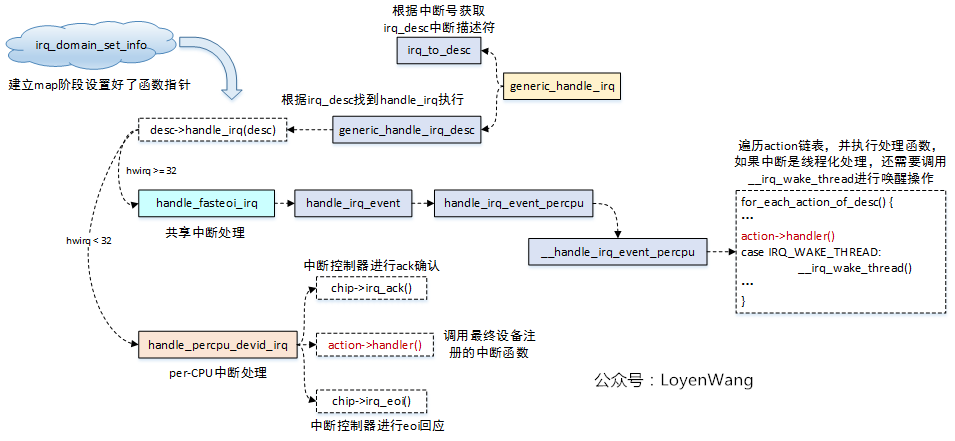
- The generic_handle_irq function eventually calls desc->handle_irq(), which corresponds to the irq_domain_set_info function called above to set the function pointer, handle_fasteoi_irq and handle_percpu_devid_irq, during the mapping process.
- handle_fasteoi_irq: Handles shared interrupts and traverses the IRQ action list, calling the action->handler() function one by one, which is the interrupt handler registered by the device driver to call the request_irq/request_threaded_irq interface, and u irq_wake_thread() to wake up the kernel thread if threading is interrupted;
- handle_percpu_devid_irq: Handles per-CPU interrupt handling, in which the interrupt controller's processing functions are called for hardware operations, which call action->handler() to handle interrupts;
static void __exception_irq_entry gic_handle_irq(struct pt_regs *regs)
{
u32 irqstat, irqnr;
struct gic_chip_data *gic = &gic_data[0];
void __iomem *cpu_base = gic_data_cpu_base(gic);
do {
// Get interrupt number
irqstat = readl_relaxed(cpu_base + GIC_CPU_INTACK);
irqnr = irqstat & GICC_IAR_INT_ID_MASK;
if (likely(irqnr > 15 && irqnr < 1020)) {
if (static_branch_likely(&supports_deactivate_key))
writel_relaxed(irqstat, cpu_base + GIC_CPU_EOI);
isb();
handle_domain_irq(gic->domain, irqnr, regs);
continue;
}
//SGI interrupt: 0~15
if (irqnr < 16) {
writel_relaxed(irqstat, cpu_base + GIC_CPU_EOI);
if (static_branch_likely(&supports_deactivate_key))
writel_relaxed(irqstat, cpu_base + GIC_CPU_DEACTIVATE);
#ifdef CONFIG_SMP
/*
* Ensure any shared data written by the CPU sending
* the IPI is read after we've read the ACK register
* on the GIC.
*
* Pairs with the write barrier in gic_raise_softirq
*/
smp_rmb();
handle_IPI(irqnr, regs);
#endif
continue;
}
break;
} while (1);
}
Implementation of handle_domain_irq:
//Source: include/linux/irqdesc.h
//Parameter meaning:
//domain: gic_irq_domain_hierarchy_ops
//hwirq: hardware interrupt number
//regs: field register
static inline int handle_domain_irq(struct irq_domain *domain,
unsigned int hwirq, struct pt_regs *regs)
{
return __handle_domain_irq(domain, hwirq, true, regs);
}
/**
* __handle_domain_irq - Invoke the handler for a HW irq belonging to a domain
* @domain: The domain where to perform the lookup
* @hwirq: The HW irq number to convert to a logical one
* @lookup: Whether to perform the domain lookup or not
* @regs: Register file coming from the low-level handling code
*
* Returns: 0 on success, or -EINVAL if conversion has failed
*/
int __handle_domain_irq(struct irq_domain *domain, unsigned int hwirq,
bool lookup, struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
unsigned int irq = hwirq;
int ret = 0;
irq_enter();
#ifdef CONFIG_IRQ_DOMAIN
if (lookup)
irq = irq_find_mapping(domain, hwirq);
#endif
/*
* Some hardware gives randomly wrong interrupts. Rather
* than crashing, do something sensible.
*/
if (unlikely(!irq || irq >= nr_irqs)) {
ack_bad_irq(irq);
ret = -EINVAL;
} else {
generic_handle_irq(irq);
}
irq_exit();
set_irq_regs(old_regs);
return ret;
}
int generic_handle_irq(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
generic_handle_irq_desc(desc);
return 0;
}
EXPORT_SYMBOL_GPL(generic_handle_irq);
/*
* Architectures call this to let the generic IRQ layer
* handle an interrupt.
*/
static inline void generic_handle_irq_desc(struct irq_desc *desc)
{
desc->handle_irq(desc);
}
Interrupt exit process
_Whether in the kernel state (including system calls and interrupt context) or in the user state, irq_handler is called to handle interrupts, where the handler of the corresponding irq number is called to handle softirq, tasklet, workqueue, and so on (which is described in a separate document), but in any case, the final step is to return to the site where the interrupts occurred.
_1. The interruption occurs in the exit process under user mode, with the following code:
//Source: arch/arm/kernel/entry-commin.S ENTRY(ret_to_user_from_irq) ldr r2, [tsk, #TI_ADDR_LIMIT] cmp r2, #TASK_SIZE blne addr_limit_check_failed ldr r1, [tsk, #TI_FLAGS] tst r1, #_TIF_WORK_MASK ---------------A bne slow_work_pending no_work_pending: asm_trace_hardirqs_on save = 0 @ and irq flag trace Relevant /* perform architecture specific actions before user return */ arch_ret_to_user r1, lr @ Some hardware platforms require some special handling of interrupt return to user space ct_user_enter save = 0 @ and trace context Relevant restore_user_regs fast = 0, offset = 0 ------------B ENDPROC(ret_to_user_from_irq)
flags members in_A:thread_info have some low level identities that require special handling if they are set. The flag s detected here include:
#define _TIF_WORK_MASK (_TIF_NEED_RESCHED | _TIF_SIGPENDING | _TIF_NOTIFY_RESUME)
_These three flags indicate whether scheduling is required, whether signal processing is required, and whether callback functions need to be called before returning to user space. As long as one flag is set, the program enters the branch of work_pending (the work_pending function passes three parameters, and the third parameter, why, identifies which system call, of course, we pass 0 here).
_B: Literally, this part of the code restores the field (register value) saved when entering the interrupt to the registers of the actual ARM, thus returning completely to the point where the interrupt occurred. The specific code is as follows:
//Source: arch/arm/kernel/entry-header.S
.macro restore_user_regs, fast = 0, offset = 0
uaccess_enable r1, isb=0
#ifndef CONFIG_THUMB2_KERNEL
@ ARM mode restore
mov r2, sp
ldr r1, [r2, #\offset+S_PSR] @ get call CPSR @ R1 saves the spsr in pt_regs, which is the CPSR at the time of interrupt
ldr lr, [r2, #\offset + S_PC]!@ get PC @ LR saves the PC value and sp moves to the location of the PC in pt_regs
tst r1, #PSR_I_BIT | 0x0f
bne 1f
msr spsr_cxsf, r1 @ save in spsr_svc @ Assign to spsr,Prepare to return to user space
#if defined(CONFIG_CPU_V6) || defined(CONFIG_CPU_32v6K)
@ We must avoid clrex due to Cortex-A15 erratum #830321
strex r1, r2, [r2] @ clear the exclusive monitor
#endif
.if \fast
ldmdb r2, {r1 - lr}^ @ get calling r1 - lr
.else
ldmdb r2, {r0 - lr}^ @ get calling r0 - lr @ Save data saved on the kernel stack to user state r0~r14 register
.endif
mov r0, r0 @ ARMv5T and earlier require a nop @ NOP Operations, ARMv5T This operation was previously required
@ after ldm {}^
add sp, sp, #\offset+PT_REGS_SIZE @ The site has been restored, move the sp of SVC model to its original location
movs pc, lr @ return & move spsr_svc into cpsr @ Return to user space
1: bug "Returning to usermode but unexpected PSR bits set?", \@
#elif defined(CONFIG_CPU_V7M)
@ V7M restore.
@ Note that we don't need to do clrex here as clearing the local
@ monitor is part of the exception entry and exit sequence.
.if \offset
add sp, #\offset
.endif
v7m_exception_slow_exit ret_r0 = \fast
#else
@ Thumb mode restore
mov r2, sp
load_user_sp_lr r2, r3, \offset + S_SP @ calling sp, lr
ldr r1, [sp, #\offset + S_PSR] @ get calling cpsr
ldr lr, [sp, #\offset + S_PC] @ get pc
add sp, sp, #\offset + S_SP
tst r1, #PSR_I_BIT | 0x0f
bne 1f
msr spsr_cxsf, r1 @ save in spsr_svc
@ We must avoid clrex due to Cortex-A15 erratum #830321
strex r1, r2, [sp] @ clear the exclusive monitor
.if \fast
ldmdb sp, {r1 - r12} @ get calling r1 - r12
.else
ldmdb sp, {r0 - r12} @ get calling r0 - r12
.endif
add sp, sp, #PT_REGS_SIZE - S_SP
movs pc, lr @ return & move spsr_svc into cpsr
1: bug "Returning to usermode but unexpected PSR bits set?", \@
#endif /* !CONFIG_THUMB2_KERNEL */
.endm
_2, the interruption occurred in the exit process under svc mode. The specific code is as follows:
//Source: arch/arm/kernel/entry-header.S
.macro svc_exit, rpsr, irq = 0
.if \irq != 0
@ IRQs already off
#ifdef CONFIG_TRACE_IRQFLAGS
@ The parent context IRQs must have been enabled to get here in
@ the first place, so there's no point checking the PSR I bit.
bl trace_hardirqs_on
#endif
.else
@ IRQs off again before pulling preserved data off the stack
disable_irq_notrace
#ifdef CONFIG_TRACE_IRQFLAGS
tst \rpsr, #PSR_I_BIT
bleq trace_hardirqs_on
tst \rpsr, #PSR_I_BIT
blne trace_hardirqs_off
#endif
.endif
uaccess_exit tsk, r0, r1
#ifndef CONFIG_THUMB2_KERNEL
@ ARM mode SVC restore
msr spsr_cxsf, \rpsr @ Will interrupt the site cpsr Save value to spsr Prepare to return to the scene where the interruption occurred
#if defined(CONFIG_CPU_V6) || defined(CONFIG_CPU_32v6K)
@ We must avoid clrex due to Cortex-A15 erratum #830321
sub r0, sp, #4 @ uninhabited address
strex r1, r2, [r0] @ clear the exclusive monitor
#endif
ldmia sp, {r0 - pc}^ @ load r0 - pc, cpsr @ This directive is ldm An exception return instruction that includes not only literal operations but also the following spsr copy reach cpsr Medium.
#else
@ Thumb mode SVC restore
ldr lr, [sp, #S_SP] @ top of the stack
ldrd r0, r1, [sp, #S_LR] @ calling lr and pc
@ We must avoid clrex due to Cortex-A15 erratum #830321
strex r2, r1, [sp, #S_LR] @ clear the exclusive monitor
stmdb lr!, {r0, r1, \rpsr} @ calling lr and rfe context
ldmia sp, {r0 - r12}
mov sp, lr
ldr lr, [sp], #4
rfeia sp!
#endif
.endm