gin framework routing theory
The gin framework uses a custom version httprouter , the principle of its routing is the tree structure using a large number of common prefixes, which is basically a compact Trie tree (or just Radix Tree ). Nodes with a common prefix also share a common parent node.
1, Radix Tree
The Radix Tree, also known as the Patricia Trie or crit bit tree, is a more space saving prefix tree. For each node of the cardinality tree, if the node is a unique subtree, it will be merged with the parent node. The following figure shows an example of a cardinality tree:
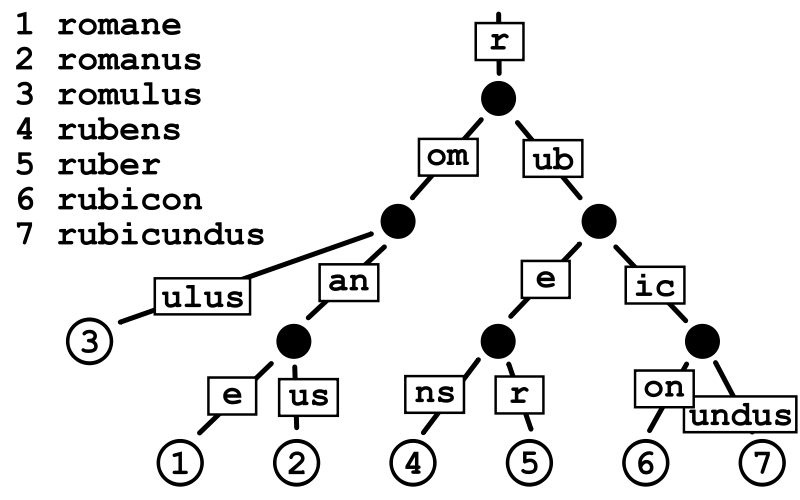
Radix Tree can be considered as a concise version of prefix tree. The process of registering a route is the process of constructing a prefix tree. Nodes with a common prefix also share a common parent node. Suppose we now have the following routing information registered:
r := gin.Default()
r.GET("/", func1)
r.GET("/search/", func2)
r.GET("/support/", func3)
r.GET("/blog/", func4)
r.GET("/blog/:post/", func5)
r.GET("/about-us/", func6)
r.GET("/about-us/team/", func7)
r.GET("/contact/", func8)
Then we will GET a routing tree corresponding to the GET method. The specific structure is as follows:
Priority Path Handle 9 \ *<1> 3 ├s nil 2 |├earch\ *<2> 1 |└upport\ *<3> 2 ├blog\ *<4> 1 | └:post nil 1 | └\ *<5> 2 ├about-us\ *<6> 1 | └team\ *<7> 1 └contact\ *<8>
Each * < number > in the rightmost column above represents the memory address (a pointer) of the Handle processing function. From the root node to the leaf node, we can get the complete routing table.
For example: blog/:post, where: post is just a placeholder (parameter) for the actual article name. Unlike hash maps, this tree structure also allows us to use dynamic parts such as the post parameter, because we actually match according to the routing pattern, not just comparing hash values.
Since the URL path has a hierarchy and uses only a limited set of characters (byte values), it is likely that there are many common prefixes. This allows us to easily simplify routing into smaller problems. In addition, the router manages a separate tree for each request method. On the one hand, it saves more space than saving a method - > handle map in each node. It also allows us to greatly reduce the routing problem even before we start looking in the prefix tree.
In order to achieve better scalability, the child nodes at each tree level are sorted by priority, and the priority (the leftmost column) is the number of handles registered in the child nodes (child nodes, child nodes, etc.). This has two benefits:
- First, the nodes included in most routing paths are matched first. This allows as many routes as possible to be located quickly.
- Similar to cost compensation. The longest path can be matched preferentially. The compensation is reflected in that the longest path takes longer to locate. If the node of the longest path can be matched preferentially (i.e. it hits the child node every time), the time spent in route matching is not necessarily longer than that of the short path. The following shows the matching path of nodes (each - can be regarded as a node): from left to right, from top to bottom.
├------------ ├--------- ├----- ├---- ├-- ├-- └-
2, Engine
type Engine struct {
RouterGroup
// Enables automatic redirection if the current route can't be matched but a
// handler for the path with (without) the trailing slash exists.
// For example if /foo/ is requested but a route only exists for /foo, the
// client is redirected to /foo with http status code 301 for GET requests
// and 307 for all other request methods.
RedirectTrailingSlash bool
// If enabled, the router tries to fix the current request path, if no
// handle is registered for it.
// First superfluous path elements like ../ or // are removed.
// Afterwards the router does a case-insensitive lookup of the cleaned path.
// If a handle can be found for this route, the router makes a redirection
// to the corrected path with status code 301 for GET requests and 307 for
// all other request methods.
// For example /FOO and /..//Foo could be redirected to /foo.
// RedirectTrailingSlash is independent of this option.
RedirectFixedPath bool
// If enabled, the router checks if another method is allowed for the
// current route, if the current request can not be routed.
// If this is the case, the request is answered with 'Method Not Allowed'
// and HTTP status code 405.
// If no other Method is allowed, the request is delegated to the NotFound
// handler.
HandleMethodNotAllowed bool
// If enabled, client IP will be parsed from the request's headers that
// match those stored at `(*gin.Engine).RemoteIPHeaders`. If no IP was
// fetched, it falls back to the IP obtained from
// `(*gin.Context).Request.RemoteAddr`.
ForwardedByClientIP bool
// List of headers used to obtain the client IP when
// `(*gin.Engine).ForwardedByClientIP` is `true` and
// `(*gin.Context).Request.RemoteAddr` is matched by at least one of the
// network origins of `(*gin.Engine).TrustedProxies`.
RemoteIPHeaders []string
// List of network origins (IPv4 addresses, IPv4 CIDRs, IPv6 addresses or
// IPv6 CIDRs) from which to trust request's headers that contain
// alternative client IP when `(*gin.Engine).ForwardedByClientIP` is
// `true`.
TrustedProxies []string
// #726 #755 If enabled, it will trust some headers starting with
// 'X-AppEngine...' for better integration with that PaaS.
AppEngine bool
// If enabled, the url.RawPath will be used to find parameters.
UseRawPath bool
// If true, the path value will be unescaped.
// If UseRawPath is false (by default), the UnescapePathValues effectively is true,
// as url.Path gonna be used, which is already unescaped.
UnescapePathValues bool
// Value of 'maxMemory' param that is given to http.Request's ParseMultipartForm
// method call.
MaxMultipartMemory int64
// RemoveExtraSlash a parameter can be parsed from the URL even with extra slashes.
// See the PR #1817 and issue #1644
RemoveExtraSlash bool
delims render.Delims
secureJSONPrefix string
HTMLRender render.HTMLRender
FuncMap template.FuncMap
allNoRoute HandlersChain
allNoMethod HandlersChain
noRoute HandlersChain
noMethod HandlersChain
pool sync.Pool
trees methodTrees
maxParams uint16
trustedCIDRs []*net.IPNet
}
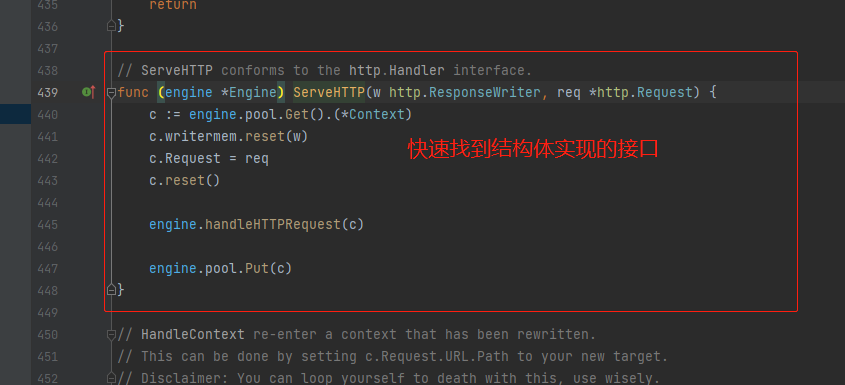
3, Routing tree node
The routing tree is composed of nodes. The nodes of the gin framework routing tree are represented by the node structure, which has the following fields:
// tree.go
type node struct {
// Node paths, such as s, s earch, and s upport above
path string
// Corresponding to the children field, the first character of the split branch is saved
// For example, search and support, the "eu" corresponding to the indices of the s node
// It means there are two branches. The initials of the branches are e and u respectively
indices string
// Son node
children []*node
// Handler chain (slice)
handlers HandlersChain
// Priority, number of registered handler s of child nodes, child nodes, etc
priority uint32
// Node types, including static, root, param, catchAll
// Static: static node (default), such as s, s earch and other nodes above
// Root: the root node of the tree
// catchAll: there are * matching nodes
// param: parameter node
nType nodeType
// Maximum number of parameters on the path
maxParams uint8
// Whether the node is a parameter node, such as: post above
wildChild bool
// Full path
fullPath string
}
4, Request method tree
In gin's route, each HTTP Method(GET, POST, PUT, DELETE...) corresponds to a radius tree. When registering the route, we will call the following addRoute function:
// routergroup.go
// GET is a shortcut for router.Handle("GET", path, handle).
func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {
return group.handle(http.MethodGet, relativePath, handlers)
}
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
// Splice address
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers)
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
// Two slice splicing
finalSize := len(group.Handlers) + len(handlers)
if finalSize >= int(abortIndex) {
panic("too many handlers")
}
mergedHandlers := make(HandlersChain, finalSize)
// Copy the starting function into mergedHandlers
copy(mergedHandlers, group.Handlers)
// Processed functions
copy(mergedHandlers[len(group.Handlers):], handlers)
return mergedHandlers
// gin.go
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
assert1(path[0] == '/', "path must begin with '/'")
assert1(method != "", "HTTP method can not be empty")
assert1(len(handlers) > 0, "there must be at least one handler")
debugPrintRoute(method, path, handlers)
// Get the tree corresponding to the request method
root := engine.trees.get(method)
if root == nil {
// If not, create one
root = new(node)
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
}
From the above code, we can see that when registering routes, we first obtain the corresponding tree according to the request method, that is, the gin framework will create a corresponding tree for each request method. Just note that one detail is that the corresponding tree relationship of the request method saved in the gin framework is not the map used, but the slice used, engine The type of trees is methodTrees, which is defined as follows:
type methodTree struct {
method string
root *node
}
type methodTrees []methodTree // slice
The get method of obtaining the tree corresponding to the request method is defined as follows:
func (trees methodTrees) get(method string) *node {
for _, tree := range trees {
if tree.method == method {
return tree.root
}
}
return nil
}
Why use slices instead of map s to store the structure of the request method - > tree? I guess it's for the sake of saving memory. After all, the number of HTTP request methods is fixed, and there are only those commonly used, so even if you use slicing to store queries, it's efficient enough. Following this idea, we can see that the initialization method of engine in the gin framework does make a memory application for the tress field:
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/",
root: true,
},
// ...
// Initialize slices with a capacity of 9 (there are 9 HTTP 1.1 request methods in total)
trees: make(methodTrees, 0, 9),
// ...
}
engine.RouterGroup.engine = engine
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
return engine
}
5, Register routing
The logic of registering routes mainly includes addRoute function and insertChild method.
addRoute
// tree.go
// addRoute adds the node with the given handle to the path.
// Not concurrency safe
func (n *node) addRoute(path string, handlers HandlersChain) {
// Construct routing tree
fullPath := path
n.priority++
numParams := countParams(path) // Count the number of parameters
// Empty tree inserts the empty tree directly into the current node
if len(n.path) == 0 && len(n.children) == 0 {
// Construct cardinality tree
n.insertChild(path, fullPath, handlers)
n.nType = root
return
}
parentFullPathIndex := 0
walk:
for {
// Update the maximum number of parameters of the current node
if numParams > n.maxParams {
n.maxParams = numParams
}
// Find the longest generic prefix
// This also means that the public prefix does not contain ':' or '*'/
// Because existing keys cannot contain these characters.
i := longestCommonPrefix(path, n.path)
// Split edge (split here is the current tree node)
// For example, at the beginning, the path is search, the new support is added, and s is their common longest prefix
// Then, s will be taken out as the parent node, and s earch and s upport will be added as the child node
if i < len(n.path) {
child := node{
path: n.path[i:], // The part after the common prefix is used as the child node
wildChild: n.wildChild,
indices: n.indices,
children: n.children,
handlers: n.handlers,
priority: n.priority - 1, //Child node priority - 1
fullPath: n.fullPath,
}
// Update maxParams (max of all children)
for _, v := range child.children {
if v.maxParams > child.maxParams {
child.maxParams = v.maxParams
}
}
n.children = []*node{&child}
// []byte for proper unicode char conversion, see #65
n.indices = string([]byte{n.path[i]})
n.path = path[:i]
n.handlers = nil
n.wildChild = false
n.fullPath = fullPath[:parentFullPathIndex+i]
}
// Insert the new node into the new parent node as the child node
if i < len(path) {
path = path[i:]
if n.wildChild { // If it is a parameter node
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
// Update maxParams of the child node
if numParams > n.maxParams {
n.maxParams = numParams
}
numParams--
// Check whether wildcards match
if len(path) >= len(n.path) && n.path == path[:len(n.path)] {
// Check for longer wildcards, such as: name and: names
if len(n.path) >= len(path) || path[len(n.path)] == '/' {
continue walk
}
}
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(path, "/", 2)[0]
}
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
// Take the initial letter of path and compare it with indices
c := path[0]
// Adding slash after processing parameters
if n.nType == param && c == '/' && len(n.children) == 1 {
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
continue walk
}
// Check whether the child node of the next byte of the path exists
// For example, the child nodes of s are now s earch and s upport, and indices is eu
// If a new route is added as super, then there is a matching part u with the support, and the current support nodes will continue to be listed
for i, max := 0, len(n.indices); i < max; i++ {
if c == n.indices[i] {
parentFullPathIndex += len(n.path)
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// Otherwise, insert
if c != ':' && c != '*' {
// []byte for proper unicode char conversion, see #65
// Note that the first character is spliced directly to n.indices
n.indices += string([]byte{c})
child := &node{
maxParams: numParams,
fullPath: fullPath,
}
// Append child node
n.children = append(n.children, child)
n.incrementChildPrio(len(n.indices) - 1)
n = child
}
n.insertChild(numParams, path, fullPath, handlers)
return
}
// Registered nodes
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
}
n.handlers = handlers
return
}
}
In fact, the above code is easy to understand. You can try to substitute the following situations into the above code logic with reference to the animation to appreciate the detailed process of the whole routing tree construction:
- Register the route for the first time, for example, register search
- Continue to register a route without a public prefix, such as blog
- Register a route with a common prefix with the previously registered route, such as support

insertChild
// tree.go
func (n *node) insertChild(numParams uint8, path string, fullPath string, handlers HandlersChain) {
// Find all parameters
for numParams > 0 {
// Find prefix up to first wildcard
wildcard, i, valid := findWildcard(path)
if i < 0 { // no wildcards were found
break
}
// Wildcard names must contain ':' and '*'
if !valid {
panic("only one wildcard per path segment is allowed, has: '" +
wildcard + "' in path '" + fullPath + "'")
}
// Check whether the wildcard has a name
if len(wildcard) < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
// Check whether this node has existing child nodes
// If we insert wildcards here, these child nodes will not be accessible
if len(n.children) > 0 {
panic("wildcard segment '" + wildcard +
"' conflicts with existing children in path '" + fullPath + "'")
}
if wildcard[0] == ':' { // param
if i > 0 {
// Insert prefix before current wildcard
n.path = path[:i]
path = path[i:]
}
n.wildChild = true
child := &node{
nType: param,
path: wildcard,
maxParams: numParams,
fullPath: fullPath,
}
n.children = []*node{child}
n = child
n.priority++
numParams--
// If the path does not end with a wildcard
// Then there will be another non wildcard sub path starting with '/'.
if len(wildcard) < len(path) {
path = path[len(wildcard):]
child := &node{
maxParams: numParams,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
n = child // Continue the next cycle
continue
}
// Or we'll be done. Insert the handler into the new leaf
n.handlers = handlers
return
}
// catchAll
if i+len(wildcard) != len(path) || numParams > 1 {
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
panic("catch-all conflicts with existing handle for the path segment root in path '" + fullPath + "'")
}
// currently fixed width 1 for '/'
i--
if path[i] != '/' {
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[:i]
// First node: catchAll node with empty path
child := &node{
wildChild: true,
nType: catchAll,
maxParams: 1,
fullPath: fullPath,
}
// Update maxParams of parent node
if n.maxParams < 1 {
n.maxParams = 1
}
n.children = []*node{child}
n.indices = string('/')
n = child
n.priority++
// The second node: the node where the variable is saved
child = &node{
path: path[i:],
nType: catchAll,
maxParams: 1,
handlers: handlers,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
return
}
// If no wildcard is found, just insert the path and handle
n.path = path
n.handlers = handlers
n.fullPath = fullPath
}
insertChild function divides the / separated parts according to the path itself, and saves them as nodes to form a tree structure. The difference between: and * in parameter matching is that the former matches one field, while the latter matches all subsequent paths.
6, Route matching
Let's first look at the entry function ServeHTTP of the gin framework for processing requests:
// gin.go
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// Here, the object pool is used to obtain an object from the object pool to reduce the frequency of gc and memory applications,
c := engine.pool.Get().(*Context) // Type assertion, cast Context pointer
// One detail here is initialization after Get object
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c) // The function we are looking for to handle HTTP requests
engine.pool.Put(c) // After processing the request, put the object back into the pool
}
The function is very long. Some codes are omitted here, and only relevant logic codes are retained:
// gin.go
func (engine *Engine) handleHTTPRequest(c *Context) {
// ...
// Find the corresponding routing tree according to the request method
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
// Find the path in the routing tree
value := root.getValue(rPath, c.Params, unescape)
if value.handlers != nil {
c.handlers = value.handlers
c.Params = value.params
c.fullPath = value.fullPath
c.Next() // Execution function chain
c.writermem.WriteHeaderNow()
return
}
// ...
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}
Route matching is implemented by the getValue method of the node. GetValue returns the nodeValue value according to the given path (key), and saves the registered processing function and the matched path parameter data.
If no handler is found, TSR (trailing slash redirection) is attempted.
// tree.go
type nodeValue struct {
handlers HandlersChain
params Params // []Param
tsr bool
fullPath string
}
// ..
func (n *node) getValue(path string, po Params, unescape bool) (value nodeValue) {
value.params = po
walk: // Outer loop for walking the tree
for {
prefix := n.path
if path == prefix {
// We should have reached the node containing the handler.
// Check whether the node has a handler registered
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
if path == "/" && n.wildChild && n.nType != root {
value.tsr = true
return
}
// The handler function was not found. Check whether there is a registered function + / at the end of this path
indices := n.indices
for i, max := 0, len(indices); i < max; i++ {
if indices[i] == '/' {
n = n.children[i]
value.tsr = (len(n.path) == 1 && n.handlers != nil) ||
(n.nType == catchAll && n.children[0].handlers != nil)
return
}
}
return
}
if len(path) > len(prefix) && path[:len(prefix)] == prefix {
path = path[len(prefix):]
// If the node has no wildcard (param or catchAll) child nodes
// We can continue to find the next child node
if !n.wildChild {
c := path[0]
indices := n.indices
for i, max := 0, len(indices); i < max; i++ {
if c == indices[i] {
n = n.children[i] // Traversal tree
continue walk
}
}
// Can't find
// If there is a leaf node with the same URL but no end /
// We can suggest redirecting there
value.tsr = path == "/" && n.handlers != nil
return
}
// Process wildcard child nodes according to node type
n = n.children[0]
switch n.nType {
case param:
// find param end (either '/' or path end)
end := 0
for end < len(path) && path[end] != '/' {
end++
}
// Save wildcard values
if cap(value.params) < int(n.maxParams) {
value.params = make(Params, 0, n.maxParams)
}
i := len(value.params)
value.params = value.params[:i+1] // Expand slice within pre allocated capacity
value.params[i].Key = n.path[1:]
val := path[:end]
if unescape {
var err error
if value.params[i].Value, err = url.QueryUnescape(val); err != nil {
value.params[i].Value = val // fallback, in case of error
}
} else {
value.params[i].Value = val
}
// Continue to query downward
if end < len(path) {
if len(n.children) > 0 {
path = path[end:]
n = n.children[0]
continue walk
}
// ... but we can't
value.tsr = len(path) == end+1
return
}
if value.handlers = n.handlers; value.handlers != nil {
value.fullPath = n.fullPath
return
}
if len(n.children) == 1 {
// Handler not found Check whether the route with / at the end of this path has a registration function
// Recommended for TSR
n = n.children[0]
value.tsr = n.path == "/" && n.handlers != nil
}
return
case catchAll:
// Save wildcard values
if cap(value.params) < int(n.maxParams) {
value.params = make(Params, 0, n.maxParams)
}
i := len(value.params)
value.params = value.params[:i+1] // Expand slice within pre allocated capacity
value.params[i].Key = n.path[2:]
if unescape {
var err error
if value.params[i].Value, err = url.QueryUnescape(path); err != nil {
value.params[i].Value = path // fallback, in case of error
}
} else {
value.params[i].Value = path
}
value.handlers = n.handlers
value.fullPath = n.fullPath
return
default:
panic("invalid node type")
}
}
// Cannot find if there is a route added / at the end of the current path
// We'll suggest redirecting there
value.tsr = (path == "/") ||
(len(prefix) == len(path)+1 && prefix[len(path)] == '/' &&
path == prefix[:len(prefix)-1] && n.handlers != nil)
return
}
}