Git internal principle
1. Summary
As a software development engineer, we rarely fight alone in our daily work. It will certainly involve multiple people working together to complete a project. How can we give the code we develop to other developers? Via U SB flash drive? Or write it in word and send it to each other? This is obviously not elegant enough. CVS, SVN, GIT and other tools with version control function perfectly solve this problem. Developers can realize the interworking of code and other files through SVN or GIT.
The main difference between Git and other version control systems (including Subversion and approximation tools) is the way Git treats data. Conceptually, most other systems store information in the form of file change lists (CVS, Subversion, Perforce, Bazaar, etc.) treat the information they store as a set of basic files and the differences that each file gradually accumulates over time (they are commonly referred to as delta based version control).
I think everyone is familiar with how to use Git, but how does Git realize version control, multi person collaboration and file merging? Next, we will go inside Git and deeply explore how Git does it. We should not only know what it is, but also know why it is.
2. Git object
Git is actually a content addressable file system, which means that the core of Git is actually a key value based database. We can insert any type of content into git warehouse, and it will return a unique key, which can retrieve the content at any time.
Since Git is a file system, it should be able to act as the concepts of "file" and "folder", which git collectively refers to as "object". That is, any type of content inserted into the GIT repository is called an object.
2.1. blob object
The data object acts as the concept of "file" in the file system (but does not contain the file name). The data object contains a key value pair, where the value is the file content, and the key is the data to be stored plus a header information (header) the checksum obtained by performing SHA-1 check operation together. The first two characters of the checksum are used to name the subdirectory, and the remaining 38 characters are used as the file name.
Use the underlying command git hash object to demonstrate:
1. After git init initializes a git repository, you can see that git automatically creates an objects directory and two subdirectories info and pack:
$ git init git-test Initialized empty Git repository in E:/demo-projects/git-test/.git/ $ cd git-test/ $ find .git/objects/ .git/objects/ .git/objects/info .git/objects/pack
2. Next, create a new blob object with git hash object and store it in the hash database:
$ echo 'content one two' | git hash-object -w --stdin 2938b4de55b3da15112c00deadf244dd6d3ef073 $ find .git/objects/ .git/objects/ .git/objects/29 .git/objects/29/38b4de55b3da15112c00deadf244dd6d3ef073 .git/objects/info .git/objects/pack
3. The Git cat file command can be used to fetch data from Git:
$ git cat-file -p 2938b4de55b3da15112c00deadf244dd6d3ef073 content one two $ git cat-file -t 2938b4de55b3da15112c00deadf244dd6d3ef073 blob $ git cat-file -s 2938b4de55b3da15112c00deadf244dd6d3ef073 16
Cat file parameters mainly use the following
-t show object type -s show object size -p pretty-print object's content
4. Start simple version control: create a file and add it to the Git database, then modify the file content and store it in the database to see what changes will occur:
$ echo 'version 1' > test.txt $ git hash-object -w test.txt warning: LF will be replaced by CRLF in test.txt. The file will have its original line endings in your working directory 83baae61804e65cc73a7201a7252750c76066a30 $ echo 'version 2' > test.txt $ git hash-object -w test.txt warning: LF will be replaced by CRLF in test.txt. The file will have its original line endings in your working directory 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a $ find .git/objects/ -type f .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a .git/objects/29/38b4de55b3da15112c00deadf244dd6d3ef073 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30
As you can see, the test is added twice Txt are saved in the database. We can use cat file to retrieve the file content corresponding to the specified SHA-1 value. Note that since the blob object does not specify a file name, the file contents can theoretically be taken out to any file through cat file.
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test-new.txt $ cat test-new.txt version 1
2.2. tree object
Although git cat file is very powerful, it is unrealistic to remember the SHA-1 value of each file in daily work. Git introduces tree objects to assist management, which are similar to the concept of folders in the file system.
Usually, Git creates and records a corresponding tree object according to the state represented by the temporary storage area (i.e. index area, the same below) at a certain time. It records the permission, file type, SHA-1 information and snapshot of file name at a certain time of each file / subfolder.
We use the Git update index command to update the test new Txt add to Git staging area:
$ git update-index --add --cacheinfo 100644 83baae61804e65cc73a7201a7252750c76066a30 test-new.txt
Note: 100644 here refers to the file mode, where 100 refers to the file and 644 refers to the permission of the file. Other options for file mode include:
100755: executable
120000: symbolic links
040000: folder / tree object
At this point, we found that An index directory appears under Git directory, and it is found through tortoise git that test new Txt file has become the status tracked by Git. Use git status to verify:
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: test-new.txt
Next, continue with the topic, write the contents of the temporary storage area into a tree object with git write tree, and then use cat file to view the contents contained in the tree object:
$ git write-tree a37e53c0b0e7c2520d1d594f9b5246ee148de814 $ git cat-file -p a37e53c0b0e7c2520d1d594f9b5246ee148de814 100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test-new.txt
Now that we have a snapshot, let's create the next tree object: including a new file new Txt and the previously added test Txt (version 2).
$ echo "new file" > new.txt $ git update-index --add new.txt warning: LF will be replaced by CRLF in new.txt. The file will have its original line endings in your working directory $ git update-index --add --cacheinfo 100644 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test-new.txt $ git write-tree 8821d4c684e63569c0bf448affd5faef50919338 $ git cat-file -p 8821d4c684e63569c0bf448affd5faef50919338 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test-new.txt
After adding, use git status to view the status of the staging area: you can see it clearly
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: new.txt
new file: test-new.txt
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: test-new.txt
Next, you can use the read tree command to add the first tree object to the second tree object to construct a hierarchy:
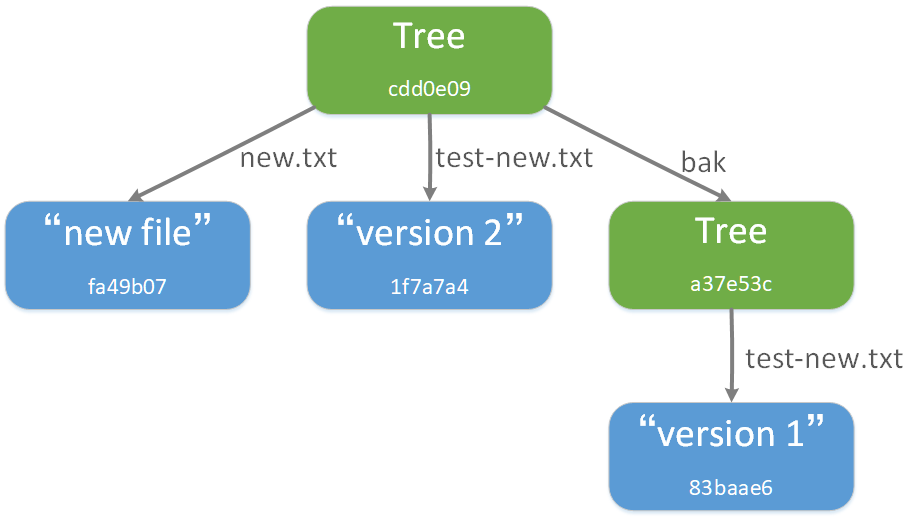
$ git read-tree --prefix=bak a37e53c0b0e7c2520d1d594f9b5246ee148de814 $ git write-tree cdd0e09fa699af925dfb6747986a60b69c1a0c05 $ git cat-file -p cdd0e09fa699af925dfb6747986a60b69c1a0c05 040000 tree a37e53c0b0e7c2520d1d594f9b5246ee148de814 bak 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test-new.txt ####################################################################### # Verify test new under different tree objects Txt $ git cat-file -p a37e53c0b0e7c2520d1d594f9b5246ee148de814 100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test-new.txt $ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 version 1 $ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a version 2
At this time, the structure of the new tree object cdd0e09fa699af925dfb6747986a60b69c1a0c05 is as follows:
2.3. commit object
Here, we find that even if the tree object is introduced, it still needs to use the SHA-1 value to refer to each tree object, and we can't completely remember which tree was created at which time and what content. Just like now, do you remember the SHA-1 value of each tree created in this article? Let's review:
1. The first tree, with SHA-1 value of a37e53c0b0e7c2520d1d594f9b5246ee148de814, contains a file test new with "version 1" txt
$ git cat-file -p a37e53c0b0e7c2520d1d594f9b5246ee148de814 100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test-new.txt $ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 version 1
2. The second tree, with the SHA-1 value of 8821d4c684e63569c0bf448affd5faef50919338, contains a file test new with the content of "version 2" Txt and a file with the content "new file" txt
$ git cat-file -p 8821d4c684e63569c0bf448affd5faef50919338 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test-new.txt $ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a version 2 $ git cat-file -p fa49b077972391ad58037050f2a75f74e3671e92 new file
3. The third tree, whose SHA-1 value is cdd0e09fa699af925dfb6747986a60b69c1a0c05, contains the second tree and the first tree. The contents of the first tree are placed in the bak directory, as follows:
$ git cat-file -p cdd0e09fa699af925dfb6747986a60b69c1a0c05 040000 tree a37e53c0b0e7c2520d1d594f9b5246ee148de814 bak 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test-new.txt $ git cat-file -p a37e53c0b0e7c2520d1d594f9b5246ee148de814 100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test-new.txt $ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 version 1 $ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a version 2
After reviewing the existing three tree objects, a commit object will be introduced to record the submitter, submission time and possible parent submissions:
$ echo 'first commit' | git commit-tree a37e53c0b0e7c2520d1d594f9b5246ee148de814 1580971f914fe3bed9c1ccdb117387db3525cf63 $ git cat-file -p 1580971f914fe3bed9c1ccdb117387db3525cf63 tree a37e53c0b0e7c2520d1d594f9b5246ee148de814 author Lu Hao <luhao@tp-link.com.cn> 1638934182 +0800 committer Lu Hao <luhao@tp-link.com.cn> 1638934182 +0800 first commit
Next, create two more submissions and concatenate the three tree objects:
$ echo 'second commit' | git commit-tree 8821d4c684e63569c0bf448affd5faef50919338 -p 1580971f914fe3bed9c1ccdb117387db3525cf63 bb6d6733199b5dbe16b4d5247999d6c9487cbd15 $ echo 'third commit' | git commit-tree cdd0e09fa699af925dfb6747986a60b69c1a0c05 -p bb6d6733199b5dbe16b4d5247999d6c9487cbd15 ff9152a5392a6f0f1f290cd8928d41b308b14fa9
At this time, use the git log --stat command on the last submission to find that there is a complete submission log: This is actually what git add and git commit do: save the rewritten file as a data object, update the staging area, record the tree object, and finally create a submission object indicating the top-level tree object and the parent submission.
$ git log --stat ff9152a5392a6f0f1f290cd8928d41b308b14fa9
commit ff9152a5392a6f0f1f290cd8928d41b308b14fa9
Author: Lu Hao <luhao@tp-link.com.cn>
Date: Wed Dec 8 11:46:29 2021 +0800
third commit
bak/test-new.txt | 1 -
1 file changed, 1 deletion(-)
commit bb6d6733199b5dbe16b4d5247999d6c9487cbd15
Author: Lu Hao <luhao@tp-link.com.cn>
Date: Wed Dec 8 11:32:13 2021 +0800
second commit
bak/test-new.txt | 1 +
new.txt | 1 +
test-new.txt | 2 +-
3 files changed, 3 insertions(+), 1 deletion(-)
commit 1580971f914fe3bed9c1ccdb117387db3525cf63
Author: Lu Hao <luhao@tp-link.com.cn>
Date: Wed Dec 8 11:29:42 2021 +0800
first commit
test-new.txt | 1 +
1 file changed, 1 insertion(+)
3. Git reference
HEAD, branch, tag, etc. are essentially references. You can see their existence in the. git/refs directory. git references are files that help users identify the corresponding SHA-1 value. We can create a new reference to record the location of the latest submission, which is actually the essence of branches.
$ echo ff9152a5392a6f0f1f290cd8928d41b308b14fa9 > .git/refs/heads/master $ git log --pretty=oneline master ff9152a5392a6f0f1f290cd8928d41b308b14fa9 (HEAD -> master) third commit bb6d6733199b5dbe16b4d5247999d6c9487cbd15 second commit 1580971f914fe3bed9c1ccdb117387db3525cf63 first commit
At this point, you can use the advanced command git log to view the submission history:
$ git log
commit ff9152a5392a6f0f1f290cd8928d41b308b14fa9 (HEAD -> master)
Author: Lu Hao <luhao@tp-link.com.cn>
Date: Wed Dec 8 11:46:29 2021 +0800
third commit
commit bb6d6733199b5dbe16b4d5247999d6c9487cbd15
Author: Lu Hao <luhao@tp-link.com.cn>
Date: Wed Dec 8 11:32:13 2021 +0800
second commit
commit 1580971f914fe3bed9c1ccdb117387db3525cf63
Author: Lu Hao <luhao@tp-link.com.cn>
Date: Wed Dec 8 11:29:42 2021 +0800
first commit
HEAD reference is a symbolic reference, that is, a pointer to other references. HEAD generally points to the current branch. It plays a key role in indicating the latest submitted SHA-1 value when performing other operations such as creating a new branch, switching branches, submitting, etc.
Tag reference is a branch reference that never moves. It always points to the same submission object, which is called * * tag object**
The remote reference is located at git/object/origin directory stores remote branches, labels and other information. It is a read-only reference. The HEAD reference can never point to the remote reference. Therefore, the remote reference can never be updated with commit, but can only be push ed to the remote by updating the local reference.
4. Git package
As mentioned earlier, every time a new object is created, it will be created in the A series of files are generated in the git/objects directory, and Git is a "snapshot based" version control system. Each submission will generate a complete snapshot. As time goes by, if no operation is done, the volume of GIT database will grow faster and faster. Therefore, GIT has designed a compression and packaging mechanism to prevent too many objects.
Before compression, the format used by Git to initially store objects to disk is called "loose" object format, and Git will package these loose objects into Git packages through compression and packaging to realize incremental storage.
git gc is such a command, which will be automatically triggered when executing pull and other commands. Before execution, check the files in the objects Directory:
$ find .git/objects/ -type f .git/objects/15/80971f914fe3bed9c1ccdb117387db3525cf63 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a .git/objects/29/38b4de55b3da15112c00deadf244dd6d3ef073 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 .git/objects/88/21d4c684e63569c0bf448affd5faef50919338 .git/objects/a3/7e53c0b0e7c2520d1d594f9b5246ee148de814 .git/objects/bb/6d6733199b5dbe16b4d5247999d6c9487cbd15 .git/objects/cd/d0e09fa699af925dfb6747986a60b69c1a0c05 .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 .git/objects/ff/9152a5392a6f0f1f290cd8928d41b308b14fa9
Then execute git gc: you will find that many object s have disappeared and replaced by a pair of files in the pack (idx and pack). Look at the data in the package with verify pack and find that all the three submissions we made earlier are packaged.
$ git gc Enumerating objects: 9, done. Counting objects: 100% (9/9), done. Delta compression using up to 6 threads Compressing objects: 100% (5/5), done. Writing objects: 100% (9/9), done. Total 9 (delta 0), reused 5 (delta 0), pack-reused 0 $ find .git/objects/ -type f .git/objects/29/38b4de55b3da15112c00deadf244dd6d3ef073 .git/objects/info/commit-graph .git/objects/info/packs .git/objects/pack/pack-dcaadb1de954542edabb220467ede8e288a9461e.idx .git/objects/pack/pack-dcaadb1de954542edabb220467ede8e288a9461e.pack $ git verify-pack -v .git/objects/pack/pack-dcaadb1de954542edabb220467ede8e288a9461e.idx ff9152a5392a6f0f1f290cd8928d41b308b14fa9 commit 219 152 12 bb6d6733199b5dbe16b4d5247999d6c9487cbd15 commit 220 152 164 1580971f914fe3bed9c1ccdb117387db3525cf63 commit 171 123 316 83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 439 fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 458 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 476 cdd0e09fa699af925dfb6747986a60b69c1a0c05 tree 105 105 495 a37e53c0b0e7c2520d1d594f9b5246ee148de814 tree 40 50 600 8821d4c684e63569c0bf448affd5faef50919338 tree 75 77 650 non delta: 9 objects .git/objects/pack/pack-dcaadb1de954542edabb220467ede8e288a9461e.pack: ok
However, it should be noted that git gc will not package dangling data. For example, if SHA-1 of the submitted object is not stored in the reference, the submitted object will not be packaged during packaging, as follows:
$ git gc Enumerating objects: 5, done. Counting objects: 100% (5/5), done. Writing objects: 100% (5/5), done. Total 5 (delta 0), reused 0 (delta 0), pack-reused 0 $ find .git/objects/ -type f .git/objects/15/80971f914fe3bed9c1ccdb117387db3525cf63 .git/objects/29/38b4de55b3da15112c00deadf244dd6d3ef073 .git/objects/88/21d4c684e63569c0bf448affd5faef50919338 .git/objects/bb/6d6733199b5dbe16b4d5247999d6c9487cbd15 .git/objects/ff/9152a5392a6f0f1f290cd8928d41b308b14fa9 .git/objects/info/packs .git/objects/pack/pack-44648cd90240ab687547eee0989f2dde2aee9a36.idx .git/objects/pack/pack-44648cd90240ab687547eee0989f2dde2aee9a36.pack $ git verify-pack -v .git/objects/pack/pack-44648cd90240ab687547eee0989f2dde2aee9a36.idx 83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 12 fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 31 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 49 cdd0e09fa699af925dfb6747986a60b69c1a0c05 tree 105 105 68 a37e53c0b0e7c2520d1d594f9b5246ee148de814 tree 40 50 173 non delta: 5 objects .git/objects/pack/pack-44648cd90240ab687547eee0989f2dde2aee9a36.pack: ok
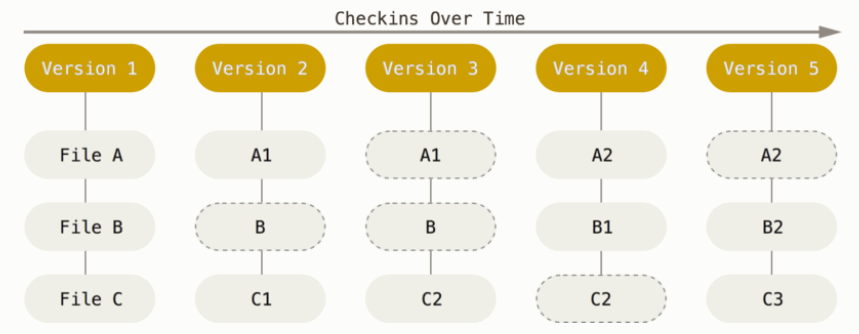
Through the gc mechanism, Git also turns files into incremental storage. Every time you submit an update or save the project status, Git will create a snapshot of all the files at that time and save the index of the snapshot. If the file is not modified, Git will no longer re store the file, but only keep a link to the previously stored file. After gc is executed, Git will recognize the change of the response file according to the file name and file size, and save the difference.
5. Git transport protocol
Git can transfer data between version libraries in two main ways: dumb protocol and smart protocol
5.1. Agreement
In the transmission process, the server does not need to have Git specific code; The fetching process is a series of HTTP GET requests. In this case, the client can infer the layout of the server Git warehouse.
The git warehouse distribution is inferred through a series of operations such as pulling info/refs, obtaining HEAD, reading tree objects, etc. this method is almost no longer used.
5.2 intelligent protocol
Intelligent protocol is a more commonly used method of transmitting data. It needs to run a process on the server to read local data, understand what the client has and needs, and generate an appropriate package file for it. A total of two groups of processes are used to transmit data, which are responsible for uploading and downloading data respectively.
5.2. 1. Upload data
The two processes started by uploading data are send pack and receive pack. The send pack process running on the client is connected to the receive pack process running on the remote end.
When executing the git push origin master command, the GIT receive pack command will immediately send a line of response for each reference it has. When the client receives the response, it will know the status of the server. Your send pack process will judge which submission records it has but the server does not have, Send pack will inform receive pack of the references that will be updated in this push.
5.2. 2. Download data
The two processes started by downloading data are fetch pack and upload pack. The client starts the fetch pack process and connects to the remote upload pack process to negotiate the subsequent transmitted data.
The fetch pack process looks at the objects it owns and responds to "want" and the SHA-1 value of the objects it needs. It also sends "have" and SHA-1 values for all objects it already owns. At the end of the list, it also sends "done" to inform the upload pack process that it can start sending the package file of the objects it needs.