
preface
The main goal is to crawl the fan data of the specified users on Github and conduct a wave of simple visual analysis of the crawled data. Let's start happily~
development tool
Python version: 3.6.4
Related modules:
bs4 module;
requests module;
argparse module;
Pyecarts module;
And some python built-in modules.
Environment construction
Install Python and add it to the environment variable. pip can install the relevant modules required.
Data crawling
I feel like I haven't used beatifulsoup for a long time, so I'll use it to parse the web page today to get the data we want. Take my own account for example:
Let's grab the user names of all followers, which are in tags like the following figure:
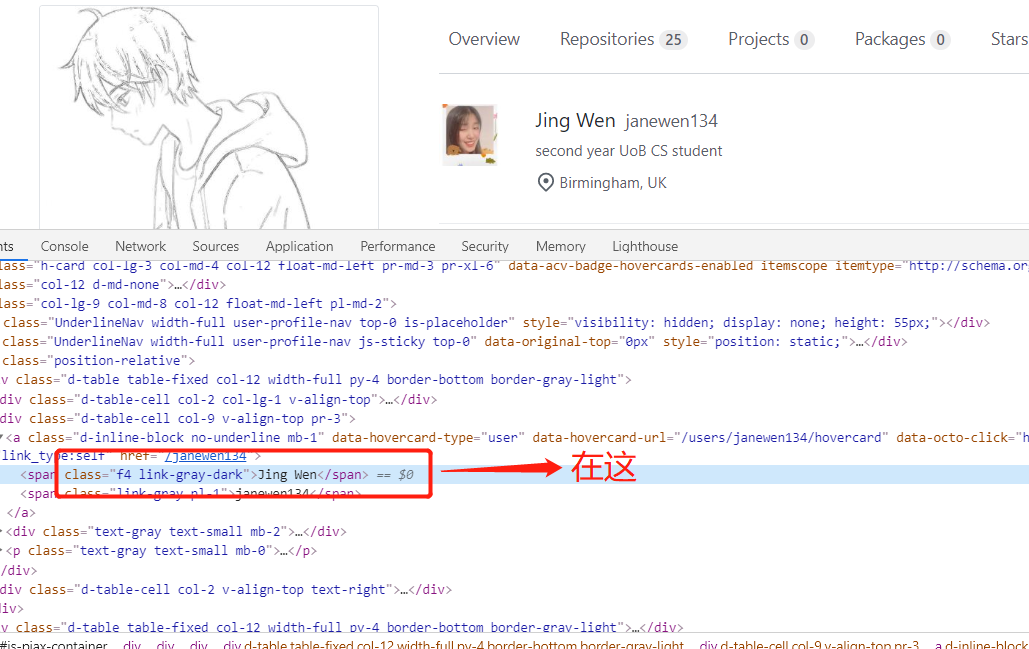
They can be easily extracted with beatifulsoup:
'''get followers User name for'''
def getfollowernames(self):
print('[INFO]: Getting%s All followers user name...' % self.target_username)
page = 0
follower_names = []
headers = self.headers.copy()
while True:
page += 1
followers_url = f'https://github.com/{self.target_username}?page={page}&tab=followers'
try:
response = requests.get(followers_url, headers=headers, timeout=15)
html = response.text
if 've reached the end' in html:
break
soup = BeautifulSoup(html, 'lxml')
for name in soup.find_all('span', class_='link-gray pl-1'):
print(name)
follower_names.append(name.text)
for name in soup.find_all('span', class_='link-gray'):
print(name)
if name.text not in follower_names:
follower_names.append(name.text)
except:
pass
time.sleep(random.random() + random.randrange(0, 2))
headers.update({'Referer': followers_url})
print('[INFO]: Successfully obtained%s of%s individual followers user name...' % (self.target_username, len(follower_names)))
return follower_names
Then, we can enter their home page according to these user names to capture the detailed data of corresponding users. The construction method of each home page link is as follows:
https://github.com / + user name for example: https://github.com/CharlesPikachu
The data we want to capture include:
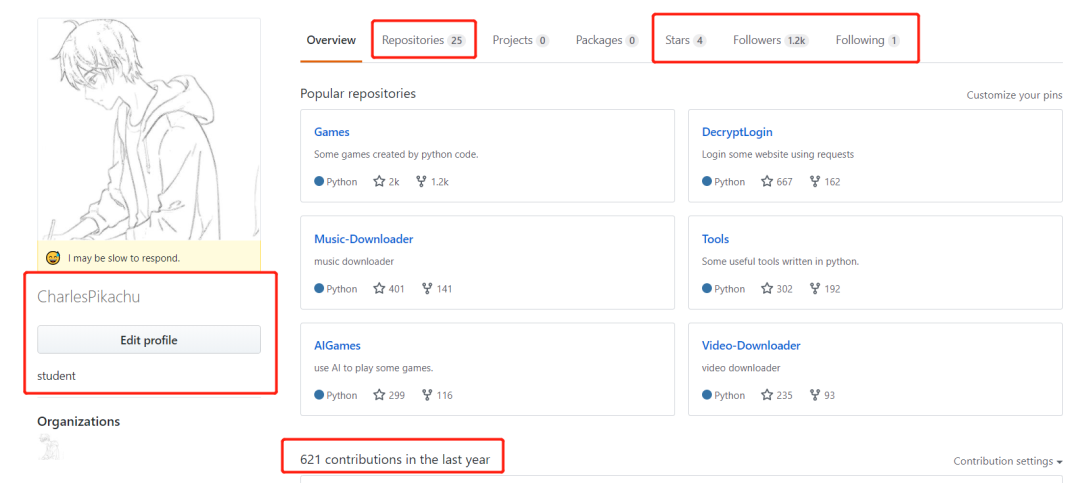
Similarly, we use beatifulsoup to extract this information:
for idx, name in enumerate(follower_names):
print('[INFO]: Crawling user%s Details of...' % name)
user_url = f'https://github.com/{name}'
try:
response = requests.get(user_url, headers=self.headers, timeout=15)
html = response.text
soup = BeautifulSoup(html, 'lxml')
# --Get user name
username = soup.find_all('span', class_='p-name vcard-fullname d-block overflow-hidden')
if username:
username = [name, username[0].text]
else:
username = [name, '']
# --Location
position = soup.find_all('span', class_='p-label')
if position:
position = position[0].text
else:
position = ''
# --Number of warehouses, stars, followers, following
overview = soup.find_all('span', class_='Counter')
num_repos = self.str2int(overview[0].text)
num_stars = self.str2int(overview[2].text)
num_followers = self.str2int(overview[3].text)
num_followings = self.str2int(overview[4].text)
# --Contribution (last year)
num_contributions = soup.find_all('h2', class_='f4 text-normal mb-2')
num_contributions = self.str2int(num_contributions[0].text.replace('\n', '').replace(' ', ''). \
replace('contributioninthelastyear', '').replace('contributionsinthelastyear', ''))
# --Save data
info = [username, position, num_repos, num_stars, num_followers, num_followings, num_contributions]
print(info)
follower_infos[str(idx)] = info
except:
pass
time.sleep(random.random() + random.randrange(0, 2))
Data visualization
Here, take our own fan data as an example, about 1200.
Let's take a look at the distribution of the number of code submissions they have made in the past year:
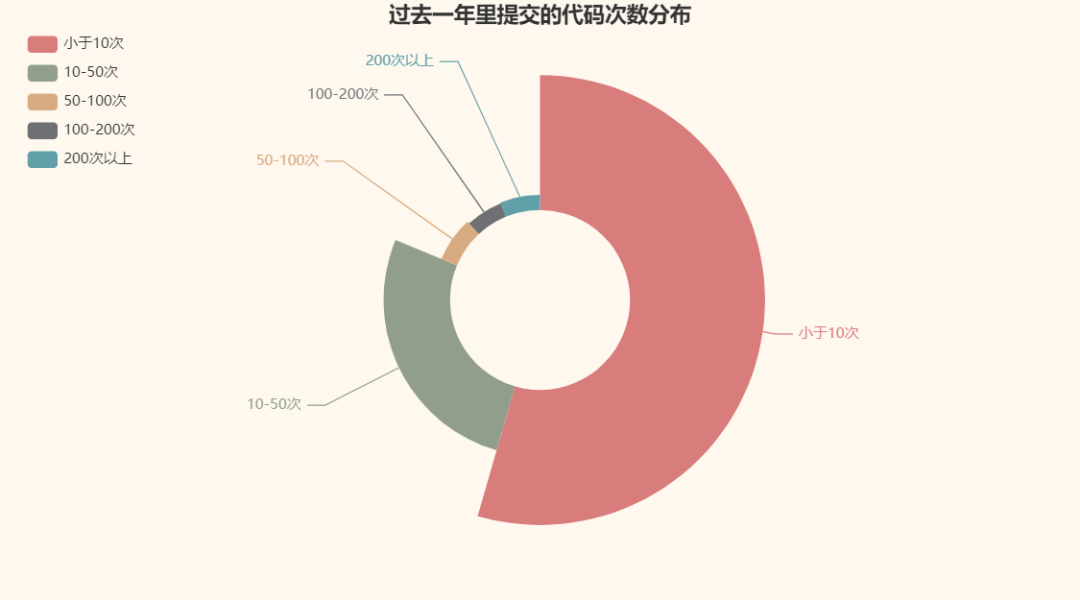
The name of the person who submitted the most was fengjixuchui, with a total of 9437 submissions in the past year. On average, I have to submit more than 20 times a day, which is too diligent.
Let's take a look at the distribution of warehouses owned by each person:
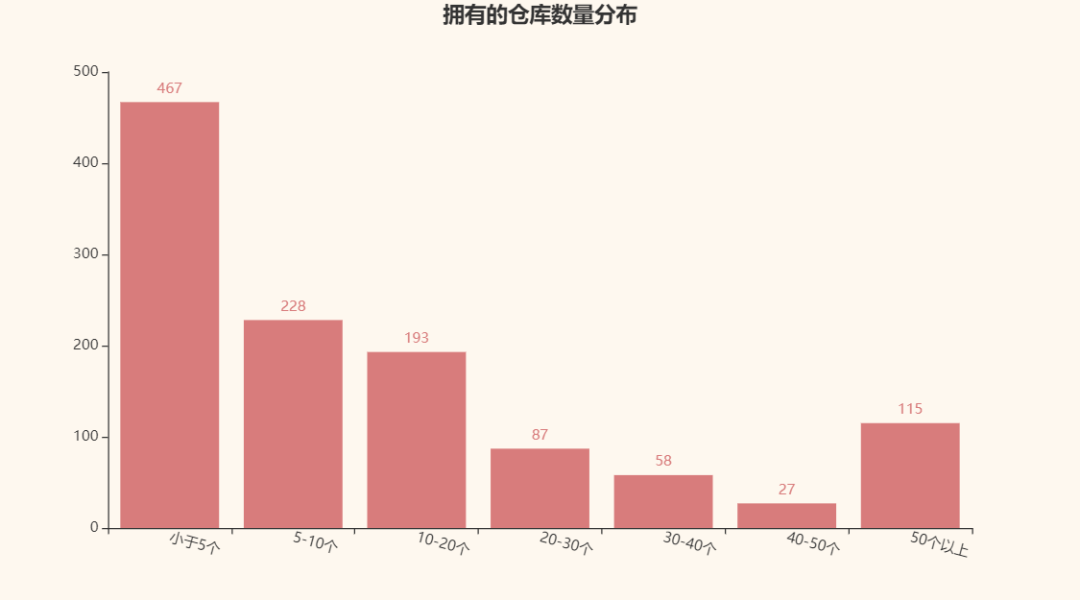
I thought it would be a monotonous curve. It seems to underestimate you.
Next, let's take a look at the distribution of the number of star s:
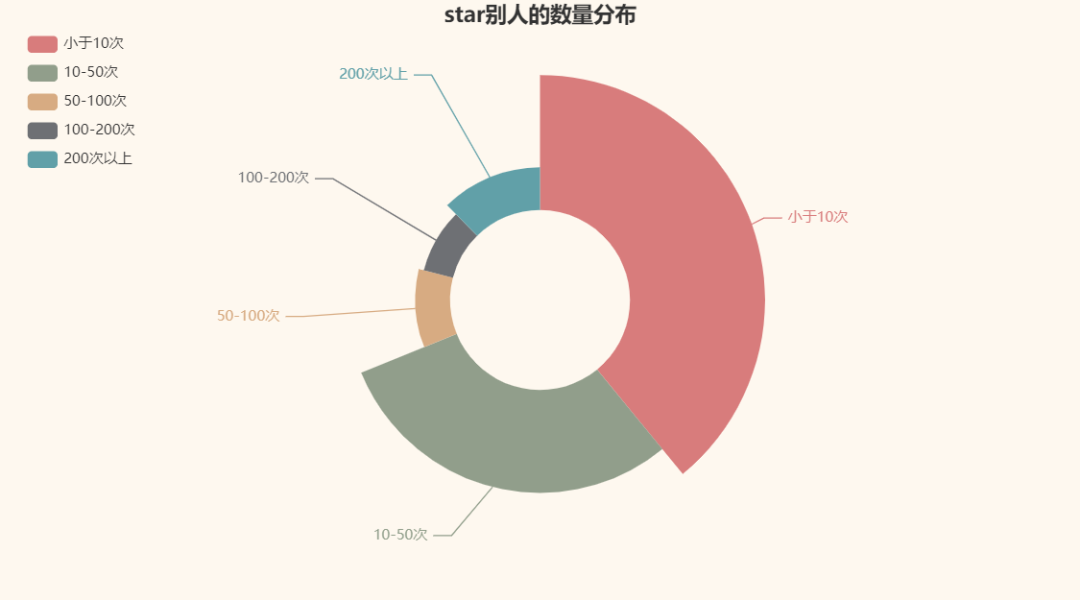
OK, at least not all of them are "diving and whoring"
. Praise the elder brother named lifa123, who gave 18700 to others 👍, It's so beautiful.
Let's take a look at the distribution of the number of fans owned by more than 1000 people:
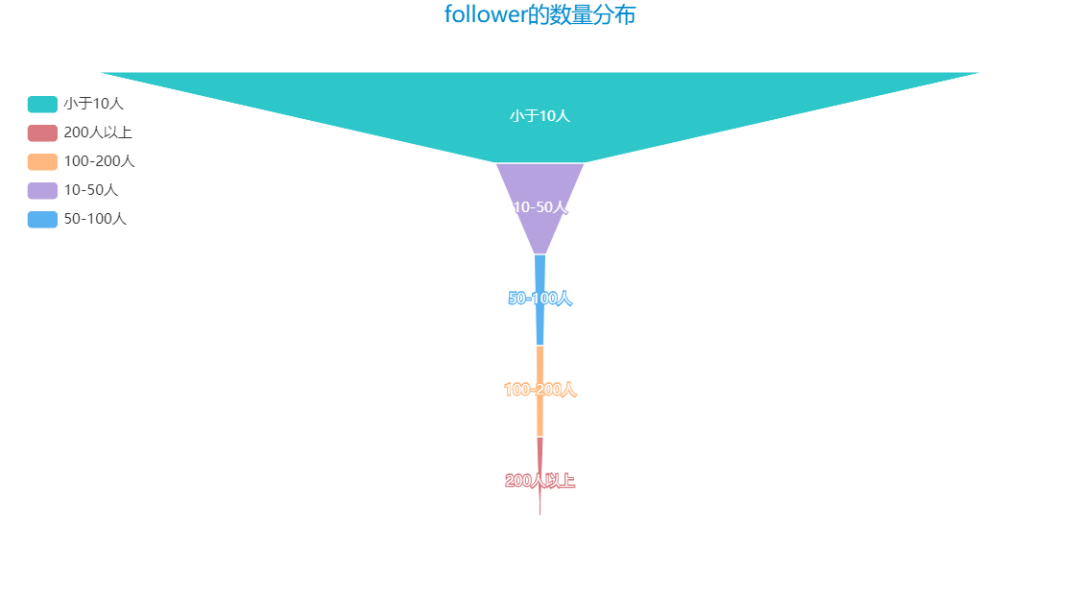
After a brief look, there are many small partners with more followers than me. Sure enough, experts are among the people.
After reading this article, my favorite friends point out their love and support, and pay attention to the python data crawler cases I share every day. The next article shares Python crawling and simple analysis of A-share company data
All done ~ for the complete source code, see the personal profile or private letter to obtain relevant documents.