I summary
- GlusterFS: open source distributed file system without metadata server
- FS: file system
1) File system composition
1. File system interface (API)
- 2. Function module (management and storage tool): software collection for object management
- 3. Objects and properties (consumers using this file system)
2) File system FS function
From the perspective of system, file system is a system that organizes and allocates the space of file storage device, is responsible for file storage, and protects and retrieves the stored files; It is mainly responsible for creating files for users, storing, reading, modifying and dumping files, and controlling file access
3) Mount usage of file system FS
In addition to the root file system, it needs to be mounted to the mount point before it can be accessed The mount point is a directory file associated with the partition device file
4) Composition of distributed file system (GFS)
Storage server
- client
- . NFS/samba storage gateway composition
5) Distributed file system (GFS) features
Scalability and high performance
- High availability (redundancy)
- Global unified namespace
- Elastic volume management (replication volume, striped volume)
- Based on standard protocol (http https)
6) Distributed file system (GFS) terminology
brick block: the server that actually stores user data
- volume: partition of the local file system
- Fuse: the file system in user space (pseudo file system), the tool for connecting the client and server, the local data is transmitted through the network, and the client service port connection tool requests to fuse
- VFS: virtual interface. The user submits a request to VFS. VFS gives the file to fuse, then to GFS client, and finally to remote storage
- Glusterd: Server
7. Role of metadata server
Store metadata to help users locate file location, index and other information
In the file system with metadata server, if the metadata is damaged, the file system will be unavailable directly (single point of failure - server location)
See the figure below for details: if A goes down, data cannot be obtained.
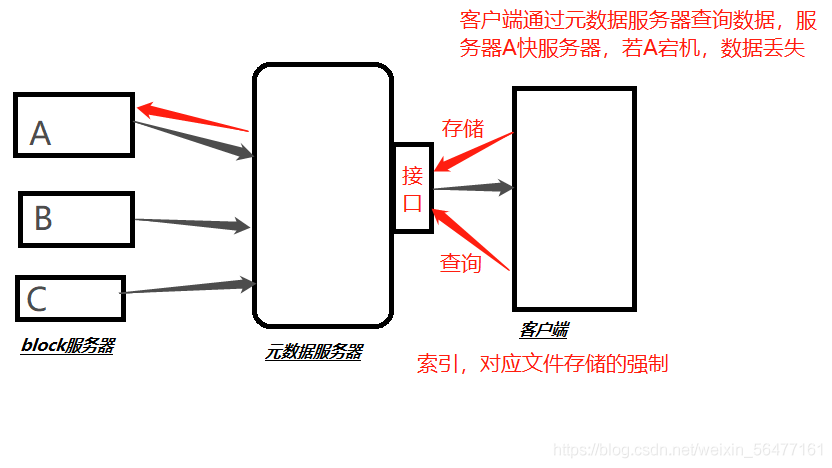
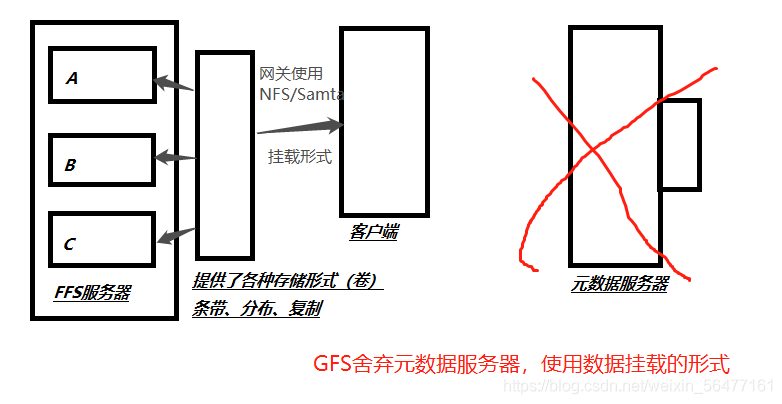
GFS discards the metadata server and uses the form of data mounting to mount to the client. The mounted gateway is NFS/Samba to realize the data sharing of three GFS servers ABC. Even if server A goes down, you can get data from server B/C
II Modular stack architecture
A variety of functional modules are combined to form a stack architecture
- Modular and stack architecture
- Through the combination of modules, complex functions are realized
Module part:
- gige: Gigabit port
- TCP/ip: network protocol
- infiniband: network protocol, TCP and IP have the characteristics of forwarding lost packets, and the probability of packet loss is small
RDMA: responsible for data transmission and data transmission protocol
Solve the delay of data processing between client and server in transmission
posix: portable system interface to solve the portability of different operating systems
III Working principle of GFS
User: install the client, install fuse, mount to the server, and store the files
1. First, the system calls VFS (virtual interface), and then sends the data to fuse (pseudo file system) to connect the client and server
2. Save the data in a virtual file
3. Transfer data to the server through the client
4. The server uses VFS interface and saves it in the actual file system
GFS workflow
Writing process
GFS client server
Requirement: save the data in the GFS file system (the client sends a write request locally)
The API of VFS accepts the request – > combine the function modules and give the data to fuse (kernel pseudo file system)
FUSE can simulate the operating system and transfer the file system. The device location for transfer is: / dev/fuse (device virtual device file for transfer)
/The dev/fuse virtual device file will deliver the data to the GFS client
The GFS client will process the data according to the configuration file, and then send it to the GFS server through TCP/IB/rdma network
GFS server
After receiving data
The data is saved on the corresponding storage node
See the figure below for details
IV GFS volume type
1) Distributed volume
- The file is not partitioned
- Save HASH values through extended file properties
- The supported underlying file systems are EXT3, EXT4, ZFS and XFS
characteristic:
- The files are stored separately without splitting size, and the efficiency is not improved
- Files are distributed on different servers without redundancy
- A single point of failure can cause data loss
- Rely on underlying data protection
Create command
- Create a distributed volume named dis volume, and the files will be distributed in server1:/dir1, server2:/dir2 and server3:/dir3 according to HASH
gluster volume create dis-volume server1:/dir1 server2:/dir2
2) Strip roll
Size split, polling storage on each node Without redundancy,
characteristic:
- The data is divided into smaller pieces and distributed to different strips in the block server cluster
- Distribution reduces load and speeds up access with smaller files
- No data redundancy
Create command
- A striped volume named stripe volume is created. The file will be stored in two bricks of Server1:/dir1 and Server2:/dir2 by block polling
gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir2
3) Copy volume
Redundant backup, the storage space of multiple nodes is inconsistent, and the access is based on the node with the minimum barrel effect At least two servers and more
characteristic:
- All servers in the volume keep a complete copy
- The number of copies of a volume can be determined by the customer when it is created
- By at least two block servers or more
- Redundancy
Create command
- Create a replication volume named rep volume, and the file will store two copies at the same time, in Server1:/dir1 and Server2:/dir2 bricks respectively
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
4) Distributed striped volume
Distributed, striped volume function Large file access processing, at least 4 servers
Create command
A distributed striped volume named dis rep is created. When configuring a distributed replication volume, the number of storage servers contained in the Brick in the volume must be a multiple of the replication number (> = 2 times)
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
5) Distributed replication volume
Distributed, replication volume function Features of both distributed and replicated volumes
Create command
A distributed striped volume named dis rep is created. When configuring a distributed replication volume, the number of storage servers contained in the Brick in the volume must be a multiple of the replication number (> = 2 times)
gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
6) Striped copy volume
similar RAID 10,It has the characteristics of striped volume and replicated volume at the same time
7) Distributed striped volume
Composite volumes of three basic volumes are commonly used for classes Map Reduce application
V Relevant maintenance commands
| command | meaning |
|---|---|
| gluster volume list | Viewing GlusterFS volumes |
| gluster volume info | View information for all volumes |
| gluster volume status | View the status of all volumes |
| gluster volume stop dis-stripe | Stop a volume |
| gluster volume delete dis-stripe | Delete a volume |
Note: when deleting a volume, you need to stop the volume first, and no host in the trust pool is down, otherwise the deletion will not succeed
| gluster volume set dis-rep auth.allow + IP | Set access control for volume deny only |
|---|---|
| gluster volume set dis-rep auth.allow + IP | Only allowed |
Vi GFS deployment
| Node name | IP address |
|---|---|
| Node 1 | 192.168.10.129 |
| Node2 | 192.168.10.134 |
| Node3 | 192.168.10.130 |
| Node4 | 192.168.10.142 |
| Client | 192.168.10.1 |
Turn off the firewall:
systemctl stop firewalld setenforce 0
1. Partition and mount the disk on the node
Node1 node: 192.168 ten point one two nine
Node2 node: 192.168 ten point one three four
Node3 node: 192.168 ten point one three zero
Node4 node: 192.168 ten point one four two
vim fdisk.sh
#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
do
echo -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/null
mkfs.xfs /dev/${VAR}"1" &> /dev/null
mkdir -p /data/${VAR}"1" &> /dev/null
echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
chmod +x fdisk.sh
./fdisk.sh
Get
#!/bin/bash
echo "the disks exist list:"
##grep out the disk of the system
fdisk -l |grep 'disk /dev/sd[a-z]'
echo "=================================================="
PS3="chose which disk you want to create:"
##Select the disk number you want to create
select VAR in `ls /dev/sd*|grep -o 'sd[b-z]'|uniq` quit
do
case $VAR in
sda)
##The local disk exits the case statement
fdisk -l /dev/sda
break ;;
sd[b-z])
#create partitions
echo "n ##create disk
p
w" | fdisk /dev/$VAR
#make filesystem
##format
mkfs.xfs -i size=512 /dev/${VAR}"1" &> /dev/null
#mount the system
mkdir -p /data/${VAR}"1" &> /dev/null
###Permanent mount
echo -e "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0\n" >> /etc/fstab
###Make mount effective
mount -a &> /dev/null
break ;;
quit)
break;;
*)
echo "wrong disk,please check again";;
esac
done

2. Modify the host name and configure the / etc/hosts file
#Take Node1 node as an example:
hostnamectl set-hostname node1 su echo "192.168.10.129 node1" >> /etc/hosts echo "192.168.10.134 node2" >> /etc/hosts echo "192.168.10.130 node3" >> /etc/hosts echo "192.168.10.142 node4" >> /etc/hosts echo "192.168.10.1 client" >> /etc/hosts
-----Install and start GlusterFS (operate on all node nodes)-----
#Upload the gfsrepo software to the / opt directory
#Upload gfsrepo Zip to / opt extract
unzip gfsrepo.zip
cd /etc/yum.repos.d/ mkdir repo.bak mv *.repo repo.bak
Open profile
vim /etc/yum.repos.d/glfs.repo
[glfs] name=glfs baseurl=file:///opt/gfsrepo gpgcheck=0 enabled=1
yum clean all && yum makecache
install
#yum -y install centos-release-gluster #If the official YUM source is used for installation, it can directly point to the Internet warehouse yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
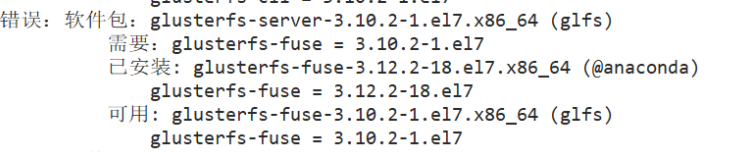
Solution: uninstall the higher version and reinstall it
rpm -e --nodeps glusterfs-api rpm -e --nodeps glusterfs-libs rpm -e --nodeps glusterfs-fuse rpm -e --nodeps glusterfs-cli yum -y install glusterfs-client-xlators.x86_64 yum -y install glusterfs-api.x86_64 yum install -y glusterfs-cli If the version of other software packages is too high, uninstall them directly and reinstall them
start-up
systemctl start glusterd.service Open service systemctl enable glusterd.service Startup and self startup service systemctl status glusterd.service View status
Time synchronization
ntpdate ntp1.aliyun.com
-----Add node to storage trust pool (operate on node1 node)-----
#Just add other nodes on one Node
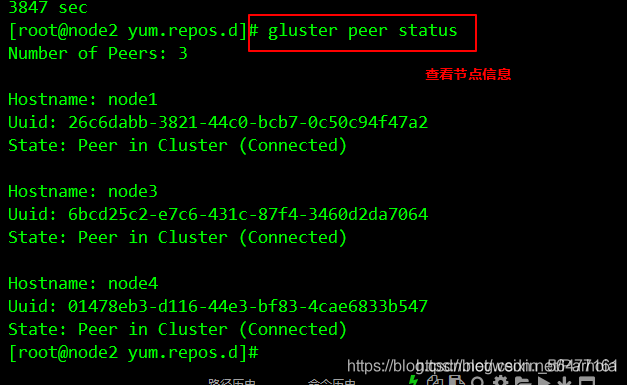
gluster peer probe node1 gluster peer probe node2 gluster peer probe node3 gluster peer probe node4
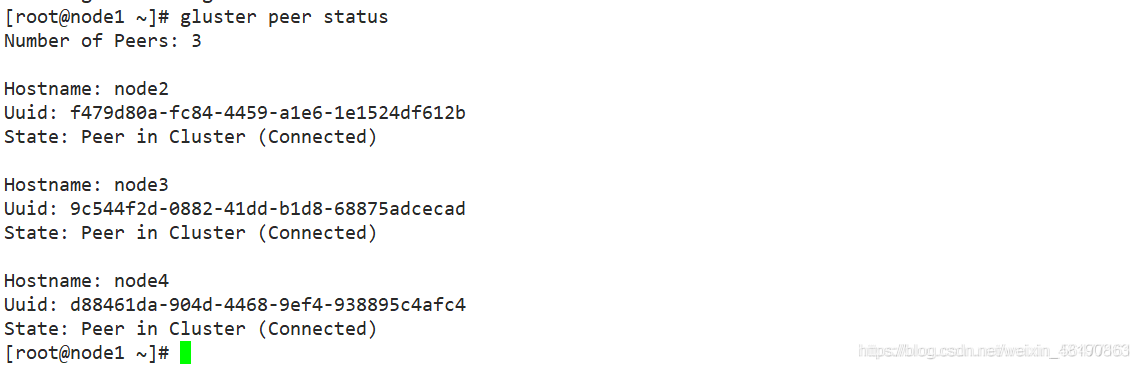
View cluster status on each Node
gluster peer status
1. Create distributed volumes
#Create a distributed volume without specifying the type. The default is to create a distributed volume
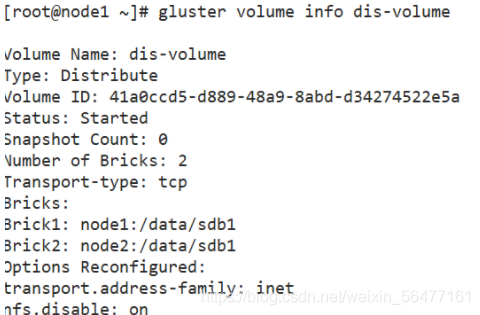
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force
#View volume list
gluster volume list
#Start new distributed volume
gluster volume start dis-volume
#Viewing information about creating distributed volumes
gluster volume info dis-volume
2. Create a striped volume
#The specified type is stripe, the value is 2, and followed by 2 brick servers, so a striped volume is created
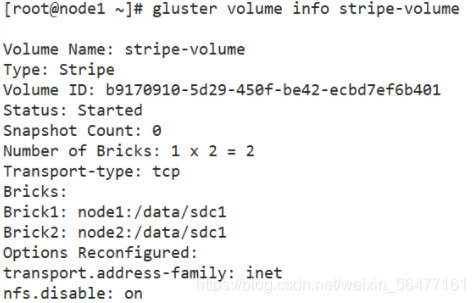
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force gluster volume start stripe-volume gluster volume info stripe-volume
3. Create replication volume
#The specified type is replica, the value is 2, and followed by 2 brick servers, so a replication volume is created
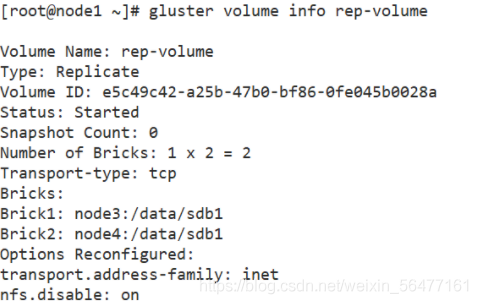
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force gluster volume start rep-volume gluster volume info rep-volume
4. Create distributed striped volumes
#The specified type is stripe, the value is 2, and followed by four brick servers, twice as much as 2, so a distributed striped volume is created
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force gluster volume start dis-stripe gluster volume info dis-stripe
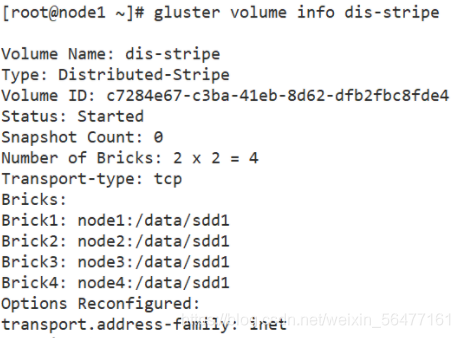
5. Create distributed replication volumes
The specified type is replica, and the value is 2, followed by four brick servers, which is twice as much as 2. Therefore, a distributed replication volume is created
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force gluster volume start dis-rep gluster volume info dis-rep gluster volume list
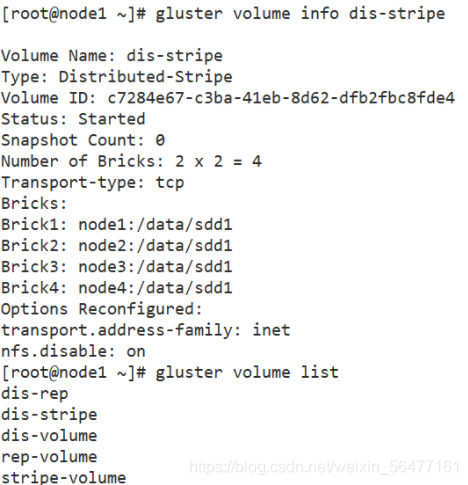
----Deploy Gluster client-----
1. Install client software
#Upload gfsrepo software to / opt
cd /etc/yum.repos.d/ mkdir repo.bak mv *.repo repo.bak
vim glfs.repo [glfs] name=glfs baseurl=file:///opt/gfsrepo gpgcheck=0 enabled=1
yum clean all && yum makecache yum -y install glusterfs glusterfs-fuse
2. Create a mount directory
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test
3. Configure the / etc/hosts file
echo "192.168.10.129 node1" >> /etc/hosts echo "192.168.10.134 node2" >> /etc/hosts echo "192.168.10.130 node3" >> /etc/hosts echo "192.168.10.142 node4" >> /etc/hosts echo "192.168.10.1 client" >> /etc/hosts
4. Mount the Gluster file system
#Temporary mount
mount.glusterfs node1:dis-volume /test/dis mount.glusterfs node1:stripe-volume /test/stripe mount.glusterfs node1:rep-volume /test/rep mount.glusterfs node1:dis-stripe /test/dis_stripe mount.glusterfs node1:dis-rep /test/dis_rep df -Th
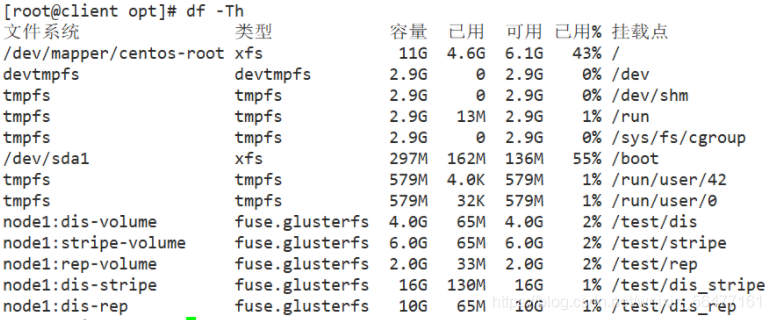
-----Testing the Gluster file system-----
1. Write files to the volume, and the client operates
cd /opt dd if=/dev/zero of=/opt/demo1.log bs=1M count=20 dd if=/dev/zero of=/opt/demo2.log bs=1M count=20 dd if=/dev/zero of=/opt/demo3.log bs=1M count=20 dd if=/dev/zero of=/opt/demo4.log bs=1M count=20 dd if=/dev/zero of=/opt/demo5.log bs=1M count=20
cp demo* /test/dis cp demo* /test/stripe/ cp demo* /test/rep/ cp demo* /test/dis_stripe/ cp demo* /test/dis_rep/
2. View file distribution
#View distributed file distribution
[root@node1 ~]# ls -lh /data/sdb1 #The data is not fragmented [root@node2 ~]# ll -h /data/sdb1
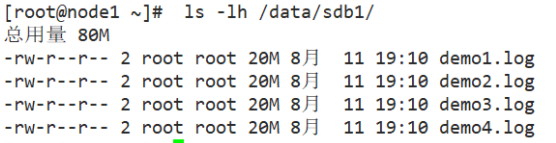

#View striped volume file distribution
[root@node1 ~]# ls -lh /data/sdc1 #The data is fragmented, 50% without replica and redundancy
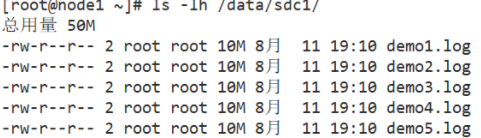
root@node2 ~]# ll -h /data/sdc1 #The data is fragmented, 50% without replica and redundancy
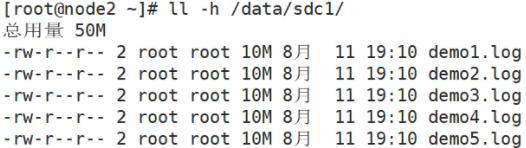
#View replication volume distribution
[root@node3 ~]# ll -h /data/sdb1 #The data is not fragmented, there are copies, and there is redundancy
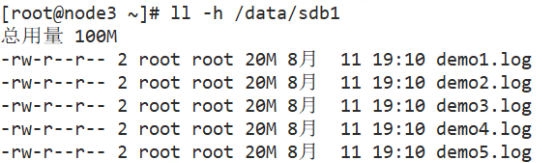
[root@node3 ~]# ll -h /data/sdd1

root@node4 ~]# ll -h /data/sdd1

root@node4 ~]# ll -h /data/sdd1

#View distributed replication volume distribution
#The data is not fragmented, there are copies, and there is redundancy
[root@node1 ~]# ll -h /data/sde1
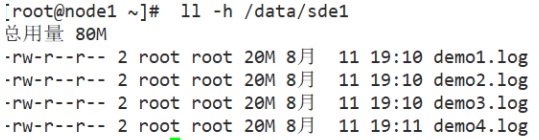
[root@node2 ~]# ll -h /data/sde1
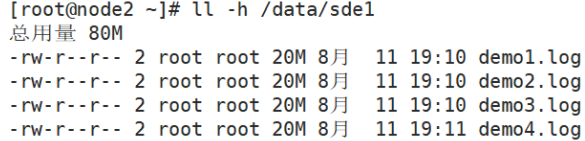
[root@node3 ~]# ll -h /data/sde1

[root@node4 ~]# ll -h /data/sde1

----Destructive test-----
#Suspend the node2 node or shut down the glusterd service to simulate a failure
[root@node2 ~]# systemctl stop glusterd.service
#Check whether the file is normal on the client
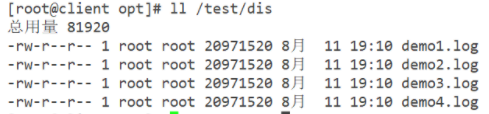
#Distributed volume data viewing
[root@localhost dis]# ll #Found demo5 missing on the customer Log file, which is on node2
#Strip roll
[root@localhost text]# cd stripe/ #Unreachable, striped volumes are not redundant [root@localhost stripe]# ll

#Distributed striped volume
[root@localhost dis_and_stripe]# ll #Inaccessible, distributed striped volumes are not redundant

#Distributed replication volume
[root@localhost dis_and_rep]# ll #Yes, distributed replication volumes are redundant

If node2 is repaired, join the cluster and the data is normal
#Suspend node2 and node4 nodes and check whether the files are normal on the client
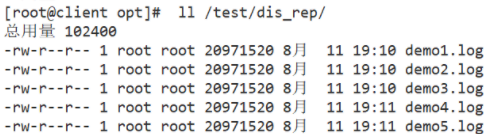
#Test whether the replicated volume is normal
[root@localhost rep]# ls -l #Test the normal data on the client
Test whether the distributed stripe volume is normal
[root@localhost dis_stripe]# ll #The test on the client is normal and there is no data

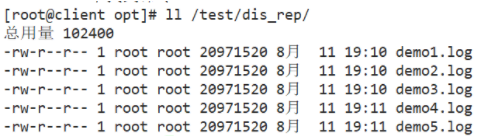
#Test whether the distributed replication volume is normal
[root@localhost dis_and_rep]# ll #Test whether there is normal data on the client
#Other maintenance commands:
1. View GlusterFS volumes
gluster volume list
2. View the information of all volumes
gluster volume info
3. View the status of all volumes
gluster volume status
4. Stop a volume
gluster volume stop dis-stripe
5. Delete a volume. Note: when deleting a volume, you need to stop the volume first, and no host in the trust pool is down, otherwise the deletion will not succeed
gluster volume delete dis-stripe
6. Set the access control of the volume
#Reject only
gluster volume set dis-rep auth.deny 192.168.10.100
#Only allowed
gluster volume set dis-rep auth.allow 192.168.10. * # setting 192.168 All IP addresses of the 10.0 network segment can access the dis rep volume (distributed replication volume)