
Go language principle
Basics
self-taught
Error
Error vs Exception
Error Type
Sentinel Error predefined error value
Sentinel errors Be you API Public part. Sentinel errors A dependency is created between the two packages. conclusion: Avoid as much as possible sentinel errors.
Error types
type MyError struct {
Msg string
File string
Line int
}
func (e *MyError) Error() string {
return fmt.Sprintf("%s:%d: %s", e.File, e.Line, e.Msg)
}
func test() error {
return &MyError{"Something happened", "server.go", 42}
}
func main() {
err := test()
switch err := err.(type) {
case nil:
// nothing
case *MyError:
fmt.Println("error occurred on line:", err.Line)
default:
// unknown
}
}
The caller uses type assertions and types switch,Let the custom error Become public. This model will lead to strong coupling with the caller, resulting in API Become vulnerable.
The conclusion is to avoid it as much as possible error types,Although the error type ratio sentinel errors Better, because they can capture more context about the error, but error types share error values Many of the same problems.
Therefore, my advice is to avoid wrong types, or at least avoid them as public API Part of.Opaque errors opaque error handling
inport "github.com/quux/bar"
func fn error {
x, err := bar.Foo()
if err != nil {
return err
}
}Handing Error
Indented flow is for errors normal process code without errors will become a straight line rather than a compressed code
f, err := os.Open(path)
if err != nil {
// handle error
}
// do stuffEliminate error handling by eliminating errors
What's wrong with the following code?
// Meaningless judgment
func AuthenticateRequest(r *Request) error {
err := authenticate(r.User)
if err != nil {
return err
}
return nil
}
func AuthenticateRequest(r *Request) error {
return authenticate(r.User)
}Statistics io Number of rows read by reader
func CountLines(r io.Reader) (int, error) {
var (
br = bufio.MewReader(r)
lines int
err error
)
for {
_, err = br.ReadString('\n')
lines++
if err != nil {
break
}
}
if err != io.EOF {
return 0, err
}
return lines, nil
}
Improved version
func CountLines(r io.Reader) (int, error) {
sc := bufio.NewScanner(r)
lines := 0
for sc.Scan() {
lines++
}
return lines, sc.Err()
}//
type Header struct {
Key, Value string
}
type Status struct {
Code int
Reason string
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.reader) error {
_, err := fmt.Fprintf(w, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
if err != nil {
return err
}
for _, h := range headers {
_, err := fmt.Fprintf(w, "%s: %s\r\n", h.Key, h.Value)
if err != nil {
return err
}
}
if _, err := fmt.Fprint(w, "\r\n"); err != nil {
return err
}
_, err = io.Copy(w, body)
return err
}
// Improved version
type errWriter struct {
io.Writer
err error
}
func (e *errWriter) Write(buf []byte) (int, error) {
if e.err != nil {
return 0, e.err
}
var n int
n, e.err = e.Writer.Write(buf)
return n, nil
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.reader) error {
ew := &errWriter{Writer: w}
fmt.Fprintf(ew, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
for _, h := range headers {
fmt.Fprintf(ew, "%s: %s\r\n", h.Key, h.Value)
}
fmt.Fprint(ew, "\r\n")
io.Copy(ew, body)
return ew.err
}Wrap errors
Go 1.13 errors
%+v ,%w
Go 2 Error Inspection
Time node
error (II)
02:30 Q & A
02:48 example
Concurrency
Goroutine
Memory model
Package sync
chan
Package context
// 3.5.go
import {
"context"
"fmt"
"time"
}
func main() {
tr := NewTracker()
go tr.Run()
_ = tr.Event(context.Background(), "test")
_ = tr.Event(context.Background(), "test")
_ = tr.Event(context.Background(), "test")
ctx, cancel := context.WithDeadline(context.Background(), time.Now().Add(2 * time.Second))
defer ctx.cancel()
tr.Shutdown(ctx)
}
type Tracker struct {
ch chan string
stop chan struct{}
}
func (t *Tracker) Event(ctx context.Context, data string) error {
select {
case t.ch <- data:
return nil
case <-ctx.Done():
return ctx.Err()
}
}
func (t *Tracker) Run() {
for data := range t.ch {
time.Sleep(1 * time.Second)
fmt.Println(data)
}
t.stop <- struct{}{}
}
func (t *Tracker) Shutdown(ctx context.Context) {
close(t.ch)
select {
case <-t.stop
case <-ctx.Done()
}
}www.jianshu.com/p/5e44168f47a3
Network programming
head of line blocking goim + bullet chat 01:03 Persistent scenarios Single queue CPU equilibrium Size end Sticky bag
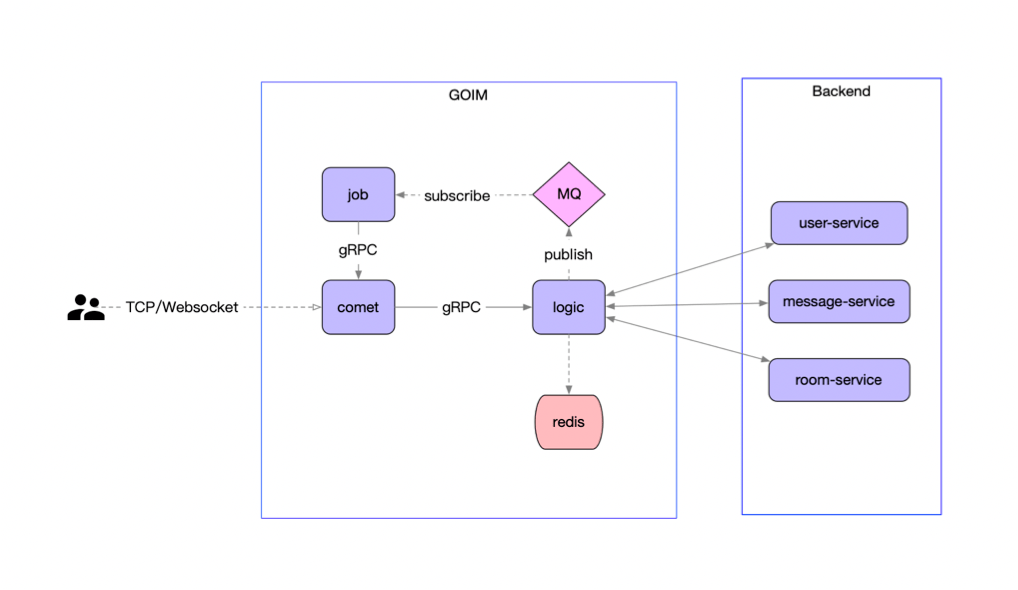
Goim
Goim overview
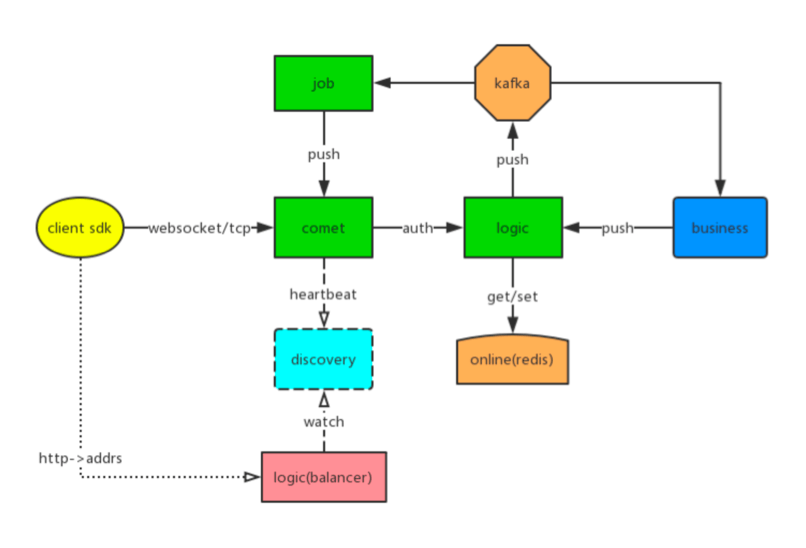
Edge node
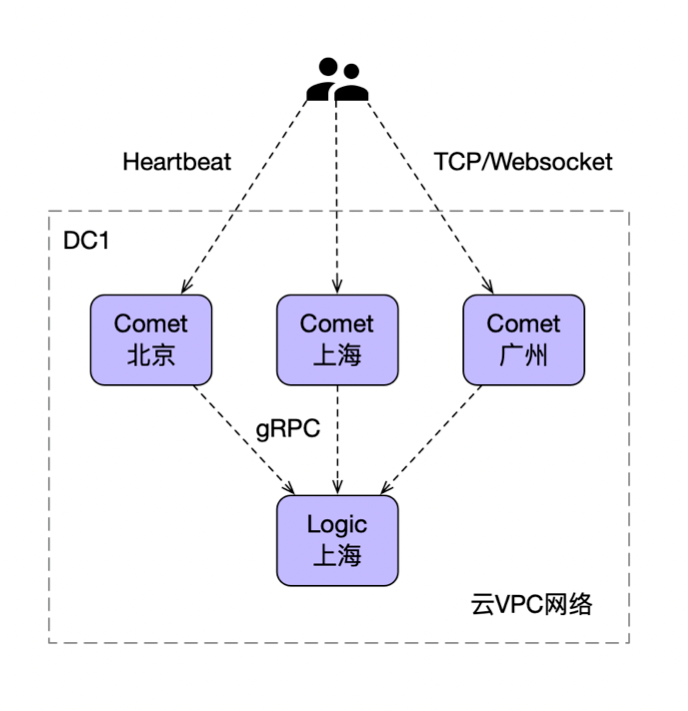
load balancing
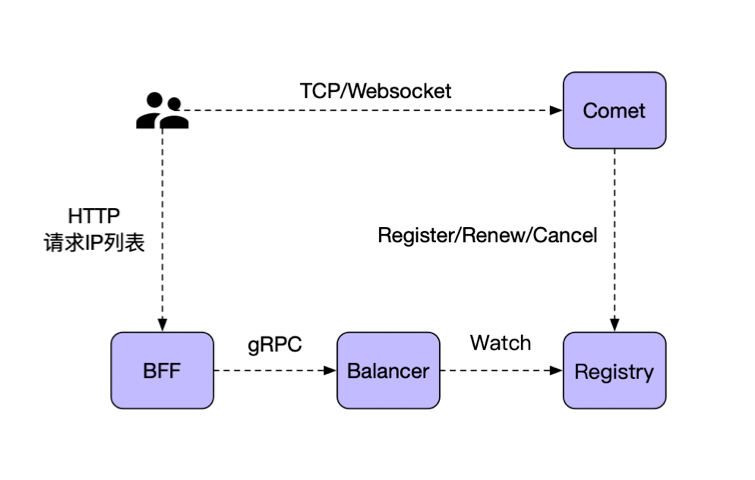
Keep heartbeat alive
Process keeping alive Keep heartbeat alive Disconnection reconnection
User authentication and Session information
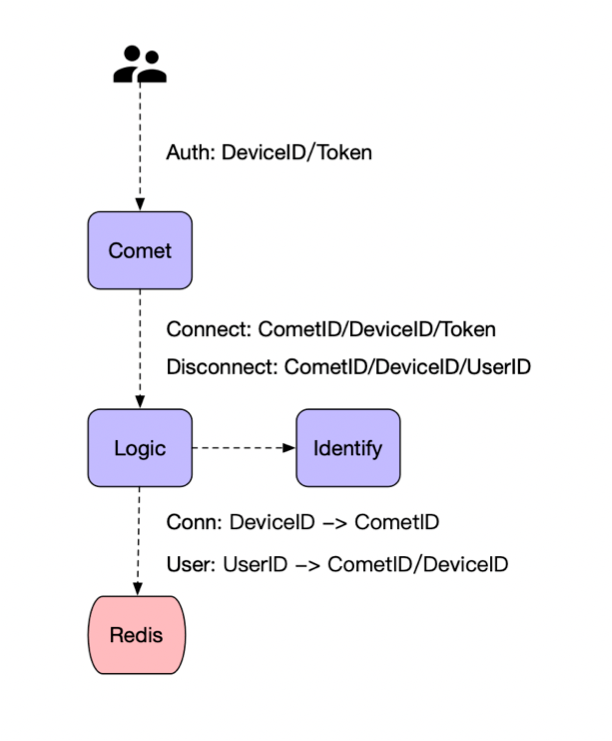
Comet
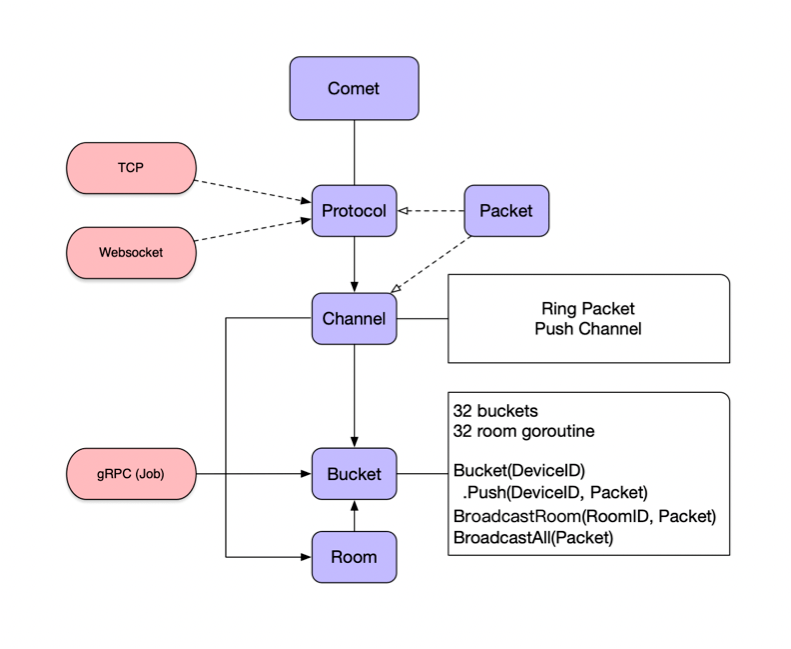
each Bucket Have independent Goroutine Read / write lock Optimization:
Buckets {
channels map[string]*Channel
rooms map[string]*Room
}Logic
Job
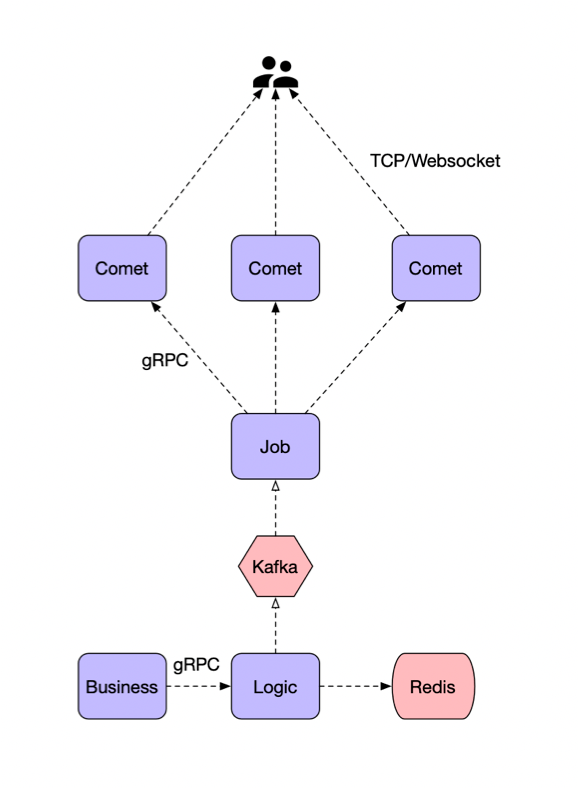
Push pull combination
Push mode: when there is a new message, the server actively pushes it to the client; Pull mode: the front end actively initiates the request to pull messages; Push pull combination mode, real-time notification of new messages, and the client extracts new messages;
Read write diffusion
Read diffusion, in IM Reading diffusion in the system usually means that every two associated people have a mailbox, or every group has a mailbox. Advantages: write operation (send message) is very light, only write your own mailbox Disadvantages: the read operation (message reading) is very heavy, and everyone's mailbox needs to be read Write diffusion, everyone only reads messages from their own mailbox, but everyone needs to write a copy when writing (sending messages) Advantages: light reading operation Disadvantages: write operation is very heavy, especially for group chat
Unique ID design
UUID be based on Snowflake of ID Generation mode Based on Application DB Generation method of step size be based on Redis perhaps DB Self increment of ID Generation mode Special rules generate unique ID
IM private message system
Barrage system
Database design
1. Separate instance of important business, separate database Separate the barrage database instance from other service instances; Internal services separate important and non important businesses 2. Separate index and content Put the frequently changed data into the index table, such as status, attribute and barrage pool; Put the static data into the content table, Such as bullet screen content, mode, font size and color; 3. Reduce the amount of data in a single table by dividing tables Change the table splitting strategy to follow cid The sub table, index table and content table are divided into 1000 tables respectively, from the original single table of 7000 w Up to 300 w 4. The contents of special barrage shall be stored in a separate table 5. Ensure as few candidate sets as possible through the top queue
Top queue design
Given that the candidate set of a single video barrage exceeds 200 w In this case, we implement a redis Top the queue to ensure that the candidate set is as small as possible,
redis sortset The implementation is as follows:
key : Ordinary barrage, protective barrage, subtitle barrage, special barrage, recommended barrage
field: fmt.Sprintf("%d.%d", Barrage attribute, bullet chat id)
member: bullet chat id
After each addition, the current queue length will be returned, which will exceed maxlimit The status of the barrage changed from normal to hidden
Every time you delete a bullet screen, you will get a bullet screen that has been hidden recently from the database, and change it from hidden to normal
Intelligent barrage
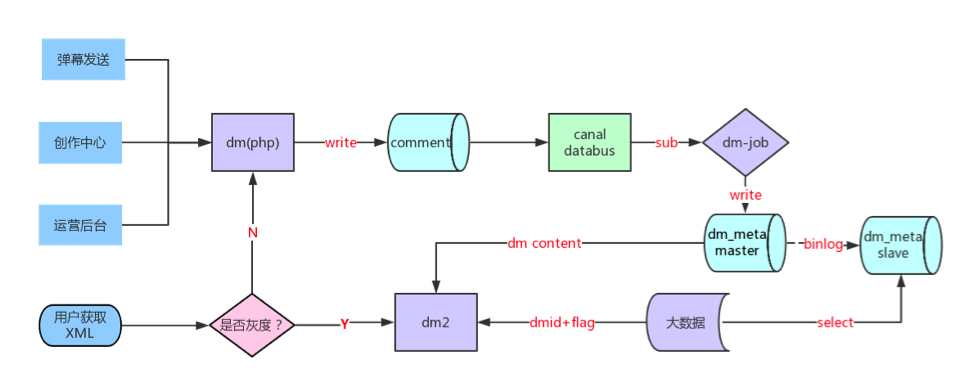
Smart barrage cache (old)
L1 cache redis,structure sortset key: Common barrage: i_type_oid_cnt_n Special barrage: s_type_oid Top barrage queue: q_oid score: bullet chat id member: bullet chat id L2 cache mc,structure k-v key: bullet chat id value: Single article xml
Smart barrage cache (New)
L1 cache mc Save barrage for each video segment The length of time each video is cached L2 cache redis,structure sortset key: Common barrage: i_type_oid_cnt_n Special barrage: s_type_oid Top barrage queue: q_oid score: bullet chat id member: bullet chat id L2 cache redis,structure hashset key: c_oid field: bullet chat id value: Single article xml
memcache concurrency
At present, this method is relatively low, and will be changed to single flight in the future;
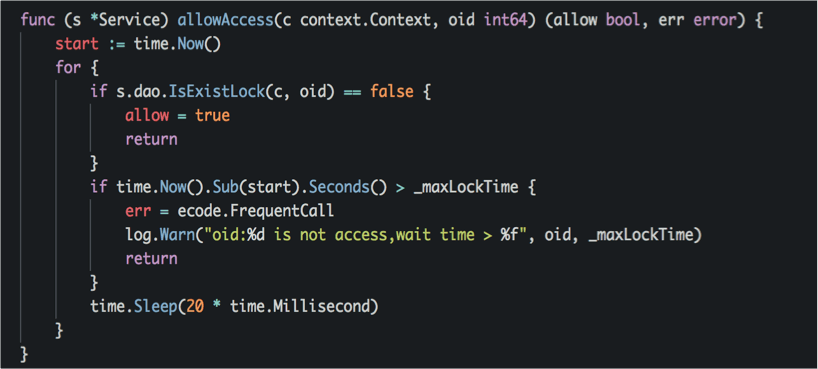
single flight concurrent lock
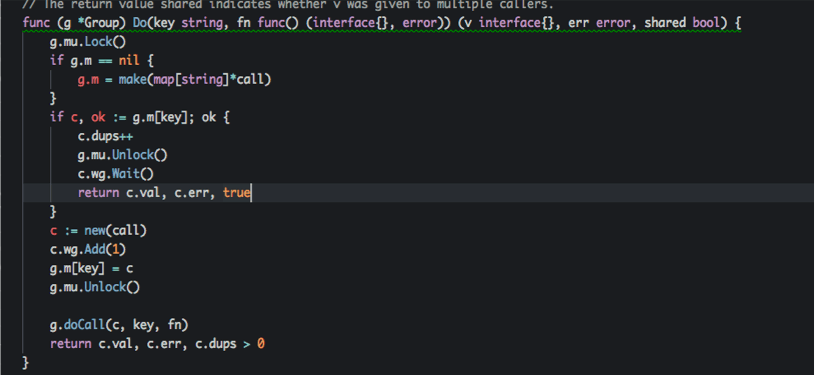
####
01:01 For live barrage goim realization The barrage is very similar to the comment For fighting fish wesocket goim In memory and gc A lot of optimization has been done
runtime
Goroutine principle
Goroutine Difference between and thread
GMP scheduling model
G goroutine M thread P Queue, and m binding M When to create? go func
Work stepping scheduling algorithm
Avoid hunger overall situation->local->Try to steal->overall situation->Go fishing on the Internet
Syscall
Sysmon
Network poller
Trigger timing sysmon schedule start the world
Memory allocation principle
Mcache - > mccentral - > mheap - > system memory (terminal)
Principle of garbage collection (GC)
Vernacular Go language memory management Trilogy (III) garbage collection principle
What every programmer should know about memory, Part 1
Architecture
Engineering practice
layout
v1 github.com/bilibili/kratos-demo
model <- dao <- service <- server
In our old layout, there are api, cmd, configs and internal directories under the app directory, and README, CHANGELOG and OWNERS are generally placed in the directory.
- API: place the API definition (protobuf) and the corresponding generated client code, based on the swagger generated by pb json.
- configs: put the configuration files required by the service, such as database yaml,redis.yaml,application.yaml.
- Internal: it is to avoid someone in the same business referencing internal struct s such as internal model and dao across directories.
- server: place the routing code of HTTP/gRPC and the code of DTO conversion.
DTO(Data Transfer Object): data transfer object. This concept comes from the design pattern of J2EE. But here, it generally refers to the data transmission object between the presentation layer / API layer and the service layer (business logic layer).
The dependency path of the project is: Model - > Dao - > Service - > api. model struct connects all layers in series until the api needs DTO object conversion.
- model: put the structure corresponding to the "storage layer", which is a one-to-one implicit reflection of storage.
- dao: data read-write layer, database and cache are all handled in this layer, including cache miss processing.
- service: combine various data accesses to build business logic.
- server: depending on the service defined by proto as the input parameter, it provides a fast global method to start the service.
- api: defines the API proto file and the generated stub code. The interface generated by it is implemented in the service.
- Because the method signature of service implements the interface definition of API, DTO is directly used in the business logic layer, and dao is directly used to simplify the code.
DO(Domain Object): domain object is a tangible or intangible business entity abstracted from the real world. Lack of dto - > do object conversion.
v2 github.com/go-kratos/kratos-layout
There are api, cmd, configs and internal directories under the app directory. README, CHANGELOG and OWNERS are generally placed in the directory.
- Internal: it is to avoid someone in the same business referencing internal struct s such as biz, data and service across directories.
- biz: the assembly layer of business logic, the domain layer similar to DDD, and the repo interface of data similar to DDD. The repo interface is defined here and uses the principle of dependency inversion.
- Data: business data access, including cache, db and other packages, and implements the repo interface of biz. We may confuse data with dao. Data focuses on the meaning of business. What it needs to do is to take out the domain objects again. We have removed the infra layer of DDD.
- Service: it implements the service layer defined by api, which is similar to the application layer of DDD. It handles the transformation from DTO to biz domain entities (DTO - > do), and cooperates with various biz interactions, but it should not deal with complex logic.
PO(Persistent Object): a persistent object that forms a one-to-one mapping relationship with the data structure of the persistence layer (usually a relational database). If the persistence layer is a relational database, each field (or several fields) in the data table corresponds to one (or several) attributes of the PO. github.com/facebook/ent
start-up
github.com/go-kratos/kratos/blob/m...
Part II
00:41 Case
00:56 Error Case
service error -> gRpc error -> service error
01:24 example demo/v1/greeter_grpc.pb.go
01:33 the interface only updates some fields, and the fieldMask identification field needs to be updated
01:35 Google Design Guide cloud.google.com/apis/design?hl=zh...
01:50 Redis Config Case
// Final edition
func main() {
// load config file from yaml.
c := new(redis.Config)
_ = ApplyYAML(c, loadConfig())
r, _ := redis.Dial(c.Network, c.Address, Options(c)...)
}02:30 about testing
Basic requirements for unit test:
- fast
- Consistent environment
- Arbitrary order
- parallel
Implement a container dependency management scheme based on docker compose for cross platform and cross language environment to solve the problem of (mysql, redis, mc) container dependency in the scenario of running unittest:
- Install Docker locally.
- No intrusive environment initialization.
- Quickly reset the environment.
- Run anytime, anywhere (independent of external services).
- Semantic API declaration resources.
- Real external dependencies, not in-process simulations.
- Correctly perform health detection on the services in the container to avoid that the resources are not ready when unittest is started.
- The app should initialize the data itself, such as db scheme and initial sql data. In order to meet the consistency of the test, the container will be destroyed after each test.
- Before unit testing, import the encapsulated testing library to facilitate the startup and destruction of containers.
- For the unit test of service, use gomock and other libraries to remove dao mock, so when designing the package, it should be oriented to abstract programming.
- When executing Docker locally and Unittest in CI environment, you need to consider the Docker network in the physical machine or start a Docker again in Docker
Use the subtests + gomock officially provided by go to complete the whole unit test.
- /api
It is more suitable for integration testing, directly testing API, using API testing framework (such as yapi) and maintaining a large number of business test case s. - /data
docker compose simulates the underlying infrastructure, so the abstraction layer of infra can be removed. - /biz
Rely on repo and rpc client, and use gomock to simulate the implementation of interface to conduct business unit test. - /service
Depending on the implementation of Biz, the implementation class of biz is constructed and passed in for unit testing.
Carry out feature development based on git branch, carry out unittest locally, submit gitlab merge request for CI unit test, build based on feature branch, complete function test, then merge master for integration test, and carry out regression test after going online.
Microservice availability design
quarantine
Service isolation
- Dynamic and static isolation, read-write isolation
Light and heavy isolation
- Core, speed and hotspot
Physical isolation
- Thread, process, cluster, computer room
Timeout control
code: 504
. . .
01:22 head of line blocking
VDSO: blog.csdn.net/juana1/article/detai...
overload protection
code: 429
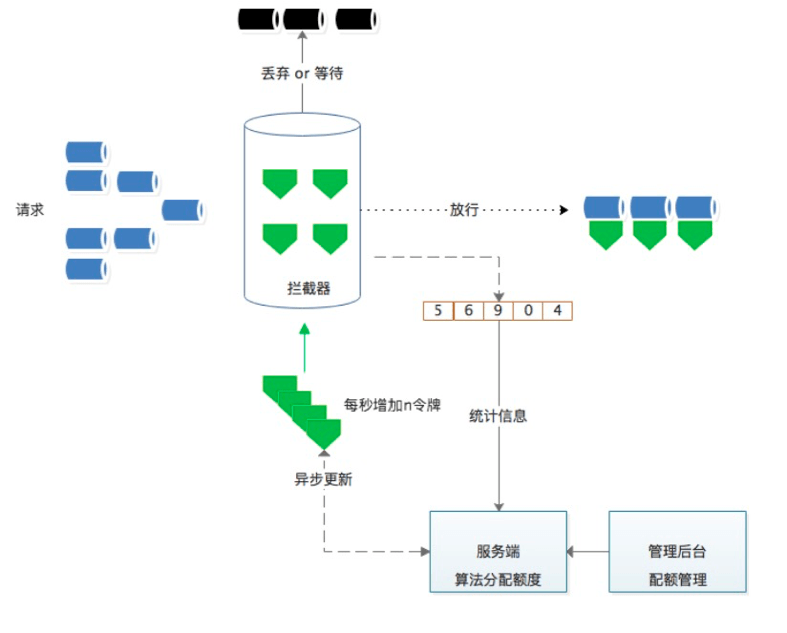
token-bucket rate limit algorithm: /x/time/rate
leaky-bucket rate limit algorithm: /go.uber.org/ratelimit
The cost of human operation and maintenance is too high. Adaptive algorithms are needed.
The peak throughput of the system near overload is calculated as the current limiting threshold for flow control to achieve system protection.
When the server approaches overload, it actively discards a certain amount of load, with the goal of self-protection.
Maintain the throughput of the system on the premise of system stability.
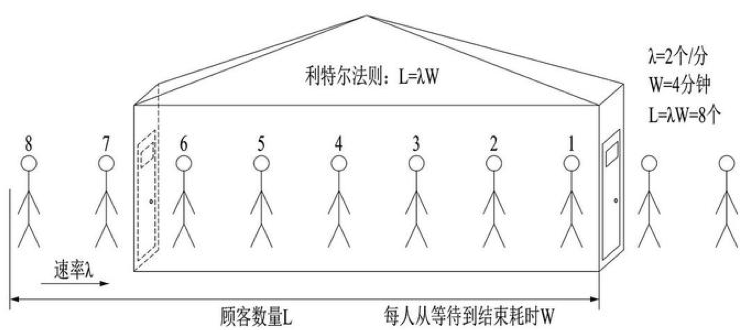
Common practice: Little's law
CPU and memory are throttled as semaphores.
Queue management: queue length, LIFO.
Controllable delay algorithm: CoDel. codel+bbr
How to calculate the system throughput near the peak? CPU: Use a separate thread sampling every 250 ms Trigger once. When calculating the mean value, a simple moving average is used to remove the influence of the peak value. Inflight: The number of requests in progress in the current service. Pass&RT: Last 5 s,pass For every 100 ms Number of successful requests in the sampling window, rt Is the average response time in a single sampling window [Cooling thought] We use CPU Sliding mean of(CPU > 800(80%))As the heuristic threshold, once the trigger enters the overload protection stage, the algorithm is:(pass* rt) < inflight After the current limiting effect takes effect, CPU Will be at the critical value(800)Nearby jitter, if the cooling time is not used, then a short time CPU The drop may lead to a large number of requests being released, which will be full in serious cases CPU. After the cooling time, re judge the threshold(CPU > 800),Whether the overload protection is continuously entered.
Overload protection: protect yourself and do every service
Current limiting
Flow limiting refers to the technology that defines how many requests a customer or application can receive or process over a period of time. For example, by limiting traffic, you can filter out customers and microservices that produce peak traffic, or you can ensure that your application will not be overloaded before auto scaling fails.
- Token bucket and leaky bucket are for a single node and cannot be distributed to limit current.
- QPS current limiting
- Different requests may require a very different number of resources to process.
- Some static QPS current limiting is not particularly accurate.
- Set limits for each user
- When the global overload occurs, some "exceptions" shall be controlled.
- A certain degree of "oversold" quota.
- Discard according to priority.
- Rejecting requests also costs.
Distributed current limiting
Distributed current limiting is to control the global traffic of an application, rather than the latitude of a single node.
- For a single high traffic interface, it is easy to generate hot spots using redis.
- The pre request mode has a certain impact on the performance. High frequency network round-trip.
reflection:
Upgrade from getting a single quota to a batch quota. Quota: indicates the rate. After obtaining, the token bucket algorithm is used to limit it.
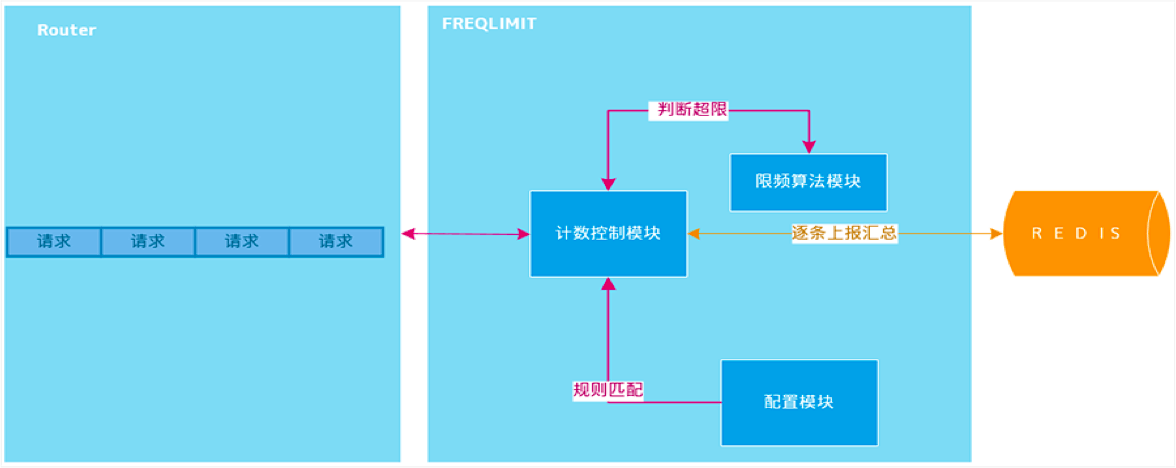
- After each heartbeat, asynchronous batch acquisition of quota can greatly reduce the frequency of requesting redis. After acquisition, local consumption can be intercepted based on token bucket.
- The quota applied for each time needs to be manually set, and the static value is slightly inflexible, such as 20 or 50 each time.
How to apply on demand based on a single node and avoid unfairness?
The default value is used for the first time. Once there is data in the past history window, you can make a quota request based on the history window data.
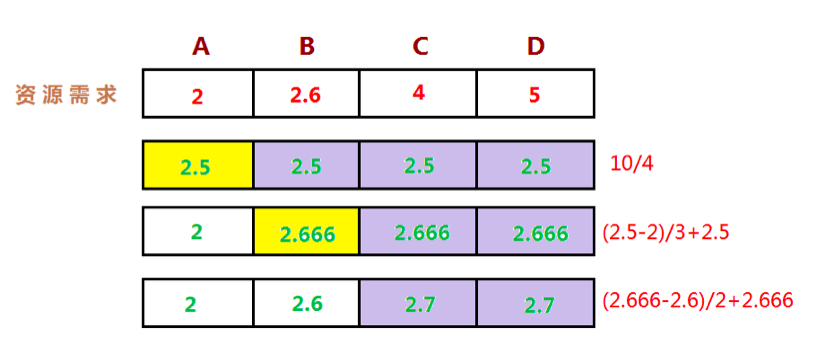
reflection:
We are often faced with the problem of dividing a group of users into rare resources. They all have equal rights to obtain resources, but some of them actually need less resources than other users.
So how do we allocate resources? A sharing technology widely used in practice is called "maximum minimum fair sharing"( Max-Min Fairness).
Intuitively, the minimum demand that each user wants to meet is fairly shared, and then the unused resources are evenly distributed to users who need 'big resources'.
The formal definition of the maximum minimum fair allocation algorithm is as follows: Resources are allocated in the order of increasing demand. There are no users who get more resources than they need. Unsatisfied users share resources equivalently.

importance
Each interface is configured with a threshold, and the operation is heavy. The simplest way is to configure the service level quota. More finely, we can set the quota according to different importance. We introduce criticality:
- Most important CRITICAL_PLUS, the type reserved for the final request. Rejecting these requests will cause very serious user visible problems.
- CRITICAL, the default request type issued by the mo. Rejecting these requests can also cause user visibility problems. But it may not be that serious.
- Discardable SHEDDABLE_PLUS these flows can tolerate some degree of unavailability. This is the default value for requests from batch tasks. These requests can usually be retried in a few minutes.
- Discardable SHEDDABLE these traffic may often encounter partial unavailability and occasionally completely unavailability.
Between gRPC systems, importance information needs to be transferred automatically. If the back end receives request A and sends requests B and C to other back ends during processing, requests B and C will use the same importance attribute as A.
- When the global quota is insufficient, the low priority will be rejected first.
- Global quotas can be set according to their importance.
- During overload protection, low priority requests are rejected first.
Fuse
Circuit breakers: in order to limit the duration of operation, we can use timeout, which can prevent pending operation and ensure that the system can respond. Because we are in a highly dynamic environment, it is almost impossible to determine the exact time limit for normal operation in every case. Circuit breakers are named after real-world electronic components because their behavior is the same. Circuit breakers are very useful in distributed systems because repeated failures may lead to snowball effect and crash the whole system.
- There are a lot of errors in the resources that the service depends on.
- When a user exceeds the resource quota, the back-end task will quickly reject the request and return the error of "insufficient quota", but the rejection reply will still consume some resources. It is possible that the back end is busy sending rejection requests, resulting in overload.
Google SRE
max(0, (requests - K*accepts) / (requests + 1))
github.com/go-kratos/kratos/blob/v...

Gutter Kafka
Client current limiting
github.com/go-kratos/kratos/blob/v...

02:10 DTO Case
02:35 code demonstration: wire dependency injection, elegant database implementation?
Demotion
Provision of damaging services
retry
load balancing
github.com/go-kratos/kratos/blob/v... (key points)
Review architecture design
Playback history architecture
Component part
Distributed cache & distributed transaction
Log & Index & Link Tracking
DNS & CDN & multi active architecture
kafka
Byte hopping MQ hive real-time data integration based on Flink
Kafka basic concept
Storage principle: highly dependent on file system
Ultra high throughput achieved by sequential I/O and Page Cache
Keep all published massage s, regardless of whether they have been consumed or not
Topic & Partition
Offset: the offset of the current Partition
The same Topic has multiple different partitions
A Partition is the same directory
(3497) global messageno + 3rd message
Sparse index, reduce the size of index file and map to memory
.timeindex -> .index -> .log ?
Producer & Consumer
01:40 Producer
Consumer
Byte link scheme?
push vs pull
codel+ bbr
Leader & Follower
Lease system
Uneven Partition distribution (knapsack algorithm) The core is to try to be balanced
Data reliability
HW(high watermark),LEO(log end offset)
performance optimization
MAD algorithm