The first part introduces the coding specifications of some common problems in the development process, and the second part mainly introduces the better writing methods of some common problems, as shown in the figure below.
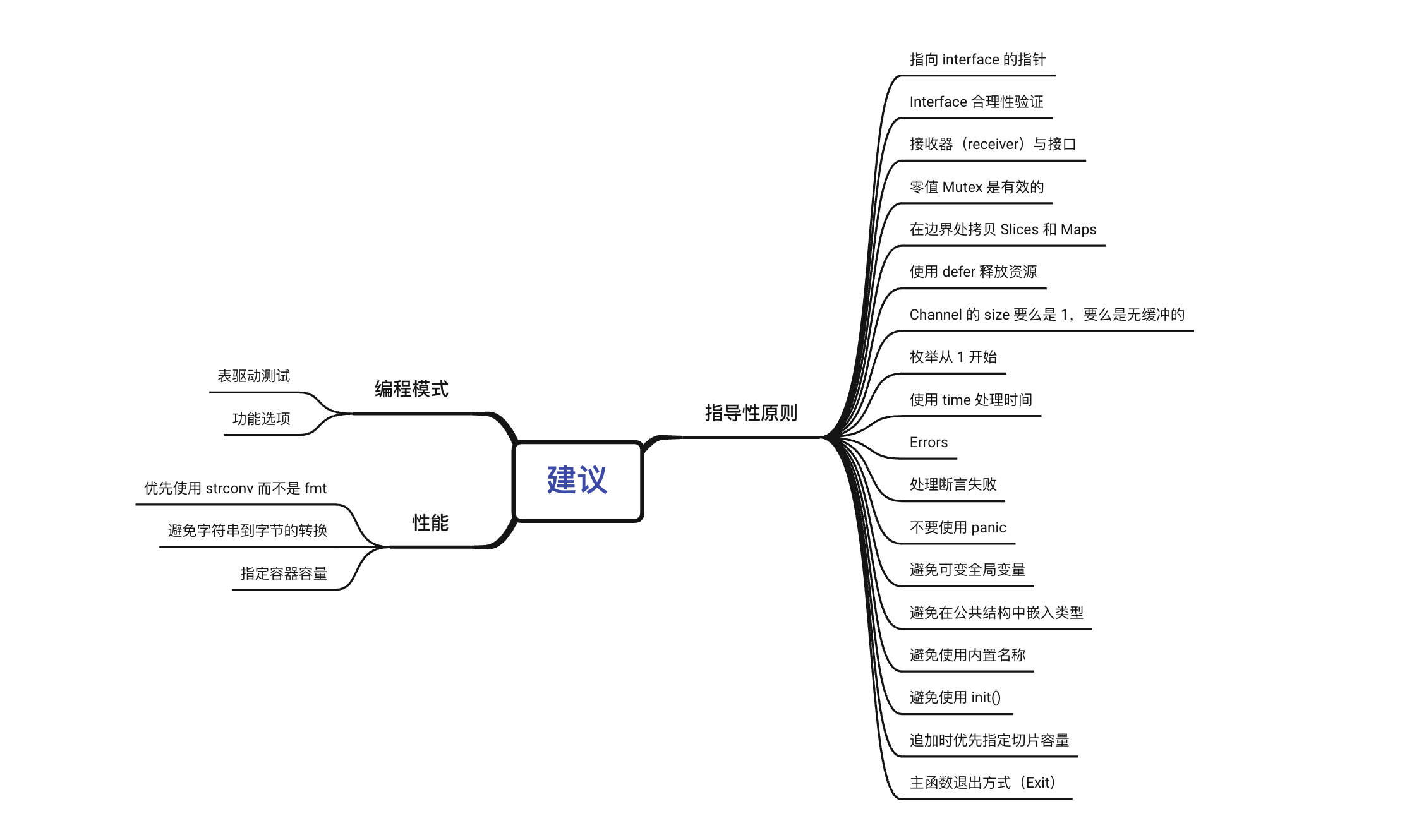
1. Guiding principles
1.1 pointer to interface
There is little need for pointers to interface types. The interface should be passed as a value, in which the underlying data passed can still be pointers.
The interface is essentially represented by two fields:
- A pointer to some specific type of information, which can be regarded as "type"
- Data pointer. If the stored data is a pointer, it is stored directly. If the stored data is a value, a pointer to the value is stored.
If you want an interface method to modify basic data, you must use pointer passing (assigning an object pointer to an interface variable).
type F interface {
f()
}
type S1 struct{}
func (s S1) f() {}
type S2 struct{}
func (s *S2) f() {}
// f1. (f) the underlying data cannot be modified
// f2.f() can modify the underlying data, and the object pointer is used when assigning value to the interface variable F2
var f1 F = S1{}
var f2 F = &S2{}
1.2 interface rationality verification
Verify the compliance of the interface at compile time. This includes:
- The export type that implements a specific interface is checked as part of the interface API
- Types that implement the same interface (export and non export) belong to a collection of implementation types
- Any scenario that violates the interface rationality check will terminate the compilation and notify the user
Note: the above three items are too difficult to understand. In short, using the interface incorrectly will report errors during compilation. Therefore, this mechanism can be used to expose some problems in the compiler.
Bad:
// If the handler does not implement http Handler, an error will be reported when running
type Handler struct {
// ...
}
func (h *Handler) ServeHTTP(
w http.ResponseWriter,
r *http.Request,
) {
...
}
Good:
type Handler struct {
// ...
}
// Rationality checking mechanism for triggering compile time interfaces
// If the handler does not implement http Handler, an error will be reported during compilation
var _ http.Handler = (*Handler)(nil)
func (h *Handler) ServeHTTP(
w http.ResponseWriter,
r *http.Request,
) {
// ...
}
Note: if * handler and HTTP If the interface of the handler does not match, the statement var_ http.Handler = (* handler) (NIL) will not compile.
The right side of the assignment should be the zero value of the assertion type. For pointer types (such as * Handler), slice and map, this is nil; For structure types, this is an empty structure.
type LogHandler struct {
h http.Handler
log *zap.Logger
}
var _ http.Handler = LogHandler{}
func (h LogHandler) ServeHTTP(
w http.ResponseWriter,
r *http.Request,
) {
// ...
}
1.3 receiver and interface
Methods that use a value sink can be called either by value or by pointer. Methods with pointer receivers can only pass through pointers or addressable values Call.
example 🌰
type S struct {
data string
}
func (s S) Read() string {
return s.data
}
func (s *S) Write(str string) {
s.data = str
}
sVals := map[int]S{1: {"A"}}
// You can only call Read by value
sVals[1].Read()
// This does not compile through:
// sVals[1].Write("test")
sPtrs := map[int]*S{1: {"A"}}
// Through the pointer, you can call either the Read method or the Write method
sPtrs[1].Read()
sPtrs[1].Write("test")
Similarly, even if the method has a value receiver, the pointer receiver can also be used to meet the interface.
type F interface {
f()
}
type S1 struct{}
func (s S1) f() {}
type S2 struct{}
func (s *S2) f() {}
s1Val := S1{}
s1Ptr := &S1{}
s2Val := S2{}
s2Ptr := &S2{}
var i F
i = s1Val
i = s1Ptr
i = s2Ptr
// The following code cannot be compiled. Because s2Val is a value, the value receiver is not used in the f method of S2
// i = s2Val
Note: Effective Go There is a paragraph about pointers vs. values Wonderful explanation.
1.4 zero Mutex is valid
-
Zero value sync Mutex and sync Rwmutex is valid. Therefore, the pointer to mutex is basically unnecessary.
Bad:
mu := new(sync.Mutex) mu.Lock()
Good:
var mu sync.Mutex mu.Lock()
-
Using a structure pointer, mutex should be a non pointer field of the structure. Even if the structure is not exported, do not directly embed mutex into the structure.
Bad: Mutex field, Lock and Unlock methods are not intentionally described in the API exported by SMap.
type SMap struct { sync.Mutex data map[string]string } func NewSMap() *SMap { return &SMap{ data: make(map[string]string), } } func (m *SMap) Get(k string) string { m.Lock() defer m.Unlock() return m.data[k] }Good: mutex and its methods are the implementation details of SMap and are not visible to its callers.
type SMap struct { mu sync.Mutex data map[string]string } func NewSMap() *SMap { return &SMap{ data: make(map[string]string), } } func (m *SMap) Get(k string) string { m.mu.Lock() defer m.mu.Unlock() return m.data[k] }Note: the author expresses doubts about this article.
1.5 copy Slices and Maps at the boundary
slices and maps contain pointers to the underlying data, so be careful when you need to copy them.
-
Slices and Maps are used as input parameters
Note that when a map or slice is passed in as a function parameter, if references to them are stored inside the function, you can modify them.
Bad:
func (d *Driver) SetTrips(trips []Trip) { d.trips = trips } trips := ... d1.SetTrips(trips) // You want to modify D1 Trips? trips[0] = ...Good:
func (d *Driver) SetTrips(trips []Trip) { d.trips = make([]Trip, len(trips)) copy(d.trips, trips) } trips := ... d1.SetTrips(trips) // Here we modify trips[0], but it will not affect D1 trips trips[0] = ... -
Returns slices or maps
Note: pay attention to the modification of the map or slice that exposes the internal state of the user.
Bad:
type Stats struct { mu sync.Mutex counters map[string]int } // The Snapshot returns the current status. func (s *Stats) Snapshot() map[string]int { s.mu.Lock() defer s.mu.Unlock() return s.counters } // Snapshots are no longer protected by mutexes // Therefore, any access to the snapshot will be affected by data competition // Impact stats counters snapshot := stats.Snapshot()Good:
type Stats struct { mu sync.Mutex counters map[string]int } func (s *Stats) Snapshot() map[string]int { s.mu.Lock() defer s.mu.Unlock() result := make(map[string]int, len(s.counters)) for k, v := range s.counters { result[k] = v } return result } // The snapshot is now a copy snapshot := stats.Snapshot()
1.6 using defer to release resources
Use defer to release resources, such as files or locks.
Bad:
p.Lock()
if p.count < 10 {
p.Unlock()
return p.count
}
p.count++
newCount := p.count
p.Unlock()
return newCount
// When there are multiple return branches, it is easy to forget unlock
Good:
p.Lock()
defer p.Unlock()
if p.count < 10 {
return p.count
}
p.count++
return p.count
// More readable
Note: using defer to improve readability is worthwhile because the cost of using them is acceptable compared to the readability of the code. It is especially suitable for larger methods that are not only simple memory access, in which the resource consumption of other calculations is much higher than that of defer.
1.7 the channel size is either 1 or unbuffered
The usual size of the channel should be 1 or unbuffered. By default, channel is unbuffered and its size is zero.
Bad:
// Should be enough to meet any situation! c := make(chan int, 64)
Good:
// Size: 1 c := make(chan int, 1) // perhaps // Unbuffered channel, size 0 c := make(chan int)
Note: it is recommended to carefully select the size of the channel because it may affect the state conditions and the logic of the context.
1.8 enumeration starts with 1
The standard way to introduce enumeration in Go is to declare a custom type and a const group using iota. Since the default value of a variable is 0, enumeration should usually start with a non-zero value.
Bad:
type Operation int const ( Add Operation = iota Subtract Multiply ) // Add=0, Subtract=1, Multiply=2
Good:
type Operation int const ( Add Operation = iota + 1 Subtract Multiply ) // Add=1, Subtract=2, Multiply=3
1.9 processing time using time
Time processing is complicated. Wrong assumptions about time usually include the following:
- There are 24 hours a day
- There are 60 minutes in an hour
- There are seven days a week
- There are 365 days in a year
- More
1.9.1 use time Time denotes instantaneous time
Use time when processing the moment of time Time, use time when comparing, adding, or subtracting time Method in time.
Bad:
func isActive(now, start, stop int) bool {
return start <= now && now < stop
}
Good:
func isActive(now, start, stop time.Time) bool {
return (start.Before(now) || start.Equal(now)) && now.Before(stop)
}
Note: the method used to add time depends on the intention. If you want the same time on the next calendar day (the next day of the current day), you should use time Adddate. However, if you want to ensure that a certain time is 24 hours later than the previous time, you should use time Add.
newDay := t.AddDate(0 /* years */, 0 /* months */, 1 /* days */) maybeNewDay := t.Add(24 * time.Hour)
1.9.2 use time Duration expression period
Use time. When processing time periods Duration.
Bad:
func poll(delay int) {
for {
// ...
time.Sleep(time.Duration(delay) * time.Millisecond)
}
}
poll(10) // Seconds or milliseconds?
Good:
func poll(delay time.Duration) {
for {
// ...
time.Sleep(delay)
}
}
poll(10*time.Second)
Use time. For external systems Time and time Duration
Whenever possible, use time in interactions with external systems Duration and time Time. For example:
- Command line flag: flag adopt time.ParseDuration Support time Duration
- JSON: encoding/json Through its UnmarshalJSON method Method supports time Time code is RFC 3339 character string
- SQL: database/sql Support the conversion of DATETIME or TIMESTAMP columns to time Time, if supported by the underlying driver
- YAML: gopkg.in/yaml.v2 Support time Time as RFC 3339 String, and through time.ParseDuration Support time Duration.
When you can no longer use time in these interactions For duration, use int or float64 and include units in the field name.
Bad:
// {"interval": 2}
type Config struct {
Interval int `json:"interval"`
}
Good:
// {"intervalMillis": 2000}
type Config struct {
IntervalMillis int `json:"intervalMillis"`
}
Note 1: because encoding/json does not support time Duration, so the unit is included in the name of the field.
When time cannot be used in interaction Time, use string and unless agreed RFC 3339 Format timestamp defined in. The time package does not support resolving leap second timestamps, nor does it consider leap seconds in calculations.
1.10 Errors
1.10.1 error type
There are few instances of declaration errors. When using, please consider the following situations:
-
Does the caller need to match the error so that they can handle it?
If so, errors must be supported by declaring a top-level error or custom type Is or errors As function.
-
Is the error message a static string or a dynamic string that requires context information?
If it is a static string, you can use errors New, but for dynamic strings, you must use FMT Errorfor custom error type.
-
Are you passing new errors returned by downstream functions?
If yes, refer to the error packaging section later.
Wrong match? Error message guidance No static errors.New No dynamic fmt.Errorf Yes static top-level var with errors.New Yes dynamic custom error type
errors.New represents an example of an error with a static string
No error matching:
// package foo
func Open() error {
return errors.New("could not open")
}
// package bar
if err := foo.Open(); err != nil {
// Can't handle the error.
panic("unknown error")
}
Wrong match:
// package foo
var ErrCouldNotOpen = errors.New("could not open")
func Open() error {
return ErrCouldNotOpen
}
// package bar
if err := foo.Open(); err != nil {
if errors.Is(err, foo.ErrCouldNotOpen) {
// handle the error
} else {
panic("unknown error")
}
}
fmt. Errorfexamples of errors in dynamic strings 🌰
No error matching:
// package foo
func Open(file string) error {
return fmt.Errorf("file %q not found", file)
}
// package bar
if err := foo.Open("testfile.txt"); err != nil {
// Can't handle the error.
panic("unknown error")
}
Wrong match:
// package foo
type NotFoundError struct {
File string
}
func (e *NotFoundError) Error() string {
return fmt.Sprintf("file %q not found", e.File)
}
func Open(file string) error {
return &NotFoundError{File: file}
}
// package bar
if err := foo.Open("testfile.txt"); err != nil {
var notFound *NotFoundError
if errors.As(err, ¬Found) {
// handle the error
} else {
panic("unknown error")
}
}
Note: if you export error variables or types from the package, they will become part of the public API of the package
1.10.2 wrong packaging
If the call fails, there are several processing methods:
- Returns the original error as is
- Use FMT Errorfand% w
- Use FMT Errorfand% v
If there is no other context to add, the original error is returned as is. Otherwise, add context to the error message as much as possible so that fuzzy errors such as "connection rejected" do not occur.
Use FMT Errorfadd up-down questions of errors and choose between% w or% v verbs according to the needs of the caller.
- Use% w if the caller should have access to the underlying error. This is a good default for most packaging errors.
- Use% v to confuse the underlying error. The caller cannot match it, but it can be changed to% w in the future if necessary.
Note: when adding context to the returned error, avoid using phrases such as "fail to" to keep the context concise. When the error penetrates upward through the stack, it will be stacked layer by layer:
Bad:
s, err := store.New()
if err != nil {
return fmt.Errorf(
"failed to create new store: %w", err)
}
failed to x: failed to y: failed to create new store: the error
Good:
s, err := store.New()
if err != nil {
return fmt.Errorf(
"new store: %w", err)
}
x: y: new store: the error
Note: once an error is sent to another system, it should be clear that the message is an error (for example, err tag or "Failed" prefix in the log)
In addition Don't just check for errors, handle them gracefully.
1.10.3 wrong naming
For error values stored as global variables, the prefix err or err is used depending on whether they are exported
var (
// Export the following two errors so that users of this package can associate them with errors Match is.
ErrBrokenLink = errors.New("link is broken")
ErrCouldNotOpen = errors.New("could not open")
// This error was not exported because we don't want it to be part of our public API. We may still use it in packages with errors.
errNotFound = errors.New("not found")
)
For custom Error types, use the suffix Error instead.
// Again, the error is exported so that users of the package can associate it with errors As match.
type NotFoundError struct {
File string
}
func (e *NotFoundError) Error() string {
return fmt.Sprintf("file %q not found", e.File)
}
// And this error was not exported because we don't want it to be part of the public API. We can still do it with errors Use it in as's package.
type resolveError struct {
Path string
}
func (e *resolveError) Error() string {
return fmt.Sprintf("resolve %q", e.Path)
}
1.11 processing assertion failed
Type Asserts panic will be returned as a single return value when an incorrect type is detected. Therefore, always use the "x, ok" method.
Bad:
t := i.(string)
Good:
t, ok := i.(string)
if !ok {
// Handle errors gracefully
}
1.12 do not use panic
Code running in a build environment must avoid painc. panic is Cascade failure The main source of. If an error occurs, the function must return an error and allow the calling method to decide how to handle it.
Bad:
func run(args []string) {
if len(args) == 0 {
panic("an argument is required")
}
// ...
}
func main() {
run(os.Args[1:])
}
Good:
func run(args []string) error {
if len(args) == 0 {
return errors.New("an argument is required")
}
// ...
return nil
}
func main() {
if err := run(os.Args[1:]); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
}
Note: panic/recover is not an error handling strategy. The program must panic only if something unrecoverable (such as a nil reference) occurs. Program initialization is an exception: the bad condition that the program should be stopped when the program starts may cause panic.
Even in test code, t.Fatal or t.FailNow is preferred over panic to ensure that failures are marked.
Bad:
// func TestFoo(t *testing.T)
f, err := ioutil.TempFile("", "test")
if err != nil {
panic("failed to set up test")
}
Good:
// func TestFoo(t *testing.T)
f, err := ioutil.TempFile("", "test")
if err != nil {
t.Fatal("failed to set up test")
}
1.13 avoiding variable global variables
Use selective dependency injection to avoid changing global variables. This applies to both function pointers and other value types.
Bad:
// sign.go
var _timeNow = time.Now
func sign(msg string) string {
now := _timeNow()
return signWithTime(msg, now)
}
// sign_test.go
func TestSign(t *testing.T) {
oldTimeNow := _timeNow
_timeNow = func() time.Time {
return someFixedTime
}
defer func() { _timeNow = oldTimeNow }()
assert.Equal(t, want, sign(give))
}
Good:
// sign.go
type signer struct {
now func() time.Time
}
func newSigner() *signer {
return &signer{
now: time.Now,
}
}
func (s *signer) Sign(msg string) string {
now := s.now()
return signWithTime(msg, now)
}
// sign_test.go
func TestSigner(t *testing.T) {
s := newSigner()
s.now = func() time.Time {
return someFixedTime
}
assert.Equal(t, want, s.Sign(give))
}
1.14 avoid embedding types in public structures
Assuming that a shared AbstractList is created to implement multiple list types, please avoid embedding AbstractList in a specific list implementation. Instead, you just need to manually write the method to the concrete list, which will be delegated to the abstract list.
type AbstractList struct {}
// Add adds an entity to the list.
func (l *AbstractList) Add(e Entity) {
// ...
}
// Remove removes an entity from the list.
func (l *AbstractList) Remove(e Entity) {
// ...
}
Bad:
// ConcreteList is a list of entities.
type ConcreteList struct {
*AbstractList
}
Good:
// ConcreteList is a list of entities.
type ConcreteList struct {
list *AbstractList
}
// Add adds an entity to the list.
func (l *ConcreteList) Add(e Entity) {
l.list.Add(e)
}
// Remove removes an entity from the list.
func (l *ConcreteList) Remove(e Entity) {
l.list.Remove(e)
}
Go allow Type embedding As a compromise between inheritance and composition.
Note: the embedded structure obtains a field with the same name as the type. Therefore, if the embedded type is public, the field is public. To maintain backward compatibility, each future version of an external type must retain the embedded type.
Embedded types are rarely required. This is a convenience that can help avoid lengthy writing, but it still risks leaking specific implementation details.
Bad:
// AbstractList is a common implementation of various entity lists.
type AbstractList interface {
Add(Entity)
Remove(Entity)
}
// ConcreteList is a list of entities.
type ConcreteList struct {
AbstractList
}
Good:
// ConcreteList is a list of entities.
type ConcreteList struct {
list AbstractList
}
// Add adds an entity to the list.
func (l *ConcreteList) Add(e Entity) {
l.list.Add(e)
}
// Remove removes an entity from the list.
func (l *ConcreteList) Remove(e Entity) {
l.list.Remove(e)
}
Both embedded structures and embedded interfaces will limit the evolution of types.
- Adding methods to embedded interfaces is a disruptive change
- The method of deleting from embedded structures is a destructive change.
- Deleting embedded types is a disruptive change.
- Even if you replace an embedded type with a type that satisfies the same interface, this operation is a destructive change.
Note: Although writing these delegate methods is tedious, it hides the implementation details, leaves more opportunities for change, and eliminates the indirect operation of discovering the complete list interface in the document.
1.15 avoid using built-in names
Go language norm Outlines several built-in that should not be used in Go projects Pre declared identifier.
Depending on the context, reusing these identifiers as names will hide the original identifiers in the current scope (or any nested scope), or confuse the code. In the best case, the compiler will report an error; In the worst case, such code may introduce potential and difficult to recover errors.
Bad:
var error string
// `error ` scope implicit override
// or
func handleErrorMessage(error string) {
// `error ` scope implicit override
}
type Foo struct {
// Although these fields do not form a shadow technically, the remapping of 'error' or 'string' strings is not clear now.
error error
string string
}
func (f Foo) Error() error {
// `Error 'and' f.error 'are visually similar
return f.error
}
func (f Foo) String() string {
// `string` and `f.string ` are visually similar
return f.string
}
Good:
var errorMessage string
// `error ` points to the built-in non overlay
// or
func handleErrorMessage(msg string) {
// `error ` points to the built-in non overlay
}
type Foo struct {
// `error` and `string ` are now explicit.
err error
str string
}
func (f Foo) Error() error {
return f.err
}
func (f Foo) String() string {
return f.str
}
Note: the compiler does not generate errors when using pre segmented identifiers, but tools such as go vet correctly address these and other implicit problems.
1.16 avoid using init()
Avoid using init() whenever possible. Of course, init () is inevitable or desirable, and the code should ensure that:
- Regardless of the program environment or call, it should be completely determined.
- Avoid ordering or side effects that depend on other init() functions. Although the init () order is explicit, the code can be changed, so the relationship between init () functions may make the code fragile and error prone.
- Avoid accessing or manipulating global or environmental states, such as machine information, environment variables, working directories, program parameters / inputs, etc.
- Avoid I/O, including file system, network, and system calls.
Code that does not meet these requirements may be written as part of the main() call (or elsewhere in the program life cycle), or as part of the main() itself. In particular, libraries intended for use by other programs should pay particular attention to complete certainty rather than executing init magic
Bad:
type Foo struct {
// ...
}
var _defaultFoo Foo
func init() {
_defaultFoo = Foo{
// ...
}
}
type Config struct {
// ...
}
var _config Config
func init() {
// Bad: Based on current directory
cwd, _ := os.Getwd()
// Bad: I/O
raw, _ := ioutil.ReadFile(
path.Join(cwd, "config", "config.yaml"),
)
yaml.Unmarshal(raw, &_config)
}
Good:
var _defaultFoo = Foo{
// ...
}
// or, for better testability:
var _defaultFoo = defaultFoo()
func defaultFoo() Foo {
return Foo{
// ...
}
}
type Config struct {
// ...
}
func loadConfig() Config {
cwd, err := os.Getwd()
// handle err
raw, err := ioutil.ReadFile(
path.Join(cwd, "config", "config.yaml"),
)
// handle err
var config Config
yaml.Unmarshal(raw, &config)
return config
}
Considering the above, in some cases, init() may be preferable or necessary, which may include:
- A complex expression that cannot be represented as a single assignment
- Pluggable hooks, such as database/sql, encoding type registry, etc.
- yes Google Cloud Functions And other forms of deterministic precomputation optimization.
1.17 when adding, the slice capacity shall be specified preferentially
Append preferentially specifies the slice capacity. Whenever possible, provide a capacity value for make() when initializing the slice to append.
Bad:
for n := 0; n < b.N; n++ {
data := make([]int, 0)
for k := 0; k < size; k++{
data = append(data, k)
}
}
BenchmarkBad-4 100000000 2.48s
Good:
for n := 0; n < b.N; n++ {
data := make([]int, 0, size)
for k := 0; k < size; k++{
data = append(data, k)
}
}
BenchmarkGood-4 100000000 0.21s
1.18 main function Exit mode (Exit)
The Go program uses OS Exit or log Fatal * quit now. Only one of the aforementioned ones is invoked in main(). All other functions shall return the error to the signal failure.
Bad:
func main() {
body := readFile(path)
fmt.Println(body)
}
func readFile(path string) string {
f, err := os.Open(path)
if err != nil {
log.Fatal(err)
}
b, err := ioutil.ReadAll(f)
if err != nil {
log.Fatal(err)
}
return string(b)
}
Good:
func main() {
body, err := readFile(path)
if err != nil {
log.Fatal(err)
}
fmt.Println(body)
}
func readFile(path string) (string, error) {
f, err := os.Open(path)
if err != nil {
return "", err
}
b, err := ioutil.ReadAll(f)
if err != nil {
return "", err
}
return string(b), nil
}
In principle, the exit with multiple exits will have the following problems:
- Unobtrusive process flow: any function can exit the program, so it is difficult to reason about the control flow.
- Difficult to test: the function that exits the program will also exit the test that calls it. This makes the function difficult to test and introduces the risk of skipping other tests that go test has not yet run.
- Skip Cleanup: when the function exits the program, it will skip the function calls that have entered the defer queue. This may result in important cleanup tasks not being performed
One time exit
If possible, OS. Is called at most once in the main() function Exit or log Fatal. If there are multiple error scenarios to stop program execution, put the logic under a separate function and return an error from it.
Note: This shortens the main() function and puts all the key business logic into a single, testable function.
Bad:
package main
func main() {
args := os.Args[1:]
if len(args) != 1 {
log.Fatal("missing file")
}
name := args[0]
f, err := os.Open(name)
if err != nil {
log.Fatal(err)
}
defer f.Close()
// If we call log Fatal is behind this line
// f.Close will be executed
b, err := ioutil.ReadAll(f)
if err != nil {
log.Fatal(err)
}
// ...
}
Good:
package main
func main() {
if err := run(); err != nil {
log.Fatal(err)
}
}
func run() error {
args := os.Args[1:]
if len(args) != 1 {
return errors.New("missing file")
}
name := args[0]
f, err := os.Open(name)
if err != nil {
return err
}
defer f.Close()
b, err := ioutil.ReadAll(f)
if err != nil {
return err
}
// ...
}
2. Performance
2.1 strconv is preferred over fmt
strconv is faster than fmt when converting primitives to or from strings.
Bad:
for i := 0; i < b.N; i++ {
s := fmt.Sprint(rand.Int())
}
BenchmarkFmtSprint-4 143 ns/op 2 allocs/op
Good:
for i := 0; i < b.N; i++ {
s := strconv.Itoa(rand.Int())
}
BenchmarkStrconv-4 64.2 ns/op 1 allocs/op
2.2 avoid string to byte conversion
Do not repeatedly create byte slice from fixed string. Instead, perform a transformation and capture the results.
Bad:
for i := 0; i < b.N; i++ {
w.Write([]byte("Hello world"))
}
BenchmarkBad-4 50000000 22.2 ns/op
Good:
data := []byte("Hello world")
for i := 0; i < b.N; i++ {
w.Write(data)
}
BenchmarkGood-4 500000000 3.25 ns/op
2.3 specified container capacity
Specify the container capacity as much as possible to pre allocate memory for the container. This minimizes subsequent allocations (by copying and resizing containers) when adding elements.
2.3.1 indication of Map capacity
If possible, provide capacity information when initializing with make(). Providing a capacity hint to make () will attempt to resize the map at initialization, which will reduce the reallocation of memory for the map when elements are added to the map.
make(map[T1]T2, hint)
Note: different from slices. The map capacity hint does not guarantee full preemptive allocation, but is used to estimate the number of HashMap buckets required. Therefore, an allocation can occur when an element is added to a map, even when the map capacity is specified.
**Bad: ** m is created without size prompt. There may be more allocations at run time.
m := make(map[string]os.FileInfo)
files, _ := ioutil.ReadDir("./files")
for _, f := range files {
m[f.Name()] = f
}
Good: m is created with size prompt, and there will be less allocation at run time.
files, _ := ioutil.ReadDir("./files")
m := make(map[string]os.FileInfo, len(files))
for _, f := range files {
m[f.Name()] = f
}
2.3.2 specify slice capacity
Whenever possible, provide capacity information when initializing slices using make(), especially when adding slices.
make([]T, length, capacity)
Note: slice capacity is not a hint: the compiler will allocate enough memory for the slice capacity provided to make(), which means that the subsequent append() operation will result in zero allocation.
After the length of the slice matches the capacity, any append will resize the slice to accommodate other elements.
Bad:
for n := 0; n < b.N; n++ {
data := make([]int, 0)
for k := 0; k < size; k++{
data = append(data, k)
}
}
BenchmarkBad-4 100000000 2.48s
Good:
for n := 0; n < b.N; n++ {
data := make([]int, 0, size)
for k := 0; k < size; k++{
data = append(data, k)
}
}
BenchmarkGood-4 100000000 0.21s
3. Programming mode
3.1 table drive test
When the test logic is repeated, pass subtests Writing case code in a table driven way looks much simpler.
Bad:
// func TestSplitHostPort(t *testing.T)
host, port, err := net.SplitHostPort("192.0.2.0:8000")
require.NoError(t, err)
assert.Equal(t, "192.0.2.0", host)
assert.Equal(t, "8000", port)
host, port, err = net.SplitHostPort("192.0.2.0:http")
require.NoError(t, err)
assert.Equal(t, "192.0.2.0", host)
assert.Equal(t, "http", port)
host, port, err = net.SplitHostPort(":8000")
require.NoError(t, err)
assert.Equal(t, "", host)
assert.Equal(t, "8000", port)
host, port, err = net.SplitHostPort("1:8")
require.NoError(t, err)
assert.Equal(t, "1", host)
assert.Equal(t, "8", port)
Good:
// func TestSplitHostPort(t *testing.T)
tests := []struct{
give string
wantHost string
wantPort string
}{
{
give: "192.0.2.0:8000",
wantHost: "192.0.2.0",
wantPort: "8000",
},
{
give: "192.0.2.0:http",
wantHost: "192.0.2.0",
wantPort: "http",
},
{
give: ":8000",
wantHost: "",
wantPort: "8000",
},
{
give: "1:8",
wantHost: "1",
wantPort: "8",
},
}
for _, tt := range tests {
t.Run(tt.give, func(t *testing.T) {
host, port, err := net.SplitHostPort(tt.give)
require.NoError(t, err)
assert.Equal(t, tt.wantHost, host)
assert.Equal(t, tt.wantPort, port)
})
}
Obviously, the method of using test table will be clearer when the code logic is extended, such as adding a test case.
We follow this Convention: the structure slice is called tests. Each test case is called tt. In addition, it is recommended to use the prefix give and want to describe the input and output values of each test case.
tests := []struct{
give string
wantHost string
wantPort string
}{
// ...
}
for _, tt := range tests {
// ...
}
3.2 function options
A function Option is a pattern in which you can declare an opaque Option type that records information in some internal structures. Accept the numbers of these options and take action based on all the information recorded by the options on the internal structure.
Use this pattern to extend optional parameters in constructors and other public API s, especially if you already have three or more parameters on these functions.
Bad:
// package db
func Open(
addr string,
cache bool,
logger *zap.Logger
) (*Connection, error) {
// ...
}
Cache and logger parameters must always be provided, even if the user wants to use default values.
db.Open(addr, db.DefaultCache, zap.NewNop()) db.Open(addr, db.DefaultCache, log) db.Open(addr, false /* cache */, zap.NewNop()) db.Open(addr, false /* cache */, log)
Good:
// package db
type Option interface {
// ...
}
func WithCache(c bool) Option {
// ...
}
func WithLogger(log *zap.Logger) Option {
// ...
}
// Open creates a connection.
func Open(
addr string,
opts ...Option,
) (*Connection, error) {
// ...
}
Provide options only when needed
db.Open(addr) db.Open(addr, db.WithLogger(log)) db.Open(addr, db.WithCache(false)) db.Open( addr, db.WithCache(false), db.WithLogger(log), )
The recommended way to implement this pattern is to use an Option interface, which saves an unexported method and records the options on an unexported options structure.
type options struct {
cache bool
logger *zap.Logger
}
type Option interface {
apply(*options)
}
type cacheOption bool
func (c cacheOption) apply(opts *options) {
opts.cache = bool(c)
}
func WithCache(c bool) Option {
return cacheOption(c)
}
type loggerOption struct {
Log *zap.Logger
}
func (l loggerOption) apply(opts *options) {
opts.logger = l.Log
}
func WithLogger(log *zap.Logger) Option {
return loggerOption{Log: log}
}
// Open creates a connection.
func Open(
addr string,
opts ...Option,
) (*Connection, error) {
options := options{
cache: defaultCache,
logger: zap.NewNop(),
}
for _, o := range opts {
o.apply(&options)
}
// ...
}
Note: the above pattern provides developers with more flexibility and easier debugging and testing. In particular, it allows options to be compared in tests and simulations where comparison is not possible. In addition, it allows options to implement other interfaces, including FMT Stringer, which allows the user to read the string representation of the option.
There is another way to implement this pattern using closures.
You can also refer to the following information:
-
Functional options for friendly APIs
Chinese version: https://goroutine.cn/2020/06/14/Functional-options-for-friendly-APIs/
4. Broken thoughts
Another beautiful day:
- Everything we do in life is to avoid pain and obtain happiness.
- It's amazing to live your life every day, isn't it.
- Nothing in the world is meaningful, meaning is given by people, and persistence itself is an incomparably shining meaning.