Learning Video: 8 Hours Transfer to Golang Engineer This course is very suitable for small partners with certain development experience, push!
Golang Advancement
reflex
Variable Built-in Pair Structure
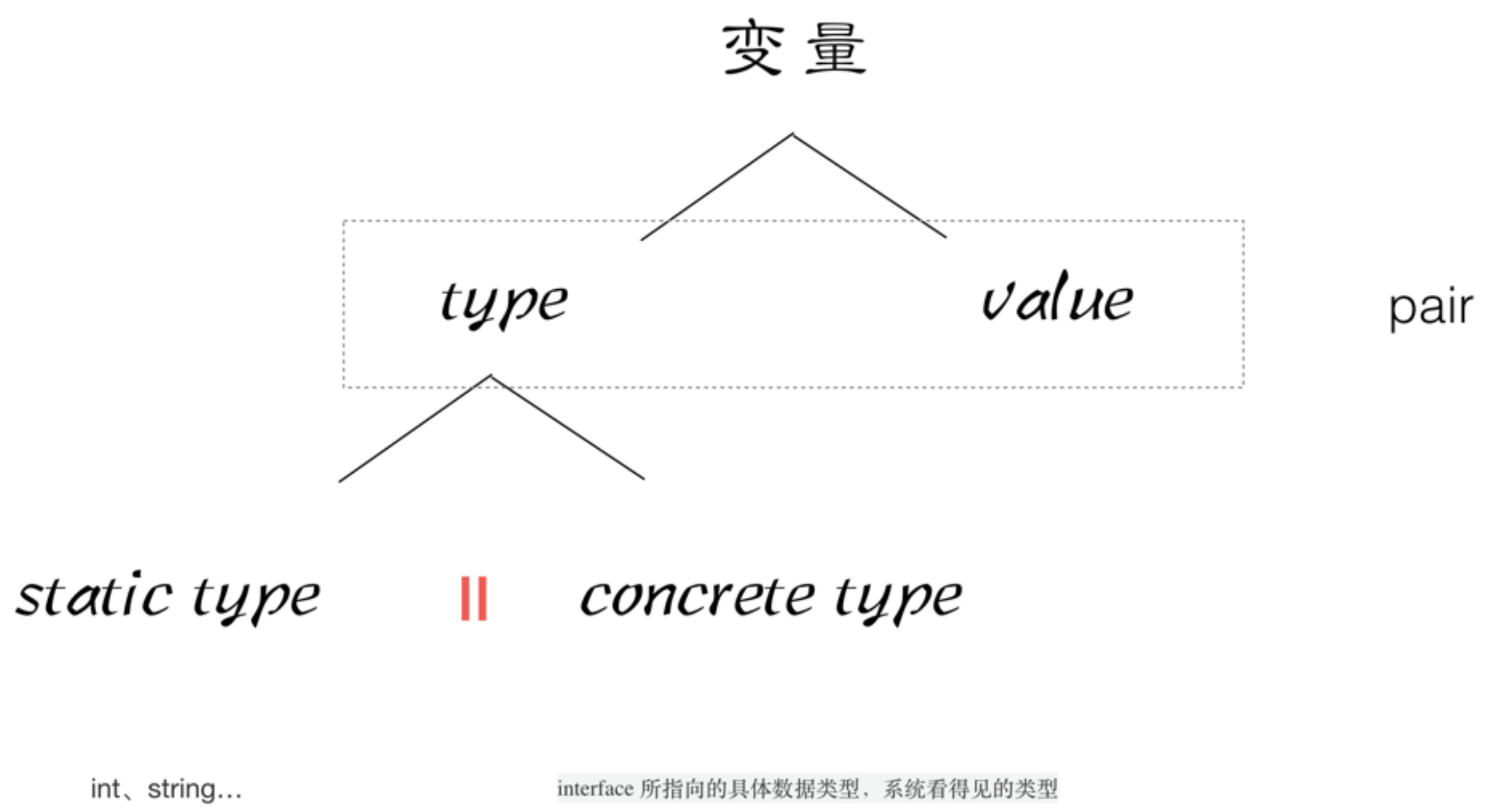
var a string
// pair<statictype:string, value:"aceld">
a = "aceld"
var allType interface{}
// pair<type:string, value:"aceld">
allType = a
str, _ := allType.(string)
Type assertions are actually value s derived from the type in pari
// Tty: pair<type: *os. File, value: "/dev/tty" file descriptor>
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
fmt.Println("open file error", err)
return
}
// r: pair<type: , value: >
var r io.Reader
// R: pair<type: *os. File, value: "/dev/tty" file descriptor>
r = tty
// w: pair<type: , value: >
var w io.Writer
// W: pair<type: *os. File, value: "/dev/tty" file descriptor>
w = r.(io.Writer) // Turn Strongly
w.Write([]byte("HELLO THIS IS A TEST!!\n"))
Carefully analyze the following code:
- Since pairs do not change during delivery, tpye in pairs is always a Book, regardless of r or w
- Because Book implements Reader and Wrtier interfaces, ReadBook() and WriteBook() can be called for type Book.
type Reader interface {
ReadBook()
}
type Writer interface {
WriteBook()
}
// Specific types
type Book struct {
}
func (b *Book) ReadBook() {
fmt.Println("Read a Book")
}
func (b *Book) WriteBook() {
fmt.Println("Write a Book")
}
func main() {
// B: pair<type: Book, value: book{} address>
b := &Book{}
// book ---> reader
// r: pair<type: , value: >
var r Reader
// R: pair<type: Book, value: book{} address>
r = b
r.ReadBook()
// reader ---> writer
// w: pair<type: , value: >
var w Writer
// W: pair<type: Book, value: book{} address>
w = r.(Writer) // Why did the assertion here succeed? Because w, r has the same type
w.WriteBook()
}
reflect
Two important interfaces in the reflect package:
// ValueOf returns a new Value initialized to the concrete value
// stored in the interface i. ValueOf(nil) returns the zero Value.
func ValueOf(i interface{}) Value {...}
// The ValueOf interface is used to get the value of the data in the input parameter interface and returns 0 if the interface is empty
// TypeOf returns the reflection Type that represents the dynamic type of i.
// If i is a nil interface value, TypeOf returns nil.
func TypeOf(i interface{}) Type {...}
// TypeOf is used to dynamically get the type of value in the input parameter interface, and returns nil if the interface is empty
Application of reflection:
- Get the type and value of a simple variable:
func reflectNum(arg interface{}) {
fmt.Println("type : ", reflect.TypeOf(arg))
fmt.Println("value : ", reflect.ValueOf(arg))
}
func main() {
var num float64 = 1.2345
reflectNum(num)
}
type : float64 value : 1.2345
- Field method to get structure variables:
type User struct {
Id int
Name string
Age int
}
func (u User) Call() {
fmt.Println("user ius called..")
fmt.Printf("%v\n", u)
}
func main() {
user := User{1, "AceId", 18}
DoFieldAndMethod(user)
}
func DoFieldAndMethod(input interface{}) {
// Get the type of input
inputType := reflect.TypeOf(input)
fmt.Println("inputType is :", inputType.Name())
// Get value of input
inputValue := reflect.ValueOf(input)
fmt.Println("inputValue is :", inputValue)
// Get the fields inside by type
// 1. Get the reflect of the interface. Type, NumField from Type, traverse
// 2. Get each field, data type
// 3. Fieldhas an Interface() method to get the corresponding value
for i := 0; i < inputType.NumField(); i++ {
field := inputType.Field(i)
value := inputValue.Field(i).Interface()
fmt.Printf("%s: %v = %v\n", field.Name, field.Type, value)
}
// Get the method inside by type, call
for i := 0; i < inputType.NumMethod(); i++ {
m := inputType.Method(i)
fmt.Printf("%s: %v\n", m.Name, m.Type)
}
}
inputType is : User
inputValue is : {1 AceId 18}
Id: int = 1
Name: string = AceId
Age: int = 18
Call: func(main.User)
Structural Label
Definition of structure tags:
type resume struct {
Name string `info:"name" doc:"My name"`
Sex string `info:"sex"`
}
func findTag(str interface{}) {
t := reflect.TypeOf(str).Elem()
for i := 0; i < t.NumField(); i++ {
taginfo := t.Field(i).Tag.Get("info")
tagdoc := t.Field(i).Tag.Get("doc")
fmt.Println("info: ", taginfo, " doc: ", tagdoc)
}
}
func main() {
var re resume
findTag(&re)
}
info: name doc: My name info: sex doc:
Application of Structural Labels: JSON Encoding and Decoding
import (
"encoding/json"
"fmt"
)
type Movie struct {
Title string `json:"title"`
Year int `json:"year"`
Price int `json:"price"`
Actors []string `json:"actors"`
Test string `json:"-"` // Ignore the value, do not resolve
}
func main() {
movie := Movie{"King of Comedy", 2000, 10, []string{"xingye", "zhangbozhi"}, "hhh"}
// Encoding: Structural - > JSON
jsonStr, err := json.Marshal(movie)
if err != nil {
fmt.Println("json marshal error", err)
return
}
fmt.Printf("jsonStr = %s\n", jsonStr)
// Decoding: jsonstr ->Structures
myMovie := Movie{}
err = json.Unmarshal(jsonStr, &myMovie)
if err != nil {
fmt.Println("json unmarshal error", err)
return
}
fmt.Printf("%v\n", myMovie)
}
jsonStr = {"title":"King of Comedy","year":2000,"price":10,"actors":["xingye","zhangbozhi"]}
{Comedy King 2000 10 [xingye zhangbozhi] }
Other applications: orm mapping relationships...
Concurrent knowledge
Fundamentals
Early operating systems were single-process and had two problems:
1. Processing of a single execution process and computer with only one task and one task
2. Wasting CPU time due to process blocking

Multi-threaded/multi-process solves blocking issues:
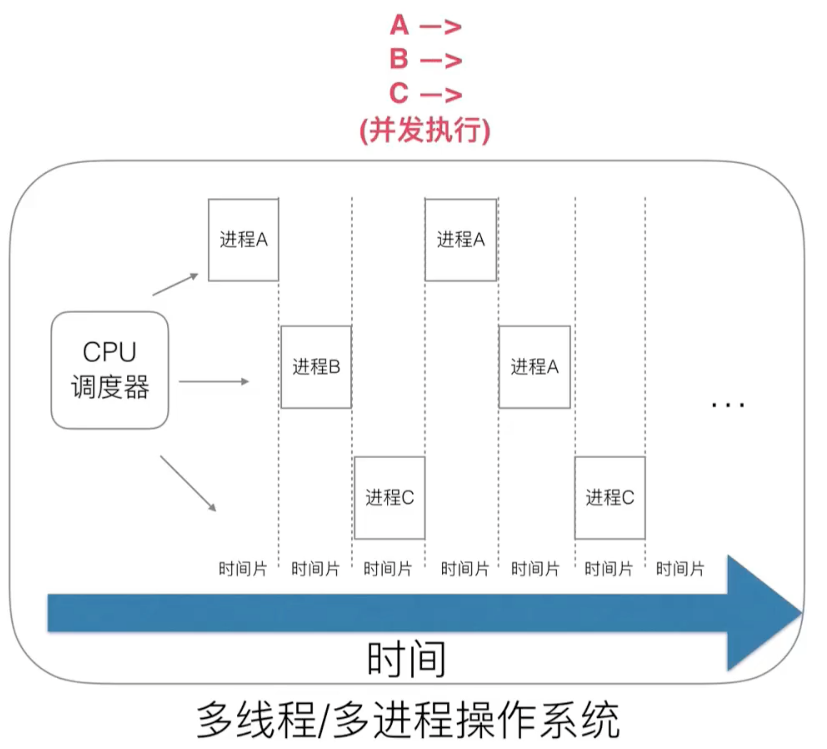
However, multithreading has a new problem: context switching is expensive.
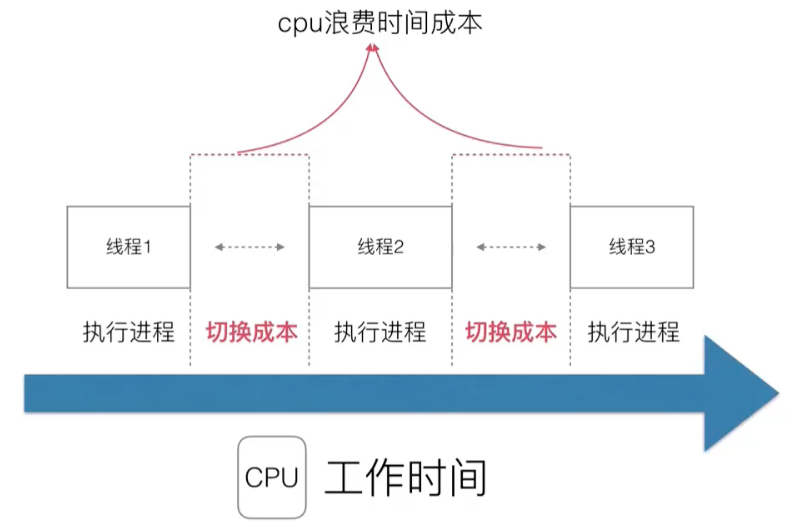
The more processes/threads there are, the greater the switching cost and the more wasteful it will be.
It is possible that the CPU usage is 100%, 60% of which are executing programs and 40% of which are executing switches...
With synchronous competition (lock, competing resource conflicts, etc.), development design becomes more and more complex.
Multi-threading has high CPU consumption, high memory consumption issues:
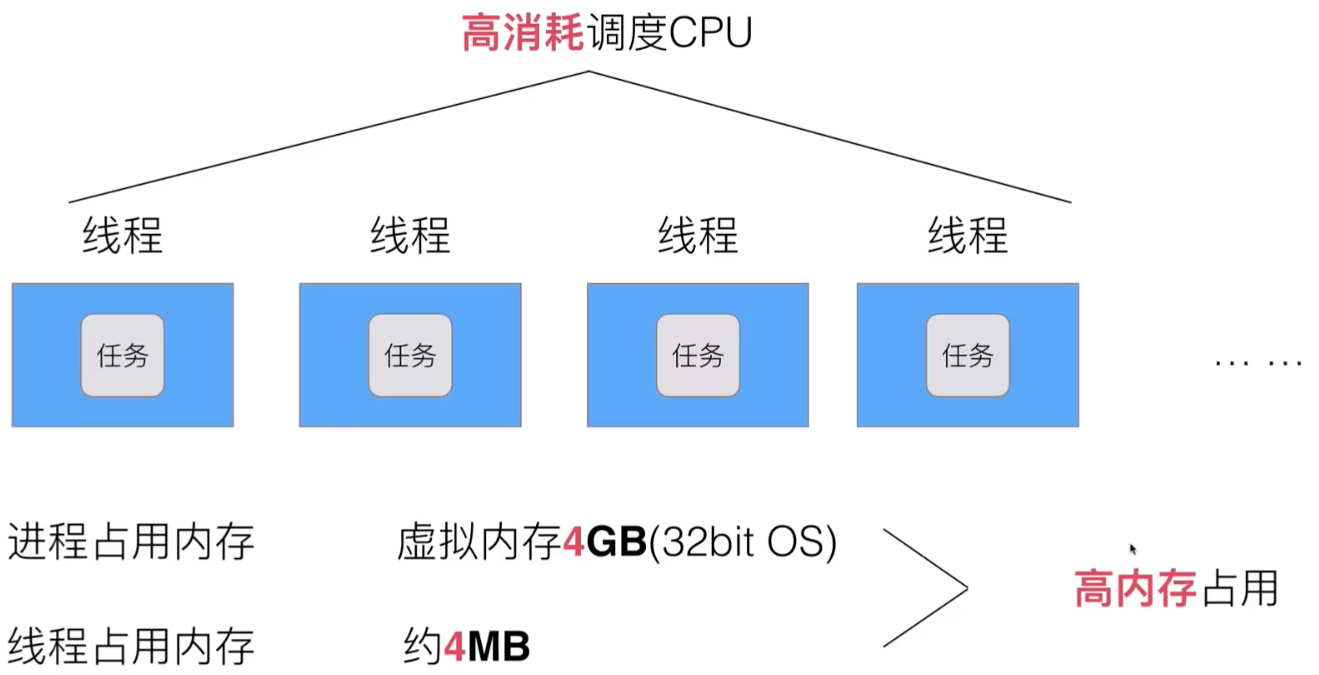
If the threads in kernel space and user space are detached, there will be a consortium (that is, a thread in user space).
The threads in the kernel space are scheduled by the CPU, and the collaboration is scheduled by the developer.
A user thread is a protocol. The kernel thread is the real thread.
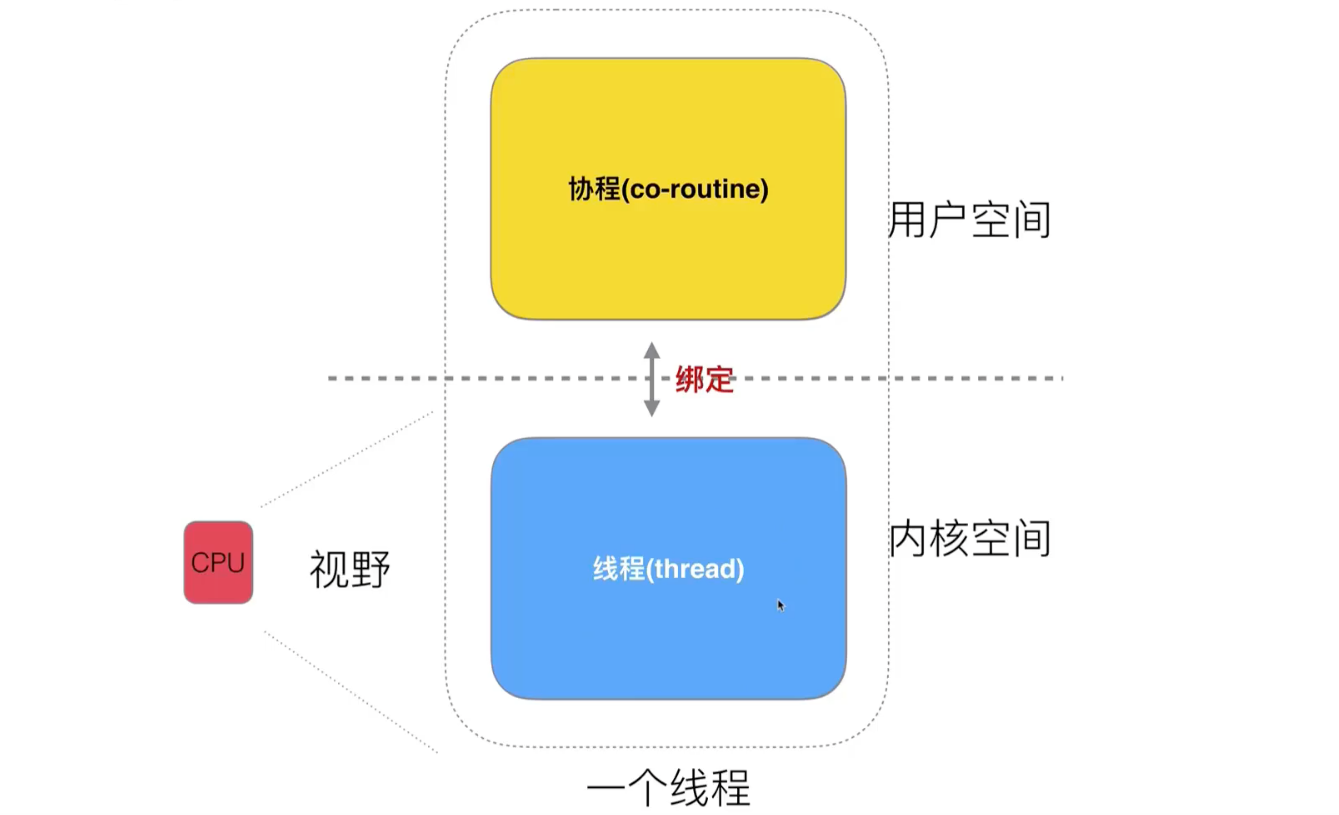
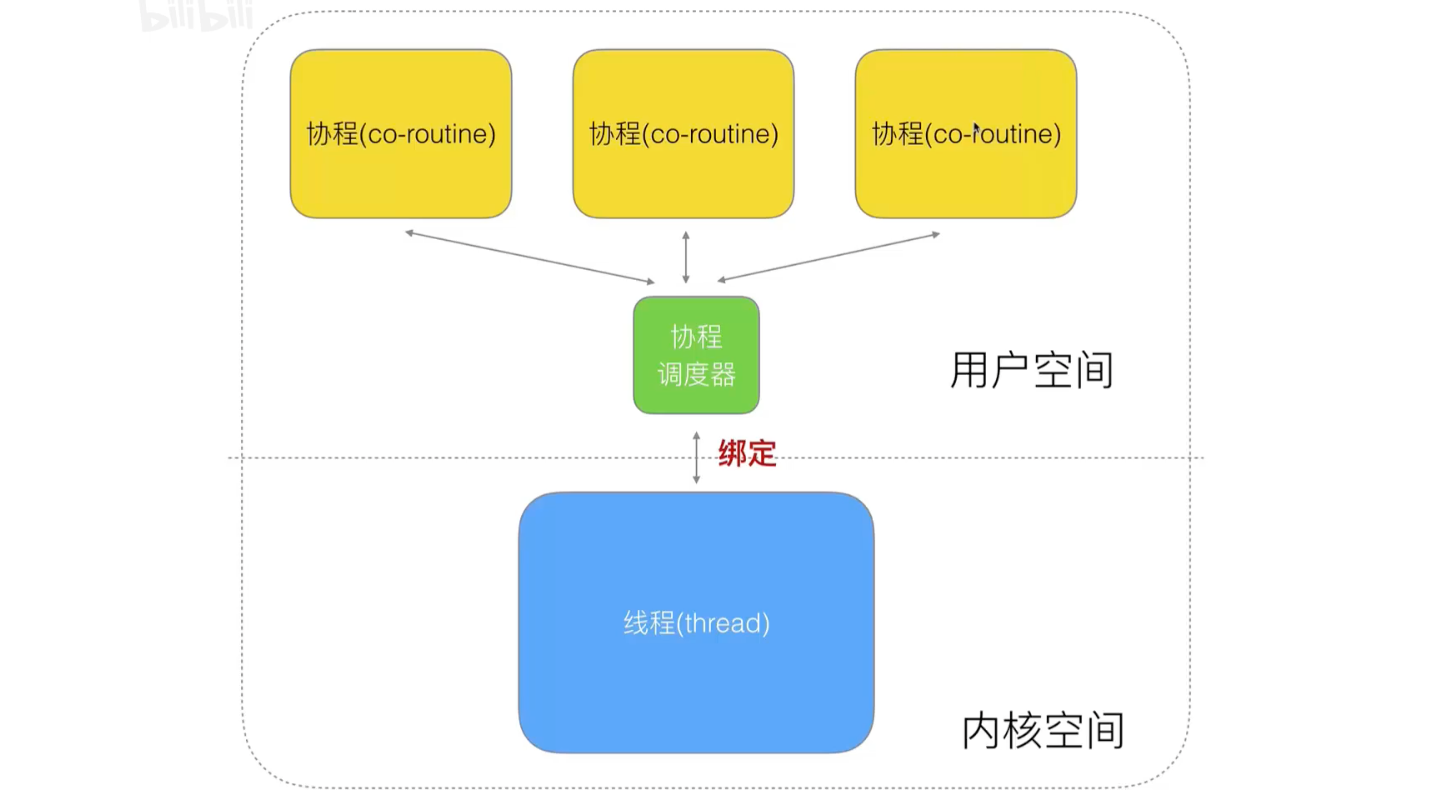
Then between the kernel thread and the coprocess, add a coprocess scheduler: a one-to-many model that implements threads and coprocesses
The disadvantage of this model is that if one protocol is blocked, it affects the next call (polling mode)
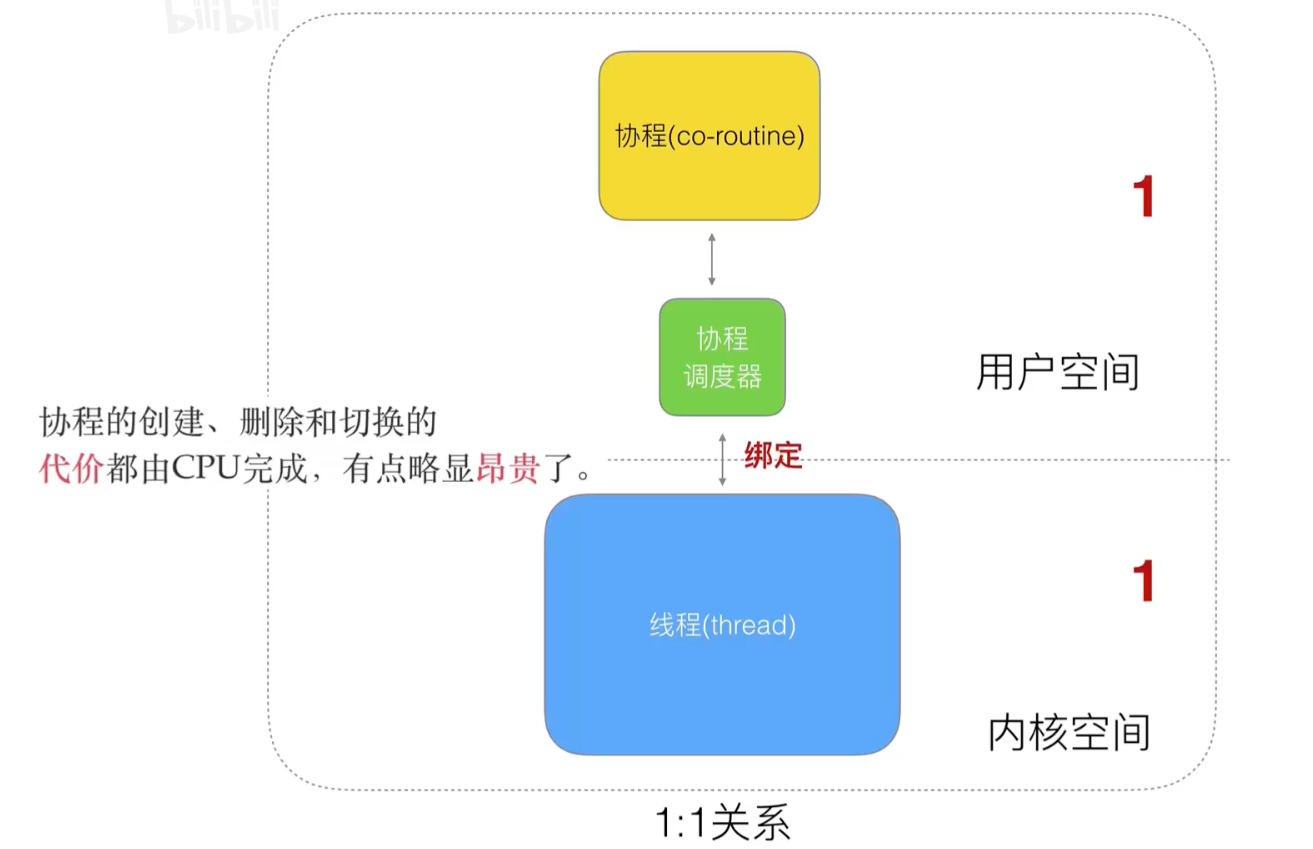
If you change the above model to a one-to-one model, there is no blocking, but it is no different from the previous threading model...
Continuing to optimize the many-to-many model will focus on optimizing the co-scheduler:
Kernel space is a CPU floor and we can't optimize much.
Different languages want to support the operation of a coprocess by optimizing its coprocess processor in user space.
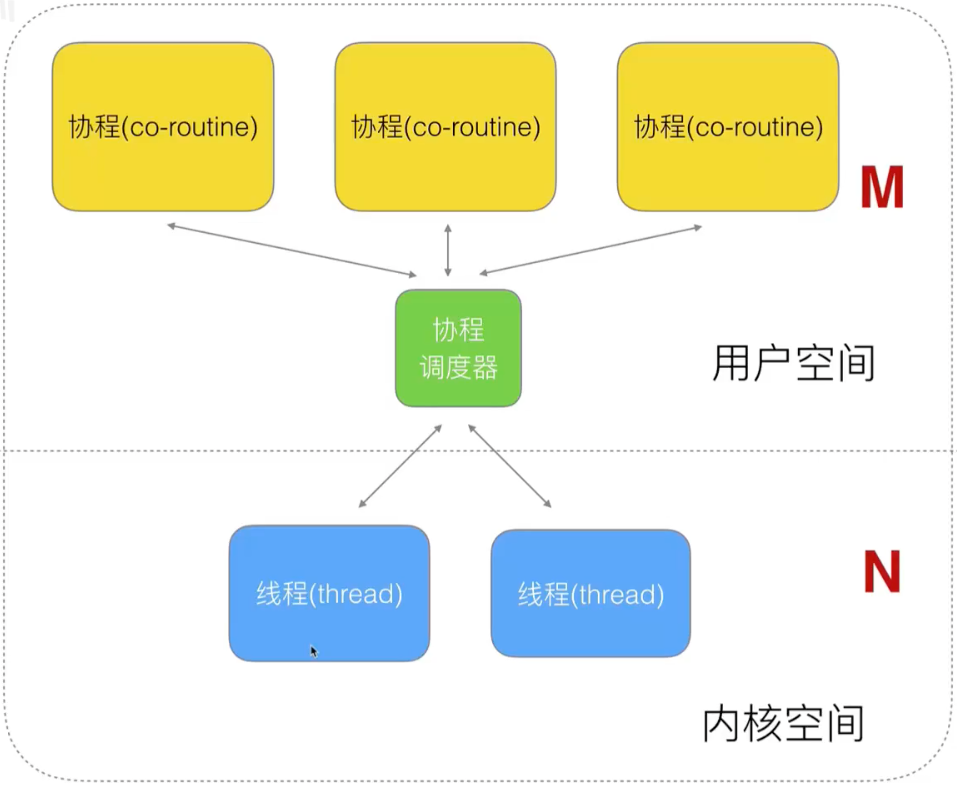
Go s'handling of the protocol:

Handling of early dispatchers

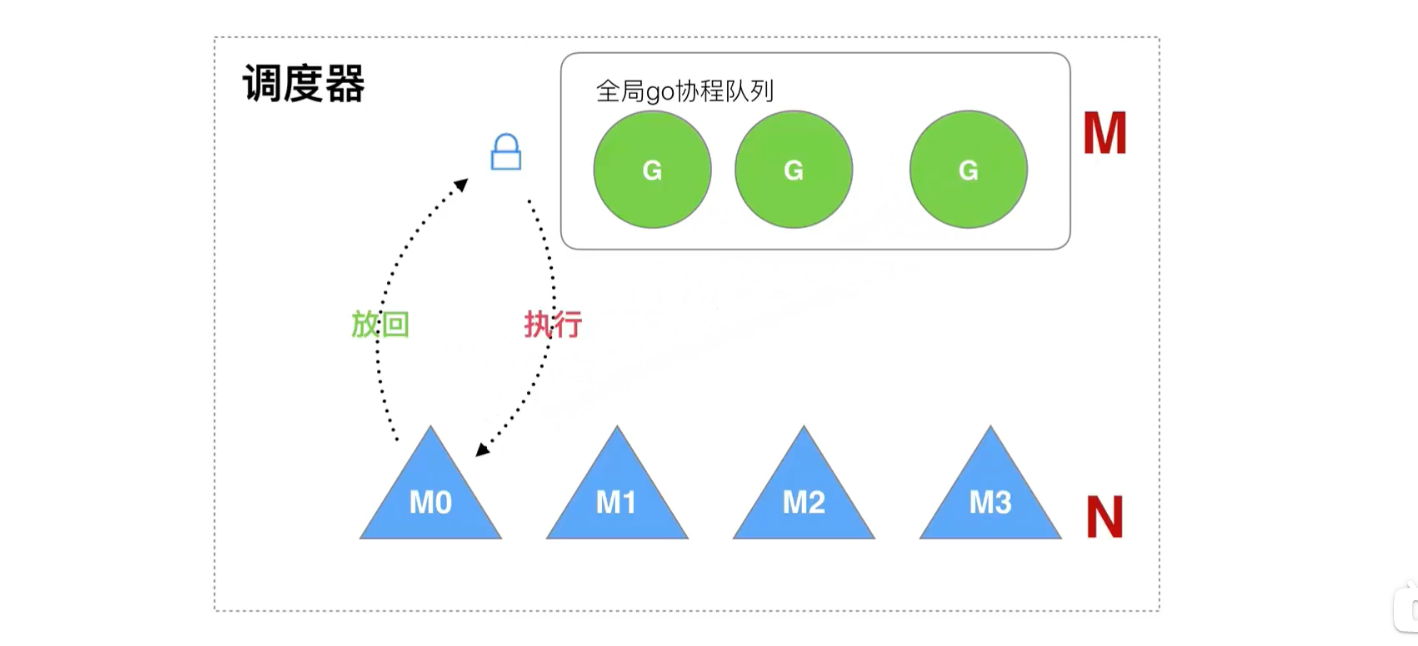
The old scheduler has several drawbacks:
- Creating, destroying, and dispatching G s require each M to acquire locks, creating intense lock competition.
- M-transfer G causes delays and additional system load.
- System calls (CPU s switching before M) result in frequent thread blocking and unblocking operations, increasing overhead.
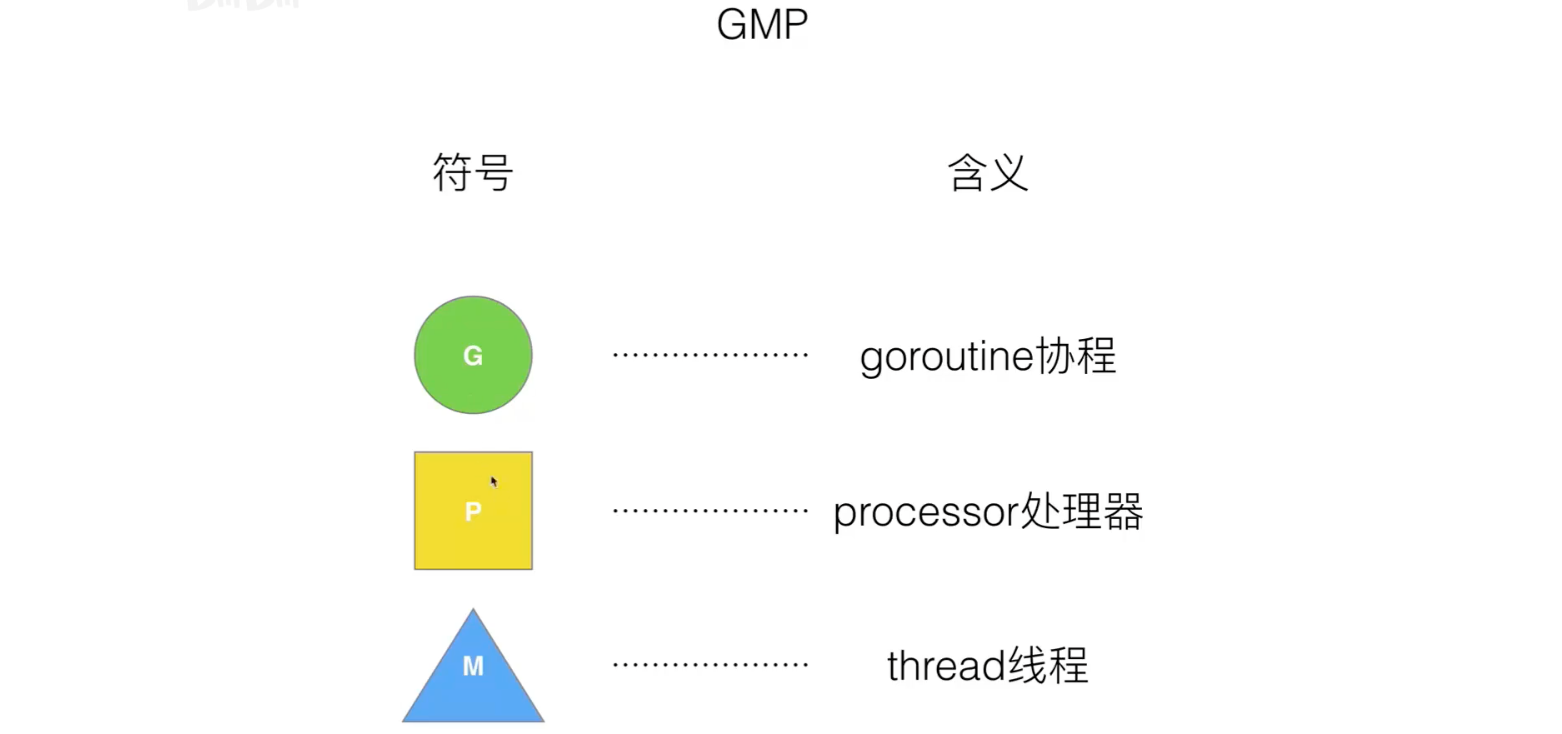
GMP Model
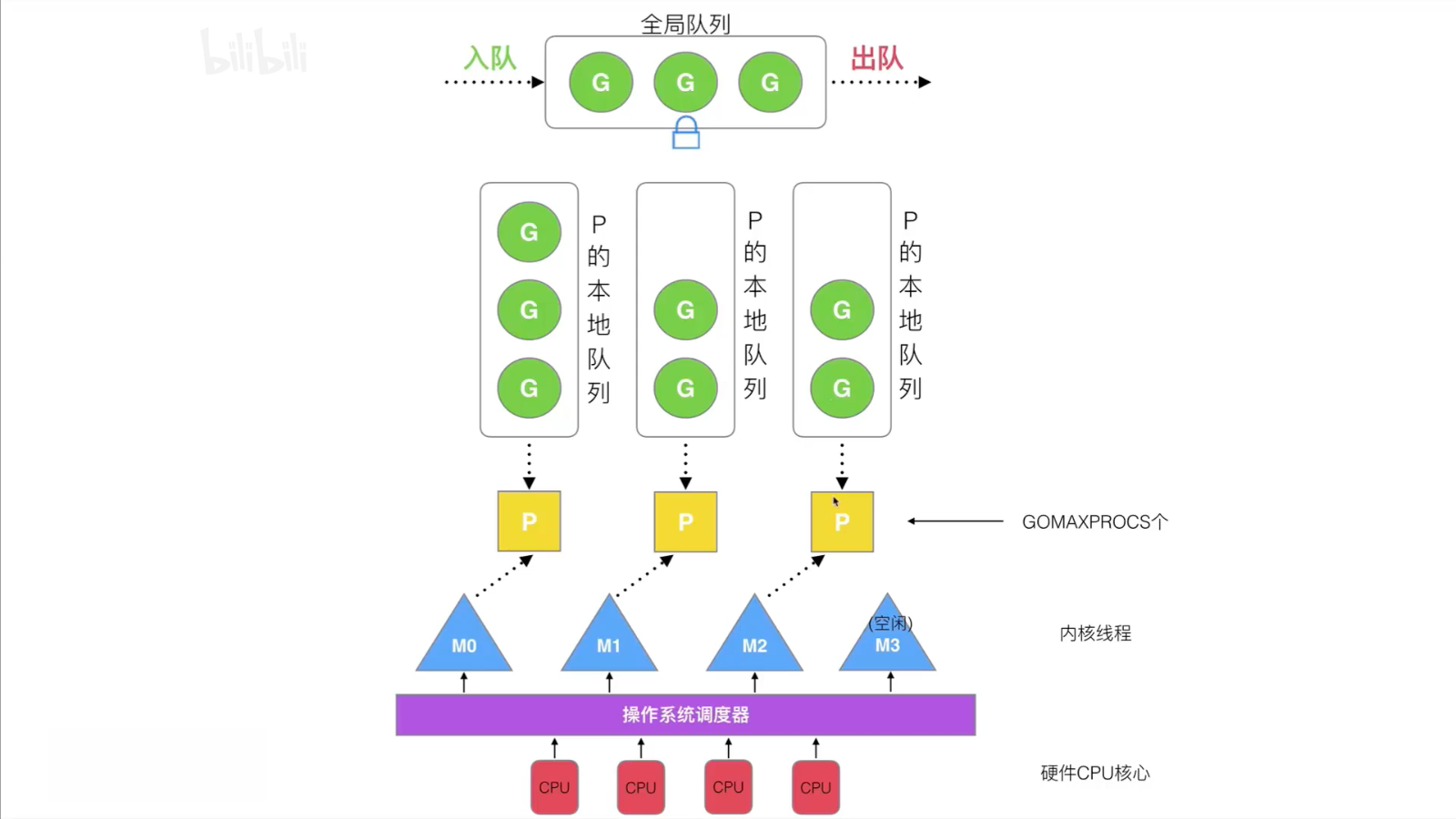
Scheduler Design Policies
Four design strategies for the scheduler: reusing threads, utilizing parallel, preemptive, global G-queue
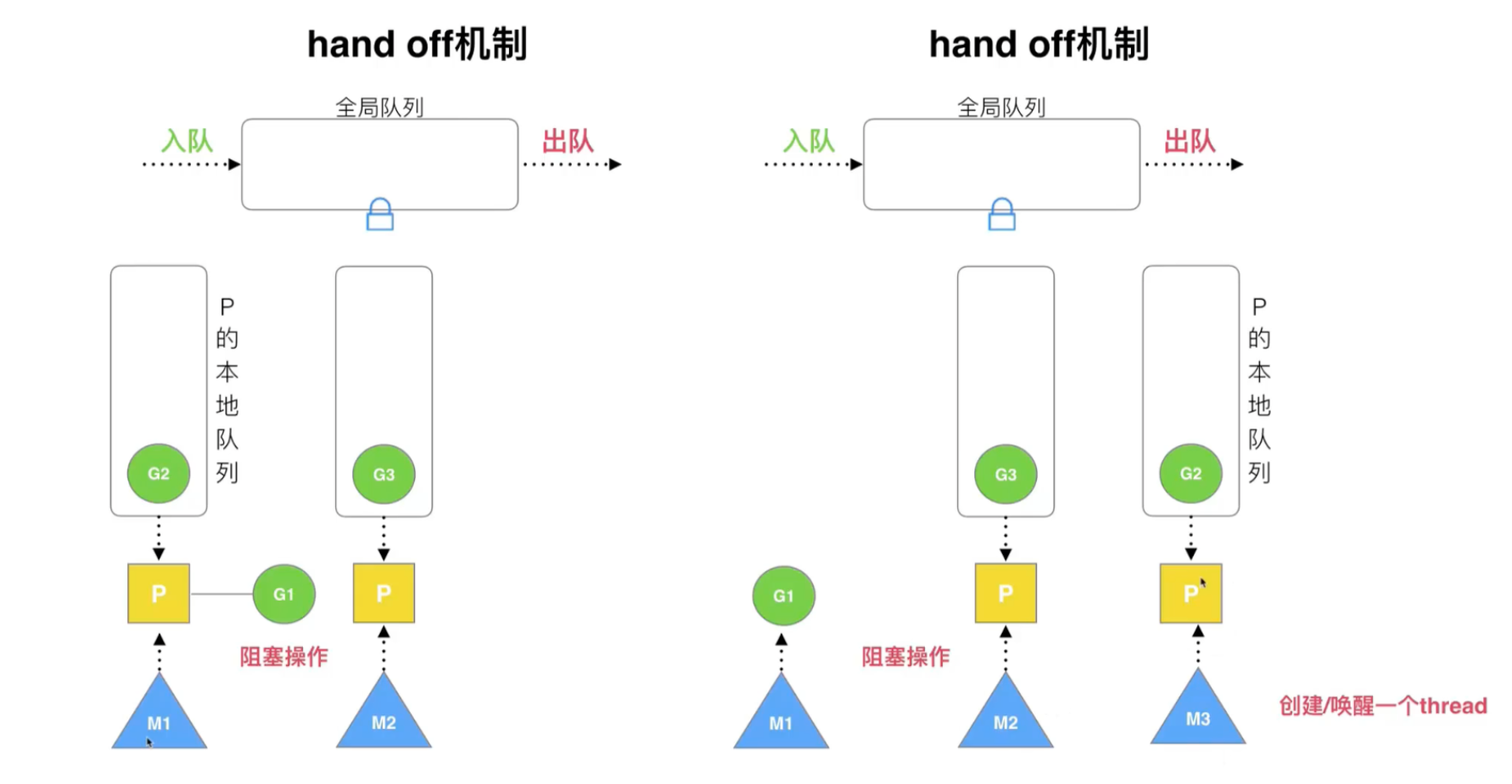
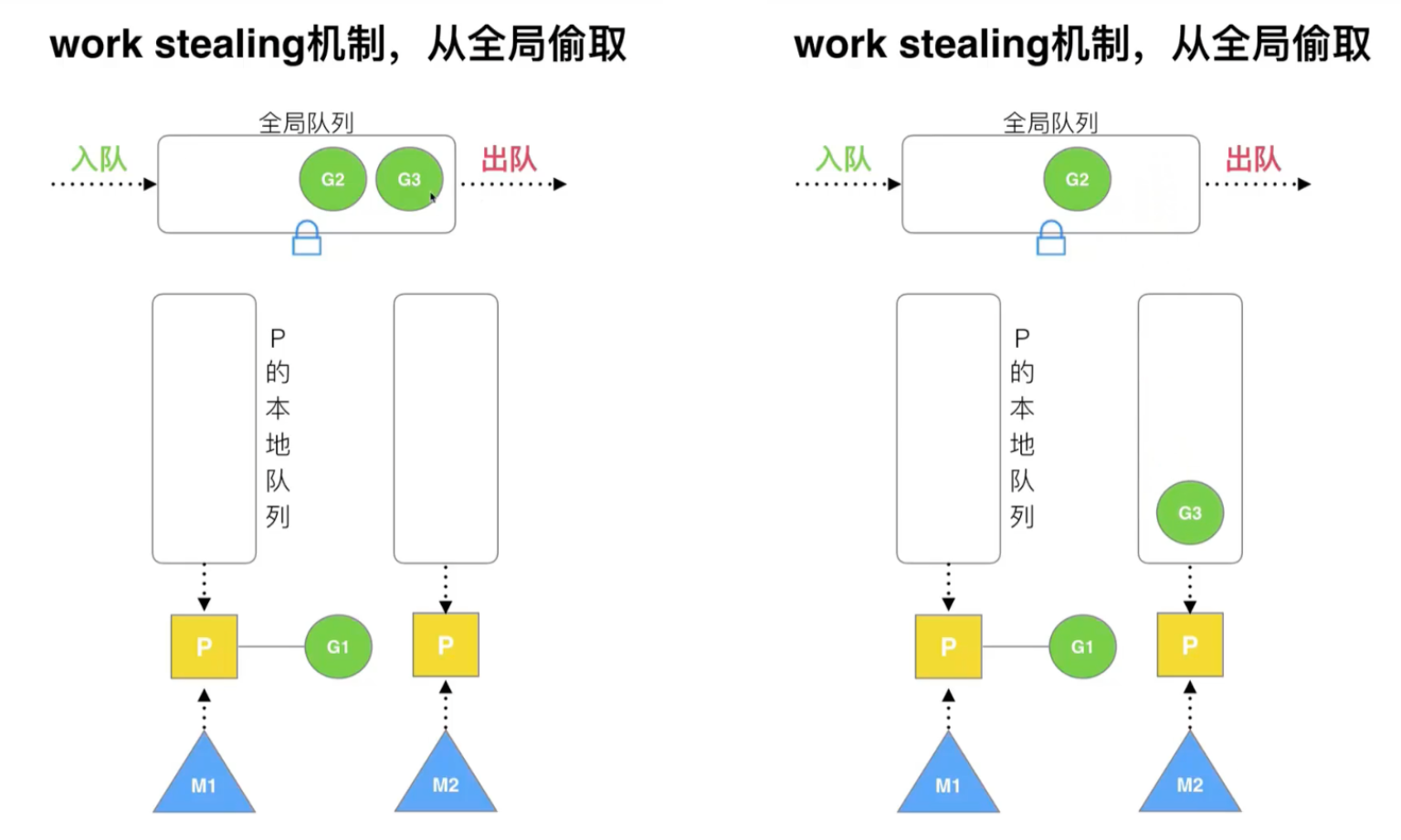
Reuse threads: work stealing, hand off
-
work stealing mechanism: a processor has an empty local queue and steals co-processes from other processors to execute
Note that this is a steal from a processor's local queue and also from a global queue
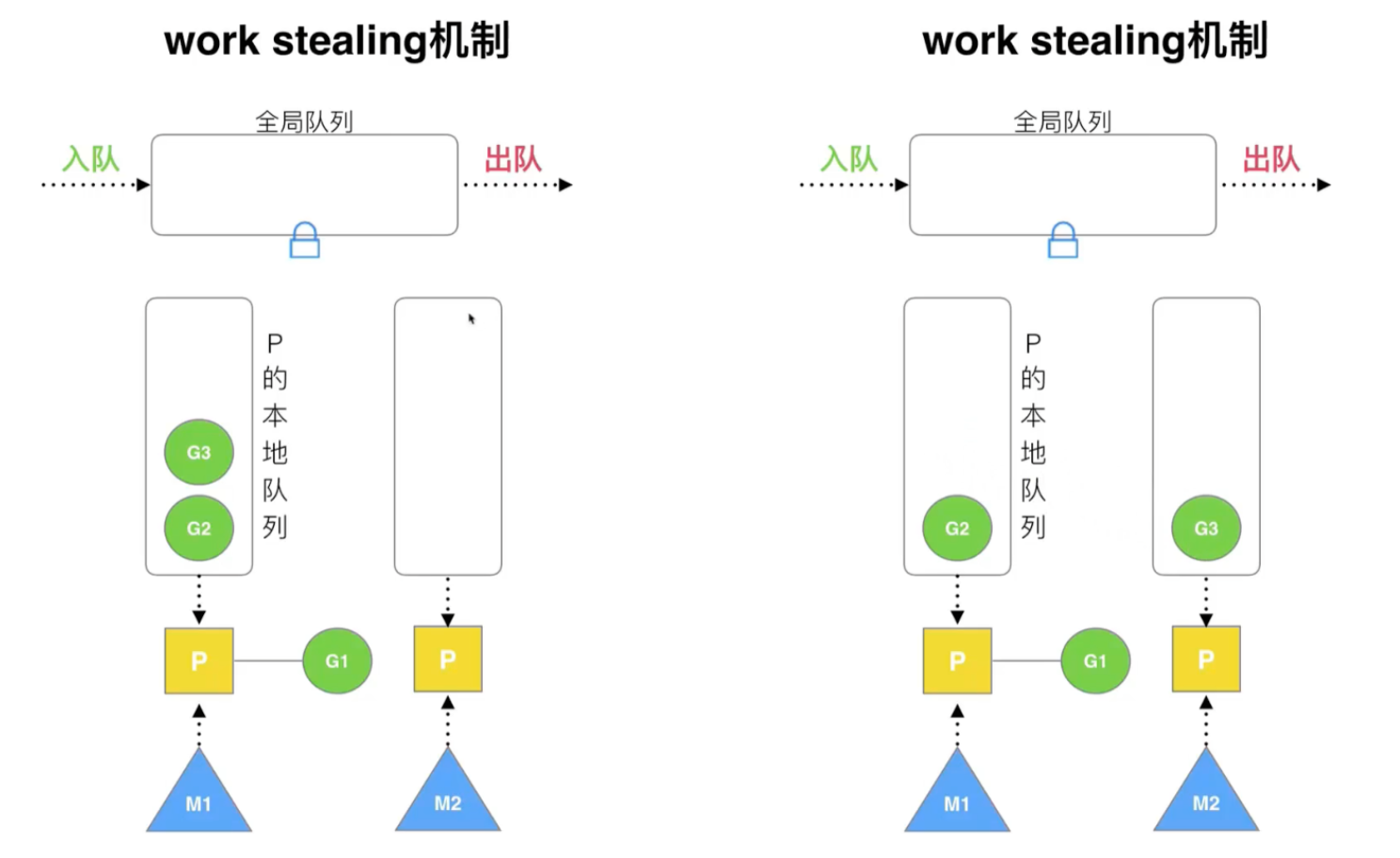
- Handoff mechanism: If one thread is blocked, the processor resources will be transferred to other threads.
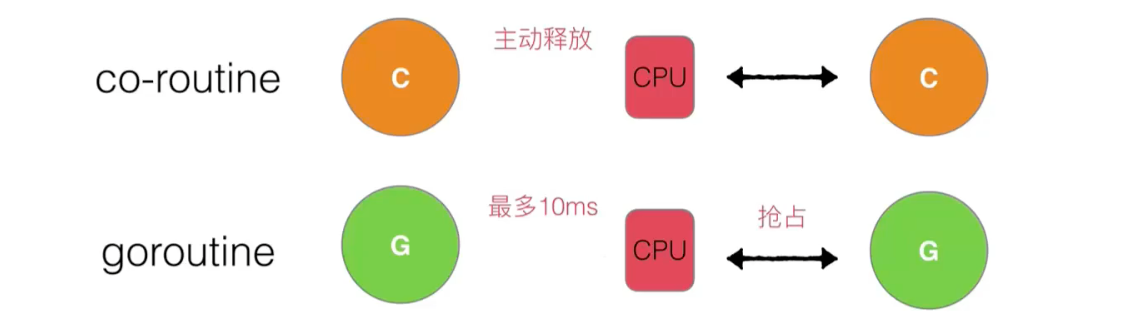
Leverage Parallelism: Use GOMAXPROCS to limit the number of P = CPU cores / 2
Seize:
Global G Queue: Based on the wark stealing mechanism, if no local queue for all processors has a protocol, it is obtained globally.
Concurrent programming
goroutine
Create goroutine:
// Subroutine
func newTask() {
i := 0
for {
i++
fmt.Printf("new Goroutie: i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
// Main routine
func main() {
// Create a subprocess to execute the newTask() process
go newTask()
i := 0
for {
i++
fmt.Printf("main goroutine: i = %d\n", i)
time.Sleep(1 * time.Second)
}
}
main goroutine: i = 1new Goroutie: i = 1new Goroutie: i = 2main goroutine: i = 2main goroutine: i = 3new Goroutie: i = 3...
Exit the current goroutine method runtime.Goexit(), compare the following two pieces of code:
func main() { go func() { defer fmt.Println("A.defer") func() { defer fmt.Println("B.defer") fmt.Println("B") }() fmt.Println("A") }() // Prevent program exit for { time.Sleep(1 * time.Second) }}
BB.deferAA.defer
Executed exit goroutine method:
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
runtime.Goexit() // Exit the current goroutine
fmt.Println("B")
}()
fmt.Println("A")
}()
// Prevent program exit
for {
time.Sleep(1 * time.Second)
}
}
B.defer A.defer
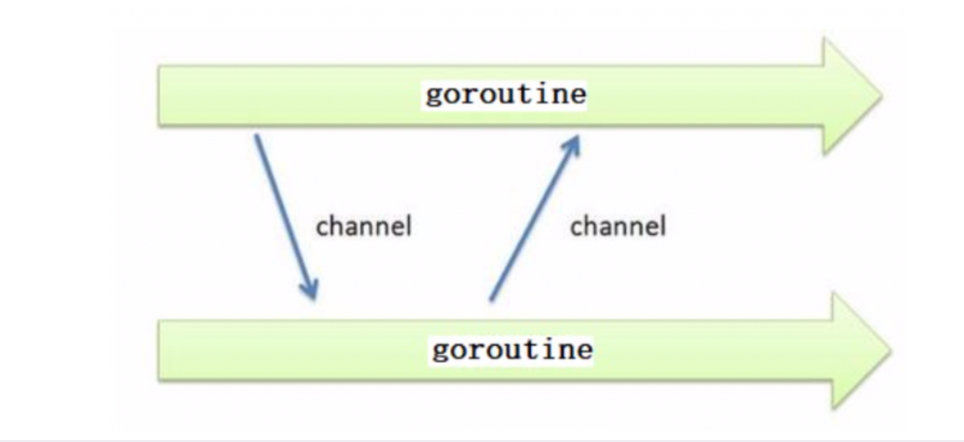
channel
channel is used for data transfer between goroutine s:
make(chan Type) // Equivalent to make(chan Type, 0) make(chan Type, capacity)
channel <- value // Send value to channel <-channel // Receive and discard x := <-channel // Receive data from channel and assign it to x x, ok := <-channel // Same functionality as above, checking if the channel is closed or empty
Use of channel:
func main() {
// Define a channel
c := make(chan int)
go func() {
defer fmt.Println("goroutine End")
fmt.Println("goroutine Running")
c <- 666 // Send 666 to c
}()
num := <-c // Accept data from c and assign it to num
fmt.Println("num = ", num)
fmt.Println("main goroutine End...")
}
goroutine Running... goroutine End num = 666 main goroutine End...
With the code above (using channel s to exchange data), the sub goroutine must run after the main goroutine:
- If the main goroutine runs fast, it enters the wait, waiting for the sub goroutine to pass the data
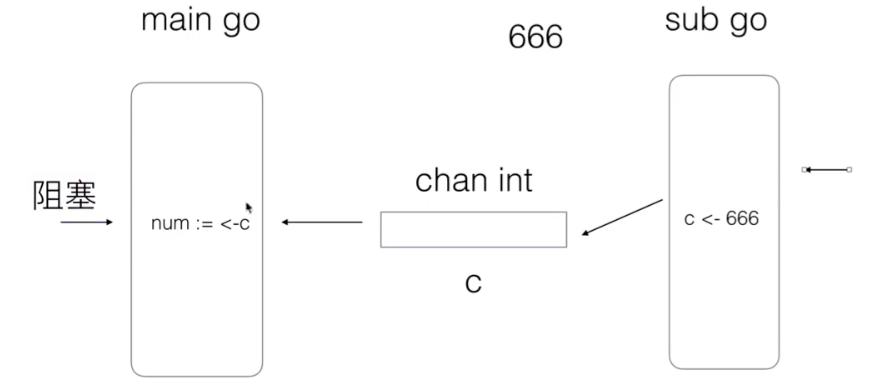
- If the sub goroutine runs fast, it also enters the wait, waits for the main routine to run to the current time, and then sends the data
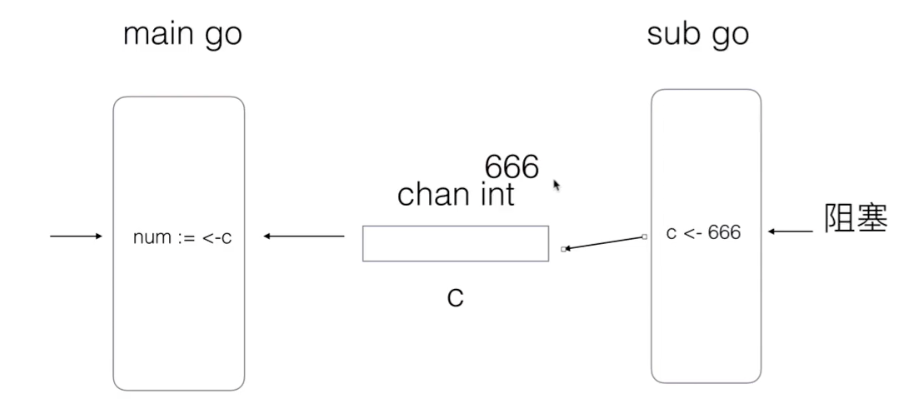
Unbuffered channel
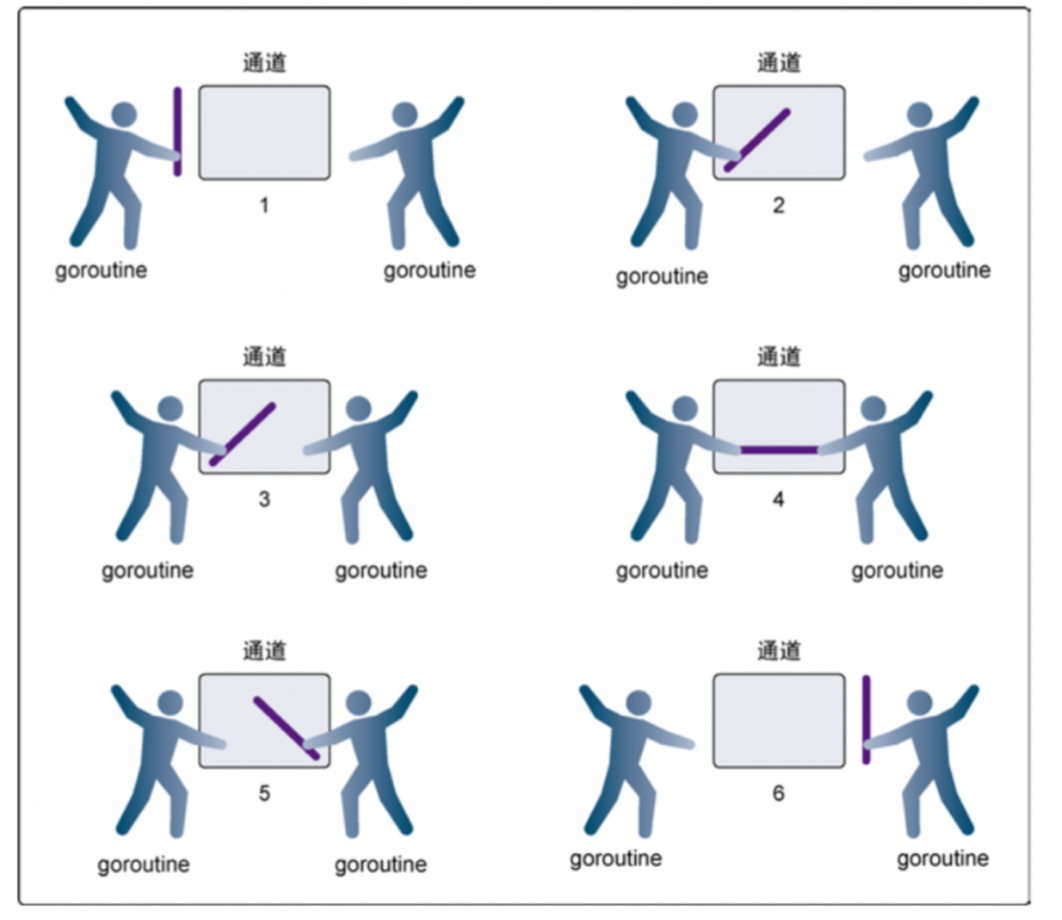
-
Step 1, both goroutine s reach the channel, but neither of them begins to send or receive.
-
Step 2, the goroutine on the left extends its channel, which simulates sending data to the channel.
This goroutine is then locked in the channel until the exchange is complete.
-
Step 3, the goroutine on the right will put its hand on the channel, which simulates receiving data from the channel.
This goroutine will also be locked in the channel until the exchange is complete.
-
Step 4 and Step 5, Forward and Swap.
-
Step 6, both goroutines take their hands out of the channel, which simulates the release of a locked goroutine.
Both goroutine s can now do other things.
Buffered channel
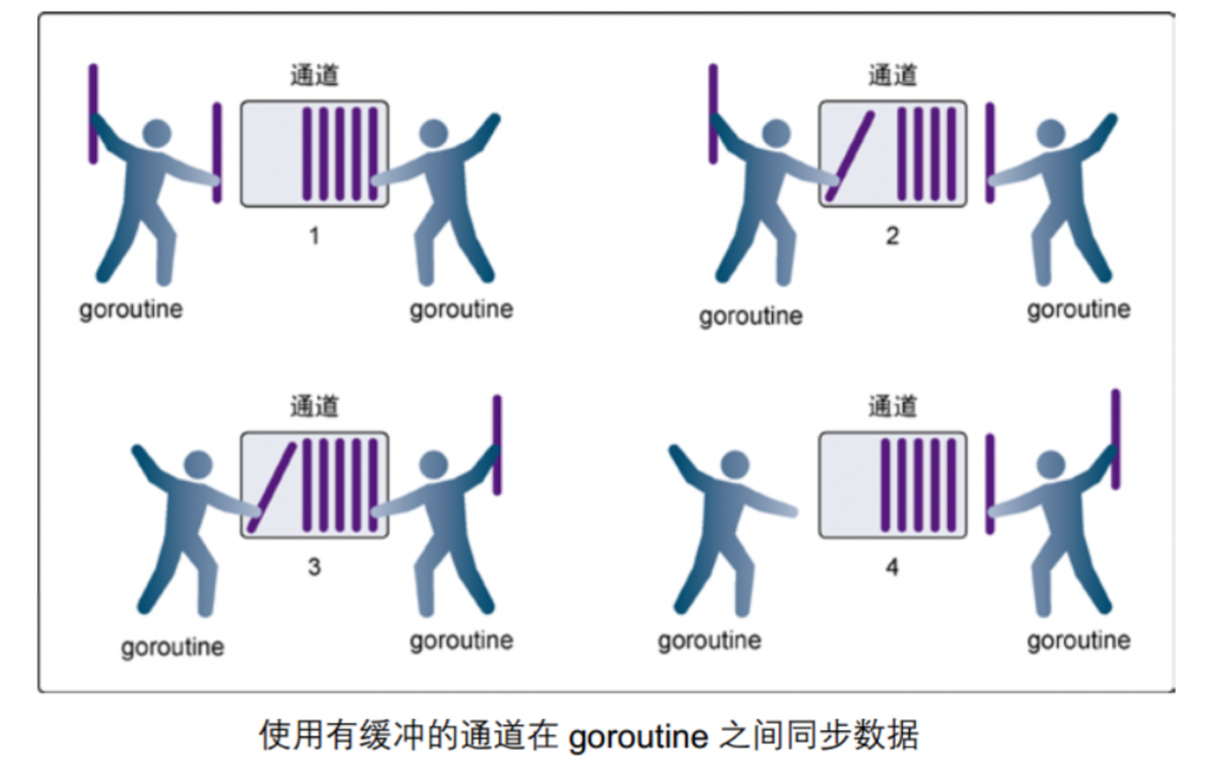
-
Step 1, the goroutine on the right is receiving a value from the channel.
-
Step 2, the goroutine on the right completes the action of receiving values independently, and the goroutine on the left is sending a new value to the channel.
-
Step 3, the goroutine on the left is still sending a new value to the channel, The goroutine on the right is receiving another value from the channel.
The two operations of this step_are neither synchronous nor blocking each other.
-
Step 4, all send and receive are completed, Channel has more values, and there is room for more values.
Characteristic:
- When the channel is full, writing data to_will block.
- When the channel is empty, fetching data from the_side will also block.
func main() {
// channel with buffer
c := make(chan int, 3)
fmt.Println("len(c) = ", len(c), "cap(c) = ", cap(c))
go func() {
defer fmt.Println("son go End of process")
for i := 0; i < 3; i++ {
c <- i
fmt.Println("son go Elements sent while the process is running =", i, "len(c) = ", len(c), " cap(c) = ", cap((c)))
}
}()
time.Sleep(2 * time.Second)
for i := 0; i < 3; i++ {
num := <-c // Receive data from c and assign it to num
fmt.Println("num = ", num)
}
fmt.Println("main End")
}
len(c) = 0 cap(c) = 3 son go Elements sent while the process is running = 0 len(c) = 1 cap(c) = 3 son go Elements sent while the process is running = 1 len(c) = 2 cap(c) = 3 son go Elements sent while the process is running = 2 len(c) = 3 cap(c) = 3 son go End of process num = 0 num = 1 num = 2 main End
In the example above, you can try to change the number of cycles of two for s to learn.
Turn off channel
func main() {
c := make(chan int)
go func() {
for i := 0; i < 5; i++ {
c <- i
}
// close closes a channel
close(c)
}()
for {
// ok means channel is not closed for true and channel is closed for false
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("Main Finished..")
}
0 1 2 3 4 Main Finished..
channel does not need to be shut down as often as a file, only if there is really no data to send, or if you want to explicitly end the range loop, etc. Note:
- Cannot send data to channel after channel is closed (causing receive to return zero immediately after a panic error is raised)
- After closing the channel, you can continue to receive data from the channel
- For nil channel, send and receive will be blocked
channel and range
func main() {
c := make(chan int)
go func() {
defer close(c)
for i := 0; i < 5; i++ {
c <- i
}
}()
// range can be used to iterate over continuous channel operations
for data := range c {
fmt.Println(data)
}
fmt.Println("Main Finished..")
}
channel and select
Selectect can be used to monitor the status of multi channel:
func fibonacii(c, quit chan int) {
x, y := 1, 1
for {
select {
case c <- x:
// If c is writable, enter the case
x, y = y, x+y
case <-quit:
// If quit is readable, enter the case
fmt.Println("quit")
return
}
}
}
func main() {
c := make(chan int)
quit := make(chan int)
// sub go
go func() {
for i := 0; i < 6; i++ {
fmt.Println(<-c)
}
quit <- 0
}()
// main go
fibonacii(c, quit)
}
1 1 2 3 5 8 quit