What is a map
The Map structure exists in many programming languages, including today's protagonist go language. Today, we will analyze the Map in go in several aspects.
In the most popular words, Map is a data structure that obtains value through key. Its underlying storage method is array. The key cannot be repeated during storage. When the key is repeated, the value is overwritten. We hash through the key, and then remainder the length of the array to get the subscript position of the key stored in the array. Finally, the key and value are assembled into a structure, Put it at the index of the array.
The structure composed of key and value is called bucket, which will be introduced below.
Use of map
// Directly declare the map and allocate memory space
var m = map[string]interface{}{"name": "leslie", "age": 18}
// Declare map var m map[string]string // Allocate memory space for map and initialize null value. The second parameter is length, or it can not be passed m = make(map[string]string, 8)
// Assign a value directly to the map
m["name"] = "leslie"
m["age"] = "18"
// Loop through each key & value pair in the map
for key, value := range m {
fmt.Println(key, value)
}
// For map value, two parameters can be returned. The first return value is the corresponding value in the map, and the second return value represents whether it exists. If ok is false, value is the default null value
value, ok := m["csdn"]
if ok {
fmt.Println(value)
}
// Delete the value whose key is csdn in the map delete(m, "csdn") // len(m) can get the element length of the current map fmt.Println(len(m))
The above are some common operations of map, which are relatively simple to master.
Bottom structure
Just now, we mentioned that the bottom layer of map is an array, and the array subscript is obtained by hash ing the key value and then de moduling the array length. The array contains a structure we call bucket, or bmap.
The source code of map is located in Src / Runtime / map In go:
//The bucket structure defines b as a bucket
type bmap{
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt values.
// NOTE: packing all the keys together and then all the values together makes the // code a bit more complicated than alternating key/value/key/value/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8.// Followed by an overflow pointer.
}
It's strange to use translation software to translate the English notes here, so we won't translate them. Here are some important information:
tophash is the hash of the upper eight bits, so the hash value is shorter. There is no need to compare the real hash value for each comparison.
At the same time, the internal kv storage is not stored in the format of k1v1,k2v2,... knvn. It's stored in k1k2k3... v1v2v3... Format.
This benefit is to prevent memory alignment and save unnecessary space overhead (~ ^ ~ particularly clever, very fine!)
The map structure is shown in the following figure:
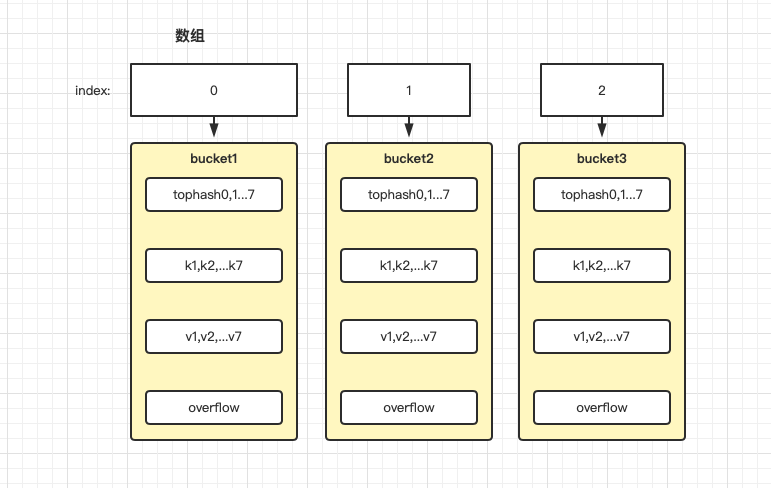
When a kv pair is stored in the map, the hash value is obtained through k. the lower eight bits of the hash value and the bucket array length are taken as the remainder to locate the subscript in the array. The upper eight bits of the hash value are stored in the tophash in the bucket to quickly judge whether the key exists. The specific values of key and value are stored through pointer operation. When a bucket is full, Link to the next bucket through the overflow pointer.
Looking at the picture here, there must be a question that not every array element corresponds to a kv, right? Why are there so many kv in the bucket? Why does the bucket still have the attribute of overflow? Why is it not enough? Don't worry, let's introduce it.
Solutions to hash conflicts
We know that hash calculation will convert an input into a string of a certain length, but it is difficult to ensure that several inputs will have the same string after hash calculation. This situation is called hash collision.
In map, there are generally two ways to resolve hash conflicts.
- Linear detection method
It starts from the conflicting subscript in sequence and then probes back. When it reaches the end of the array, it probes from the beginning of the array until an empty location is found to store the key. When the array cannot be found, it will be expanded back. This is the idea of using arrays. - Zipper method
It is simply understood as a linked list. When the hash of the key conflicts, we form a linked list on the elements at the conflict position and connect them through pointers. When looking up, we find the key conflict and look down the linked list until the tail node of the linked list. If we can't find it, it returns null. This is the implementation of our figure above. In short, after a hash conflict, it is placed in the same bucket as the previous key, and the overflow part is connected through the overflow mentioned above.
Advantages and disadvantages of both
- It can be seen from the above that zipper method is simpler than linear detection
- Linear detection and search will be blocked by zipper method, which will consume more time
- Linear detection will more easily lead to capacity expansion, while zippers will not
- The zipper stores pointers, so it takes up a little more space than linear detection
- The zipper applies for storage space dynamically, so it is more suitable for uncertain chain length