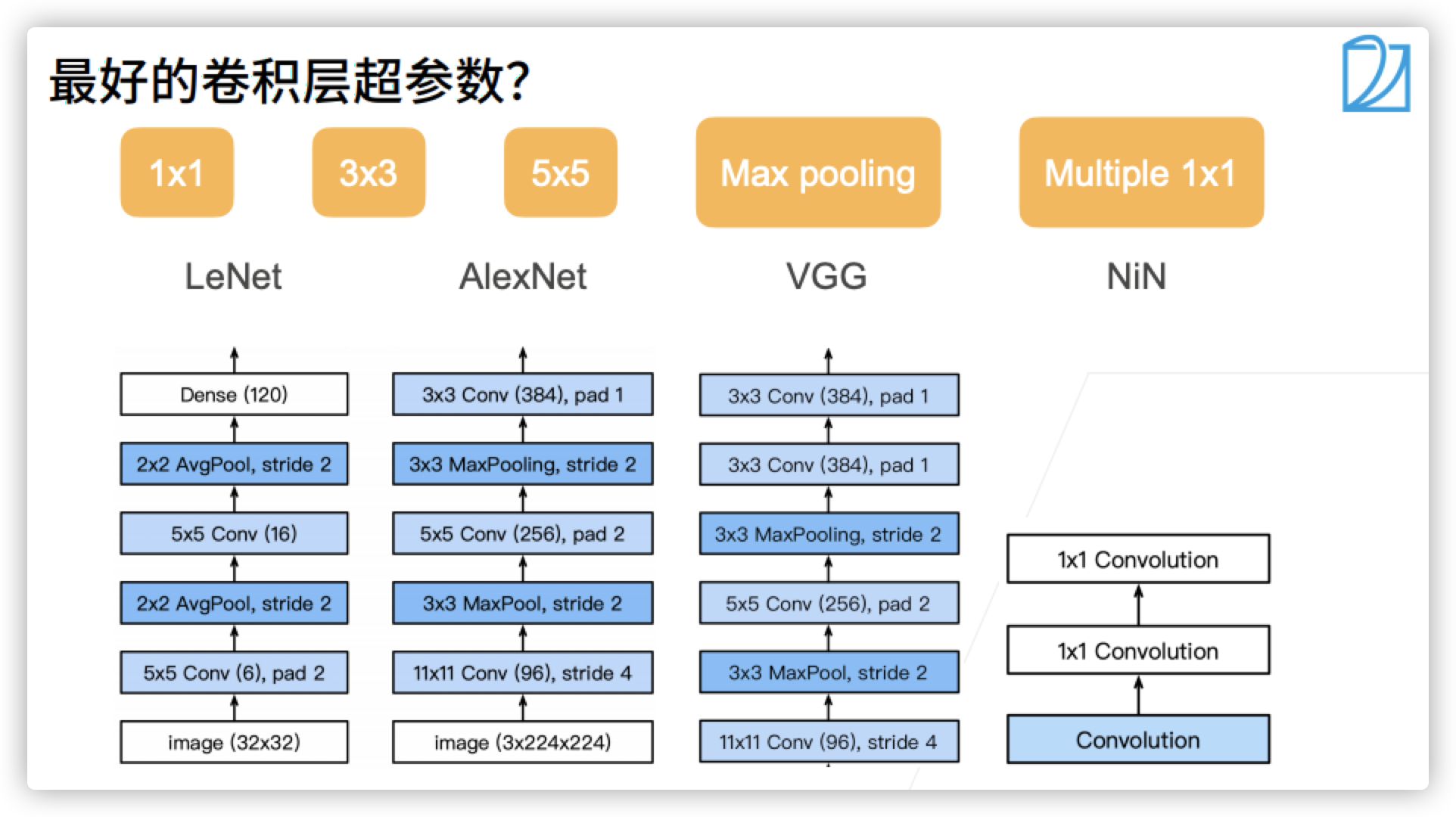
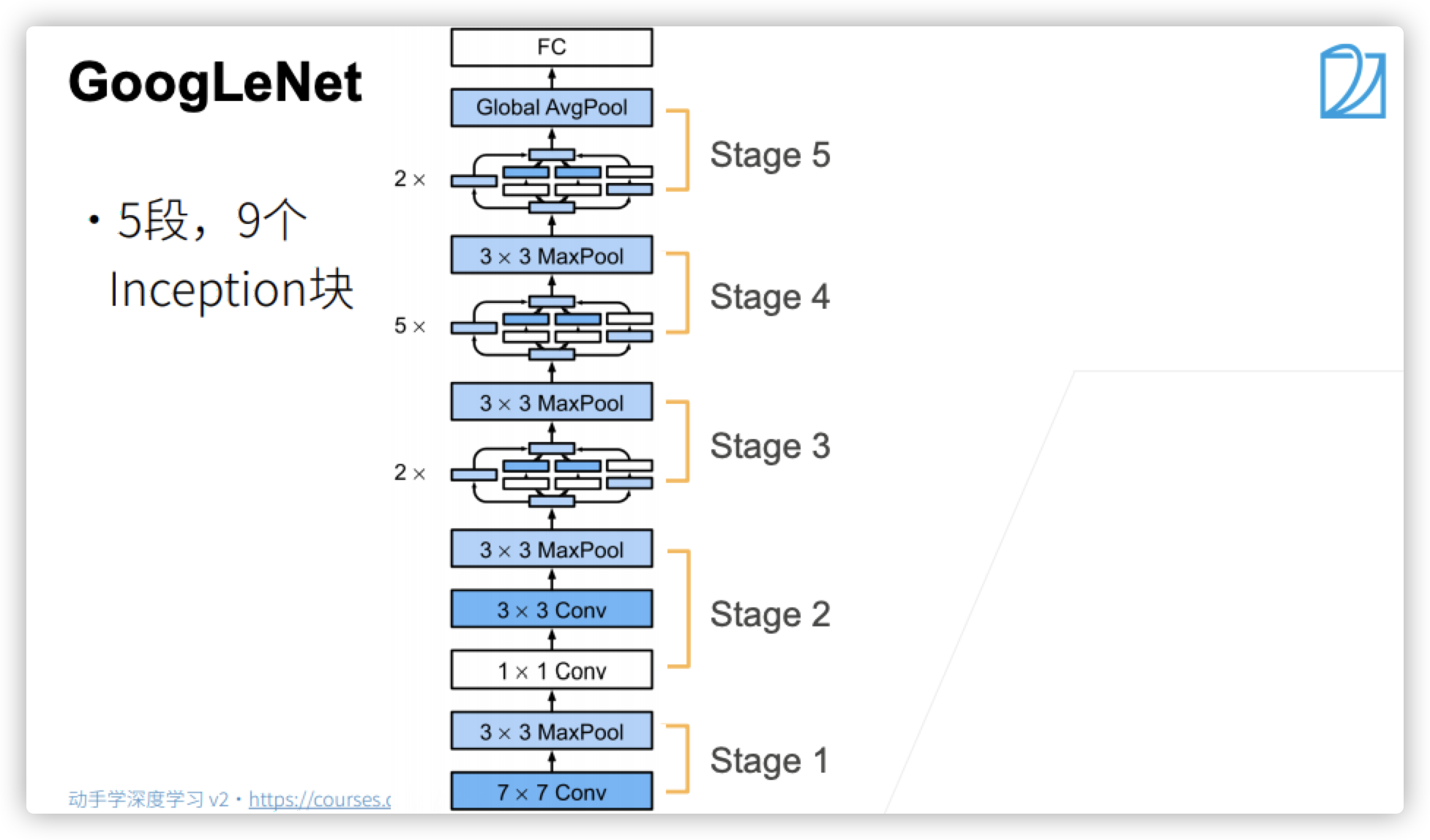
GoogLeNet
- Earlier, we learned some classic neural networks. We don't have to ask a question, why do we do this and why do we do that?
Concept block: only primary school students do multiple-choice questions. I want them all
-
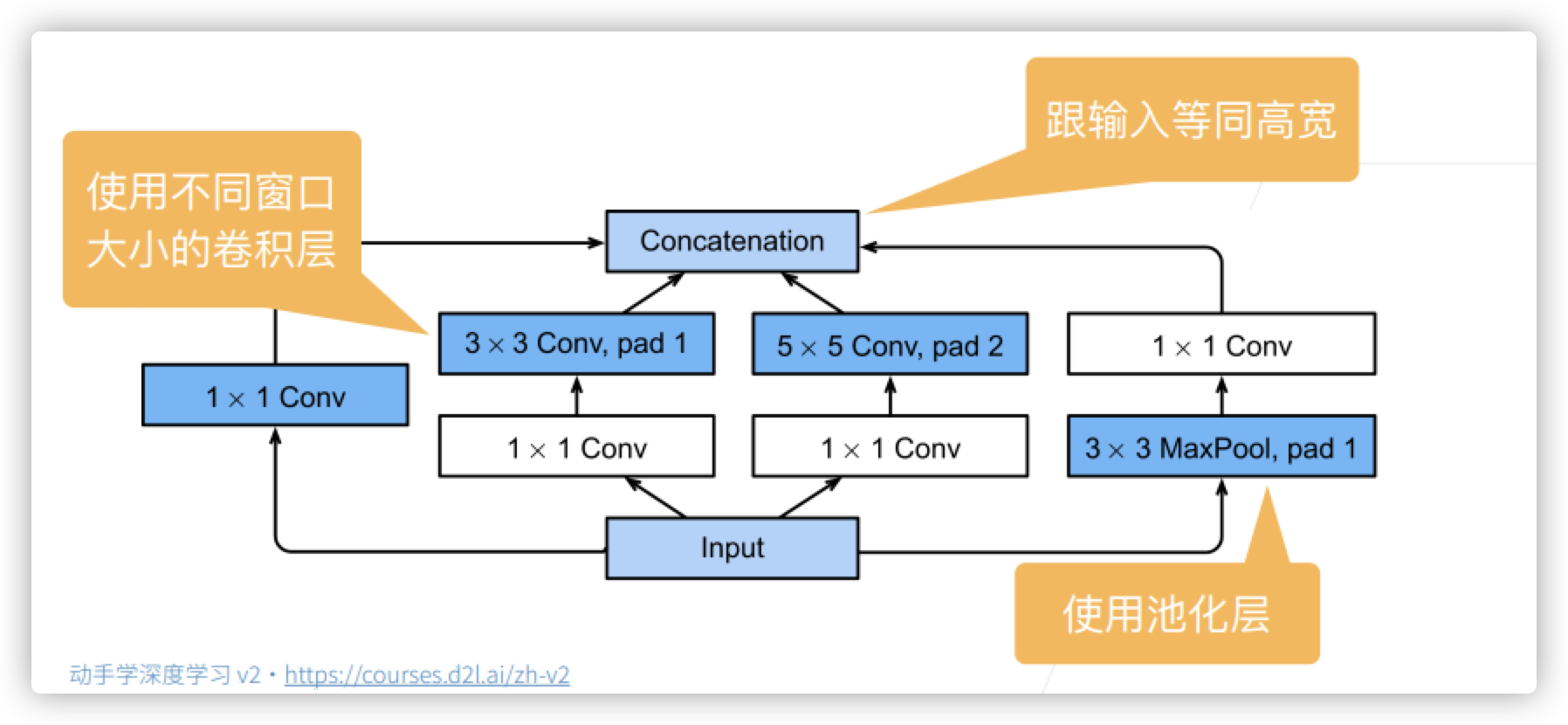
The four paths extract information from different levels, and then merge in the output channel dimension. It means that different blocks have different channels and put everything we want in them.
-
What the Inception block is doing: make the input copy into four blocks. The first path is connected to a 1 * 1 convolution layer and then output to Concatenation. The second way is to transform the channel through a 1 * 1 convolution layer, and then input it to a 3 * 3 convolution layer, padding=1 Make the input and output the same height and width. The third way: first transform the channel through a 1 * 1 convolution layer, and through a 5 * 5 convolution layer, padding=2. The fourth way: first pass through a 3 * 3 MaxPool, use padding, and then add a 1 * 1 convolution layer. Then, after passing through these four roads, these are combined to stack the number of channels rather than enlarge the picture. After entering this block, the height and width remain the same, but the number of channels changes
-
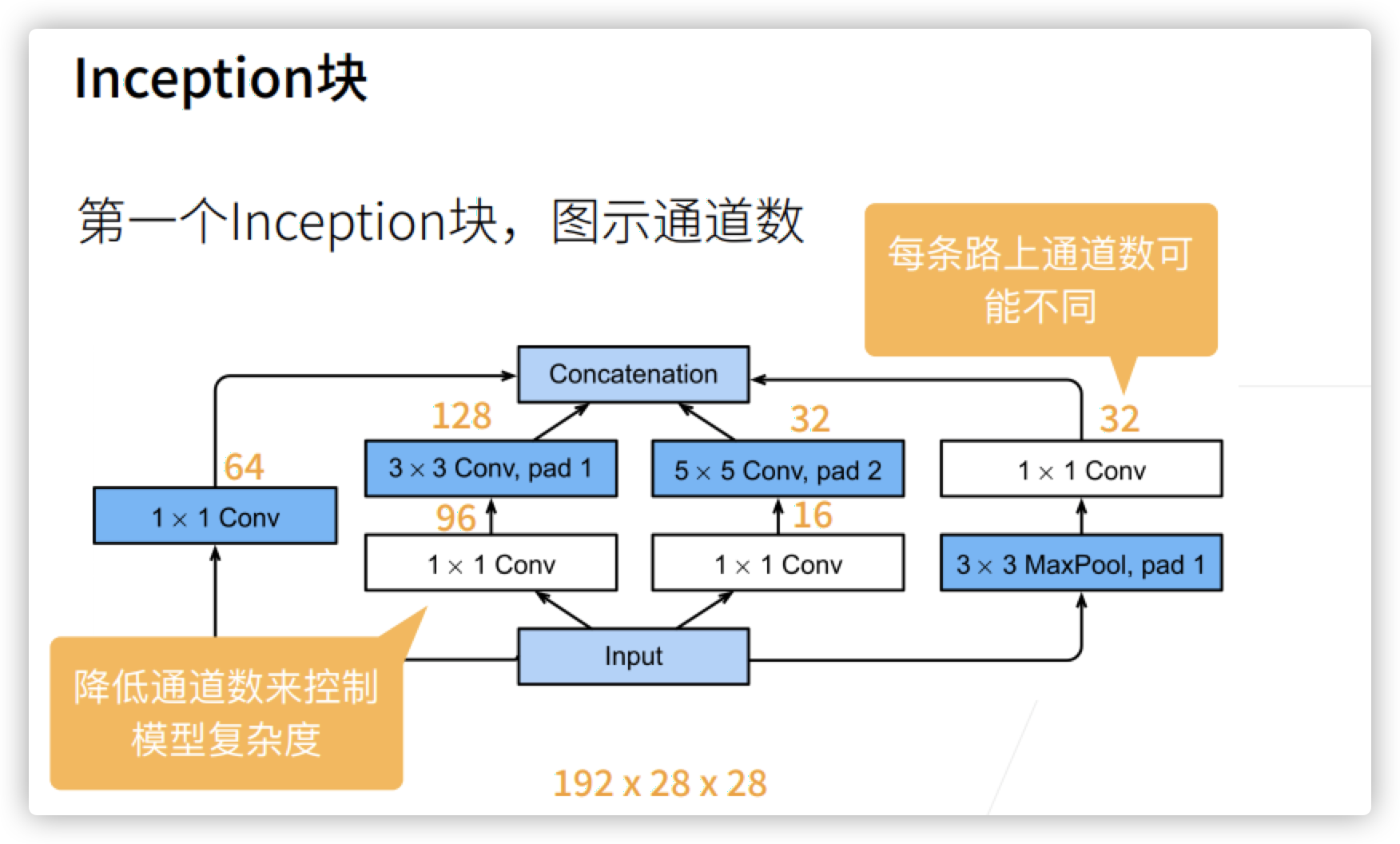
Look at the number of channels. The white box in the figure below basically changes the number of channels. The blue box can be considered to be used to extract information. The final channel is 64 + 128 + 32 + 32.
-
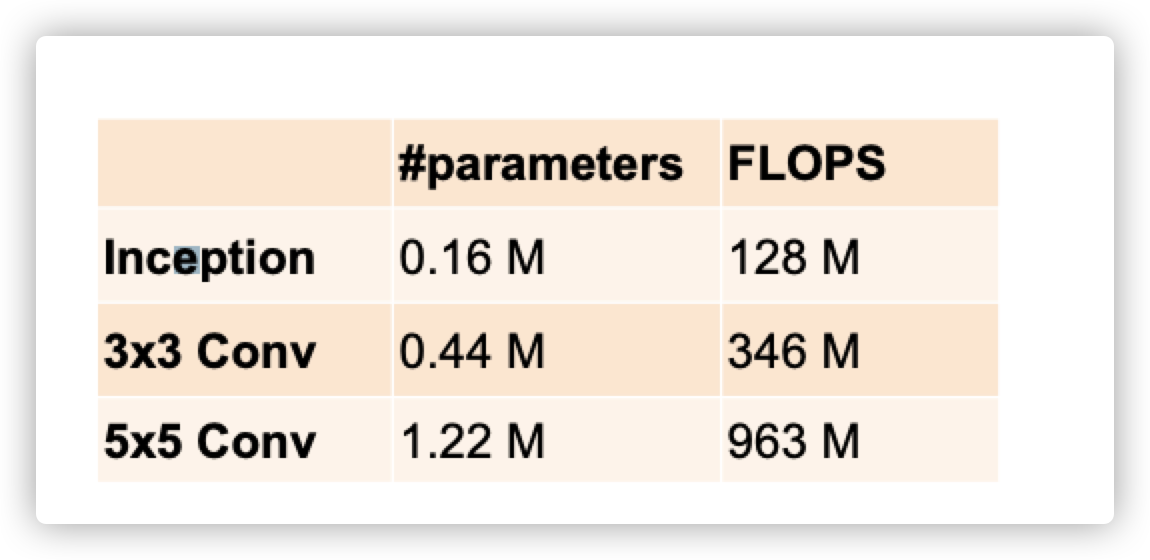
Compared with 3 * 3 or 5 * 5 convolution layers, Inception blocks have fewer parameters and computational complexity.
GoogLeNet
- Each stage here means halving the height and width. After the global average pooling layer is finally used here, a vector with the length of the number of channels will be obtained, and then mapped to the number of categories through a full connection layer.
- Stage 1&2
- Smaller windows and more channels are used
- Stage 3
- Two inception blocks are used here. After this period, the number of channels changes from 192 to 480, and the size changes from 28 * 28 to 14 * 14
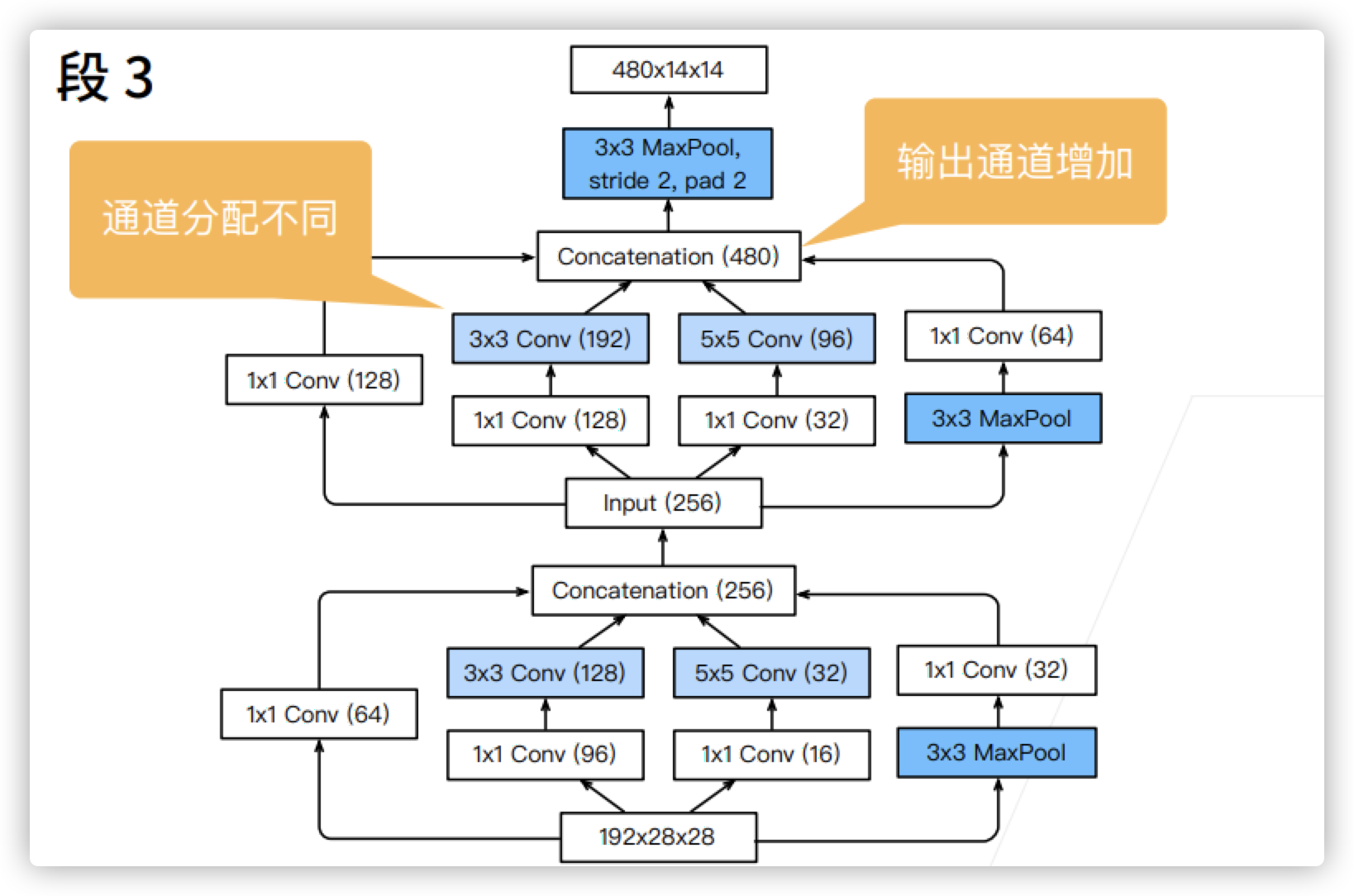
- Two inception blocks are used here. After this period, the number of channels changes from 192 to 480, and the size changes from 28 * 28 to 14 * 14
- Stage 4&5
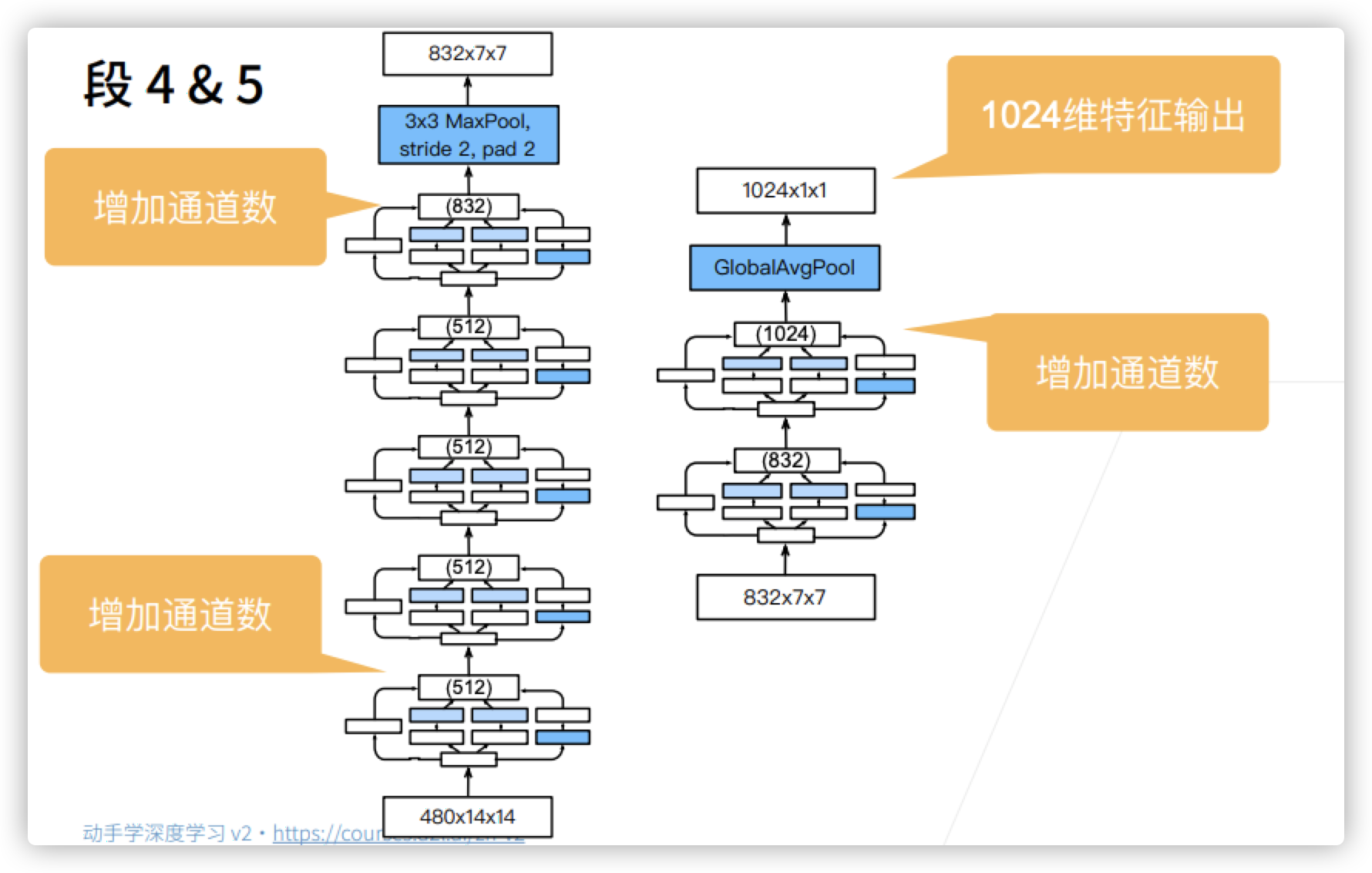
- After the above stages, the number of channels increases continuously.
Subsequent variants of Inception

- Inception V3 block, Stage 3. The right side of the figure below is the original, and so is the next figure below
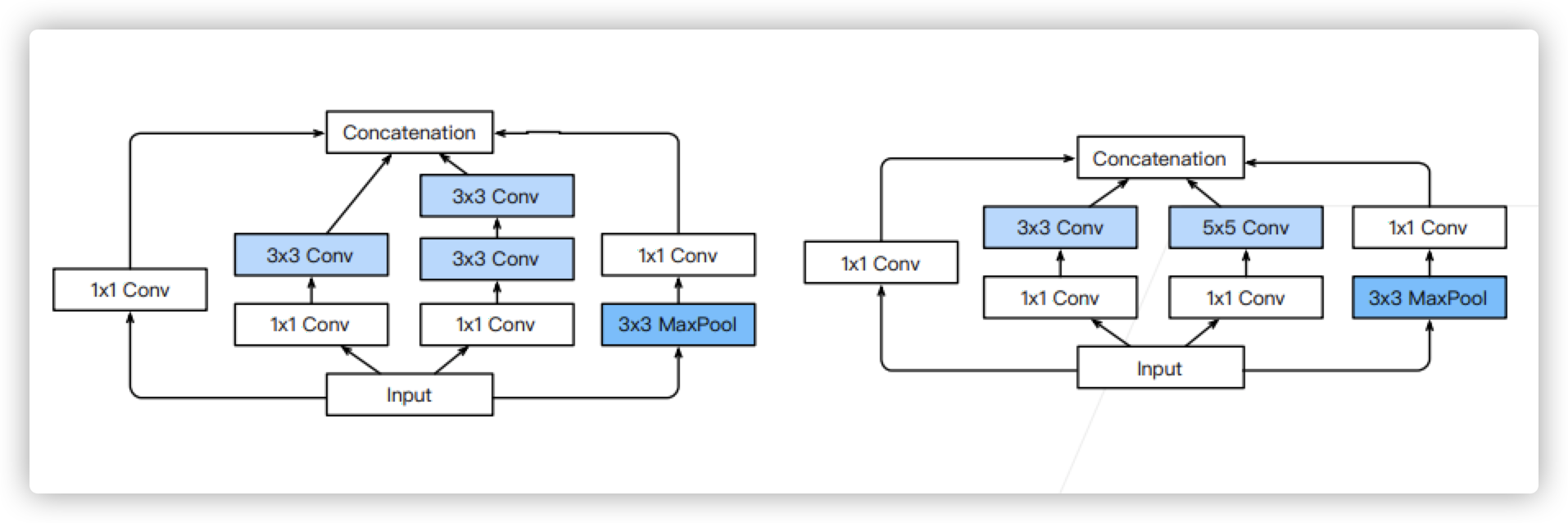
- Inception V3 block, segment 4
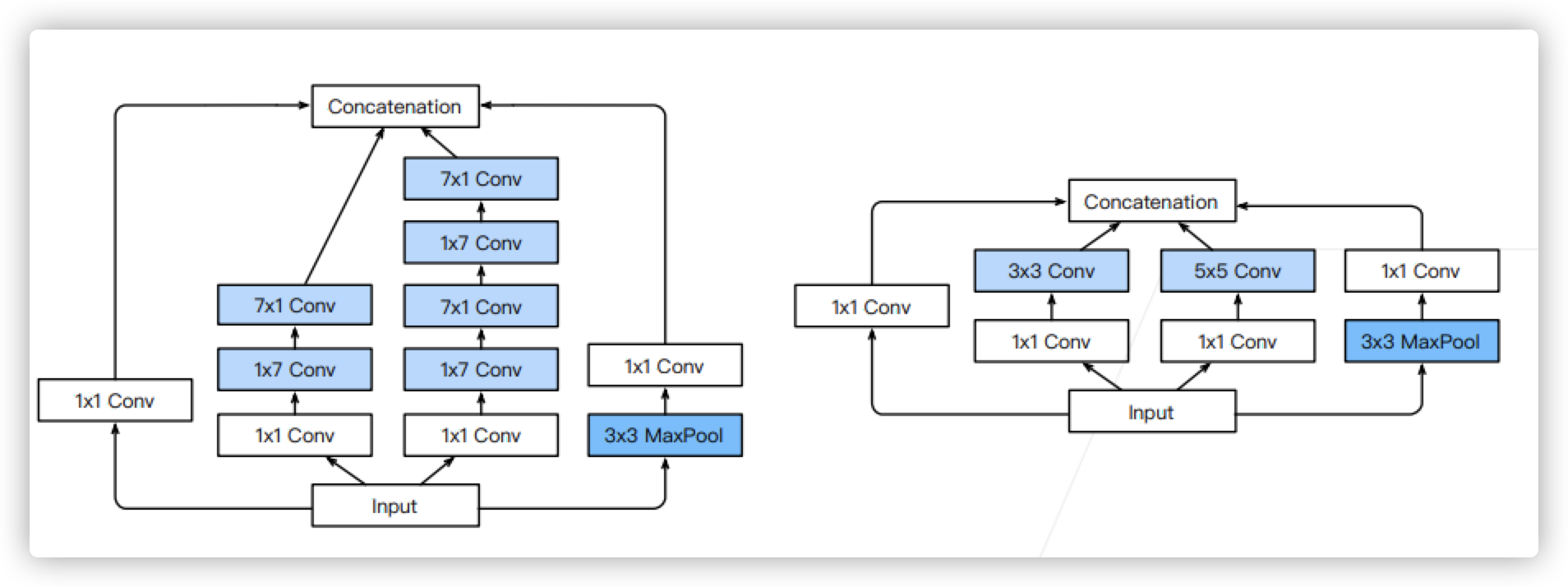
- Inception V3 Block,Stage 5
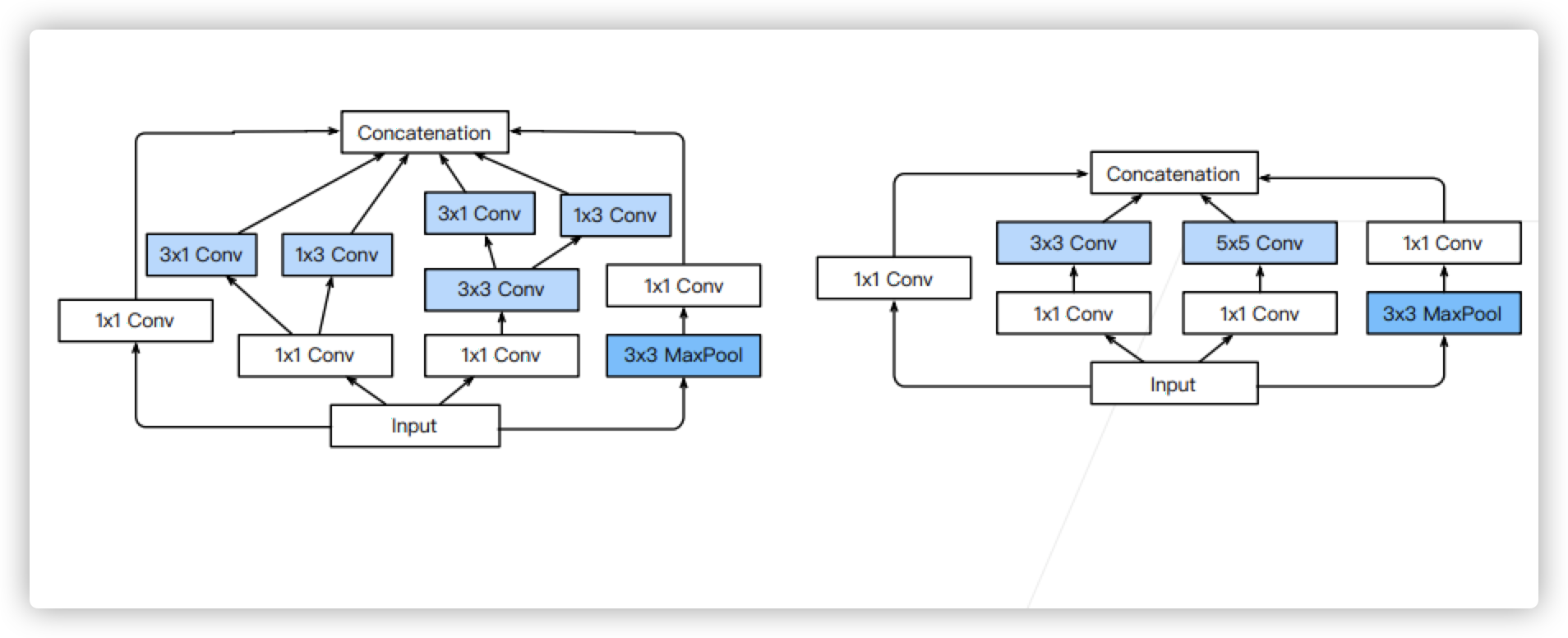
summary

code implementation
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# Create an Inception block
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1)
# Stage 1: a convolution plus a maximum pool
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 2
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 3
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 4
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 5
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 24, 24]) Sequential output shape: torch.Size([1, 192, 12, 12]) Sequential output shape: torch.Size([1, 480, 6, 6]) Sequential output shape: torch.Size([1, 832, 3, 3]) Sequential output shape: torch.Size([1, 1024]) Linear output shape: torch.Size([1, 10]) /Users/tiger/opt/anaconda3/envs/d2l-zh/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ../c10/core/TensorImpl.h:1156.) return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
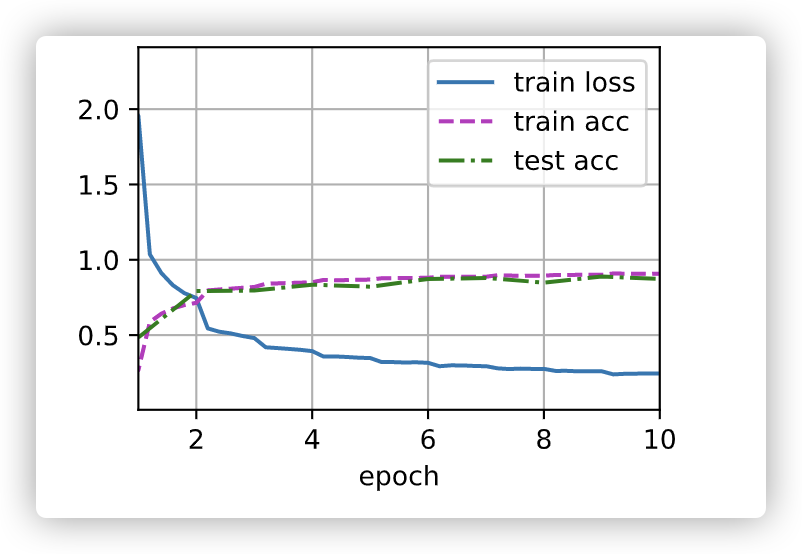
Training results
import torch
import time
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# Create an Inception block
class Inception(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1)
# Stage 1: a convolution plus a maximum pool
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 2
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 3
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 4
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Stage 5
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten())
start = time.time()
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
end = time.time()
print(f'time:\t{end - start}')
loss 0.246, train acc 0.907, test acc 0.874 484.0 examples/sec on cuda:0 time: 1352.389996767044