preface
I believe there are still many people who don't know what ebpf is or where to start. However, it seems that it is becoming a de facto standard for the technical means of cloud native development performance optimization. In particular, ebpf has great advantages in container network performance and security. Almost all cloud manufacturers spend time on the practical application of ebpf, and can't keep up with others without using ebpf. Therefore, mastering ebpf is very helpful for those who want to engage in cloud native development, performance optimization and other related work. I will not repeat the historical background and application background of ebpf. Many articles have introduced it. This article mainly tells me about some personal experience of a gopher learning ebpf. There may be something wrong with his posture. If there is a great God who can make comments or criticism, I would be grateful.
What is ebpf
ebpf is a revolutionary technology, originated from the Linux kernel, which can run sandbox programs in the operating system kernel. It is used to safely and effectively extend the functions of the kernel without changing the kernel source code or loading kernel modules. ebpf programs are event driven and run when the kernel or application passes through a hook point. Predefined hooks include system calls, function entry / exit, kernel trace points, network events, etc. In short, ebpf program is hook.
Some background knowledge about ebpf
The following contents, at the beginning, have no concept at all, and soon forget after reading. It's normal. When you forget, it's a big deal to look back.
Program type of ebpf
Simply understand that ebpf is a program that hangs on the kernel or application.
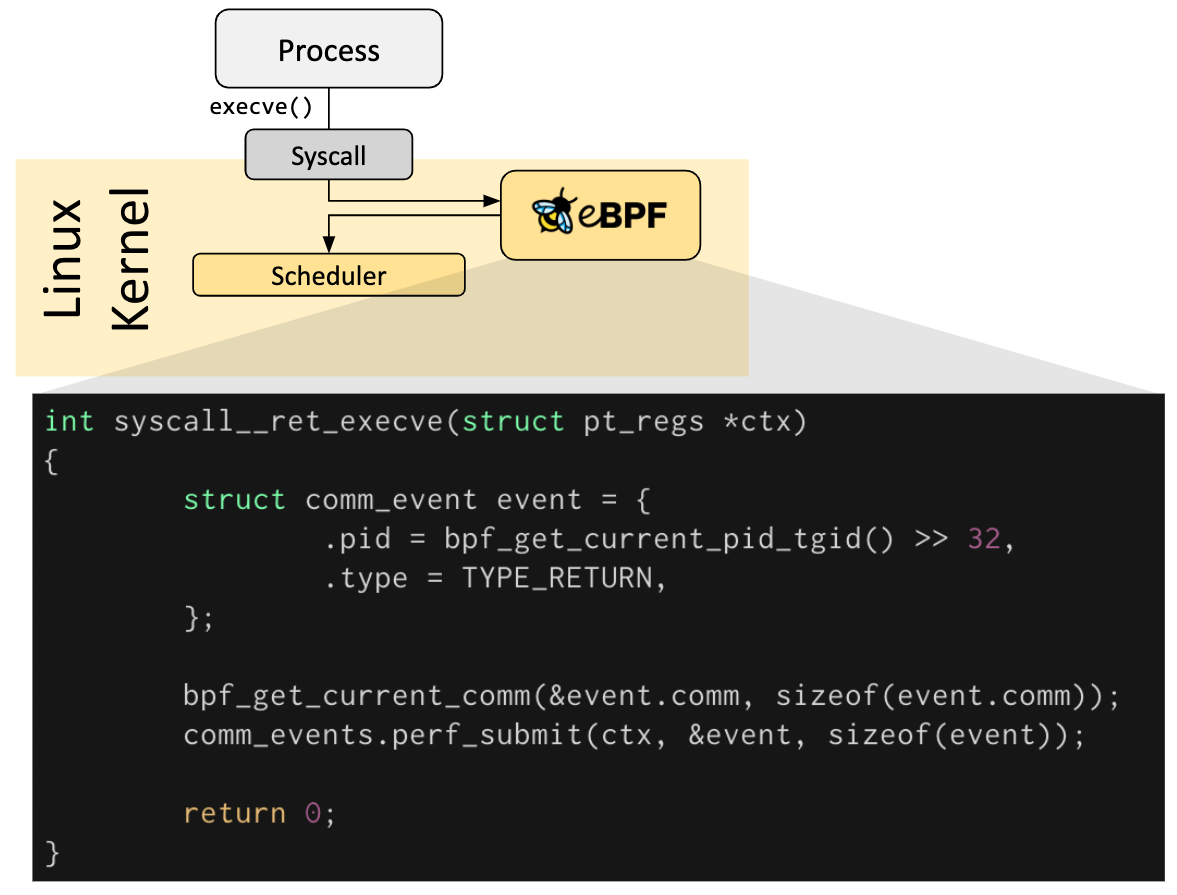
Moreover, there are types of these programs. The specific types can be viewed in the source code: ebpf program type
- XDP
- tc
- kprobe
- uretprobe
- tracepoint
There are many types of ebpf programs. It seems that these types of programs are not familiar with us. It doesn't matter. If you see more in the future, you will know that xdp program can process network data packets when they reach the network card driver layer, tc program can control traffic, and tracepoint program can perform certain actions when the kernel calls some functions. It's normal for beginners not to understand, I don't know how to write these programs.
map type of ebpf
- BPF_MAP_TYPE_HASH: hash table, key value pair
- BPF_MAP_TYPE_ARRAY: array, optimized for fast lookup speed, usually used for counters
- BPF_MAP_TYPE_PROG_ARRAY: file descriptor array corresponding to eBPF program; It is used to implement jump table and subroutine to process specific packet protocol, and the tail call is used
- BPF_MAP_TYPE_PERCPU_ARRAY: array of each CPU
- BPF_MAP_TYPE_PERF_EVENT_ARRAY: storage points to struct perf_event pointer array, which is used to read and store perf event counters
- BPF_MAP_TYPE_CGROUP_ARRAY: an array that stores control group pointers
- BPF_MAP_TYPE_PERCPU_HASH: hash table of each CPU
- BPF_MAP_TYPE_LRU_HASH: hash with elimination mechanism. Only the hash table of the most recently used items is retained
- BPF_MAP_TYPE_LRU_PERCPU_HASH: hash table of each CPU with elimination mechanism. Only the most recently used items are retained
- BPF_MAP_TYPE_LPM_TRIE: the longest prefix matching tree, which is suitable for matching IP addresses to a certain range
- BPF_MAP_TYPE_STACK_TRACE: store stack trace
- BPF_MAP_TYPE_ARRAY_OF_MAPS: map data structure in map
- BPF_MAP_TYPE_HASH_OF_MAPS: map data structure in map
- BPF_MAP_TYPE_DEVICE_MAP: used to store and find network device references
- BPF_MAP_TYPE_SOCKET_MAP: stores and finds sockets, and allows socket redirection using BPF helper functions, following BPF_SK_SKB_STREAM_VERDICT,BPF_ SK_ SKB_ STREAM_ Related to ebpf programs such as parser
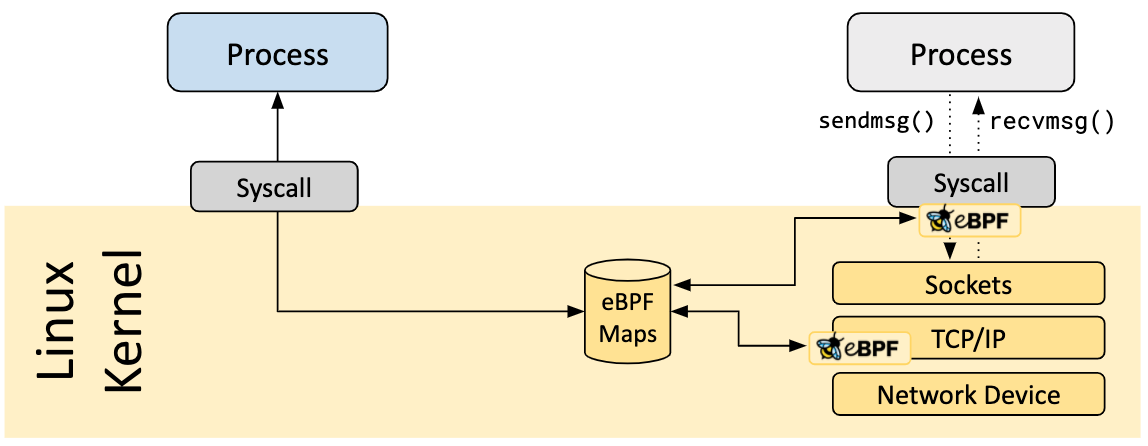
Ebpf's map is used to communicate between kernel and user space. We know that our own business programs run in user space, and the communication between user space and kernel space is generally through system call. Now we know that there is another way, this map. After reading the ebpf program type and map type, some students may feel that these words look like I know what it is, but together, I don't know what the ghost is. It doesn't matter. When we take an ebpf program to analyze it later, we will know what it is and how to use it.
Architecture of ebpf
BPF is a general-purpose RISC instruction set. The initial design purpose is to write programs with a subset of C. These programs can be compiled into BPF instructions through the compiler back-end (such as LLVM), so that the kernel can later be translated into the local opcode through the JIT compiler in the kernel, so as to achieve the best execution performance in the kernel. Generally speaking, it means that a program is written in C and then compiled into byte code in ELF format. After verification (having permission, not endangering the kernel, not endless loop, etc.), it is converted into machine specific instruction set by JIT compiler (if enabled) and loaded into the kernel.
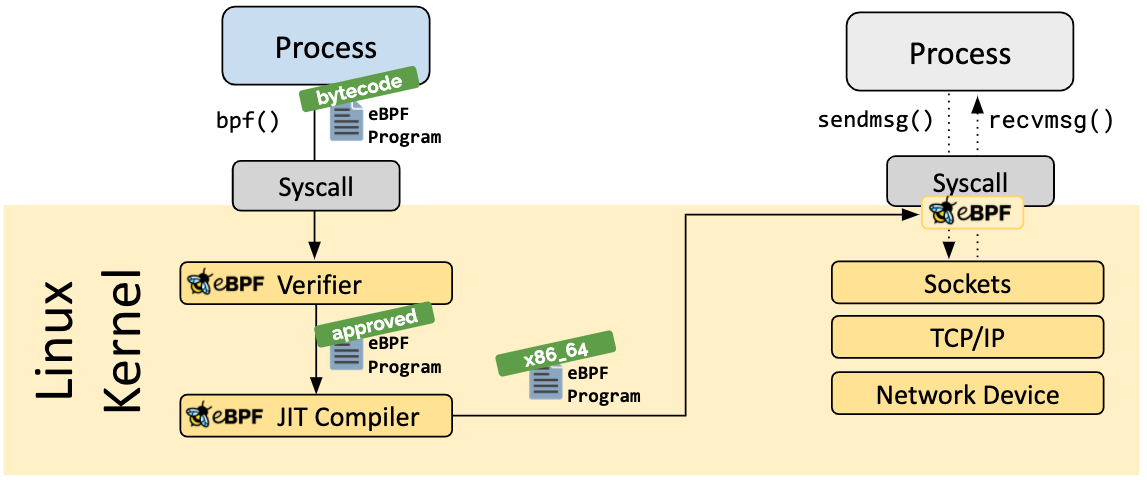
Other concepts
Such as bpf instruction system, tail call, bpf to bpf call, bpf auxiliary function and so on, I don't think it's necessary to delve into or understand the concepts at the beginning of learning, because it will be forgotten soon, and it hasn't been applied to that part at the beginning. Skip it first and check the data if necessary.
reference resources
BPF and XDP reference guide
eBPF Documentation
BPF Documentation
How can I learn ebpf
When I first came into contact with ebpf, I only knew it was awesome, but I didn't know where to start, especially for a rookie like me. Don't speak C language. go I didn't understand it. How to learn it?
I study ebpf as a language. The following points are what I consider in the process of learning:
- Try not to involve other languages. If it can be solved with go, I will resolutely not use other languages, so when I choose library tools later in development, I choose cilium/ebpf No, No bcc (for python) and other tools
- Master most grammar
- To master a language, I also need to know how to debug the program, so after I know how to write ebpf program, I also need to know how to check the debugging information and how to troubleshoot problems
- Master the application of this technology, the development of the industry, have learning channels, and know how to learn and progress
- In view of ebpf's dependence on the kernel version, this is related to ebpf's co re (create once, run everywhere). I hope the program I write can run across environments
I will try to reflect the above points in the following articles.
Build ebpf development environment
For learning a new technology, setting up the environment can be said to be the first obstacle on the way to learning. According to my research, most people will give up learning this technology because the environment is not built successfully. So my suggestion is to use virtual machine to learn. During the learning process, pay attention to backup. If you mess up the environment, you can roll back. As we all know (I mentioned earlier), ebpf depends on the kernel version, and the Linux kernel version 3.18 includes ebpf. I didn't want to get entangled with the kernel version too much, so I directly downloaded the newer version of Ubuntu. Of course, other systems can also use the following command to check their own kernel version. If the kernel version is too low, you can upgrade it:
$ uname -r 5.11.0-49-generic
My environment mainly refers to the documents of cilium. The following contents can be read directly from cilium without looking at mine file , richer.
Next, install some necessary libraries and software:
$ sudo apt-get install -y make gcc libssl-dev bc libelf-dev libcap-dev \ clang gcc-multilib llvm libncurses5-dev git pkg-config libmnl-dev bison flex \ graphviz
Compile the kernel, download the required kernel source code version, and then compile (this is not necessary, and it is not necessary to do this if the kernel version is high enough).
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git $ cd linux $ cp /boot/config-`uname -r`* .config $ make defconfig $ make -j4 $ sudo make modules_install install $ sudo update-grub2
Then restart and take effect.
Compile bpftool, which is an important tool for debugging and introspection around BPF programs and mappings. It is part of the kernel tree in tools/bpf/bpftool /.
$ cd <kernel-tree>/tools/bpf/bpftool/ $ make $ make install
In fact, I think the environment is almost finished after using the relatively new Linux version and installing llvm and clang. If you encounter other problems, solve them when you encounter them.
Start the first bpf program
I am not a person who likes system learning very much, especially as the title says, I am a gopher Xiaobai. I know little about C language and kernel development. If I learn how to develop the kernel and how to develop C language from scratch, I will run away and have the idea of giving up. I can't be too strict with a Xiaobai. What I hope is to get started immediately, see the results, and even apply it to production, which makes me boast. How do I start my first bpf program? Of course, copy and refer to other people's code. You can refer to the code of bcc and the code examples of bpf in the Linux source code. The source code of samples/bpf in the source code directory or other excellent works are learning materials. Here I take cilium/ebpf/examples The example of is slightly modified to give an example. The code is as follows:
#include "common.h"
#include "bpf_helpers.h"
char __license[] SEC("license") = "Dual MIT/GPL";
struct event_t {
u32 pid;
char str[80];
};
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
} events SEC(".maps");
SEC("uretprobe/bash_readline")
int uretprobe_bash_readline(struct pt_regs *ctx) {
struct event_t event;
event.pid = bpf_get_current_pid_tgid();
bpf_probe_read(&event.str, sizeof(event.str), (void *)PT_REGS_RC(ctx));
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU, &event, sizeof(event));
return 0;
}
Then compile it. I will use the library of cilium/ebpf to complete this work. First look at the code:
//go:build linux
// +build linux
// This program demonstrates how to attach an eBPF program to a uretprobe.
// The program will be attached to the 'readline' symbol in the binary '/bin/bash' and print out
// the line which 'readline' functions returns to the caller.
package main
import (
"bytes"
"encoding/binary"
"errors"
"log"
"os"
"os/signal"
"syscall"
"github.com/cilium/ebpf/link"
"github.com/cilium/ebpf/perf"
"github.com/cilium/ebpf/rlimit"
"golang.org/x/sys/unix"
)
// $BPF_CLANG and $BPF_CFLAGS are set by the Makefile.
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go -cc $BPF_CLANG -cflags $BPF_CFLAGS bpf ./bpf/uretprobe_example.c -- -I../headers
// An Event represents a perf event sent to userspace from the eBPF program
// running in the kernel. Note that this must match the C event_t structure,
// and that both C and Go structs must be aligned same way.
type Event struct {
PID uint32
Line [80]byte
}
const (
// The path to the ELF binary containing the function to trace.
// On some distributions, the 'readline' function is provided by a
// dynamically-linked library, so the path of the library will need
// to be specified instead, e.g. /usr/lib/libreadline.so.8.
// Use `ldd /bin/bash` to find these paths.
binPath = "/bin/bash"
symbol = "readline"
)
func main() {
stopper := make(chan os.Signal, 1)
signal.Notify(stopper, os.Interrupt, syscall.SIGTERM)
// Allow the current process to lock memory for eBPF resources.
if err := rlimit.RemoveMemlock(); err != nil {
log.Fatal(err)
}
// Load pre-compiled programs and maps into the kernel.
objs := bpfObjects{}
if err := loadBpfObjects(&objs, nil); err != nil {
log.Fatalf("loading objects: %s", err)
}
defer objs.Close()
// Open an ELF binary and read its symbols.
ex, err := link.OpenExecutable(binPath)
if err != nil {
log.Fatalf("opening executable: %s", err)
}
// Open a Uretprobe at the exit point of the symbol and attach
// the pre-compiled eBPF program to it.
up, err := ex.Uretprobe(symbol, objs.UretprobeBashReadline, nil)
if err != nil {
log.Fatalf("creating uretprobe: %s", err)
}
defer up.Close()
// Open a perf event reader from userspace on the PERF_EVENT_ARRAY map
// described in the eBPF C program.
rd, err := perf.NewReader(objs.Events, os.Getpagesize())
if err != nil {
log.Fatalf("creating perf event reader: %s", err)
}
defer rd.Close()
go func() {
// Wait for a signal and close the perf reader,
// which will interrupt rd.Read() and make the program exit.
<-stopper
log.Println("Received signal, exiting program..")
if err := rd.Close(); err != nil {
log.Fatalf("closing perf event reader: %s", err)
}
}()
log.Printf("Listening for events..")
var event Event
for {
record, err := rd.Read()
if err != nil {
if errors.Is(err, perf.ErrClosed) {
return
}
log.Printf("reading from perf event reader: %s", err)
continue
}
if record.LostSamples != 0 {
log.Printf("perf event ring buffer full, dropped %d samples", record.LostSamples)
continue
}
// Parse the perf event entry into an Event structure.
if err := binary.Read(bytes.NewBuffer(record.RawSample), binary.LittleEndian, &event); err != nil {
log.Printf("parsing perf event: %s", err)
continue
}
log.Printf("%s:%s return value: %s", binPath, symbol, unix.ByteSliceToString(event.Line[:]))
}
}
Let's look at the directory structure and compile it:
$ tree
.
├── go.mod
├── go.sum
├── headers
│ ├── bpf_helper_defs.h
│ ├── bpf_helpers.h
│ └── common.h
└── uretprobe
├── bpf
│ └── uretprobe_example.c
├── bpf_bpfeb.go
├── bpf_bpfeb.o
├── bpf_bpfel.go
├── bpf_bpfel.o
├── main.go
└── uretprobe
3 directories, 12 files
$ BPF_CLANG=clang BPF_CFLAGS="-O2 -Wall" go generate main.go
$ go build
Here's an explanation of BPF_CLANG=clang BPF_CFLAGS="-O2 -Wall" is added by me on the command line. If I directly use the makefile in the cilium example, I'll just make it directly. Then go generate main Go, which corresponds to main Go / / go: generate go run GitHub com/cilium/ebpf/cmd/bpf2go -cc $BPF_ CLANG -cflags $BPF_ CFLAGS bpf ./ bpf/uretprobe_ example. c -- -I../ Headers, which calls the tool of cilium, does two things, converts the content of C language into bytecode, and generates go files under different platforms for main Go call. We will analyze what cilium / ebpf / CMD / bpf2go did later. Let's run our program first to see the effect. Open two windows, one to run our program, and the other to send anything. You can see that our program captures the input content of another window:
$ sudo ./uretprobe 2022/01/29 17:43:04 Listening for events.. 2022/01/29 17:43:38 /bin/bash:readline return value: 2022/01/29 17:43:40 /bin/bash:readline return value: 2022/01/29 17:43:48 /bin/bash:readline return value: echo 2022/01/29 17:43:58 /bin/bash:readline return value: hello world
Let's look at the contents of / sys/kernel/tracing/trace:
tail: /sys/kernel/tracing/trace: File truncated
# tracer: nop
#
# entries-in-buffer/entries-written: 10/10 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
bash-27288 [001] d... 2139.056864: bpf_trace_printk: Hello World!
bash-27288 [002] d... 2154.118664: bpf_trace_printk: Hello World!
bash-27288 [000] d... 2199.808609: bpf_trace_printk: Hello World!
bash-27288 [001] d... 2211.306168: bpf_trace_printk: Hello World!
bash-27288 [001] d... 2228.578027: bpf_trace_printk: Hello World!
bash-28525 [002] d... 2258.128661: bpf_trace_printk: Hello World!
bash-28525 [001] d... 2407.117436: bpf_trace_printk: Hello World!
bash-28525 [001] d... 2412.014455: bpf_trace_printk: Hello World!
bash-28525 [001] d... 2412.163354: bpf_trace_printk: Hello World!
The result is in line with our expectations, so let's analyze the code next.
kernel code analysis
The first is the #include part. To be honest, I was not very familiar with C language at the beginning. So my article will be more wordy, because I "know nothing".
include
#include "common.h" #include "bpf_helpers.h"
These two files are not the header files of the system, but the relative paths of references. During compilation, "- I" specifies the headers directory. There is a problem that has bothered me for a long time. That is, how did these header files come from? This is as tricky as environmental issues. Header files should refer to files with large headers. Later, I learned that most of these header files are generated when compiling the kernel. You can put them into your own project to solve some environmental problems. Some header files still report errors when compiling, such as: fatal error: 'ASM / types For problems such as H 'file not found, it is sometimes necessary to install some delve packages at this time. There is also a more conventional way is to compile and generate some header files by yourself. Let's take a look at the readme document of Linux's own samples/bpf, which reads:
Kernel headers -------------- There are usually dependencies to header files of the current kernel. To avoid installing devel kernel headers system wide, as a normal user, simply call:: make headers_install This will creates a local "usr/include" directory in the git/build top level directory, that the make system automatically pickup first.
You can compile and generate the header file of the kernel in this way. It is recommended that you download the source code and look at this document. But goose, it's not over. After generating the header file, it makes me more confused. A bunch of header files with the same file name are generated in different directories. What's the matter, such as uapi/linux/if_ether.h and linux/if_ether.h. What's the matter? Which one do I use when I write my own code, Gan! I haven't found the right information to understand this aspect. At first, I just wanted to write a gadget with ebpf and force it. It's so complicated! Later, I found some clues in the readme document of samples/bpf mentioned above and ran it
$ make M=samples/bpf V=1 ··· clang -nostdinc -isystem /usr/lib/gcc/x86_64-linux-gnu/10/include -I./arch/x86/include -I./arch/x86/include/generated -I./include -I./arch/x86/include/uapi -I./arch/x86/include/generated/uapi -I./include/uapi -I./include/generated/uapi -include ./include/linux/kconfig.h -fno-stack-protector -g \ -Isamples/bpf -I./tools/testing/selftests/bpf/ \ -I./tools/lib/ \ -D__KERNEL__ -D__BPF_TRACING__ -Wno-unused-value -Wno-pointer-sign \ -D__TARGET_ARCH_x86 -Wno-compare-distinct-pointer-types \ -Wno-gnu-variable-sized-type-not-at-end \ -Wno-address-of-packed-member -Wno-tautological-compare \ -Wno-unknown-warning-option \ -I./samples/bpf/ -include asm_goto_workaround.h \ -O2 -emit-llvm -Xclang -disable-llvm-passes -c samples/bpf/hbm_edt_kern.c -o - | \ opt -O2 -mtriple=bpf-pc-linux | llvm-dis | \ llc -march=bpf -filetype=obj -o samples/bpf/hbm_edt_kern.o CLANG-bpf samples/bpf/xdpsock_kern.o
It's finally clear that there are so many - I in the source code. Although it's troublesome, there is a conclusion that you really have to write a lot of include yourself. Many open source projects put the system or generated header files into their own projects, so there are not so many dependencies to pay attention to when writing include or makefile.
When it comes to dependence, there's another problem here. I'll go. Can two lines of include deal with so many messy things?! The header file of the system will change slightly with the change of kernel version. This brings great challenges to the compatibility of code and environment. Therefore, there is the CO-RE concept of BPF program, which can be compiled once and run everywhere. The key of CO-RE is BTF and vmlinux h. BTF structures BPF objects (prog and map), while vmlinux H contains the structure of most system header files to generate vmlinux H command:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
Then when writing bpf code, include does not need to include so many header files, including a vmlinux Just H. But according to my attempt, vmlinux H still does not fully contain all the contents of the system header file, which leads to cutting out the contents of some header files by yourself. It's really torture. Probably bpf's CO-RE is not perfect, or my posture is wrong.
SEC
char __license[] SEC("license") = "Dual MIT/GPL";
···
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
} events SEC(".maps");
···
SEC("uretprobe/bash_readline")
Look at BPF_ helpers. Definition of SEC in H:
/*
* Helper macro to place programs, maps, license in
* different sections in elf_bpf file. Section names
* are interpreted by libbpf depending on the context (BPF programs, BPF maps,
* extern variables, etc).
* To allow use of SEC() with externs (e.g., for extern .maps declarations),
* make sure __attribute__((unused)) doesn't trigger compilation warning.
*/
#define SEC(name) \
_Pragma("GCC diagnostic push") \
_Pragma("GCC diagnostic ignored \"-Wignored-attributes\"") \
__attribute__((section(name), used)) \
_Pragma("GCC diagnostic pop") \
SEC is a macro, which is used in the compiled elf file to indicate that it is the section of bpf's program, license and map.
License: when the program uses the BPF auxiliary function provided by the kernel, the kernel will use the license section to verify whether the program is compatible with the kernel license, which is generally "GPL".
map, which has been introduced a little earlier. BPF is used in this sample code_ map_ TYPE_ PERF_ EVENT_ map of array type.
uretprobe/bash_readline, this is the most confusing part of this code. How do I know what to write here? Later, I found these after searching for information definition
static const struct bpf_sec_def section_defs[] = {
SEC_DEF("socket", SOCKET_FILTER, 0, SEC_NONE | SEC_SLOPPY_PFX),
SEC_DEF("sk_reuseport/migrate", SK_REUSEPORT, BPF_SK_REUSEPORT_SELECT_OR_MIGRATE, SEC_ATTACHABLE | SEC_SLOPPY_PFX),
SEC_DEF("sk_reuseport", SK_REUSEPORT, BPF_SK_REUSEPORT_SELECT, SEC_ATTACHABLE | SEC_SLOPPY_PFX),
SEC_DEF("kprobe/", KPROBE, 0, SEC_NONE, attach_kprobe),
SEC_DEF("uprobe/", KPROBE, 0, SEC_NONE),
SEC_DEF("kretprobe/", KPROBE, 0, SEC_NONE, attach_kprobe),
SEC_DEF("uretprobe/", KPROBE, 0, SEC_NONE),
···
Moreover, the type is a prefix, such as uretprobe / *. No matter what followed, the kernel also knows that this is a bpf program of uretprobe type. Some friends may wonder why they need so many classifications. They are really unfriendly to novices. They have to know what these types are before they know how to write them. In fact, there is no way, because bpf is actually hook, which should be hung on a node of the kernel. If you don't indicate what type of program it is, you don't know which kernel node to hang on.
int uretprobe_bash_readline(struct pt_regs *ctx) {
Many people may have questions about the parameter BPF. If they don't know what to use, they may have questions about it H this file, the document is very complete, and there are some examples/ usr/include/linux/bpf.h:
···
* SEC("kprobe/sys_open")
* void bpf_sys_open(struct pt_regs *ctx)
* {
* char buf[PATHLEN]; // PATHLEN is defined to 256
* int res = bpf_probe_read_user_str(buf, sizeof(buf),
* ctx->di);
*
* // Consume buf, for example push it to
* // userspace via bpf_perf_event_output(); we
* // can use res (the string length) as event
* // size, after checking its boundaries.
* }
···
bpf_helper
bpf_get_current_pid_tgid: returns the PID of the current program
bpf_probe_read: store kernel space data safely to the target address
bpf_perf_event_output: write data to BPF_MAP_TYPE_PERF_EVENT_ARRAY's map to interact with user space
bpf_helpers.h,bpf_helper_defs.h defines auxiliary functions related to BPF, which can help us better write BPF programs. It is worth reading through.
Summary
Although it's just a few lines of code, there are so many mysteries in it. The extension is complex and unfriendly to novices. To sum up, how to write a bpf program?
- First of all, any bpf program can determine the license first, so let's write it first;
- We also need to know what program we're going to write? It's SOCKET_FILTER or TRACEPOINT. After knowing the program type, we can go to the linux source code (samples/bpf) or other channels to find some program examples, or write them ourselves (know the input and return of the program from / usr/include/linux/bpf.h), and then we can write our own main logic;
- Some header files that may be used in the program. I don't know how to include. You can generate vmlinux h. In addition to some self copied and customized files, you can also directly specify - I with the header file of the system
After mastering the above process, you can almost write a simple bpf program. Next, let's look at how to deal with user space.
userspace code analysis
go generate
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go -cc $BPF_CLANG -cflags $BPF_CFLAGS bpf ./bpf/uretprobe_example.c -- -I../headers
The development and application of bpf program generally ("generally" refers to my understanding) is such a process:
- Write bpf program in C language;
- Compile the C language program into bytecode;
- Load the bytecode to the loading point of the kernel (of course, there are the steps of compiling the bytecode into instructions, but I'm talking about the development process, so I won't elaborate on these transparent steps);
- User space programs interact with these programs loaded into the kernel path through system calls or map s.
go generate calls bpf2go to compile the language program into bytecode, which is equivalent to clang XXX. It can also directly generate go language code, expose the interface and call it directly, which is much simpler and more convenient. Take a look at the generated code. There is a paragraph of this:
// Do not access this directly. //go:embed bpf_bpfel.o var _BpfBytes []byte
It loads the generated bytecode file into the user space, and then parses the secs such as prog and map for easy calling.
loadBpfObjects
// Load pre-compiled programs and maps into the kernel.
objs := bpfObjects{}
if err := loadBpfObjects(&objs, nil); err != nil {
log.Fatalf("loading objects: %s", err)
}
defer objs.Close()
This section is to load bpf program and map into the kernel, defer objs Close () is used to close some user space programs, such as closing files.
// Open an ELF binary and read its symbols. ex, err := link.OpenExecutable(binPath) ··· // Open a Uretprobe at the exit point of the symbol and attach // the pre-compiled eBPF program to it. up, err := ex.Uretprobe(symbol, objs.UretprobeBashReadline, nil) ···
Open the elf format file and read symbols. This step is not common to every program. Different types of programs may be different. For specific reference examples, it's easy to write.
perf.NewReader
// Open a perf event reader from userspace on the PERF_EVENT_ARRAY map // described in the eBPF C program. rd, err := perf.NewReader(objs.Events, os.Getpagesize())
Then there is the interaction between kernel program and user space program. The interaction of this program is through PERF_EVENT_ARRAY map. The rest is to read data from this map:
var event Event
for {
record, err := rd.Read()
if err != nil {
if errors.Is(err, perf.ErrClosed) {
return
}
log.Printf("reading from perf event reader: %s", err)
continue
}
if record.LostSamples != 0 {
log.Printf("perf event ring buffer full, dropped %d samples", record.LostSamples)
continue
}
// Parse the perf event entry into an Event structure.
if err := binary.Read(bytes.NewBuffer(record.RawSample), binary.LittleEndian, &event); err != nil {
log.Printf("parsing perf event: %s", err)
continue
}
log.Printf("%s:%s return value: %s", binPath, symbol, unix.ByteSliceToString(event.Line[:]))
}
Summary
User space code returns to go language, so it looks friendly and easy to understand. The development process is also summarized above, which will not be repeated here. Basically, at this stage, you can master the introduction of developing and applying bpf programs even if you don't know anything (don't know the kernel or even C) (I think it should be possible). Add link description
miscellaneous
When using the bpf2go tool, there is no way to specify the ready-made bytecode file. The only way is to compile the bytecode from the C language program and then generate the go file. For example:
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go -cc $BPF_CLANG -cflags $BPF_CFLAGS bpf ./bpf/kprobe_example.c -- -I../headers
When I have many parameters to specify in go generate, it will become a long line and look messy. Therefore, I want to separate the two steps of compiling and converting into go files. So I fork cilium/ebpf can specify bytecode files to generate go files. The usage is very simple. Only one parameter - objfile is added, and the others remain unchanged. However, there is no need to compile, so the compiled parameters do not need to be added. Examples are as follows:
//go:generate $GOPATH/bin/bpf2go -objfile collect_bpefel.o -target bpfel collect ../c/collect/collect.c
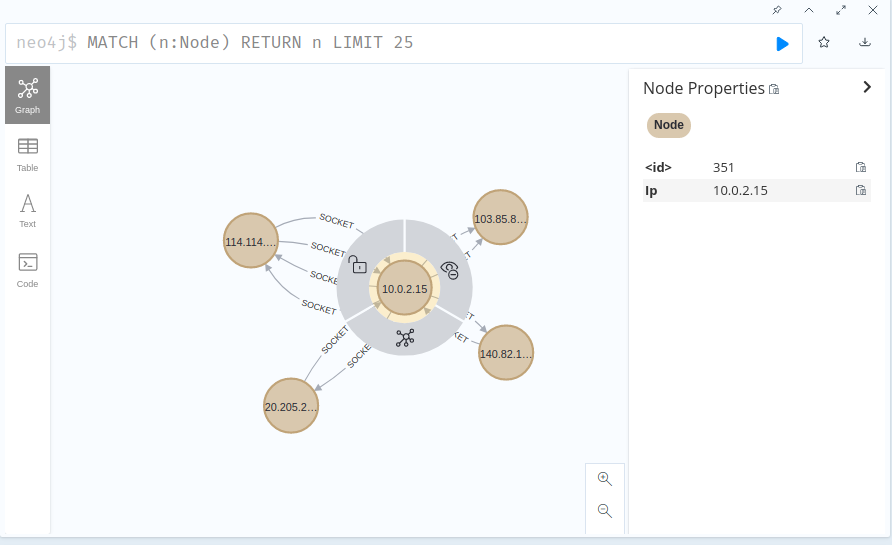
There are not many examples of raw socket s in cilium/ebpf, and they are not written together in examples. I guess they are not very perfect. I wrote an example myself, which uses the ability of ebpf to monitor the traffic of the specified network card to achieve the purpose of bypass detection of traffic, and uses the graph database neo4j to save the traffic relationship between nodes. If necessary, you can refer to the following applications: https://github.com/TomatoMr/watch-dog
summary
Generally speaking, this article is disorderly. It's not easy to keep up with where you think and write. However, this article should be regarded as a relatively complete introduction to the development process of ebpf from 0 to 1. There are many kinds of ebpf programs, which need to be further studied. This paper only briefly introduces one of them. It is so lengthy and normal. After all, it is related to the kernel. The program is not very long, but the coverage of knowledge is very wide. To continue to learn bpf related knowledge, I think we can pay attention to ebpf IO and the articles of various technical gods and manufacturers mentioned in the official website.