1, Introduction to goroutine Foundation
goroutine is a coroutine in Golang. It is a micro thread, which consumes less resources than threads. The function of thread is to carry out concurrency or parallelism, and make full use of the resources of computer multi-core.
- Concurrent multiple tasks run on one cpu, only one task is processed at a certain time, and the time of switching back and forth between tasks is very short
- Parallel multiple tasks run on multiple CPUs, and multiple CPUs process multiple tasks at a certain time to achieve the effect of parallel
So how to use goroutine in Golang? Multiple coprocesses can be started in the main thread of Golang. For example, there is a case:
- The main thread starts a coroutine to output "Hello goroutine" every 1 second and outputs it 10 times
- The main thread outputs "Hello main" every 1 second and outputs it 10 times
- The main thread and the coroutine work at the same time
package main import ( "fmt" "time" ) func printGoroutine() { // Co process execution function for i := 0; i < 5; i++ { time.Sleep(time.Second) fmt.Printf("Hello goroutine %v \n", i) } } func main() { // Main thread // Start a collaborative process go printGoroutine() // Continue to execute the main process code for i := 0; i < 5; i++ { time.Sleep(time.Second) fmt.Printf("Hello main %v \n", i) } } /* Output: Hello main 0 Hello goroutine 0 Hello goroutine 1 Hello main 1 Hello main 2 Hello goroutine 2 Hello goroutine 3 Hello main 3 Hello main 4 */
You can see that the main thread and the coroutine work at the same time. The flow chart is as follows:
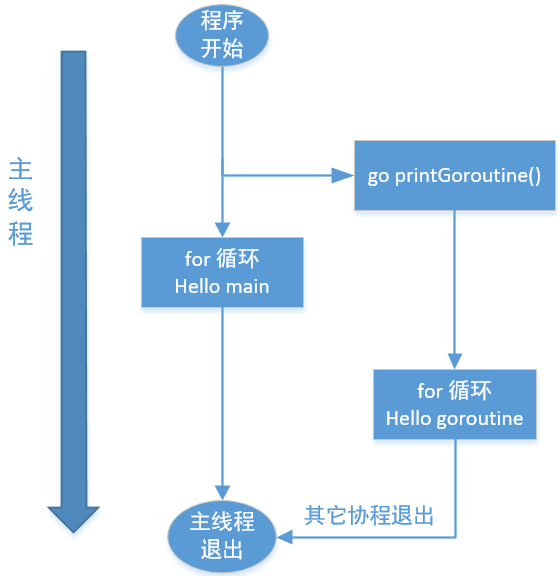
- Once the go command is passed, it is equivalent to starting a co process, which is synchronized with the main thread, and it is equivalent to starting another branch in the main thread
- If the main thread ends, other coroutines will end even if they have not finished executing
- A coroutine can also complete its own task before the end of the main thread
- Thread startup directly affects the physical level cpu, which is very resource-consuming, and the collaborative process can easily control millions of levels
2, Synchronization
(1) WaitGroup
An obvious problem in the above example is that printGoroutine should be printed five times, but it is obviously missing one time. Why? In fact, it is obvious in the figure that if the main running in the main collaboration process ends, the rest of the collaboration process will be terminated, so how to terminate the main collaboration process after all the collaboration processes are completed is a very important thing.
sync.WaitGroup can solve this problem by stating:
var wg sync.WaitGroup
After that, the wg variable can be used normally. This type has three pointer methods, Add, Done and Wait
sync.WaitGroup is a structure type with a count field inside. When sync After a variable of waitgroup type is declared, when the value of this field is 0, you can increase or decrease the count value through the Add method. And this value is the number of started processes.
The Wait method is used to block the goroutine calling it until the count value is 0.
package main import ( "fmt" "sync" "time" ) var wg sync.WaitGroup func printGoroutine() { // Co process execution function defer wg.Done() // Every time the process is executed, Add Parameter in minus 1 for i := 0; i < 5; i++ { time.Sleep(time.Second) fmt.Printf("Hello goroutine %v \n", i) } } func main() { // Running in the main coordination process main function // Start a collaborative process wg.Add(1) // Add The parameter in is the number of open processes go printGoroutine() // Continue to execute the main process code for i := 0; i < 5; i++ { time.Sleep(time.Second) fmt.Printf("Hello main %v \n", i) } wg.Wait() // Block until Add The parameter in changes to 0 to end the main collaboration } /* Output: Hello main 0 Hello goroutine 0 Hello goroutine 1 Hello main 1 Hello main 2 Hello goroutine 2 Hello goroutine 3 Hello main 3 Hello main 4 Hello goroutine 4 */
You can see the output result. One more line will be output. The main process will wait until all the processes are executed.
(2) Lock mechanism
1. Problem introduction
Data security issues will be involved in the concurrent operation of multiple processes, such as:
package main import ( "fmt" "sync" ) var num int var wg sync.WaitGroup func sub() { defer wg.Done() for i := 0; i < 100000; i++ { num -= 1 } } func add() { defer wg.Done() for i := 0; i < 100000; i++ { num += 1 } } func main() { wg.Add(2) // Start two coroutines, plus 1 and minus 1 respectively go add() go sub() // At this time, wait for the execution of the two cooperation processes to be completed wg.Wait() // Then execute the logic of the main process fmt.Println(num) }
The above output result should be 0, because one function increases and one function decreases, but the result is not the expected result at all. The result of each execution is different:
PS D:\go_practice\go_tutorial\day19\MutexDemo01> go run .\main.go -36503 PS D:\go_practice\go_tutorial\day19\MutexDemo01> go run .\main.go -60812 PS D:\go_practice\go_tutorial\day19\MutexDemo01> go run .\main.go -47786 PS D:\go_practice\go_tutorial\day19\MutexDemo01> go run .\main.go 89516 PS D:\go_practice\go_tutorial\day19\MutexDemo01> go run .\main.go -97086
Then why? This is because of the resource competition caused by multiple collaborative processes:
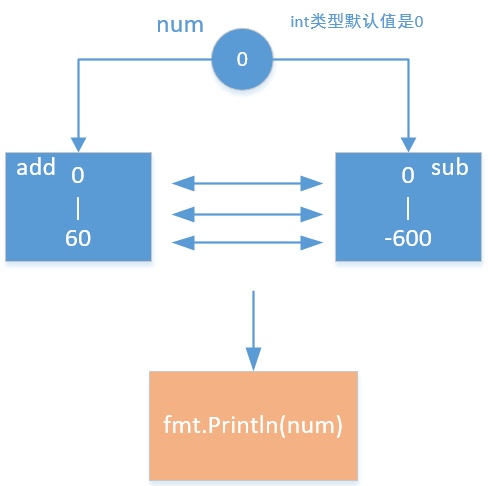
Because the two processes operate on num at the same time, the number that the two processes may get is 0. At this time, the add function adds it. If it is added to 6000, and the subtraction is constantly operating on num, the obtained num may be 6000; On the contrary, the num of add may also obtain the value of the sub function, which is a negative number. Therefore, the value of num is uncontrollable. So how to solve this problem?
Locks can be used in Go, which are divided into:
- mutex
- Read write lock
2. Mutex
Mutexes control the access of shared resources in concurrent programs. They appear in pairs, i.e. Lock and Unlock. Only when a coroutine obtains the Lock can it execute the following code block.
package main import ( "fmt" "sync" ) var num int var wg sync.WaitGroup var lock sync.Mutex // Declare a mutex variable func sub() { defer wg.Done() for i := 0; i < 100000; i++ { lock.Lock() // Lock. Currently, only this collaboration can be executed num -= 1 lock.Unlock() // Unlock } } func add() { defer wg.Done() for i := 0; i < 100000; i++ { lock.Lock() // Lock when reading data, because there may be resource competition at this time num += 1 lock.Unlock() } } func main() { wg.Add(2) // Start two coroutines, plus 1 and minus 1 respectively go add() go sub() // At this time, wait for the execution of the two cooperation processes to be completed wg.Wait() // Then execute the logic of the main process fmt.Println(num) }
In the previous code, if mutex can solve the problem, why should mutex be added to the reading place? Because there may be competition for resources. Syntax of mutex:
... var lock sync.Mutex // Declare a mutex variable func main() { ... lock.Lock() // Lock. Currently, only this collaboration is executed ... Code block ... lock.Unlock() // Unlock }
The mutex needle is a write operation for the above-mentioned operations, which can safely solve this problem. However, if it is a read-write hybrid, its strength is relatively large, which is easy to affect the performance of the program. The read operation will not affect the data change, so it can be read by multiple people at the same time, and the above mutex can only be read or written by one process at the same time. Therefore, this problem can be solved by using read-write lock. Then the following example is used to demonstrate the read-write lock, reading data and writing data at the same time.
2. Read write lock
Read / write lock is a mutex for read / write operations. Its difference from ordinary mutex is that it can lock and unlock read operations and write operations respectively. It allows any read operation to be carried out at the same time, but it only allows one write operation to be carried out at the same time, and the read operation is not allowed when the write operation is carried out. in other words. Multiple write operations in a read / write lock are mutually exclusive, and write operations and read operations are mutually exclusive - but There is no mutually exclusive relationship between multiple read operations. This can greatly improve the performance of the program.
Usage syntax:
var rwlock sync.RWMutex // Declare a read-write lock variable func read() { rwlock.RLock() .... ... rwlock.RUnlock() } func write() { rwlock.Lock() .... ... rwlock.Unlock() }
The following is an example of a read-write lock:
package main import ( "fmt" "sync" "time" ) var mapNum = make(map[int]int, 50) var wg sync.WaitGroup var rwlock sync.RWMutex // Declare a read-write lock variable func write() { defer wg.Done() rwlock.Lock() fmt.Printf("Write data\n") time.Sleep(time.Second * 2) fmt.Printf("Write end\n") rwlock.Unlock() } func read() { defer wg.Done() rwlock.RLock() fmt.Printf("Read data\n") time.Sleep(time.Second) fmt.Printf("End of reading\n") rwlock.RUnlock() } func main() { // Start 10 reads and 10 writes wg.Add(22) for i := 0; i < 20; i++ { go write() } for i := 0; i < 2; i++ { go read() } // At this time, wait for the completion of 20 collaborative processes wg.Wait() } /* Write data Write end Read data Read data End of reading End of reading Write data Write end Write data Write end Write data Write end Write data */
It can be seen from the output that when writing data, write first and then end, while reading data can be multiple concurrent at the same time.