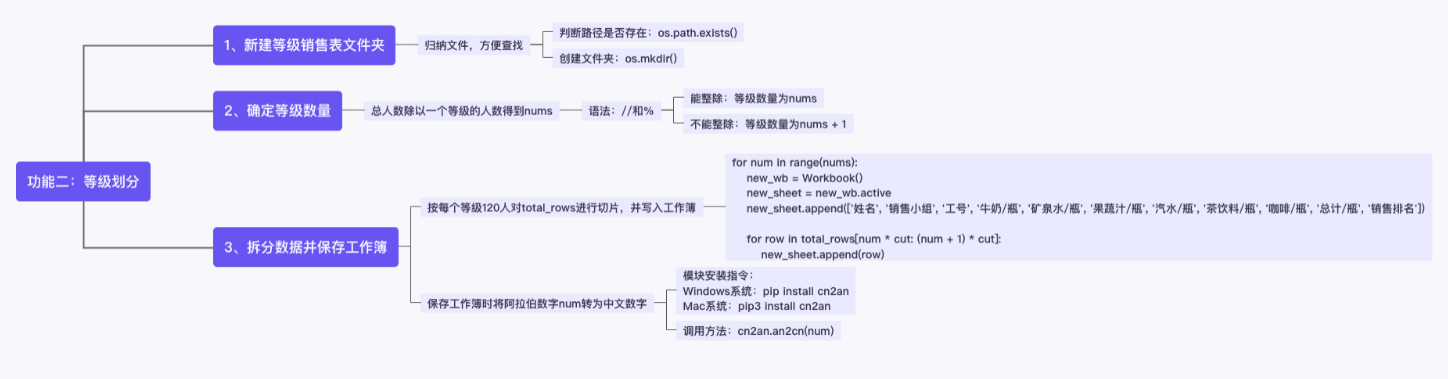
We're going to start learning how to grade. To realize this function, you have to learn five new knowledge points, namely OS path. exists(),os.mkdir(), arithmetic operators / /,% and cn2an an2cn()
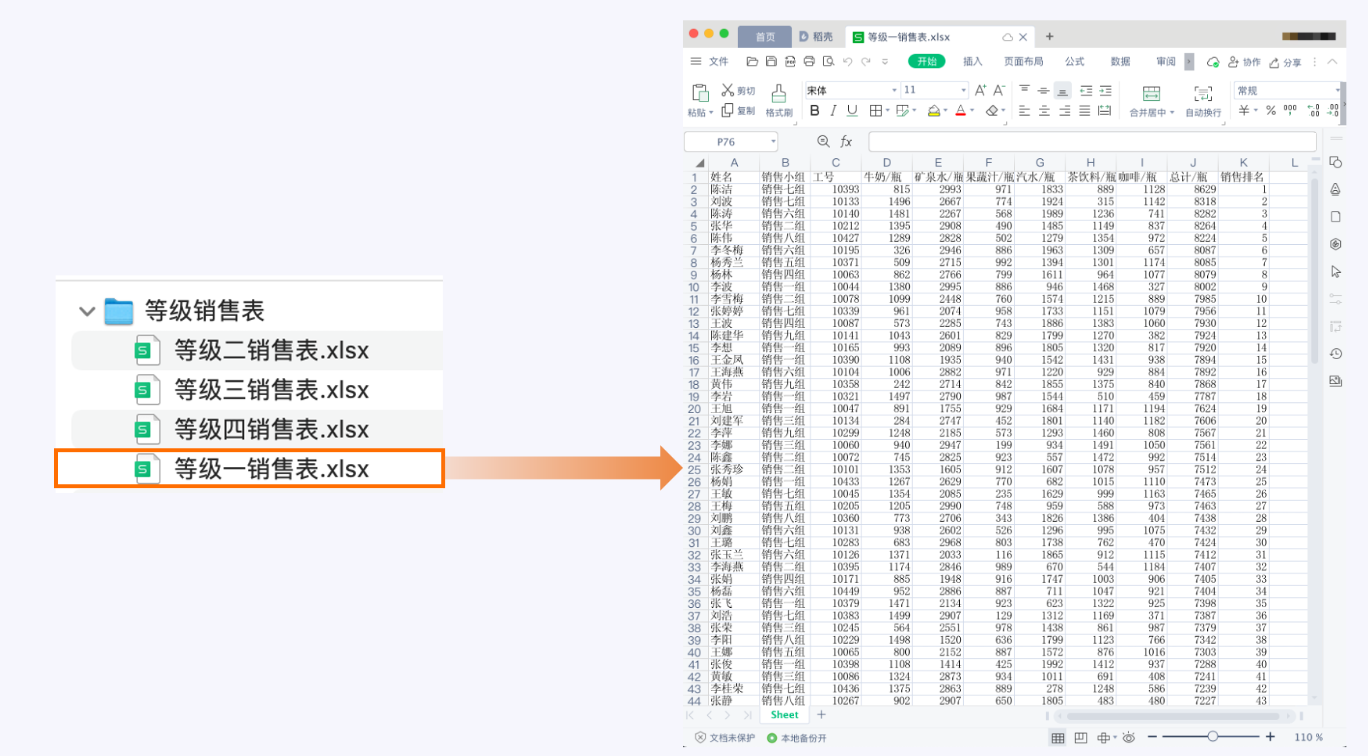
In this function, we need to split the [general sales table. xlsx] into [level x sales table. xlsx] according to the sales ranking and place it in the [level sales table] folder, in which 120 people are a level.
According to the description of the grading function in the project overview, it can be summarized into the following three small steps:
1) Create a new [level sales table] folder to store the generated [level x sales table. xlsx];
2) Split the [general sales table. xlsx] according to the "sales ranking" column, one level for every 120 people, and determine the level quantity;
3) Create a corresponding number of workbooks according to the level quantity, write the personnel sales and ranking data of each level from the beginning to the back, and save it as [level x sales table. xlsx], where x is the corresponding level.

2 classification
2.1 create a new level sales table folder
After grading, multiple new workbooks will inevitably appear. If they are still stored in the same directory as the [general sales table. xlsx] and [sales data] folders, it will be inconvenient to find files.
In order to better summarize files, you can create a folder to store new workbooks before splitting. Here, you need OS path. Exists() and OS Mkdir() these two new knowledge points.
Exists means "being", OS path. As the name suggests, exists() is used to judge whether the path exists. What is written in parentheses is the path of the file / folder. If the path exists, it returns True. If it does not exist, it returns False.
import os
# The test folder exists in the current directory
print(os.path.exists('./test/'))
# Test does not exist in the current directory_ New folder
print(os.path.exists('./test_new/')) 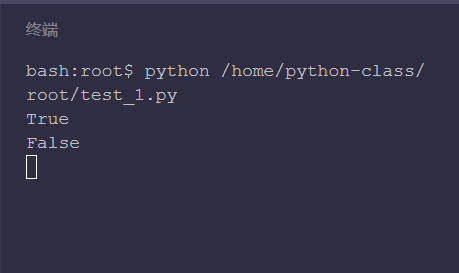
Because the [test] folder exists, it will print True, while the [test_new] folder does not exist, it will print False.
At this time, if you want to create a new folder, you have to use OS mkdir().
"dir" means "directory" Mkdir() is used to create directory / path, OS path. Exists() and OS The two knowledge points MKDIR () are often used in combination.
Still take the above scenario as an example. If the [test_new] folder does not exist, create a new [test_new] folder. The code can be written as follows:
import os
# Determine whether a folder exists
path = './test_new/'
if not os.path.exists(path):
# New folder
os.mkdir(path)We can see that there is an additional [test_new] folder in the [static3] folder.
Back to the project itself, if we want to create the "grade sales table" folder, how should we write the code?
import os
path = './Grade sales table/'
# Determine whether there is a folder '/ Grade sales table / ', if it does not exist, create a new'/ Grade sales table / '
if not os.path.exists(path):
os.mkdir(path)
2.2 determination of grade and quantity
According to the needs of Kangming, every 120 people will be divided into one level. So the first step is to determine the total number of people. In other words, we need to know the total list we have been using_ How long are rows.
As for the length of the list, we can find it with len(list).
After determining the total number of people, it is also necessary to determine the specific needs to be divided into several levels in combination with the operation results. Therefore, the arithmetic operators / / and% need to be used in the operation.
//The quotient used to return the division formula can be understood as taking integral division.
%It is used to return the remainder of the division formula, that is, modulus
Let's look at the string code
print('Business:', 10 // 3)
print('remainder:', 10 % 3)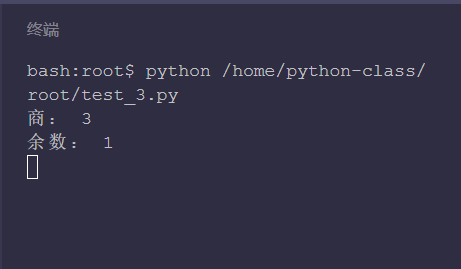
10 divided by 3, the quotient is 3 and the remainder is 1, which is just consistent with the code result.
Let's take total_ The first 10 items of data in rows are split as an example, and every 4 items are divided into one level,
cut = 4
# Get the final total in the summary sorting function_ A small part of the data of rows
total_rows = [['Chen Jie', 'Sales group 7', 10393, 815, 2993, 971, 1833, 889, 1128, 8629, 1], ['Liu Bo', 'Sales group 7', 10133, 1496, 2667, 774, 1924, 315, 1142, 8318, 2], ['Tao Chen', 'Sales group 6', 10140, 1481, 2267, 568, 1989, 1236, 741, 8282, 3], ['Zhang Hua', 'Sales group 2', 10212, 1395, 2908, 490, 1485, 1149, 837, 8264, 4], ['Chen Wei',
'Sales group 8', 10427, 1289, 2828, 502, 1279, 1354, 972, 8224, 5], ['Dong Mei Li', 'Sales group 6', 10195, 326, 2946, 886, 1963, 1309, 657, 8087, 6], ['Yang Xiulan', 'Sales group 5', 10371, 509, 2715, 992, 1394, 1301, 1174, 8085, 7], ['Yang Lin', 'Sales group 4', 10063, 862, 2766, 799, 1611, 964, 1077, 8079, 8], ['Li Bo', 'Sell a group', 10044, 1380, 2995, 886, 946, 1468, 327, 8002, 9], ['Li Xuemei', 'Sales group 2', 10078, 1099, 2448, 760, 1574, 1215, 889, 7985, 10]]
# Calculate the grade quantity, divide it first, and get at least the grade quantity nums that needs to be split
nums = len(total_rows) // cut
# If the remainder is not 0, the number of grades nums+1 to get the final required number of grades
if len(total_rows) % cut != 0:
nums += 1
print(nums) 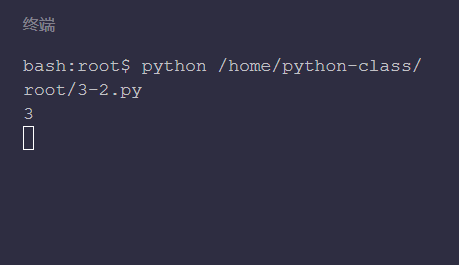
In the above code, line 8 is to divide and calculate the grade quantity first, and lines 11 to 13 are used to judge whether the quantity grade can be divided, that is, whether the remainder is 0. If the remainder is not 0, the final required quantity level can be obtained by adding 1 to the grade quantity.
2.3 split data and save Workbook
After specifying the level and quantity, start to create a new workbook, write the header information and traverse the total_rows list, but there is a new problem. How to split every 120 people into one level?
Actually, it's not difficult. It's just slicing,
# Split into 3 levels
nums = 3
# Every four items are a grade
cut = 4
# Definition list
list_info = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Through traversal, it is divided into three lists
for i in range(nums):
# The maximum number of cut items per list is limited
print(list_info[i*cut:(i+1)*cut]) 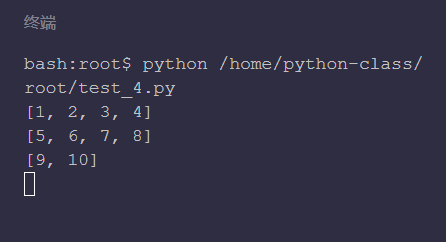
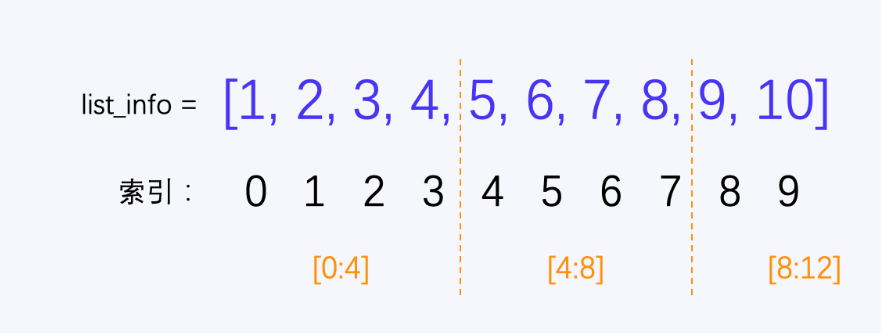
The reason why line 10 is multiplied by cut here is that we want to divide every four items into a level, which ensures that the list obtained by each slice is at most four items, list_info[i * cut: (i + 1) * cut] got the list respectively_ info[0:4],list_info[4:8],list_info[8:12], because the list_ There are only 10 info items, up to list_info[9], so list_info[8:12] actually, it's just a list_ The last two items of info list get the last level list.
Back to the project, let's do an exercise and still take the total used earlier_ The first 10 items in the rows list are divided into one level and written into a new worksheet,
from openpyxl import Workbook
# Every 4 items are divided into one level
cut = 4
# It is divided into 3 grades in total
nums = 3
# Get the final total in the summary sorting function_ A small part of the data of rows
total_rows = [['Chen Jie', 'Sales group 7', 10393, 815, 2993, 971, 1833, 889, 1128, 8629, 1], ['Liu Bo', 'Sales group 7', 10133, 1496, 2667, 774, 1924, 315, 1142, 8318, 2], ['Tao Chen', 'Sales group 6', 10140, 1481, 2267, 568, 1989, 1236, 741, 8282, 3], ['Zhang Hua', 'Sales group 2', 10212, 1395, 2908, 490, 1485, 1149, 837, 8264, 4], ['Chen Wei',
'Sales group 8', 10427, 1289, 2828, 502, 1279, 1354, 972, 8224, 5], ['Dong Mei Li', 'Sales group 6', 10195, 326, 2946, 886, 1963, 1309, 657, 8087, 6], ['Yang Xiulan', 'Sales group 5', 10371, 509, 2715, 992, 1394, 1301, 1174, 8085, 7], ['Yang Lin', 'Sales group 4', 10063, 862, 2766, 799, 1611, 964, 1077, 8079, 8], ['Li Bo', 'Sell a group', 10044, 1380, 2995, 886, 946, 1468, 327, 8002, 9], ['Li Xuemei', 'Sales group 2', 10078, 1099, 2448, 760, 1574, 1215, 889, 7985, 10]]
# Split the grade table by grade quantity
for num in range(nums):
# New sheet
new_wb = Workbook()
new_sheet = new_wb.active
# Write header
new_sheet.append(['full name', 'Sales team', 'Job number', 'milk/bottle', 'mineral water/bottle', 'Fruit and vegetable juice/bottle', 'Soda/bottle', 'Tea beverage/bottle', 'Coffee/bottle', 'total/bottle', 'Sales ranking'])
# Write data
for row in total_rows[num*cut:(num+1)*cut]:
new_sheet.append(row)
# Save level table
new_wb.save('Grade{}Sales table.xlsx'.format(num + 1))Because we extract the sales data of 4 people every time, and the sales data of each person is a separate list, the actual results obtained from the code slice in line 21 of the above example are as follows:
[['Chen Jie', 'Sales group 7', 10393, 815, 2993, 971, 1833, 889, 1128, 8629, 1], ['Liu Bo', 'Sales group 7', 10133, 1496, 2667, 774, 1924, 315, 1142, 8318, 2], ['Tao Chen', 'Sales group 6', 10140, 1481, 2267, 568, 1989, 1236, 741, 8282, 3], ['Zhang Hua', 'Sales group 2', 10212, 1395, 2908, 490, 1485, 1149, 837, 8264, 4]] [['Chen Wei', 'Sales group 8', 10427, 1289, 2828, 502, 1279, 1354, 972, 8224, 5], ['Dong Mei Li', 'Sales group 6', 10195, 326, 2946, 886, 1963, 1309, 657, 8087, 6], ['Yang Xiulan', 'Sales group 5', 10371, 509, 2715, 992, 1394, 1301, 1174, 8085, 7], ['Yang Lin', 'Sales group 4', 10063, 862, 2766, 799, 1611, 964, 1077, 8079, 8]] [['Li Bo', 'Sell a group', 10044, 1380, 2995, 886, 946, 1468, 327, 8002, 9], ['Li Xuemei', 'Sales group 2', 10078, 1099, 2448, 760, 1574, 1215, 889, 7985, 10]]
The nested list is not suitable for writing into the new worksheet. The traversal is added in lines 20-22 to obtain everyone's separate sales data, that is, a separate small list, and then write into the new worksheet.
Finally, num+1 is used because we want to start from level 1 to the back row, not from level 0.
Let's take a look again. When Kangming saved it as [level x sales table. xlsx], X used Chinese numbers instead of Arabic numbers in our project. Therefore, it leads to the last new knowledge point we need to learn - cn2an An2cn (), this usage is very easy.
The cn2an module needs to be installed in advance when the computer is running locally. We use pip to install in cmd / terminal.
# Windows system: pip install cn2an # Mac system: pip3 install cn2an
import cn2an num1 = 101 num2 = 'three hundred and sixty-nine' # Convert num1 to Chinese numbers num1_new = cn2an.an2cn(num1) # Turn num2 into Arabic numerals num2_new = cn2an.cn2an(num2) print(num1_new) print(num2_new)
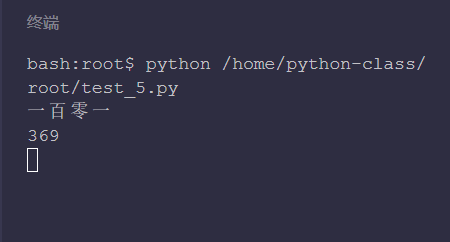
You can see that 101 is converted to "101" and "369" is converted to 369. Therefore, in the project, if you want to change the X in [level x sales table. xlsx] into Chinese numbers, you actually use cn2an for num+1 in the saved folder code An2cn() does the conversion.
Summary
The above is the relevant knowledge of function 2. Let's summarize it with mind map.