1, Local cache (single project)
If it is a single project, the cache only needs to consider its current application, but in the micro service, each micro service must have a cache service, and the data update must update its own cache, which may lead to data inconsistency
- Let's take a look at the process of single application caching
An out of heap memory overflow occurred later when performing a stress test OutOfDirectMemoryError
springboot2.0 It will be used by default in the future lettuce As operation redis Client, which uses netty Network communication
lettuce of bug cause netty Out of heap memory overflow. Solution replacement jedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
to configure
spring:
redis:
host: 127.0.0.1
port: 6379
@Autowired
private StringRedisTemplate redisTemplate;
public static final String KEY_PREFIX = "index:category:";
public List<CategoryEntity> queryLvl2CategoriesWithSub(Long pid) {
// Get from cache
String cacheCategories = this.redisTemplate.opsForValue().get(KEY_PREFIX + pid);
if (StringUtils.isNotBlank(cacheCategories)){
// If there is in the cache, return directly
List<CategoryEntity> categoryEntities = JSON.parseArray(cacheCategories, CategoryEntity.class);
return categoryEntities;
}
ResponseVo<List<CategoryEntity>> subCategoryResp = this.gmallPmsFeign.querySubCategory(pid);
// Put query results into cache
this.redisTemplate.opsForValue().set(KEY_PREFIX + pid, JSON.toJSONString(subCategoryResp), 30, TimeUnit.DAYS);
return subCategoryResp.getData();
}
-
The three most common cache problems:
a. Cache penetration
b. Cache avalanche
c. Buffer breakdown
Cache penetration refers to querying a nonexistent data. Because the cache cannot be hit, we will query the database, but the database does not have this record. Moreover, for the sake of fault tolerance, we do not write the null of this query into the cache, which will cause the nonexistent data to be queried in the storage layer every request, losing the significance of the cache. When the traffic is heavy, the DB may hang up. If someone uses a nonexistent key to frequently attack our application, this is a vulnerability.
solve:
- Empty results are also cached (five minutes or less for short-term validity)
- Bloom filter
Cache avalanche refers to an avalanche in which the same expiration time is used when we set the cache, resulting in the cache invalidation at the same time at a certain time, all requests are forwarded to the DB, and the DB is under excessive instantaneous pressure.
solve:
- Avoid avalanche: the expiration time of cached data is set randomly to prevent the expiration of a large amount of data at the same time.
- If the cache database is distributed, the hot data will be evenly distributed in different cache databases.
- Set hotspot data to never expire.
- Avalanche: degraded fuse
- In advance: try to ensure the high availability of the whole redis cluster, and make up the machine downtime as soon as possible. Select the appropriate memory obsolescence strategy.
- In fact: local ehcache cache + hystrix current limiting & degradation to avoid MySQL crash
- Afterwards: restore the cache as soon as possible using the data saved by the redis persistence mechanism
Cache breakdown refers to some keys with expiration time set. If these keys may be accessed at some time points, they are very "hot" data. At this time, we need to consider a problem: if the key fails just before a large number of requests come in at the same time, all data queries on the key fall to db, which is called cache breakdown.
solve:
- Set hotspot data not to expire
- ADD mutex: mutex is a common practice in the industry. To put it simply, when the cache fails (it is judged that the value is empty), instead of going to load db to load the database immediately, first use some operations of the cache tool with the return value of successful operations (such as SETNX of Redis or ADD of Memcache) to set a mutex key. When the operation returns success, then operate load db and reset the cache; Otherwise, retry the entire get cached method.
Difference from cache avalanche:
- Breakdown is a hot spot
- Avalanches are a collective failure of many people
2, Distributed caching and locking
2.1 redis implements distributed locks
With the needs of business development, after the original single project is evolved into a distributed cluster system, because the distributed system is multi-threaded, multi process and distributed on different machines, this will invalidate the concurrency control lock strategy under the original single machine deployment (cross jvm), and the simple Java API can not provide the ability of distributed lock.
Here, we use redis. The main principle is to use the command setnx(key, value) in redis. If a key does not exist, it will be added, and if it exists, it will do nothing. When multiple clients send setnx commands at the same time, only one client can succeed, and 1 (true) is returned; Other clients return 0 (false)
public void testLock() {
// 1. Obtain the lock from redis, setnx
Boolean lock = this.redisTemplate.opsForValue().setIfAbsent("lock", "111");
if (lock) {
// Query the num value in redis
String value = this.redisTemplate.opsForValue().get("num");
// There is no such value return
if (StringUtils.isBlank(value)){
return ;
}
// If there is value, it will be converted to int
int num = Integer.parseInt(value);
// Add the num value in redis + 1
this.redisTemplate.opsForValue().set("num", String.valueOf(++num));
// 2. Release the lock del
this.redisTemplate.delete("lock");
} else {
// 3. Call back every 1 second and try to obtain the lock again
try {
Thread.sleep(1000);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
First think about the problem
- After setting the lock, what should I do when the service goes down, causing a deadlock (set an expiration time)
- The lock expires before the business is executed. When others get the lock, they delete others' locks (lock renewal (reisson has a watchdog). When deleting a lock, it is clear that it is their own lock. For example, uuid, ensure that it is their own lock)
- The judgment uuid is correct, but the lock expires when it is about to be deleted, and someone else sets a new value, then someone else's lock is deleted
- When index1 performs deletion, the lock value queried is indeed equal to uuid
- Before index1 is deleted, the lock has just expired and is automatically released by redis
- index2 got lock
- index1 deletes, and the lock of index2 will be deleted (using redis+Lua script, which is atomic)
if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end;
// redistemplate can execute lua scripts
stringRedisTemplate.execute(
new DefaultRedisScript<Long return type>(script Script payment is very important, Long.class return type),
Arrays.asList("lock"), // Set of key s
lockValue);
- Final realization
public Map<String, List<Catalog2Vo>> getCatalogJsonDbWithRedisLock() {
String uuid = UUID.randomUUID().toString();
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
Boolean lock = ops.setIfAbsent("lock", uuid,500, TimeUnit.SECONDS);
if (lock) {
Map<String, List<Catalog2Vo>> categoriesDb = getCategoryMap();
String lockValue = ops.get("lock");
// get and delete atomic operations
String script = "if redis.call(\"get\",KEYS[1]) == ARGV[1] then\n" +
" return redis.call(\"del\",KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
stringRedisTemplate.execute(
new DefaultRedisScript<Long>(script, Long.class), // Scripts and return types
Arrays.asList("lock"),
lockValue);
return categoriesDb;
}else {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// After sleeping for 0.1s, call / / spin again
return getCatalogJsonDbWithRedisLock();
}
}
2.2 redisson
2.2.1 integrating redisson
Redisson is a Java in memory data grid implemented on the basis of Redis. It not only provides a series of distributed Java common objects, but also provides many distributed services. Including (BitSet, set, Multimap, sortedset, map, list, queue, BlockingQueue, deque, blockingdeque, semaphore, lock, atomiclong, countdownlatch, publish / subscribe, bloom filter, remote service, spring cache, executor service, liveobject service, scheduler service), redisson provides the simplest and most convenient way to use Redis. Redisson aims to promote users' Separation of Concern on Redis, so that users can focus more on processing business logic.
Official document address: https://github.com/redisson/redisson/wiki
Consolidation:
//rely on
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
// You can use "rediss: / /" to enable SSL connections
//The id address can be written as the configuration address
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
}
}
// Business code
@Autowired
private RedissonClient redissonClient;
@Override
public void testLock() {
RLock lock = this.redissonClient.getLock("lock"); // As long as the name of the lock is the same, it is the same lock
lock.lock(); // Lock
// Query the num value in redis
String value = this.redisTemplate.opsForValue().get("xx");
// No value
if (StringUtils.isBlank(value)) {
//... your business code
}
//Value your business code
.........................
lock.unlock(); // Unlock
}
2.2.2 Reentrant Lock
What is a reentrant lock: a calls B. AB all need the same lock. A obtains the lock and B can use it directly
Non reentrant, a calls B. AB all need the same lock. A needs to release B before it can be used. There will be a deadlock
Redisson distributed reentrant lock RLock Java object based on Redis implements the java.util.concurrent.locks.Lock interface.
If the Redisson node responsible for storing the distributed lock goes down and the lock is locked, the lock will be locked. In order to avoid this situation, Redisson provides a watchdog to monitor the lock. Its function is to continuously extend the validity of the lock before the Redisson instance is closed. By default, the timeout time for the watchdog to check the lock is 30 seconds, which can also be specified by modifying Config.lockWatchdogTimeout.
In addition, Redisson also provides the parameter of leaseTime to specify the locking time through the locking method. After this time, the lock will be unlocked automatically.
The above case uses. It is also the most commonly used lock.
// Parameter is lock name
RLock lock = redissonClient.getLock("CatalogJson-Lock");//The lock implements the JUC.locks.lock interface
lock.lock();//Blocking waiting if we don't get back, we'll wait all the time. What we just wrote ourselves is the way of spin
try{
Thread.slepp(30000)
}catch(Exception e){
}finally{
lock.unlock();
}
// Start two application tests and find that one does not end. The browser Lake keeps turning (blocking and waiting)
- For deadlock problem (watchdog mechanism)
lock.lock(10, TimeUnit.SECONDS);
// Try to lock, wait for 100 seconds at most, and unlock automatically 10 seconds after locking
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
If the lock timeout is passed, execute the script to occupy the lock;
If the lock time is not passed, use the watchdog time to occupy the lock. If the lock occupation is successful future,call future.onComplete();
Call if there is no exception scheduleExpirationRenewal(threadId);
Reset the expiration time to schedule the task;
The principle of the watchdog is a scheduled task: reset the expiration time of the lock, and the new expiration time is the default time of the watchdog;
Lock time/3 Is a scheduled task cycle;
It is recommended to specify the time manually
2.2.3 read write lock
- Redisson distributed reentrant read-write lock RReadWriteLock Java object based on Redis implements the java.util.concurrent.locks.ReadWriteLock interface. Both read lock and write lock inherit RLock interface.
- Distributed reentrant read-write locks allow multiple read locks and one write lock to be locked at the same time.
RReadWriteLock rwlock = redisson.getReadWriteLock("anyRWLock");
// Most common usage
rwlock.readLock().lock();
// or
rwlock.writeLock().lock();
// Automatic unlocking after 10 seconds
// There is no need to call the unlock method to unlock manually
rwlock.readLock().lock(10, TimeUnit.SECONDS);
// or
rwlock.writeLock().lock(10, TimeUnit.SECONDS);
// Try to lock, wait for 100 seconds at most, and unlock automatically 10 seconds after locking
boolean res = rwlock.readLock().tryLock(100, 10, TimeUnit.SECONDS);
// or
boolean res = rwlock.writeLock().tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
Use test
@GetMapping("read")
public ResponseVo<String> read(){
String msg = indexService.readLock();
return ResponseVo.ok(msg);
}
@GetMapping("write")
public ResponseVo<String> write(){
String msg = indexService.writeLock();
return ResponseVo.ok(msg);
}
public String readLock() {
// Initialize read / write lock
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("readwriteLock");
RLock rLock = readWriteLock.readLock(); // Acquire read lock
rLock.lock(10, TimeUnit.SECONDS); // Add 10s lock
String msg = this.redisTemplate.opsForValue().get("msg");
//rLock.unlock(); // Unlock
return msg;
}
public String writeLock() {
// Initialize read / write lock
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("readwriteLock");
RLock rLock = readWriteLock.writeLock(); // Get write lock
rLock.lock(10, TimeUnit.SECONDS); // Add 10s lock
this.redisTemplate.opsForValue().set("msg", UUID.randomUUID().toString());
//rLock.unlock(); // Unlock
return "Successfully written content......";
}
Open two browser tests
-
Simultaneous access write: after one is finished, wait for a while (about 10s), and the other starts to write
-
Simultaneous access read: no waiting
-
Write first and then read: wait (about 10s) for reading to complete
-
Read before write: wait (about 10s) for reading to complete
2.2.4 Semaphore
The distributed Semaphore Java object RSemaphore of Redisson based on Redis adopts an interface and usage similar to java.util.concurrent.Semaphore.
RSemaphore semaphore = redisson.getSemaphore("semaphore");
semaphore.acquire();
//or
semaphore.acquire(23);
semaphore.tryAcquire();
semaphore.tryAcquire(23, TimeUnit.SECONDS);
// Release resources
semaphore.release();
The Redisson distributed locking (CountDownLatch) Java object RCountDownLatch based on Redisson adopts an interface and usage similar to java.util.concurrent.CountDownLatch.
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// In another thread or other JVM
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
Two threads are required, one waiting. A count countDown
/**
* wait for
* @return
*/
@GetMapping("latch")
public ResponseVo<Object> countDownLatch(){
String msg = indexService.latch();
return ResponseVo.ok(msg);
}
/**
* count
* @return
*/
@GetMapping("out")
public ResponseVo<Object> out(){
String msg = indexService.countDown();
return ResponseVo.ok(msg);
}
public String latch() {
RCountDownLatch countDownLatch = this.redissonClient.getCountDownLatch("countdown");
try {
countDownLatch.trySetCount(6);
countDownLatch.await();
return "close the door.....";
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
public String countDown() {
RCountDownLatch countDownLatch = this.redissonClient.getCountDownLatch("countdown");
countDownLatch.countDown();
return "A man came out...";
}
Restart the test and open two pages: the first request will not be executed until the second request is executed 6 times.
2.2.5 CountDownLatch
The Redisson distributed locking (CountDownLatch) Java object RCountDownLatch based on Redisson adopts an interface and usage similar to java.util.concurrent.CountDownLatch.
The following code has only offLatch()After being called 5 times setLatch()To continue
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// In another thread or other JVM
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
2.2.6 cache data consistency
In order to ensure data consistency, there are two general operations:
- Double write (write the cache after writing the database, which may cause problems. In case of concurrency, 2 writes enter, and write the cache after writing the DB. There is temporary dirty data)
- Failure mode: delete the cache after writing the database (it has not been stored in the database, 1. Thread 2 reads the old DB again, distributed lock read-write, 2. Set the expiration time of the cache)
Solution:
- If it is user latitude data (order data and user data), the concurrency probability is very small. This problem does not need to be considered. Add the expiration time to the cached data and trigger the active update of the read at regular intervals
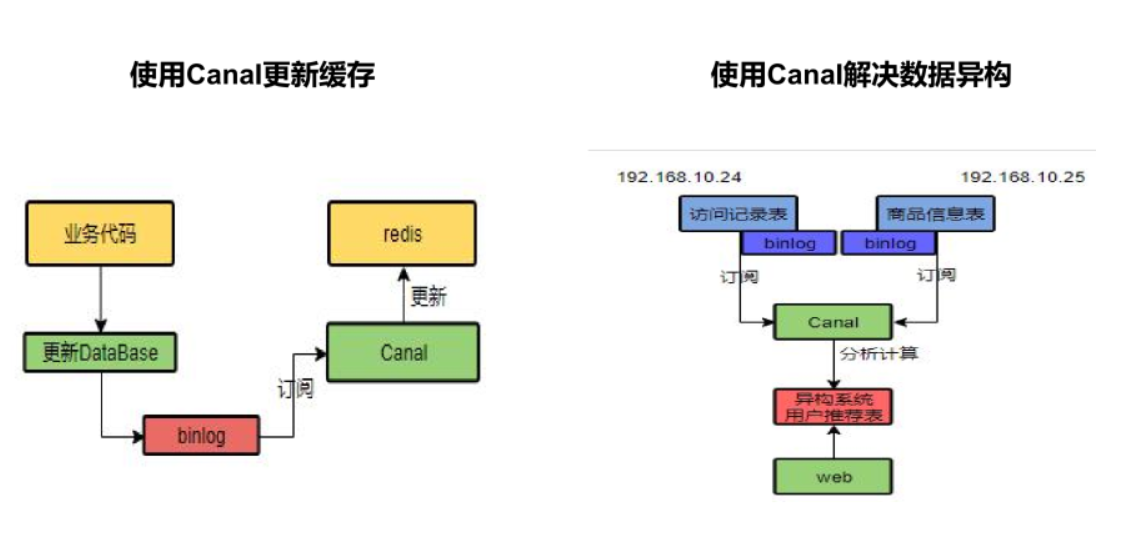
- For basic data such as menus and product introductions, you can also use canal to subscribe to binlog
- Cache data + expiration time is also sufficient to solve the cache requirements of most businesses.
- Lock to ensure concurrent reading and writing, and line up in order when writing. It doesn't matter to read. Therefore, it is suitable to use read-write lock. (the service is not related to heart data, and temporary dirty data can be ignored);
Summary:
Conclusion: the data we can put into the cache should not have high requirements for real-time and consistency. Therefore, add the expiration time when caching data to ensure that you can get the latest data every day. We should not over design and increase the complexity of the system. In case of data with high requirements for real-time and consistency, we should check the database, even slowly.
2.3 springcache
2.3.1 introduction to spring cache
We made a judgment when operating the Cache, but it's too troublesome to write the Cache like that every time. spring has defined Cache and CacheManager interfaces since 3.1 to unify different Cache technologies. It also supports the use of JCache(JSR-107) annotations to simplify our development
The implementation of Cache interface includes RedisCache, EhCacheCache, ConcurrentMapCache, etc
Each time a method requiring caching is called, spring will check whether the specified target method of the specified parameter has been called; If yes, get the result of the method call directly from the cache. If not, call the method and cache the result and return it to the user. The next call is taken directly from the cache.
When using Spring cache abstraction, we need to pay attention to the following two points:
- Identify the methods that need caching and their caching policies
- Read the data stored in the previous cache from the cache
2.3.2 integration
//rely on
<dependency>
<groupId>org.springframework.b oot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
//to configure
spring:
cache:
#The specified cache type is redis
type: redis
redis:
# Specify the expiration time in redis as 1h
time-to-live: 3600000
Add to the startup class@EnableCaching
Default use jdk Serialization (poor readability), default ttl by-1 Never expire. To customize the serialization method, you need to write a configuration class
@Configuration
public class MyCacheConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration( CacheProperties cacheProperties) {
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
org.springframework.data.redis.cache.RedisCacheConfiguration config = org.springframework.data.redis.cache.RedisCacheConfiguration
.defaultCacheConfig();
//Specifies that the cache serialization method is json
config = config.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
//Set various configurations in the configuration file, such as expiration time
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
//use
// When this method is called, the result will be cached. The cache name is category and the key is the method name
// sync means that the cache of this method will be locked when it is read. / / value is equivalent to cacheNames // key if it is a string "''"
@Cacheable(value = {"category"},key = "#root.methodName",sync = true)
public Map<String, List<Catalog2Vo>> getCatalogJsonDbWithSpringCache() {
return getCategoriesDb();
}
//Calling this method will delete all caches under the cache category. If you want to delete a specific, use key = ''
@Override
@CacheEvict(value = {"category"},allEntries = true)
public void updateCascade(CategoryEntity category) {
this.updateById(category);
if (!StringUtils.isEmpty(category.getName())) {
categoryBrandRelationService.updateCategory(category);
}
}
If you want to empty multiple caches, use@Caching(evict={@CacheEvict(value="")})
2.3.4 principles and shortcomings of springcache
1) , read mode
Cache penetration: query a null data. Solution: cache empty data through spring. Cache. Redis. Cache null values = true
Cache breakdown: a large number of concurrent queries come in and query an expired data at the same time. Solution: lock? It is unlocked by default;
Use sync = true to solve the breakdown problem
Cache avalanche: a large number of Keys expire at the same time. Solution: add random time.
2) . write mode: (cache is consistent with database)
Read write lock.
Introduce Canal to sense the update of MySQL and update Redis
Read more and write more. Just go to the database to query
3) . summary:
General data (for data with more reads and less writes, timeliness and low consistency requirements, spring cache can be used):
Write mode (as long as the cached data has an expiration time)
Special data: special design