Catalogue of series articles
Tip: you can add the directories of all articles in the series here. You need to add the directories manually
For example: the first chapter is the use of pandas, an introduction to Python machine learning
Tip: after writing the article, the directory can be generated automatically. For how to generate it, please refer to the help document on the right
preface
Tip: Graylog is an open source tool for log aggregation, analysis, audit, presentation and early warning. Low cost and high performance. In fact, it is more convenient to encapsulate es and query logs.
Tip: the following is the main content of this article. The following cases can be used for reference
1, Installation preparation?
Graylog 4.0.7 is installed this time. Note that the version of elasticsearch required by graylog 4 needs to be more than 7. Graylog 3 is not applicable to elasticsearch 7 x!
-
Official document tips:
 Install graylog4 Prerequisites for 0
Install graylog4 Prerequisites for 0 -
Elasticsearch 6.8, 7.7 to 7.10
-
MongoDB 3.6, 4.0 or 4.2
-
Oracle Java SE 8 (OpenJDK 8 is also applicable; the latest stable update is recommended)
- Prepare three nodes. The system version is CentOS 7 6.
| IP | Hostname |
|---|---|
| 172.16.72.160 | Graylog_01 |
| 172.16.72.159 | Graylog_02 |
| 172.16.79.210 | Graylog_03 |
- Deploy products:
| mongodb database | Using alicloud, I won't repeat it here |
|---|---|
| elasticsearch | 7.10.0 (because the 4 version is selected by graylog, the corresponding es also needs a higher version of 7, and the 7 version does not support graylog 3) |
2, Deployment steps
1. Front work
1: Turn off server firewall
Server firewall status query (example):
systemctl status firewalld Check whether the firewall is closed. If the firewall is not closed, please close the firewall Or use: firewall-cmd --state
 Server firewall off (example):
Server firewall off (example):
systemctl stop firewalld.service Turn off server firewall systemctl disable firewalld.service Disable firewall startup and self startup
#####2: Close SELinux
Permanent shutdown (example):
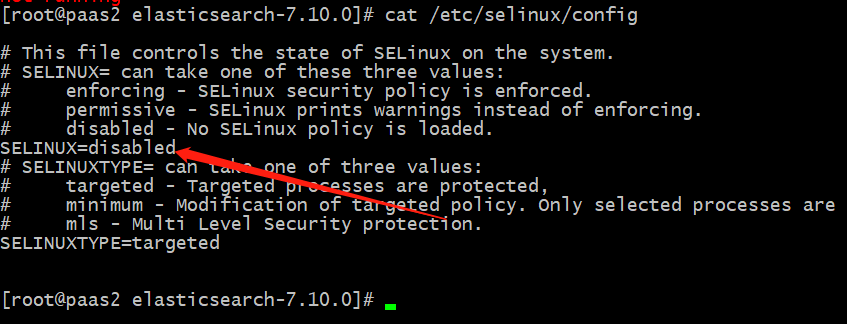
vi /etc/selinux/config
Change SELINUX=enforcing to SELINUX=disabled
After setting, you need to restart to take effect
View selinux status information (example):
cat /etc/selinux/config
 #####3: Install jdk1 8 and above
#####3: Install jdk1 8 and above
- I won't repeat it here. The 1.8 installation tutorials are all over the network
III Install mongodb database
1: What is the purpose of MongoDB?
Graylog use MongoDB To store your configuration data, not your log data. Store only metadata, such as user information or flow configuration. Any of your log messages will not be stored in the MongoDB Yes. That's why MongoDB The reason why it doesn't have much impact on the system, and you don't have to worry too much about expanding it. Through our recommended setting architecture, MongoDB Can work with your Graylog The server runs with processes and uses almost no resources.
- Please refer to the online tutorial for mondogb installation. I use Alibaba cloud mongodb
- Create a graylog database, add a graylog user, and grant readWrite and dbAdmin permissions:
1: establish graylog database
use graylog
2: establish graylog The user sets the password and graylog This database is granted read and write permissions
db.createUser( {
user: "graylog",
pwd: "xxxxx",
roles: [ { role: "readWrite", db: "graylog" } ]
});
3: give graylog user graylog library dbAdmin jurisdiction
db.grantRolesToUser( "graylog" , [ { role: "dbAdmin", db: "graylog" } ])
4: View user:
show users
IV. Elasticsearch cluster construction
Elasticsearch I choose 7.10.0, and my installation directory is: / opt/server /:
1: es Download
- Downloading using Huawei cloud is fast and comprehensive: https://mirrors.huaweicloud.com/elasticsearch/
wget https://mirrors.huaweicloud.com/elasticsearch/7.10.0/elasticsearch-7.10.0-linux-x86_64.tar.gz tar -zxvf elasticsearch-7.10.0-linux-x86_64.tar.gz

2: Create es data directory
mkdir -p /opt/data/
3: Modify es cluster configuration
1: Modify config / jvm.exe in the es installation directory options
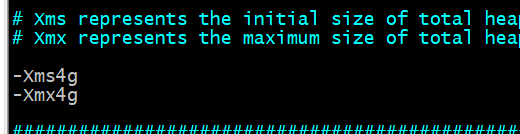
* modify es The startup parameter is half of the local memory (according to your actual needs) * take es Of the installation directory config/jvm.options * this jvm.options Used to configure various jvm Parameters, such as GC,GC logging,heap dumps Wait.
vim /opt/server/elasticsearch-7.10.0/config/jvm.options Amend to read: -Xms4g -Xmx4g
2: Modify config / elasticsearch. In the es installation directory yml
vim /opt/server/elasticsearch-7.10.0/config/elasticsearch.yml
-
First, let's check the meaning of this file configuration:
-
Configure the name of the cluster name
A node only has the same master as all other nodes in the cluster Name to join the cluster. The default cluster name is elasticsearch. It is best to set it to an appropriate name, otherwise it may have the same name as the existing cluster. The following configuration names the cluster: graylogcluster.name: graylog
-
Name of the configuration node
If the node name is not set, node Name, by default, Elasticsearch will use the first seven characters of the randomly generated UUID as the node ID, and the random string will be persisted and will not be lost even if the system is restarted. However, in order to improve the readability of the system, we'd better set an appropriate name for each node:node.name: graylog01
Or simply set it to the name of the host: node name: hostname
-
Lists all nodes in the cluster
-
Elasticsearch implements a discovery node named "Zen Discovery" and selects the master node from among the nodes of the cluster. In the cluster configuration, two configuration items related to "Zen Discovery" must be configured, one of which is discovery zen. ping. unicast. hosts.
Without any network configuration, Elasticsearch will bind to available loopback addresses and scan ports 9300 to 9305 to try to connect to other nodes running on the same server. This provides an automated clustering experience without any configuration. When you need to use nodes on other servers to form a cluster, you must use discovery zen. ping. unicast. Hosts provides a list of other nodes in the cluster:discovery.zen.ping.unicast.hosts: ["192.168.79.210:9300", "192.168.72.159:9300","192.168.72.160:9300"]
In addition to the IP address, the host name can also be used here.
-
Configure the minimum number of master nodes
-
Another configuration item related to "Zen Discovery" that must be set is discovery zen. minimum_ master_ nodes. Its default value is 1. This attribute defines the minimum number of candidate primary nodes connected to each other to form a cluster. It is strongly recommended to use the majority principle for setting this attribute: (master_eligible_nodes / 2) + 1, which can not only avoid split brain, but also quickly elect new primary nodes after failure. For example, if there are 5 candidate primary nodes, it is recommended to set this attribute to 3. Since there are only two nodes in the demo demonstrated in this article, set this value to 1:
Cluster configuration example
# node-1 node.name: node-1 node.master: true node.data: true path.data: /opt/data/elasticsearch path.logs: /opt/logs/elasticsearch bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 discovery.seed_hosts: ["172.16.72.160", "172.16.72.159","172.16.79.210"] cluster.initial_master_nodes: ["172.16.72.160"] http.cors.enabled: true http.cors.allow-origin: "*" # node-2 node.name: node-2 node.master: true node.data: true path.data: /opt/data/elasticsearch path.logs: /opt/logs/elasticsearch bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 discovery.seed_hosts: ["172.16.72.160", "172.16.72.159","172.16.79.210"] cluster.initial_master_nodes: ["172.16.72.160"] http.cors.enabled: true http.cors.allow-origin: "*" # node-3 node.name: node-3 node.master: true node.data: true path.data: /opt/data/elasticsearch path.logs: /opt/logs/elasticsearch bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 discovery.seed_hosts: ["172.16.72.160", "172.16.72.159","172.16.79.210"] cluster.initial_master_nodes: ["172.16.72.160"] http.cors.enabled: true http.cors.allow-origin: "*"
3: Create the es startup user and empower the es directory to this user
- Because es cannot be started with root, a startup user is created
useradd es chmod -R chown -R es:es /etc/elasticsearch-6.4.3/ take es Installation directory assignment es user
4: Modify / etc / sysctl conf
- vim /etc/sysctl.conf add the following configuration in the last line of the file
vm.max_map_count=262144
- Then let the configuration take effect
sysctl -p
4: Start es
-
Use the elasticsearch script - d under bin in the installation directory to start
/opt/server/elasticsearch-7.10.0/bin/elasticsearch -d
Start error
Because of your / etc / sysctl Conf is not added to VM max_ map_ count=262144

Installing Graylog
1111:
#####Download graylog official website download address: https://www.graylog.org/releases Choose the version you need. I choose 4.0.7 here! [insert picture description here]( https://img-blog.csdnimg.cn/20210616165629331.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0xvdmVseV9yZWRfc2NhcmY=,size_16,color_FFFFFF,t_70)summary
Tip: here is a summary of the article:
For example, the above is what we want to talk about today. This paper only briefly introduces the use of pandas, which provides a large number of functions and methods that enable us to process data quickly and conveniently.