Input format:
The first line of input gives a positive integer n (≤ 50), which is the number of sets. Then, N lines, each line corresponds to a set. Each set first gives a positive integer m (≤ 10 ^ 4), which is the number of elements in the set; then followed by M integers in the [0,10 ^ 9] interval. The next line gives a positive integer K (≤ 2000), followed by K lines, each line corresponds to the number of a pair of sets to calculate similarity (sets are numbered from 1 to n). The numbers are separated by spaces.
Output format:
For each pair of sets to be calculated, output their similarity in one line, which is the percentage number with 2 digits after the decimal point.
Input example:
3 3 99 87 101 4 87 101 5 87 7 99 101 18 5 135 18 99 2 1 2 1 3 (No blank lines at the end)
Output example:
50.00% 33.33% (No blank lines at the end)
Topic analysis
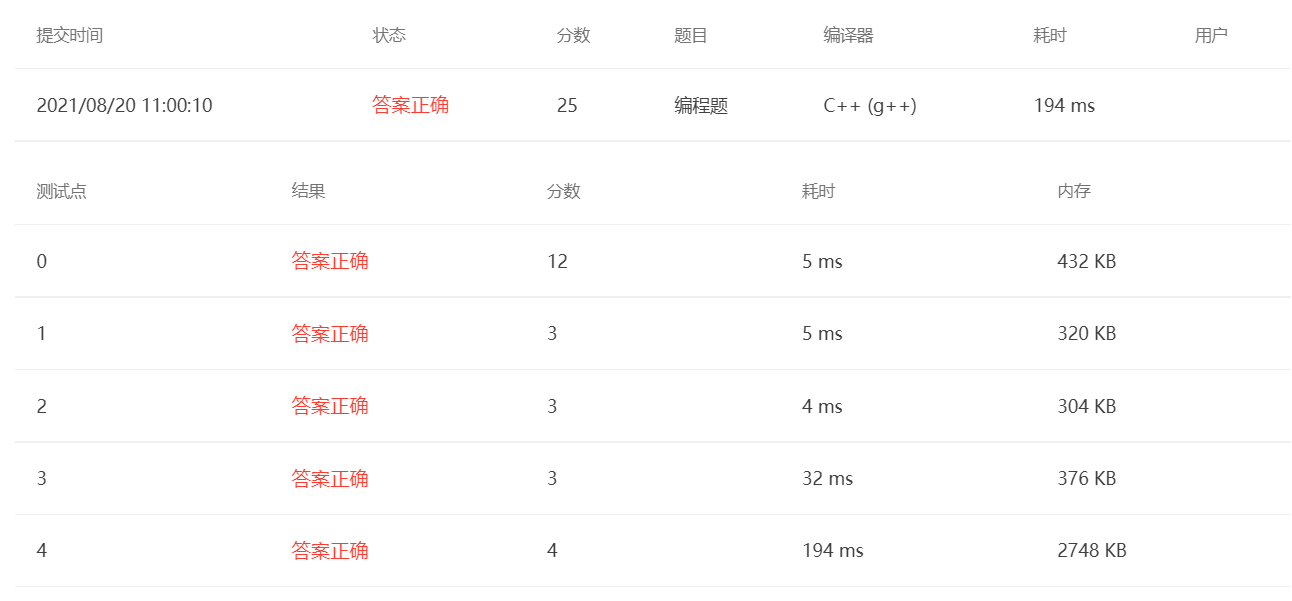
When I saw the de duplication, I thought of using set, but I didn't take the most stupid method, that is, I didn't insert at the same time of input, but began to insert into set at the time of each query, which led to the huge time consumption of the program in the insertion operation when there was a large amount of data. Therefore, I exceeded the time at the last test point and only got 21 points.
#include<bits/stdc++.h>
using namespace std;
const int num=10005;
int N,M,loop[num];
set<int> unequal;
set<int> equal_1;
set<int> equal_2;
long arr[num][num];
void calculate(int x,int y)
{
for(int i=0;i<loop[x];i++)
{
unequal.insert(arr[x][i]);
equal_1.insert(arr[x][i]);
}
for(int i=0;i<loop[y];i++)
{
unequal.insert(arr[y][i]);
equal_2.insert(arr[y][i]);
}
int N2=unequal.size();
int N1=0;
for(set<int>::iterator i=equal_1.begin();i!=equal_1.end();i++)
{
for(set<int>::iterator j=equal_2.begin();j!=equal_2.end();j++)
{
if(*i==*j)
{
N1++;
break;
}
}
}
float result=(float)N1/N2;
result*=100;
cout << setiosflags(ios::fixed) << setprecision(2) << result << "%" << endl;
}
int main()
{
cin >> N;
for(int i=0;i<N;i++)
{
cin >> loop[i];
for(int j=0;j<loop[i];j++)
{
cin >> arr[i][j];
}
}
int test,judge[N][N];
cin >> test;
for(int i=0;i<test;i++)
{
int x,y;
cin >> x >> y;
unequal.clear();
equal_1.clear();
equal_2.clear();
calculate(x-1,y-1);
}
return 0;
}
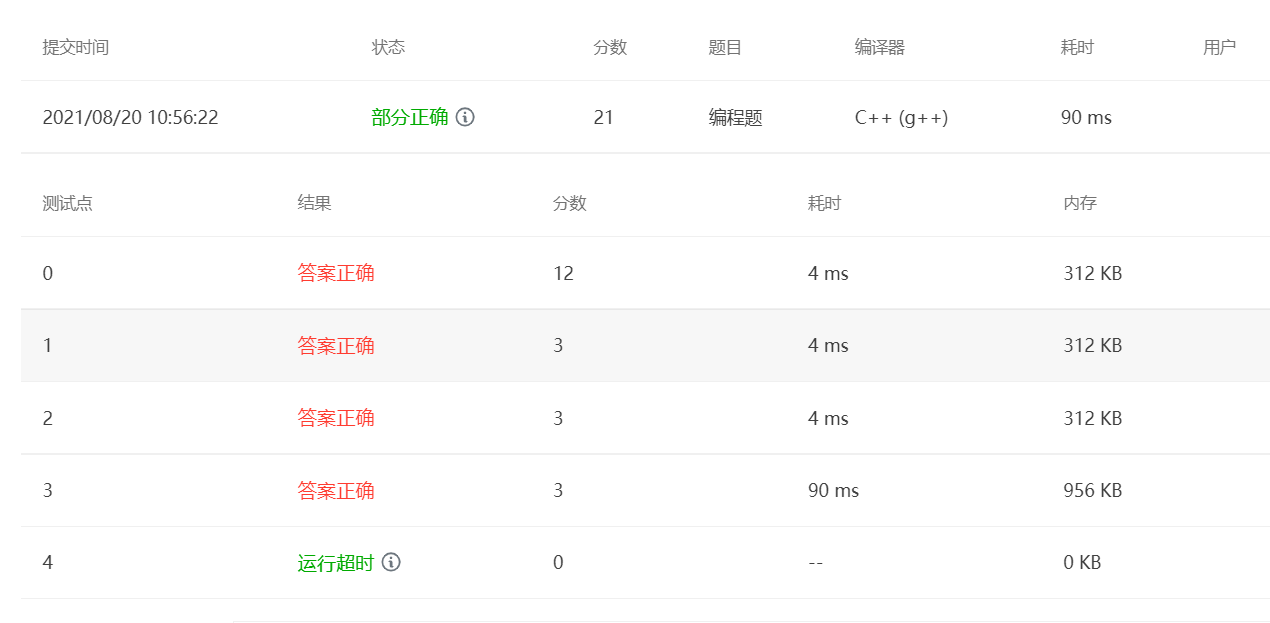
Then, even if the bisection operation is used to reduce the time complexity as much as possible, it can not offset the impact of the insertion operation. Finally, the idea is changed and the method of inserting while inputting is adopted. More importantly, the key relationship len1+len2-M is found, so there is no need to set up a set to maintain Nt, which greatly saves time.
The key is to make good use of the characteristics of set and some member functions. These are the key points we need to master when preparing for the competition, and we should also know that there is no way to duplicate without set. These are very important.
#include<bits/stdc++.h>
using namespace std;
int N;
set<int> equal_set[55];
set<int> abc;
int main()
{
cin >> N;
for(int i=1;i<=N;i++)
{
int loop,x;
cin >> loop;
for(int j=0;j<loop;j++)
{
cin >> x;
equal_set[i].insert(x);
}
}
int test;
cin >> test;
for(int i=0;i<test;i++)
{
int x,y;
cin >> x >> y;
int len1=equal_set[x].size();
int len2=equal_set[y].size();
int M=0;
for(set<int>::iterator it=equal_set[x].begin();it!=equal_set[x].end();it++)
{
if(equal_set[y].find(*it)!=equal_set[y].end())
{
M++;
}
}
float result=(float)M/(len1+len2-M);
result*=100;
cout << setiosflags(ios::fixed) << setprecision(2) << result << "%" << endl;
}
return 0;
}