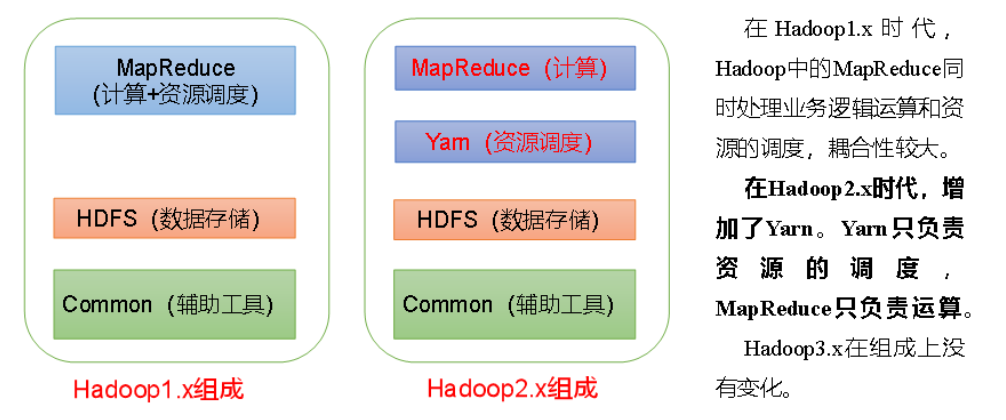
Hadoop overview
Hadoop composition
HDFS Architecture Overview
Hadoop Distributed File System (HDFS for short) is a distributed file system.
-
NameNode (nn): stores the metadata of the file. Such as file name, file directory structure, file attributes (generation time, number of copies, file permissions), block list of each file, DataNode where the block is located, etc.
-
DataNode(dn): stores file block data in the local file system. And the checksum of block data.
3) secondary NameNode (2nn): Backup metadata of NameNode at regular intervals.
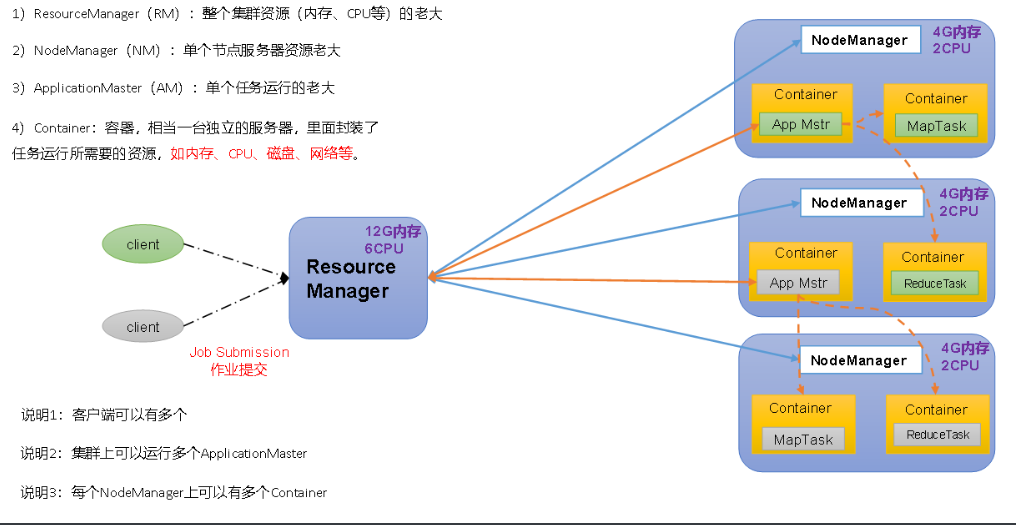
Overview of YARN architecture
MapReduce Architecture Overview
MapReduce divides the calculation process into two stages: Map and Reduce
1) The Map stage processes the input data in parallel
2) In the Reduce phase, the Map results are summarized
Template virtual machine environment preparation
Install the template virtual machine, IP address 192.168.10.100, host name Hadoop 100
1. Hadoop 100 virtual machine configuration requirements are as follows
1. Install EPEL release
[root@hadoop100 ~]# yum install epel-release
2. Net tool: toolkit collection
[root@hadoop100 ~]# yum install -y net-tools
3. Turn off the firewall. Turn off the firewall and start it automatically
[root@hadoop100 ~]# systemctl stop firewalld [root@hadoop100 ~]# systemctl disable firewalld.service Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
4. Create user and change password
[root@hadoop100 ~]# useradd liyuhao [root@hadoop100 ~]# passwd liyuhao
5. (optional) configure liyuhao user to have root permission, which is convenient for sudo to execute the command with root permission later
[root@hadoop100 ~]# vim /etc/sudoers
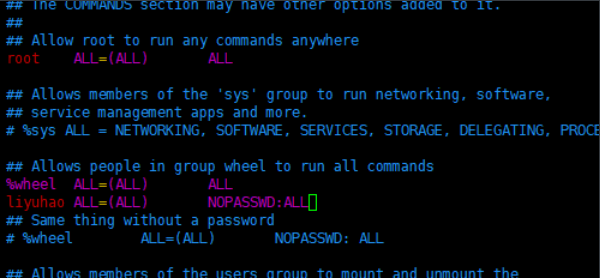
Note: the liyuhao line should not be placed directly under the root line, because all users belong to the wheel group. You first configured liyuhao to have the password free function, but when the program runs to the% wheel line, the function is overwritten and requires a password. So liyuhao should be placed under the line% wheel.
6. Create a folder in the / opt directory and modify the owner and group
(1) Create the module and software folders in the / opt directory
[root@hadoop100 ~]# mkdir /opt/module [root@hadoop100 ~]# mkdir /opt/software [root@hadoop100 ~]# ll /opt Total consumption 12 drwxr-xr-x. 2 root root 4096 2 November 17:32 module drwxr-xr-x. 2 root root 4096 10 March 31, 2018 rh drwxr-xr-x. 2 root root 4096 2 November 17:32 software [root@hadoop100 ~]# chown liyuhao:liyuhao /opt/module [root@hadoop100 ~]# chown liyuhao:liyuhao /opt/software [root@hadoop100 ~]# ll /opt/ Total consumption 12 drwxr-xr-x. 2 liyuhao liyuhao 4096 2 November 17:32 module drwxr-xr-x. 2 root root 4096 10 March 31, 2018 rh drwxr-xr-x. 2 liyuhao liyuhao 4096 2 November 17:32 software
7. Uninstall the JDK that comes with the virtual machine
[root@hadoop100 ~]# rpm -qa | grep -i java java-1.8.0-openjdk-headless-1.8.0.222.b03-1.el7.x86_64 python-javapackages-3.4.1-11.el7.noarch tzdata-java-2019b-1.el7.noarch java-1.7.0-openjdk-headless-1.7.0.221-2.6.18.1.el7.x86_64 javapackages-tools-3.4.1-11.el7.noarch java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64 java-1.7.0-openjdk-1.7.0.221-2.6.18.1.el7.x86_64 [root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps [root@hadoop100 ~]# rpm -qa | grep -i java [root@hadoop100 ~]#
rpm -qa: Query all installed rpm software package grep -i: ignore case xargs -n1: Indicates that only one parameter is passed at a time rpm -e –nodeps: Force uninstall software
8. Restart the virtual machine
reboot
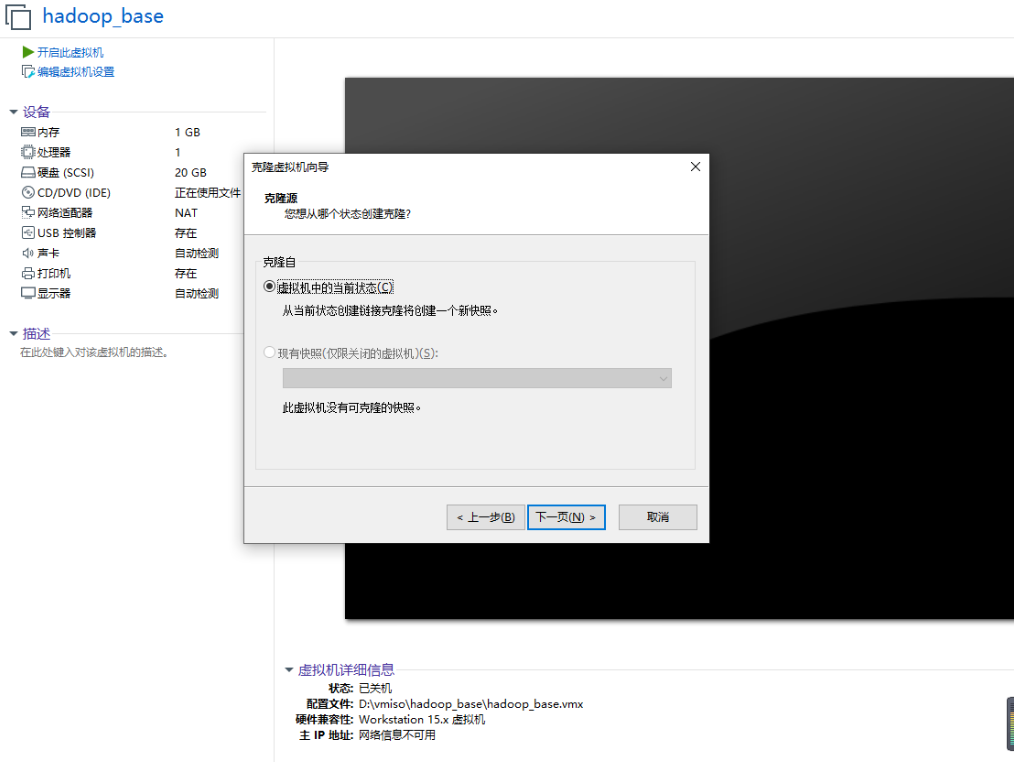
2, Clone virtual machine
1) Using the template machine Hadoop 100, clone three virtual machines: Hadoop 102, Hadoop 103, Hadoop 104
Note: when cloning, close Hadoop 100 first
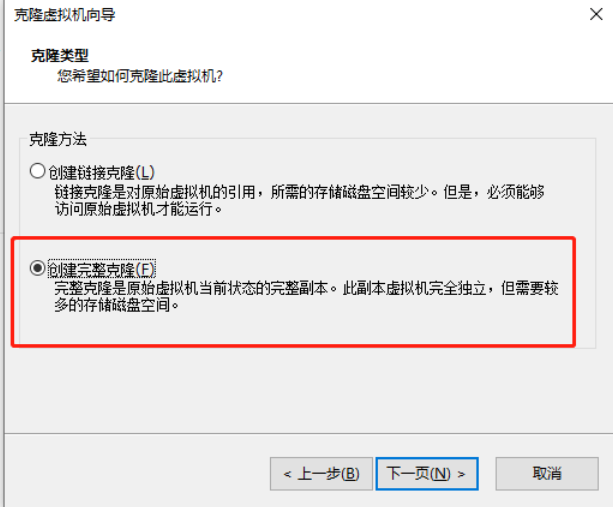
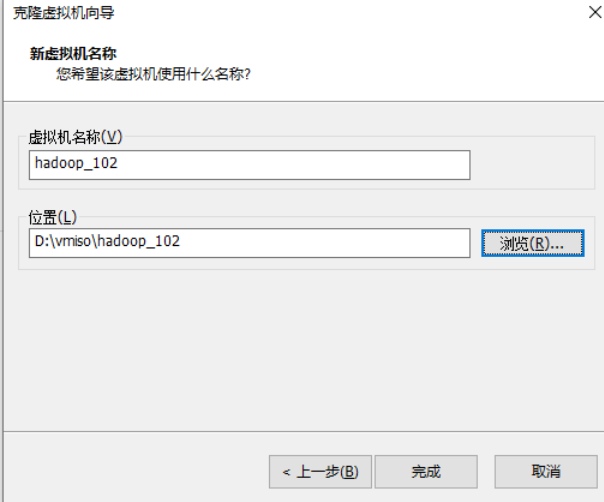
2) Modify the clone machine IP, which is illustrated by Hadoop 102 below
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 Change to BOOTPROTO=static IPADDR=192.168.10.102 GATEWAY=192.168.10.2 DNS1=192.168.10.2
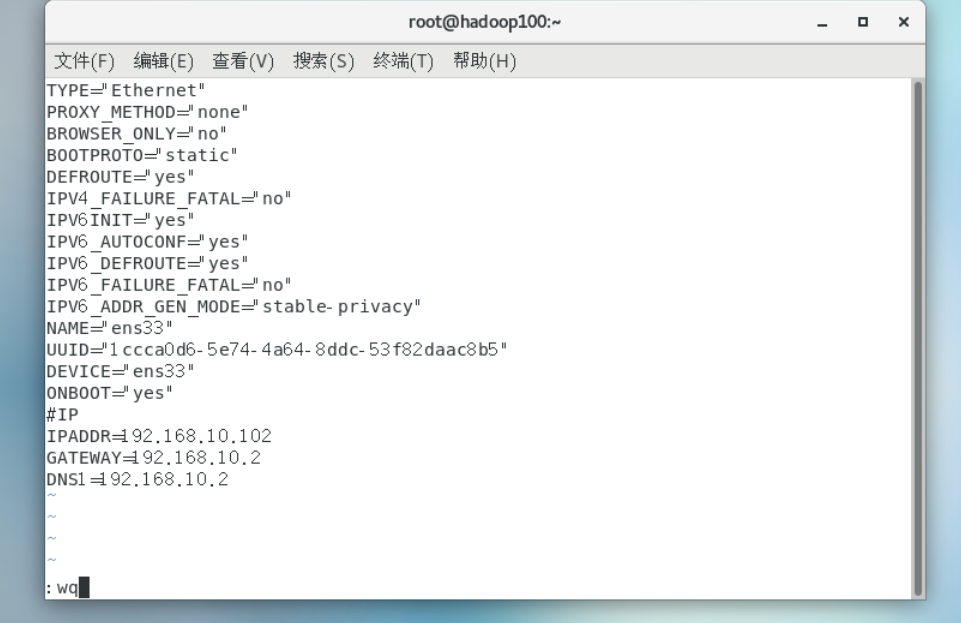
(1) Modify clone host name
[root@hadoop100 ~]# vim /etc/hostname hadoop102 Host name mapping hosts file [root@hadoop100 ~]# vim /etc/hosts
(2)reboot
3) Install JDK in Hadoop 102
1) Uninstall JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps [root@hadoop100 ~]# rpm -qa | grep -i java
2) Download from official website
https://www.java.com/zh-CN/download/manual.jsp
Import the JDK into the software folder under the opt directory with the XShell transport tool

3) Check whether the software package is imported successfully in opt directory under Linux system
[root@hadoop102 ~]# ls /opt/software/ jre-8u321-linux-x64.tar.gz
4) Unzip the JDK to the / opt/module directory
[root@hadoop102 software]# tar -zxvf jre-8u321-linux-x64.tar.gz -C /opt/module/
5) Configure JDK environment variables
(1) Create a new / etc / profile d/my_ env. SH file
[root@hadoop102 software]# vim /etc/profile.d/my_env.sh #JAVA_HOME export JAVA_HOME=/opt/module/jre1.8.0_321 export PATH=$PATH:$JAVA_HOME/bin
(2) source click the / etc/profile file to make the new environment variable PATH effective
[root@hadoop102 software]# source /etc/profile
(3) Test whether the JDK is installed successfully
[root@hadoop102 software]# java -version java version "1.8.0_321" Java(TM) SE Runtime Environment (build 1.8.0_321-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.321-b07, mixed mode)
4) Installing Hadoop on Hadoop 102
Hadoop download address: https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
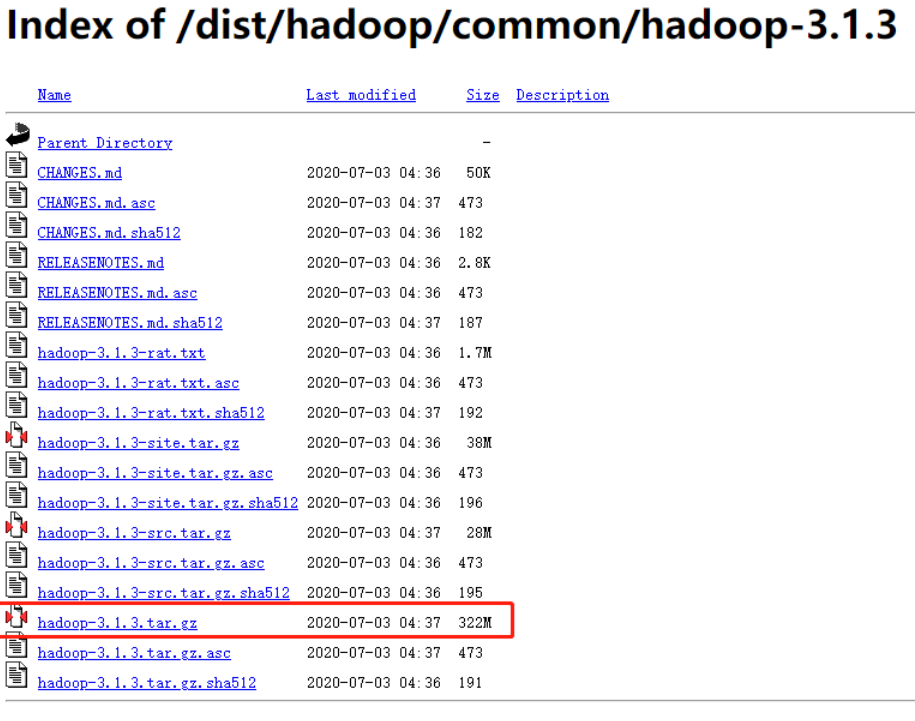
(1) Unzip the installation file under / opt/module
[root@hadoop102 module]# tar -cxvf hadoop-3.1.3.tar.gz -C /opt/module/ [root@hadoop102 module]# cd hadoop-3.1.3/ [root@hadoop102 hadoop-3.1.3]# ll Total consumption 200 drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 bin drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 etc drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 include drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 lib drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 libexec -rw-rw-r--. 1 lyh lyh 147145 9 April 2019 LICENSE.txt -rw-rw-r--. 1 lyh lyh 21867 9 April 2019 NOTICE.txt -rw-rw-r--. 1 lyh lyh 1366 9 April 2019 README.txt drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 sbin drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 share
(2) Add Hadoop to environment variable
Get Hadoop installation path
[root@hadoop102 hadoop-3.1.3]# pwd /opt/module/hadoop-3.1.3
Open / etc / profile d/my_ env. SH file
[root@hadoop102 hadoop-3.1.3]# sudo vim /etc/profile.d/my_env.sh #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
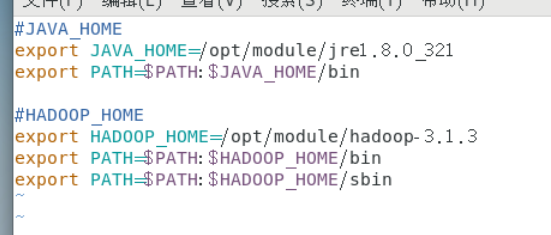
[root@hadoop102 hadoop-3.1.3]# source /etc/profile [root@hadoop102 hadoop-3.1.3]# hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
5) Directory structure of hadoop
[root@hadoop102 hadoop-3.1.3]# ll Total consumption 200 drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 bin drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 etc drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 include drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 lib drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 libexec -rw-rw-r--. 1 lyh lyh 147145 9 April 2019 LICENSE.txt -rw-rw-r--. 1 lyh lyh 21867 9 April 2019 NOTICE.txt -rw-rw-r--. 1 lyh lyh 1366 9 April 2019 README.txt drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 sbin drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 share
Important catalogue
(1) bin directory: stores scripts that operate Hadoop related services (hdfs, yarn, mapred)
(2) etc Directory: Hadoop configuration file directory, which stores Hadoop configuration files
(3) lib Directory: the local library where Hadoop is stored (the function of compressing and decompressing data)
(4) sbin Directory: stores scripts for starting or stopping Hadoop related services
(5) share Directory: stores the dependent jar packages, documents, and official cases of Hadoop
3, Hadoop operation mode
Hadoop operation modes include: local mode, pseudo distributed mode and fully distributed mode.
-
Local mode: stand-alone operation, just to demonstrate the official case. The production environment is not used. Data is stored locally in LINUX.
-
Pseudo distributed mode: it is also a stand-alone operation, but it has all the functions of Hadoop cluster. One server simulates a distributed environment. Individual companies that are short of money are used for testing, and the production environment is not used. Data storage HDFS.
-
Fully distributed mode: multiple servers form a distributed environment. Use in production environment. Data storage, HDFS, multiple servers.
1. Local operation mode (official WordCount)
1) Create a wcinput folder under the hadoop-3.1.3 file
[root@hadoop102 ~]# cd /opt/module/hadoop-3.1.3/ [root@hadoop102 hadoop-3.1.3]# mkdir wcinput [root@hadoop102 hadoop-3.1.3]# cd wcinput/ [root@hadoop102 wcinput]# vim word.txt [root@hadoop102 wcinput]# cat word.txt hadoop yarn hadoop mapreduce liyuhao liyuhao
2) Go back to Hadoop directory / opt/module/hadoop-3.1.3
[root@hadoop102 hadoop-3.1.3]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput [root@hadoop102 hadoop-3.1.3]# cat wcoutput/part-r-00000 hadoop 2 liyuhao 2 mapreduce 1 yarn 1
2. Fully distributed operation mode (development focus)
1. Write cluster distribution script
1) scp (secure copy)
(1) scp definition
scp can copy data between servers. (from server1 to server2)
(2) Basic grammar
scp -r $pdir/$fname $user@$host:$pdir/$fname Command recursion File path to copy/Name destination user@host:Destination path/name
Case practice
Premise: the / opt/module and / opt/software directories have been created in Hadoop 102, Hadoop 103 and Hadoop 104, and the two directories have been modified to root:root
sudo chown root:root -R /opt/module
(a) On Hadoop 102, add / opt / module / jdk1 8.0_ 212 directory to Hadoop 103.
[root@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 root@hadoop103:/opt/module
(b) On Hadoop 103, copy the / opt/module/hadoop-3.1.3 directory in Hadoop 102 to Hadoop 103.
[root@hadoop103 ~]$ scp -r root@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
(c) Operate on Hadoop 103 and copy all directories under / opt/module directory in Hadoop 102 to Hadoop 104.
[root@hadoop103 opt]$ scp -r root@hadoop102:/opt/module/* root@hadoop104:/opt/module
2) rsync remote synchronization tool
rsync is mainly used for backup and mirroring. It has the advantages of high speed, avoiding copying the same content and supporting symbolic links.
Difference between rsync and scp: copying files with rsync is faster than scp. rsync only updates the difference files. scp is to copy all the files.
(1) Basic grammar
rsync -av $pdir/$fname $user@$host:$pdir/$fname The command option parameter is the path of the file to be copied/Name destination user@host:Destination path/name Option parameter description option function -a Archive copy -v Show copy process
(2) Case practice
(a) Delete / opt/module/hadoop-3.1.3/wcinput in Hadoop 103
hadoop103
[root@hadoop103 hadoop-3.1.3]# ll Total consumption 208 drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 bin drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 etc drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 include drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 lib drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 libexec -rw-rw-r--. 1 lyh lyh 147145 9 April 2019 LICENSE.txt -rw-rw-r--. 1 lyh lyh 21867 9 April 2019 NOTICE.txt -rw-rw-r--. 1 lyh lyh 1366 9 April 2019 README.txt drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 sbin drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 share drwxr-xr-x. 2 root root 4096 2 June 17-16:45 wcinput drwxr-xr-x. 2 root root 4096 2 June 17-16:47 wcoutput [root@hadoop103 hadoop-3.1.3]# rm -rf wcinput/ [root@hadoop103 hadoop-3.1.3]# ll Total consumption 204 drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 bin drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 etc drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 include drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 lib drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 libexec -rw-rw-r--. 1 lyh lyh 147145 9 April 2019 LICENSE.txt -rw-rw-r--. 1 lyh lyh 21867 9 April 2019 NOTICE.txt -rw-rw-r--. 1 lyh lyh 1366 9 April 2019 README.txt drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 sbin drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 share drwxr-xr-x. 2 root root 4096 2 June 17-16:47 wcoutput
(b) Synchronize / opt/module/hadoop-3.1.3 in Hadoop 102 to Hadoop 103
hadoop102
[root@hadoop102 module]# rsync -av hadoop-3.1.3/ root@hadoop103:/opt/module/hadoop-3.1.3/ The authenticity of host 'hadoop103 (192.168.10.103)' can't be established. ECDSA key fingerprint is SHA256:01MEqjbUTtlwu/eeW4s/lw5f3Rg+IQfuc43NMVLqckk. ECDSA key fingerprint is MD5:ac:a2:7c:97:22:44:ba:31:1d:73:f2:67:28:cf:ba:a8. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop103,192.168.10.103' (ECDSA) to the list of known hosts. root@hadoop103's password: sending incremental file list ./ wcinput/ wcinput/word.txt sent 683,973 bytes received 2,662 bytes 16,953.95 bytes/sec total size is 844,991,426 speedup is 1,230.63
hadoop103
[root@hadoop103 hadoop-3.1.3]# ll Total consumption 208 drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 bin drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 etc drwxr-xr-x. 2 lyh lyh 4096 9 December 2019 include drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 lib drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 libexec -rw-rw-r--. 1 lyh lyh 147145 9 April 2019 LICENSE.txt -rw-rw-r--. 1 lyh lyh 21867 9 April 2019 NOTICE.txt -rw-rw-r--. 1 lyh lyh 1366 9 April 2019 README.txt drwxr-xr-x. 3 lyh lyh 4096 9 December 2019 sbin drwxr-xr-x. 4 lyh lyh 4096 9 December 2019 share drwxr-xr-x. 2 root root 4096 2 June 17-16:45 wcinput drwxr-xr-x. 2 root root 4096 2 June 17-16:47 wcoutput
3) xsync cluster distribution script
It is expected that the script can be used in any path (the script needs to be placed in the path where the global environment variable is declared)
Original copy of rsync command:
rsync -av /opt/module root@hadoop103:/opt/
(a) Create xsync file
View global variables
[root@hadoop102 home]# echo $PATH /usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin:/opt/module/jre1.8.0_321/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/root/bin:/opt/module/jre1.8.0_321/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin
Create xsync script
[root@hadoop102 bin]# vim xsync
#!/bin/bash
#1. Number of judgment parameters
if [ $# -lt 1 ]
# If the number of parameters is less than 1: no parameters are transferred
then
echo Not Enough Arguement!
exit;
fi
#2. Traverse all machines in the cluster
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. Traverse all directories and send them one by one
for file in $@
do
#4. Judge whether the document exists
if [ -e $file ]
then
#5. Get the current parent directory - P: soft connect wants to synchronize to the root directory
# Soft connect ln s aaa BBB CD - P BBB - > Enter aaa path
pdir=$(cd -P $(dirname $file); pwd)
#6. Get the name of the current file
fname=$(basename $file)
ssh $host "mkdir -p $pdir" # Create a file to the target host - p: create it regardless of whether the file name exists or not
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
(b) The modified script xsync has execution permission
[root@hadoop102 bin]# ll xsync -rw-r--r--. 1 root root 948 2 October 18:39 xsync [root@hadoop102 bin]# chmod +x xsync [root@hadoop102 bin]# ll xsync -rwxr-xr-x. 1 root root 948 2 October 18:39 xsync
(c) Copy the script to / bin for global invocation
[root@hadoop102 bin]# cp xsync /bin [root@hadoop102 bin]# cd /bin/ [root@hadoop102 bin]# ll | grep xsync -rwxr-xr-x. 1 root root 948 2 November 18:00 xsync
(d) Target document distribution and use
[root@hadoop102 bin]# xsync /bin/xsync ==================== hadoop102 ==================== root@hadoop102's password: root@hadoop102's password: sending incremental file list sent 43 bytes received 12 bytes 22.00 bytes/sec total size is 948 speedup is 17.24 ==================== hadoop103 ==================== root@hadoop103's password: root@hadoop103's password: sending incremental file list xsync sent 1,038 bytes received 35 bytes 429.20 bytes/sec total size is 948 speedup is 0.88 ==================== hadoop104 ==================== root@hadoop104's password: root@hadoop104's password: sending incremental file list xsync sent 1,038 bytes received 35 bytes 429.20 bytes/sec total size is 948 speedup is 0.88
(e) Distribute environment variables
[root@hadoop102 bin]# sudo /bin/xsync /etc/profile.d/my_env.sh ==================== hadoop102 ==================== root@hadoop102's password: root@hadoop102's password: sending incremental file list sent 48 bytes received 12 bytes 24.00 bytes/sec total size is 215 speedup is 3.58 ==================== hadoop103 ==================== root@hadoop103's password: root@hadoop103's password: sending incremental file list sent 48 bytes received 12 bytes 24.00 bytes/sec total size is 215 speedup is 3.58 ==================== hadoop104 ==================== root@hadoop104's password: root@hadoop104's password: sending incremental file list sent 48 bytes received 12 bytes 24.00 bytes/sec total size is 215 speedup is 3.58
Make environment variables effective
[root@hadoop103 bin]# source /etc/profile [root@hadoop104 bin]# source /etc/profile
3. SSH non secret login configuration
1. Configure ssh
Basic grammar
ssh Of another computer IP address
ssh connection:
[root@hadoop102 bin]# ssh hadoop103 root@hadoop103's password: Last login: Fri Feb 18 09:41:23 2022 [root@hadoop103 ~]# exit Log out Connection to hadoop103 closed.
2. Generate public and private keys
Now you want Hadoop 102 password free login 103 104
[root@hadoop102 .ssh]# pwd /root/.ssh [root@hadoop102 .ssh]# ll Total consumption 4 -rw-r--r--. 1 root root 558 2 November 18:16 known_hosts
ssh keygen - t RSA in. ssh directory,
Then click (three carriage returns) and two file IDS will be generated_ RSA (private key), id_rsa.pub (public key)
[root@hadoop102 .ssh]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:TFAcmwMOZ9pCsjsFiBFyFgcI8Qdo5uk17+flzOQEd+ root@hadoop102 The key's randomart image is: +---[RSA 2048]----+ |OBOo+ =oo. | |** B B o.o | |+ + = o = | | o * . o . . | |. + o .S. . . | | . . . o . . | | . + E | | . .O | +----[SHA256]-----+ [root@hadoop102 .ssh]# ll Total consumption 12 -rw-------. 1 root root 1675 2 June 18-13:45 id_rsa -rw-r--r--. 1 root root 396 2 June 18-13:45 id_rsa.pub -rw-r--r--. 1 root root 558 2 November 18:16 known_hosts
(3) Copy the Hadoop 102 public key to the target machine for password free login
[root@hadoop102 .ssh]# ssh-copy-id hadoop103 /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@hadoop103's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'hadoop103'" and check to make sure that only the key(s) you wanted were added. [root@hadoop102 .ssh]# ssh hadoop103 Last login: Fri Feb 18 13:38:22 2022 from hadoop102 [root@hadoop103 ~]# exit Log out Connection to hadoop103 closed.
(4) Distribute data
[root@hadoop102 bin]# xsync test.txt ==================== hadoop102 ==================== root@hadoop102's password: sending incremental file list sent 46 bytes received 12 bytes 16.57 bytes/sec total size is 0 speedup is 0.00 ==================== hadoop103 ==================== sending incremental file list test.txt sent 89 bytes received 35 bytes 82.67 bytes/sec total size is 0 speedup is 0.00 ==================== hadoop104 ==================== sending incremental file list test.txt sent 89 bytes received 35 bytes 82.67 bytes/sec total size is 0 speedup is 0.00
3,. Explanation of file functions under the ssh folder (~ /. ssh)
known_hosts record ssh Access the public key of the computer( public key) id_rsa Generated private key id_rsa.pub Generated public key authorized_keys Store the authorized secret free login server public key
4. Cluster configuration
1) Cluster deployment planning
be careful:
1. NameNode and SecondaryNameNode should not be installed on the same server
2. Resource manager also consumes a lot of memory and should not be configured on the same machine as NameNode and SecondaryNameNode.
hadoop102 hadoop103 hadoop104 HDFS NameNode SecondaryNameNode YARN ResourceManager
2) Configuration file
core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml four configuration files are stored in $Hadoop_ On the path of home / etc / Hadoop, users can modify the configuration again according to the project requirements.
[root@hadoop102 hadoop]# pwd /opt/module/hadoop-3.1.3/etc/hadoop [root@hadoop102 hadoop]# ll | grep site.xml -rw-r--r--. 1 lyh lyh 774 9 December 2019 core-site.xml -rw-r--r--. 1 lyh lyh 775 9 December 2019 hdfs-site.xml -rw-r--r--. 1 lyh lyh 620 9 December 2019 httpfs-site.xml -rw-r--r--. 1 lyh lyh 682 9 December 2019 kms-site.xml -rw-r--r--. 1 lyh lyh 758 9 December 2019 mapred-site.xml -rw-r--r--. 1 lyh lyh 690 9 December 2019 yarn-site.xml
3) Configure cluster
(1) Core profile
Configure core site XML, add content in < configuration >
[root@hadoop102 hadoop]# cd $HADOOP_HOME/etc/hadoop [root@hadoop102 hadoop]# vim core-site.xml
?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- appoint NameNode Address of -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- appoint hadoop Storage directory of data -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- to configure HDFS The static user used for web page login is root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
(2) HDFS profile
[root@hadoop102 hadoop]# vim hdfs-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web End access address-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web End access address-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
(3) YARN profile
Note that the value of value must not have spaces or indents!!!
[root@hadoop102 hadoop]# vim yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- appoint MR go shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- appoint ResourceManager Address of -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- Inheritance of environment variables -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
(4) MapReduce profile
Configure mapred site xml
[root@hadoop102 hadoop]# vim mapred-site.xml [root@hadoop102 hadoop]# cat mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- appoint MapReduce The program runs on Yarn upper -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
</configuration>
4) Distribute the configured Hadoop configuration file on the cluster
[root@hadoop102 hadoop]# xsync /opt/module/hadoop-3.1.3/etc/hadoop/ ==================== hadoop102 ==================== root@hadoop102's password: root@hadoop102's password: sending incremental file list sent 989 bytes received 18 bytes 402.80 bytes/sec total size is 107,799 speedup is 107.05 ==================== hadoop103 ==================== sending incremental file list hadoop/ hadoop/core-site.xml hadoop/hdfs-site.xml hadoop/mapred-site.xml hadoop/yarn-site.xml sent 3,633 bytes received 139 bytes 2,514.67 bytes/sec total size is 107,799 speedup is 28.58 ==================== hadoop104 ==================== sending incremental file list hadoop/ hadoop/core-site.xml hadoop/hdfs-site.xml hadoop/mapred-site.xml hadoop/yarn-site.xml sent 3,633 bytes received 139 bytes 7,544.00 bytes/sec total size is 107,799 speedup is 28.58
5) Go to 103 and 104 to check the distribution of documents
[root@hadoop103 ~]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml [root@hadoop104 ~]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
5. Group together
1) Configure workers
[root@hadoop102 hadoop]# vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
Add the following contents to the document:
hadoop102 hadoop103 hadoop104
Note: no space is allowed at the end of the content added in the file, and no blank line is allowed in the file.
Synchronize all node profiles
[root@hadoop102 hadoop]# xsync /opt/module/hadoop-3.1.3/etc/ ==================== hadoop102 ==================== sending incremental file list sent 1,014 bytes received 19 bytes 2,066.00 bytes/sec total size is 107,829 speedup is 104.38 ==================== hadoop103 ==================== sending incremental file list etc/hadoop/ etc/hadoop/workers sent 1,104 bytes received 51 bytes 2,310.00 bytes/sec total size is 107,829 speedup is 93.36 ==================== hadoop104 ==================== sending incremental file list etc/hadoop/ etc/hadoop/workers sent 1,104 bytes received 51 bytes 2,310.00 bytes/sec total size is 107,829 speedup is 93.36 [root@hadoop102 hadoop]# ssh hadoop103 Last login: Mon Feb 21 14:58:42 2022 from hadoop102 [root@hadoop103 ~]# cat /opt/module/hadoop-3.1.3/etc/hadoop/workers localhost hadoop102 hadoop103 hadoop104 [root@hadoop103 ~]# exit Log out Connection to hadoop103 closed. [root@hadoop102 hadoop]# ssh hadoop104 Last login: Mon Feb 21 14:59:14 2022 from hadoop102 [root@hadoop104 ~]# cat /opt/module/hadoop-3.1.3/etc/hadoop/workers localhost hadoop102 hadoop103 hadoop104
2) Start cluster
(1) If the cluster is started for the first time, The namenode needs to be formatted in the Hadoop 102 node (Note: formatting namenode will generate a new cluster id, which will lead to the inconsistency between the cluster IDs of namenode and datanode, and the cluster cannot find the past data. If the cluster reports an error during operation and needs to reformat namenode, be sure to stop the namenode and datanode process first, and delete the data and logs directories of all machines before formatting.)
[root@hadoop102 hadoop]# cd /opt/module/hadoop-3.1.3/ [root@hadoop102 hadoop-3.1.3]# hdfs namenode -format
(2) Start HDFS
[root@hadoop102 hadoop-3.1.3]# sbin/start-dfs.sh
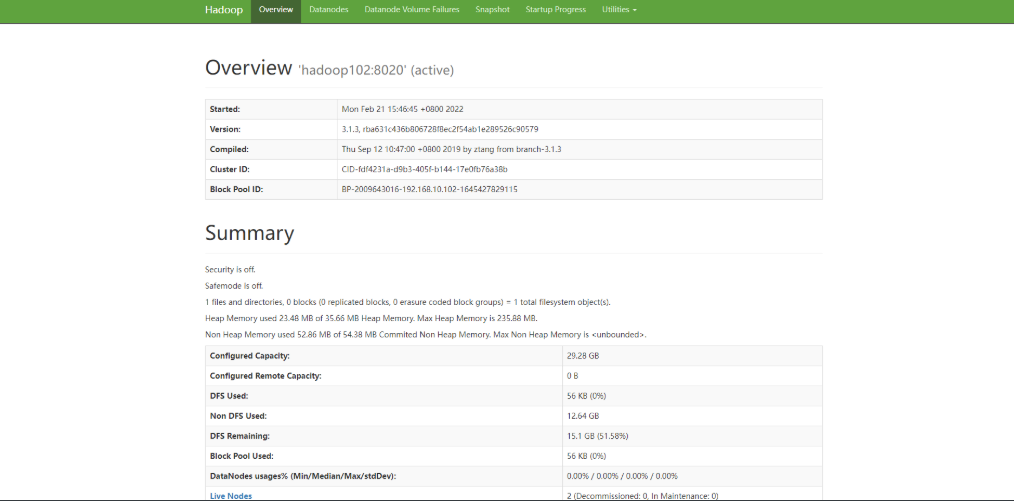
View the NameNode of HDFS on the Web side
(a) Enter in the browser: http://hadoop102:9870
(b) View data information stored on HDFS
(3) Start YARN on the node (Hadoop 103) where the resource manager is configured
[root@hadoop103 hadoop-3.1.3]# cd /opt/module/hadoop-3.1.3/ [root@hadoop103 hadoop-3.1.3]# sbin/start-yarn.sh
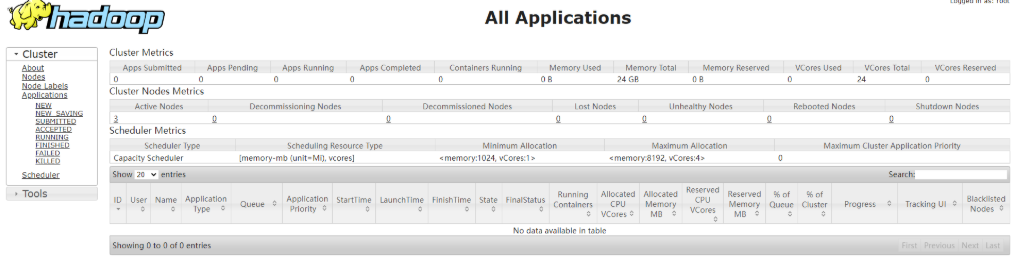
View YARN's ResourceManager on the Web
(a) Enter in the browser: http://hadoop103:8088
(b) View Job information running on YARN
3) Cluster Basic test
(1) Upload files to cluster
Upload small files
[root@hadoop102 ~]# hadoop fs -mkdir /input
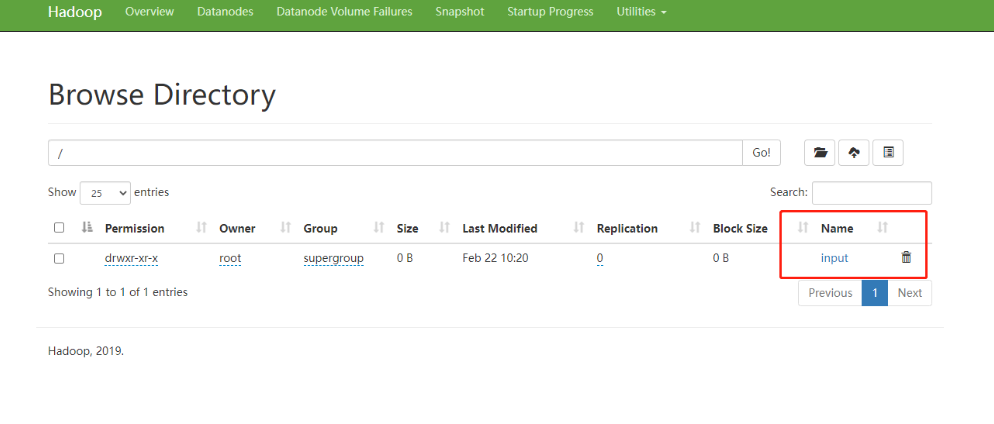
[root@hadoop102 ~]# vim test.txt [root@hadoop102 ~]# hadoop fs -put /root/test.txt /input 2022-02-22 10:30:05,347 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
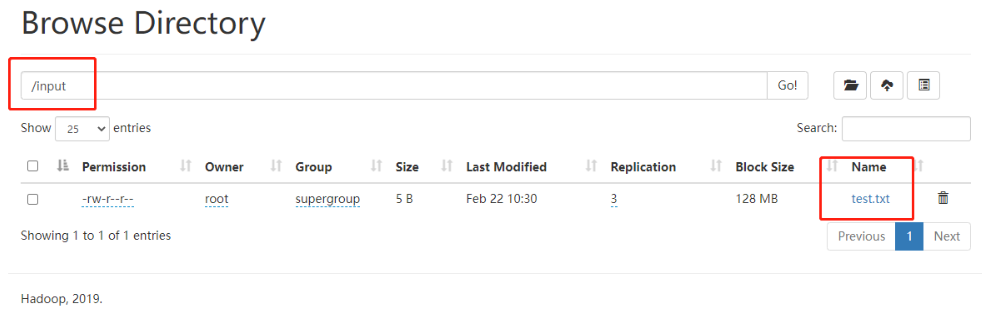
(2) View HDFS file storage path
[root@hadoop102 ~]# cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-2009643016-192.168.10.102-1645427829115/current/finalized/subdir0/subdir0 [root@hadoop102 subdir0]# ll Total consumption 8 -rw-r--r--. 1 root root 5 2 October 22:30 blk_1073741825 -rw-r--r--. 1 root root 11 2 October 22:30 blk_1073741825_1001.meta
(3) View the contents of files stored on disk by HDFS
[root@hadoop102 subdir0]# cat blk_1073741825 test
(4) Download File
[root@hadoop102 ~]# ll Total dosage 40 -rw-------. 1 root root 1685 2 October 17:28 anaconda-ks.cfg ... [root@hadoop102 ~]# hadoop fs -get /input/test.txt 2022-02-22 10:55:07,798 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [root@hadoop102 ~]# ll Total consumption 44 -rw-------. 1 root root 1685 2 October 17:28 anaconda-ks.cfg -rw-r--r--. 1 root root 5 2 October 22:55 test.txt ...
(5) Execute the wordcount program
[root@hadoop102 hadoop-3.1.3]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output [root@hadoop102 wcoutput]# hadoop fs -get /output 2022-02-23 11:04:39,586 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [root@hadoop102 wcoutput]# cd output/ [root@hadoop102 output]# ll Total consumption 4 -rw-r--r--. 1 root root 7 2 November 23:04 part-r-00000 -rw-r--r--. 1 root root 0 2 November 23:04 _SUCCESS [root@hadoop102 output]# cat part-r-00000 test 1
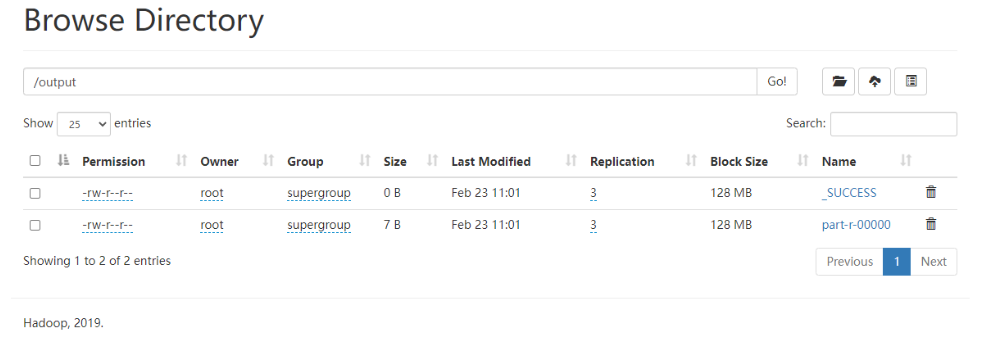
6. Configure history server
In order to view the historical operation of the program, you need to configure the history server. The specific configuration steps are as follows:
1) Configure mapred site xml
[root@hadoop102 hadoop-3.1.3]# vim etc/hadoop/mapred-site.xml
Add history server content
<!-- Historical server address -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- History server web End address -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
2) Distribute
[root@hadoop102 hadoop-3.1.3]# xsync etc/hadoop/mapred-site.xml ==================== hadoop102 ==================== sending incremental file list sent 64 bytes received 12 bytes 152.00 bytes/sec total size is 1,554 speedup is 20.45 ==================== hadoop103 ==================== sending incremental file list mapred-site.xml sent 969 bytes received 47 bytes 677.33 bytes/sec total size is 1,554 speedup is 1.53 ==================== hadoop104 ==================== sending incremental file list mapred-site.xml sent 969 bytes received 47 bytes 677.33 bytes/sec total size is 1,554 speedup is 1.53
3) Start the history server in Hadoop 102
[root@hadoop102 hadoop-3.1.3]# mapred --daemon start historyserver
4) View process
[root@hadoop102 hadoop]# jps 111254 Jps 110649 JobHistoryServer 46056 NameNode 109448 NodeManager 46237 DataNode
5) View JobHistory
http://hadoop102:19888/jobhistory

7. Configure log aggregation
Log aggregation concept: after the application runs, upload the program running log information to the HDFS system.
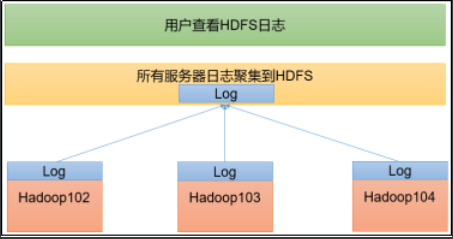
Benefits of log aggregation function: you can easily view the details of program operation, which is convenient for development and debugging.
Note: to enable the log aggregation function, you need to restart NodeManager, ResourceManager and HistoryServer.
1) Configure yarn site xml
[root@hadoop102 hadoop]# vim yarn-site.xml
Add log aggregation function
<!-- Enable log aggregation -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- Set log aggregation server address -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- Set the log retention time to 7 days -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2) Distribute
[root@hadoop102 hadoop]# xsync yarn-site.xml ==================== hadoop102 ==================== sending incremental file list sent 62 bytes received 12 bytes 148.00 bytes/sec total size is 2,097 speedup is 28.34 ==================== hadoop103 ==================== sending incremental file list yarn-site.xml sent 814 bytes received 53 bytes 1,734.00 bytes/sec total size is 2,097 speedup is 2.42 ==================== hadoop104 ==================== sending incremental file list yarn-site.xml sent 814 bytes received 53 bytes 1,734.00 bytes/sec total size is 2,097 speedup is 2.42
3) Close NodeManager, ResourceManager, and HistoryServer
[root@hadoop103 sbin]# stop-yarn.sh [root@hadoop102 hadoop]# mapred --daemon stop historyserver [root@hadoop103 sbin]# start-yarn.sh [root@hadoop102 hadoop]# mapred --daemon start historyserver
4) Test and delete the existing output files on HDFS
hadoop fs -rm -r /output
5) Execute wordcount
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
6) View log
(1) historical server address
http://hadoop102:19888/jobhistory
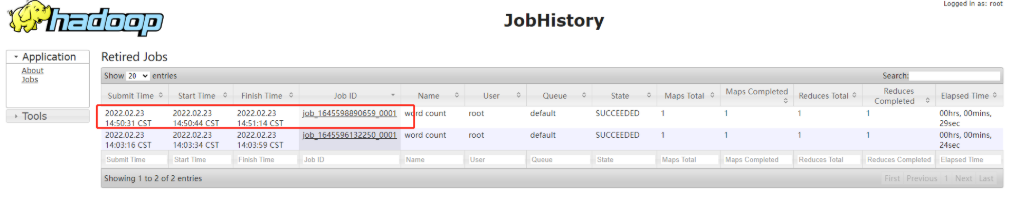
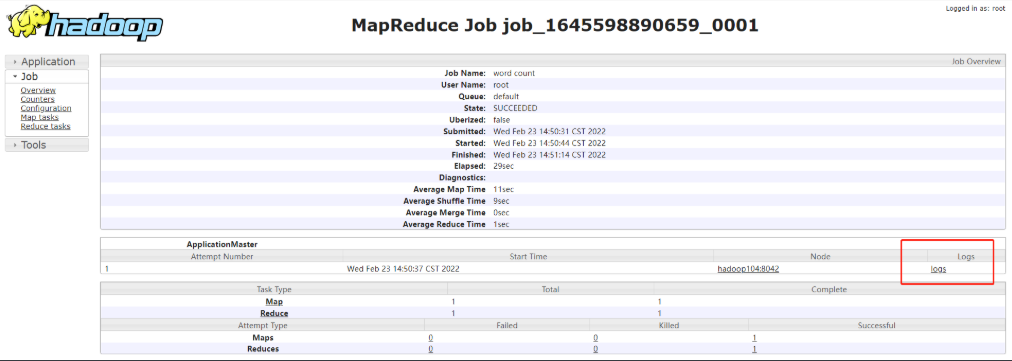
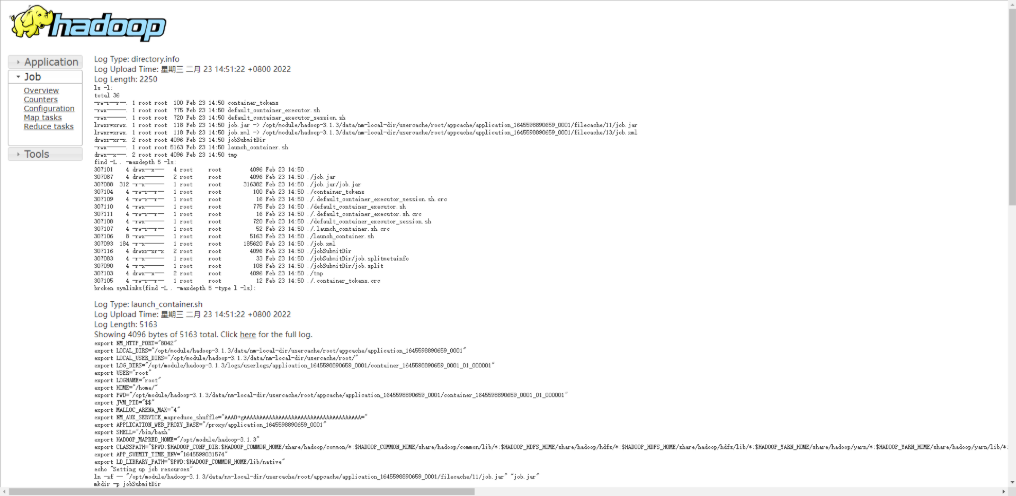
8. Summary of cluster start / stop modes
1) Each module starts / stops separately (ssh configuration is the premise)
(1) Overall start / stop HDFS
start-dfs.sh stop-dfs.sh
(2) Overall start / stop of YARN
start-yarn.sh stop-yarn.sh
2) Each service component starts / stops one by one
(1) Start / stop HDFS components respectively
hdfs --daemon start namenode/datanode/secondarynamenode hdfs --daemon stop namenode/datanode/secondarynamenode
(2) Start / stop YARN
yarn --daemon start resourcemanager/nodemanager yarn --daemon stop resourcemanager/nodemanager
9. Write common scripts for Hadoop cluster
1) Hadoop cluster startup and shutdown script (including HDFS, Yan and Historyserver): myhadoop sh
Put in / bin / directory
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== start-up hadoop colony ==================="
echo " --------------- start-up hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- start-up yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- start-up historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== close hadoop colony ==================="
echo " --------------- close historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- close yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- close hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
10. Common port number Description
Port name Hadoop2.x Hadoop3.x NameNode Internal communication port 8020 / 9000 8020 / 9000/9820 NameNode HTTP UI 50070 9870 MapReduce View task execution port 8088 8088 History server communication port 19888 19888
11. Cluster time synchronization
If the server is in the public network environment (can connect to the external network), cluster time synchronization can not be adopted, because the server will calibrate with the public network time regularly;
If the server is in the Intranet environment, the cluster time synchronization must be configured, otherwise the time deviation will occur after a long time, resulting in the asynchronous execution of tasks by the cluster.
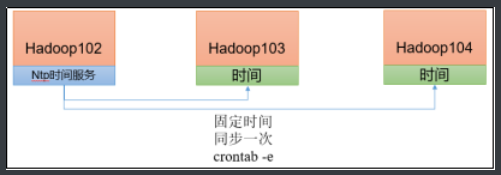
1) Demand
Find a machine as a time server. All machines are synchronized with the cluster time regularly. The production environment requires periodic synchronization according to the accuracy of the task to the time. In order to see the effect as soon as possible, the test environment adopts one minute synchronization.
2) Time server configuration (must be root)
(1) View ntpd service status and startup and self startup status of all nodes
[root@hadoop102 ~]$ sudo systemctl status ntpd [root@hadoop102 ~]$ sudo systemctl start ntpd [root@hadoop102 ~]$ sudo systemctl is-enabled ntpd
(2) Modify NTP of Hadoop 102 Conf configuration file
[root@hadoop102 ~]$ sudo vim /etc/ntp.conf
(a) Modify 1 (authorize all machines in the 192.168.10.0-192.168.10.255 network segment to query and synchronize time from this machine)
#restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap by restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
(b) Modification 2 (cluster in LAN, do not use time on other Internet)
server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst by #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst
(c) Add 3 (when the node loses network connection, the local time can still be used as the time server to provide time synchronization for other nodes in the cluster)
server 127.127.1.0 fudge 127.127.1.0 stratum 10
(3) Modify the / etc/sysconfig/ntpd file of Hadoop 102
[root@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd
Add the following contents (synchronize the hardware time with the system time)
SYNC_HWCLOCK=yes
(4) Restart ntpd service
[root@hadoop102 ~]$ sudo systemctl start ntpd
(5) Set ntpd service startup
[root@hadoop102 ~]$ sudo systemctl enable ntpd
3) Other machine configurations (must be root)
(1) Turn off ntp service and self startup on all nodes
[root@hadoop103 ~]$ sudo systemctl stop ntpd [root@hadoop103 ~]$ sudo systemctl disable ntpd [root@hadoop104 ~]$ sudo systemctl stop ntpd [root@hadoop104 ~]$ sudo systemctl disable ntpd
(2) Configure other machines to synchronize with the time server once a minute
[root@hadoop103 ~]$ sudo crontab -e
The scheduled tasks are as follows:
*/1 * * * * /usr/sbin/ntpdate hadoop102
(3) Modify any machine time
[root@hadoop103 ~]$ sudo date -s "2021-9-11 11:11:11"
(4) Check whether the machine is synchronized with the time server after 1 minute
[root@hadoop103 ~]$ sudo date
$ sudo vim /etc/ntp.conf
(a)Amendment 1 (authorization 192).168.10.0-192.168.10.255 All machines on the network segment can query and synchronize time from this machine) ```shell #restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap by restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
(b) Modification 2 (cluster in LAN, do not use time on other Internet)
server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst by #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst
(c) Add 3 (when the node loses network connection, the local time can still be used as the time server to provide time synchronization for other nodes in the cluster)
server 127.127.1.0 fudge 127.127.1.0 stratum 10
(3) Modify the / etc/sysconfig/ntpd file of Hadoop 102
[root@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd
Add the following contents (synchronize the hardware time with the system time)
SYNC_HWCLOCK=yes
(4) Restart ntpd service
[root@hadoop102 ~]$ sudo systemctl start ntpd
(5) Set ntpd service startup
[root@hadoop102 ~]$ sudo systemctl enable ntpd
3) Other machine configurations (must be root)
(1) Turn off ntp service and self startup on all nodes
[root@hadoop103 ~]$ sudo systemctl stop ntpd [root@hadoop103 ~]$ sudo systemctl disable ntpd [root@hadoop104 ~]$ sudo systemctl stop ntpd [root@hadoop104 ~]$ sudo systemctl disable ntpd
(2) Configure other machines to synchronize with the time server once a minute
[root@hadoop103 ~]$ sudo crontab -e
The scheduled tasks are as follows:
*/1 * * * * /usr/sbin/ntpdate hadoop102
(3) Modify any machine time
[root@hadoop103 ~]$ sudo date -s "2021-9-11 11:11:11"
(4) Check whether the machine is synchronized with the time server after 1 minute
[root@hadoop103 ~]$ sudo date