Hadoop distributed file system
brief introduction
HDFS (Hadoop distributed file system) is a core component of Hadoop and a distributed storage service
Distributed file systems can span polymorphic computers. It has a wide application prospect in the era of big data. They provide the required expansion capability for storing and processing super large-scale data.
HDFS is a kind of distributed file system
concept
HDFS locates files through a unified namespace directory tree
The function is realized through the association of polymorphic servers, and the servers in the cluster have their own roles (the essence of distribution is to split and perform their own duties)
-
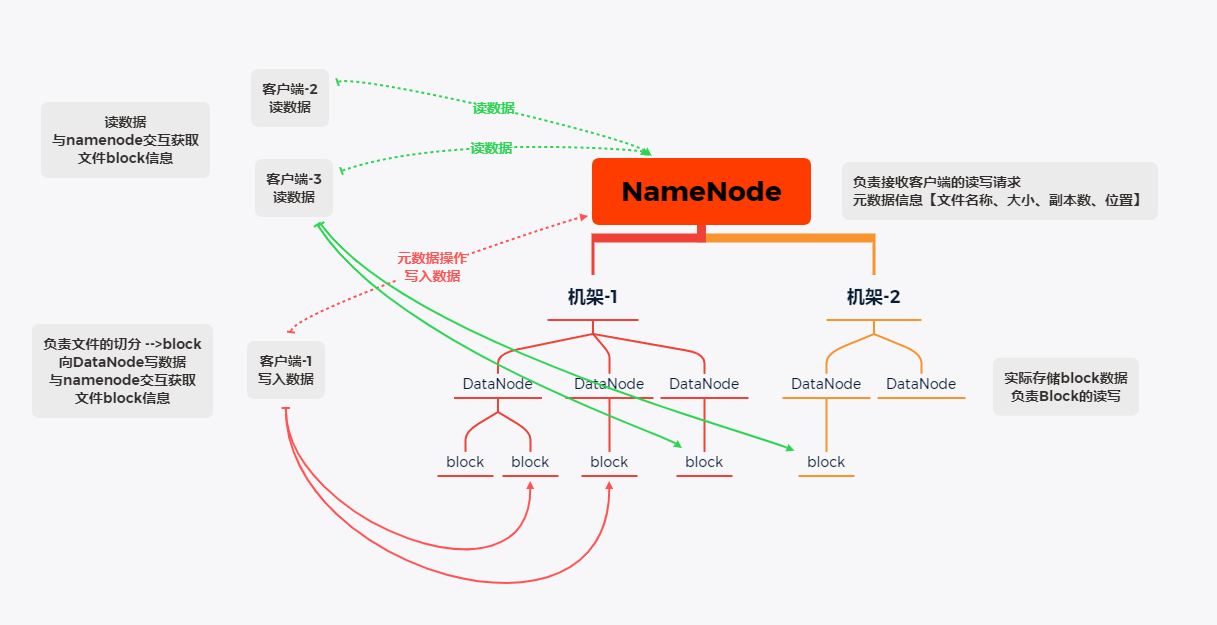
Typical Master/Slave architecture
HDFS clusters are often composed of one NameNode + multiple datanodes
NameNode is the master node of the cluster, and DataNode is the slave node of the cluster
The HA architecture has two namenodes, the Federation mechanism
-
Split fast storage (block mechanism)
The files in HDFS are physically stored in blocks, and the block size can be determined by configuration parameters
Hadoop 2. The default block in the X version is 128M
-
Namespace
HDFS supports traditional hierarchical file organization. Users or applications can create directories and save files in these directories.
The file system namespace hierarchy is similar to most file systems: you can create, delete, move, rename files, and so on
NameNode is responsible for maintaining the file system namespace. Any modification to the file system namespace or attributes will be recorded by NameNode
HDFS provides an abstract directory tree in the form of access hdfs://namenode Host name: port file path
For example: hdfs://linux121:9000/test/inpu
-
NameNode metadata management
The directory structure and file block location information are called metadata
The metadata of NameNode records the block information corresponding to each file (block id, information of the DataNode where it is located)
-
DataNode datastore
The specific storage management of each block of the file is undertaken by the DataNode node; A block will have multiple datanodes to store
DataNode will regularly report the block information it holds to NameNode
-
Replica mechanism
For fault tolerance, all blocks of the file will have copies. The block size and copy factor of each file are configurable. The application can specify the number of copies of a file.
The number of copies can be specified when the file is created or changed later.
Number of copies: 3
When the number of replicas exceeds the number of datanodes, the maximum is the number of datanodes
-
Write once, read many times
HDFS is designed according to the scene of one write and multiple read.
Random modification (update) of files is not supported, and additional writing is supported
HDFS is suitable for the underlying storage service for big data analysis, but it is not suitable for network disk and other applications. The main reasons are: inconvenient modification, large delay, large network overhead and high cost
framework
- NameNode (nn): manager of HDFS cluster, Master
- Maintain and manage HDFS namespaces
- Maintain replica policy
- Record the mapping information of file block information
- Responsible for client read and write requests
- DataNode (dn): execute the actual operation, Slave
- Save actual data block
- Responsible for reading and writing data
- Client: client
- When uploading files, be responsible for file block segmentation and then upload
- Interact with NameNode to obtain the location information of the file
- When reading or writing, interact with DataNode to read and write
- Use some commands to manage and access HDFS
shell command operation HDFS
-
Basic grammar
Method 1: bin/hadoop fs specific command
Mode 2: bin/hadoop dfs specific command
-
View all commands
bin/hdfs dfs
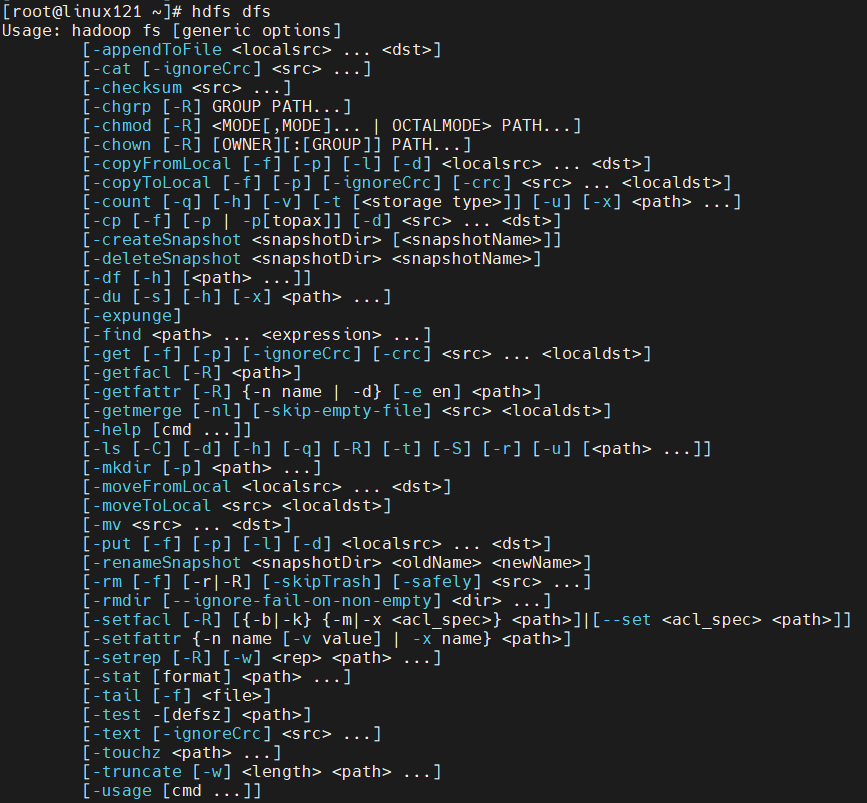
Most HDFS operation commands are equivalent to those under Linux, but they need to be added before the command-
View command parameters
-
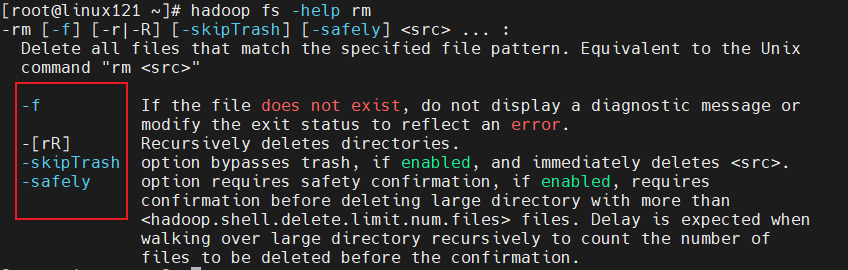
-Help: output the parameters of this command hadoop fs -help command
For example: hadoop fs -help rm
1. Display directory information - ls
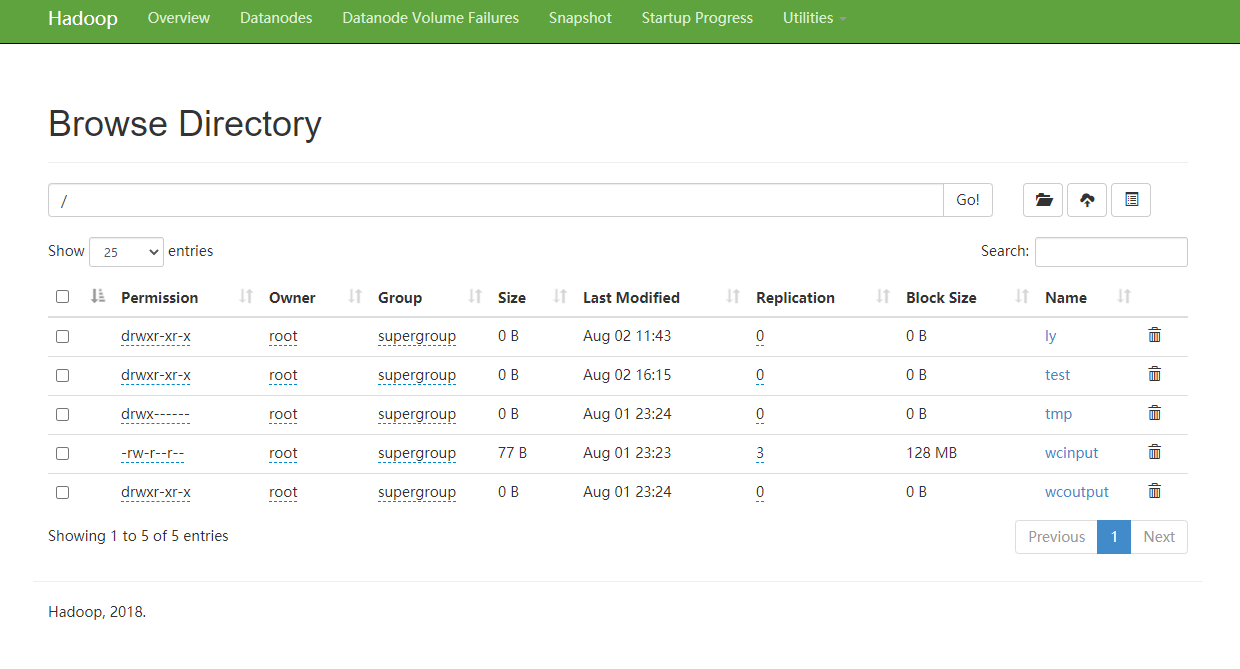
[root@linux121 testfile]# hadoop fs -ls / Found 4 items drwxr-xr-x - root supergroup 0 2021-08-02 16:15 /test drwx------ - root supergroup 0 2021-08-01 23:24 /tmp -rw-r--r-- 3 root supergroup 77 2021-08-01 23:23 /wcinput drwxr-xr-x - root supergroup 0 2021-08-01 23:24 /wcoutput
The parameters that can be added are shown in the following figure:

View via web url: http://linux:50070/explorer.html#/ly/test The host name should be based on the host ip address you set
2. Create directory - mkdir on HDFS
[root@linux121 ~]# hadoop fs -mkdir -p /ly/test [root@linux121 ~]# hadoop fs -ls / Found 5 items drwxr-xr-x - root supergroup 0 2021-08-02 11:43 /ly drwxr-xr-x - root supergroup 0 2021-08-01 23:18 /test drwx------ - root supergroup 0 2021-08-01 23:24 /tmp -rw-r--r-- 3 root supergroup 77 2021-08-01 23:23 /wcinput drwxr-xr-x - root supergroup 0 2021-08-01 23:24 /wcoutput
3. Copy files
-
Move from local to HDFS: hadoop fs -moveFromLocal move the moved file name to a directory in HDFS
# Create files locally [root@linux121 testfile]# vim hadoop.txt # Move to HDFS [root@linux121 testfile]# hadoop fs -moveFromLocal hadoop.txt /ly/test
-
Copy local files to HDFS - put [recommended] - copyFromLocal
# Create files and add content [root@linux121 testfile]# vim copyfile.txt [root@linux121 testfile]# ls copyfile.txt hadoop.txt # Use the - put command [root@linux121 testfile]# hadoop fs -put copyfile.txt /ly/test # Use - copyFromLocal [root@linux121 testfile]# hadoop fs -copyFromLocal copyfile.txt /ly/test
-
Copy files from HDFS to local - get [recommended] - copyToLocal
# Delete local file [root@linux121 testfile]# rm -f copyfile.txt [root@linux121 testfile]# ls hadoop.txt # Use - get [root@linux121 testfile]# hadoop fs -get /ly/test/copyfile.txt ./ # Use - copyToLocal [root@linux121 testfile]# hadoop fs -copyToLocal /ly/test/copyfile.txt ./ [root@linux121 testfile]# ls copyfile.txt hadoop.txt
-
Copy from one path of HDFS to another path of HDFS - cp
# Add hadoop.exe in / ly/test / directory Txt to the root directory [root@linux121 testfile]# hadoop fs -cp /ly/test/hadoop.txt /
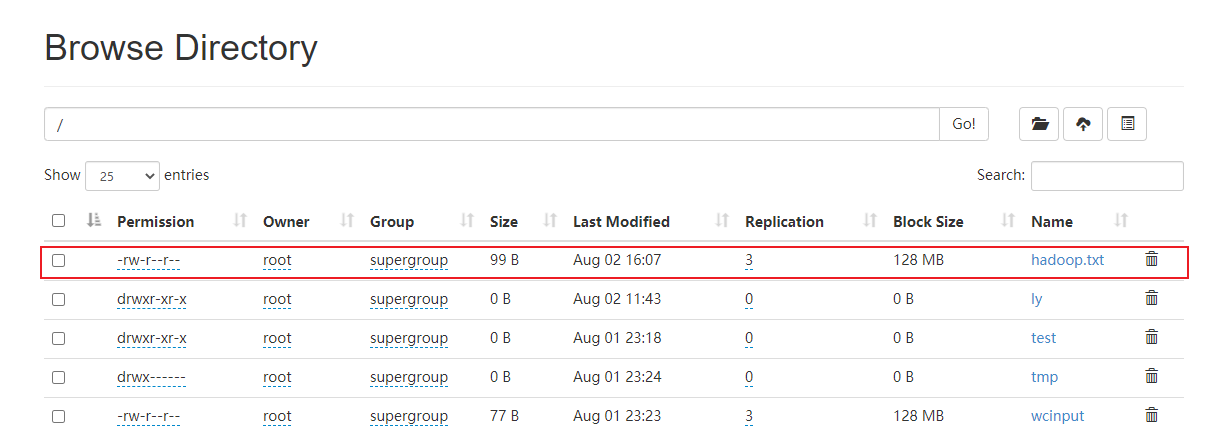
4. Delete the file - rm -rmdir
# Delete hadoop.exe moved to the root directory Txt file [root@linux121 testfile]# hadoop fs -rm /hadoop.txt Deleted /hadoop.txt # Delete empty directory [root@linux121 testfile]# hadoop fs -mkdir /delete [root@linux121 testfile]# hadoop fs -rmdir /delete
5. Move files -mv
# View file information in directory [root@linux121 testfile]# hadoop fs -ls /test Found 1 items drwxr-xr-x - root supergroup 0 2021-08-01 23:19 /test/input [root@linux121 testfile]# hadoop fs -ls /ly/test Found 2 items -rw-r--r-- 3 root supergroup 22 2021-08-02 15:54 /ly/test/copyfile.txt -rw-rw-rw- 3 root root 99 2021-08-02 15:25 /ly/test/hadoop.txt # Add hadoop.exe in the / ly/test directory Txt file to / test directory [root@linux121 testfile]# hadoop fs -mv /ly/test/hadoop.txt /test [root@linux121 testfile]# hadoop fs -ls /test Found 2 items -rw-rw-rw- 3 root root 99 2021-08-02 15:25 /test/hadoop.txt drwxr-xr-x - root supergroup 0 2021-08-01 23:19 /test/input
6. Additions at the end of the document
# Create a file and add additional content as needed [root@linux121 testfile]# vim hadoopappend.txt [root@linux121 testfile]# hadoop fs -appendToFile hadoopappend.txt /ly/test/hadoop.txt
7. View content - cat -tail
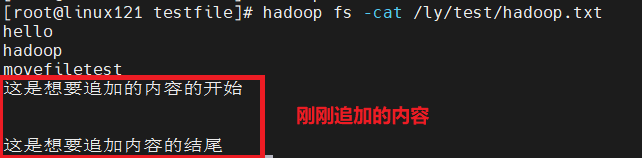
# Displays the end of the file [root@linux121 testfile]# hadoop fs -tail /test/hadoop.txt hello hadoop movefiletest This is the beginning of what you want to add This is the end of what you want to add
8. Permission to modify files
# File permissions chmod [root@linux121 testfile]# hadoop fs -chmod 666 /ly/test/hadoop.txt # File user chown [root@linux121 testfile]# hadoop fs -chown root /ly/test/hadoop.txt # File user group chgrp [root@linux121 testfile]# hadoop fs -chgrp root /ly/test/hadoop.txt # View modified file properties [root@linux121 testfile]# hadoop fs -ls -h /ly/test/ Found 1 items -rw-rw-rw- 3 root root 99 2021-08-02 15:25 /ly/test/hadoop.txt
9. Statistical file information -du
# Count the total size of the folder [root@linux121 testfile]# hadoop fs -du -s -h /test 130 /test # Displays the size of files and folders [root@linux121 testfile]# hadoop fs -du -h /test 99 /test/hadoop.txt 31 /test/input
10. Set the number of copies - setrep
[root@linux121 testfile]# hadoop fs -setrep 5 /test/hadoop.txt Replication 5 set: /test/hadoop.txt
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-iXRhG26P-1627894430116)(Hadoop distributed file system. assets/image-20210802163708163.png)]
- The number of replicas set here is only recorded in the metadata of the NameNode. Whether there will be so many replicas depends on the metadata of the DataNode
quantity At present, there are only 3 devices, at most 3 replicas. The number of replicas can reach 10 only when the number of nodes increases to 10.
Current quantity - setrep
[root@linux121 testfile]# hadoop fs -setrep 5 /test/hadoop.txt Replication 5 set: /test/hadoop.txt
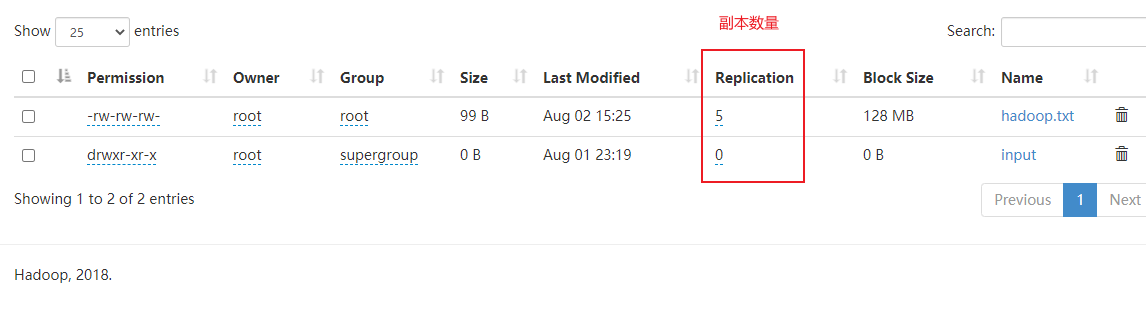
- The number of replicas set here is only recorded in the metadata of the NameNode. Whether there will be so many replicas depends on the metadata of the DataNode
quantity At present, there are only 3 devices, at most 3 replicas. The number of replicas can reach 10 only when the number of nodes increases to 10.