1. Debug environment preparation
1.1 Debug code: MR classic introduction case WordCount
1.1.1 Mapper class
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\\s+");
for (String word : words) {
context.write(new Text(word),new LongWritable(1));
}
}
}
1.1.2 Reducer class
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count +=value.get();
}
context.write(key,new LongWritable(count));
}
}
1.1.3 main classes of program operation
public class WordCountDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// Create job instance
Job job = Job.getInstance(getConf(), WordCountDriver.class.getSimpleName());
// Set job driven class
job.setJarByClass(this.getClass());
// Set job mapper reducer class
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// Set the output key value data type of job mapper stage
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//Set the output key value data type of the job reducer stage, that is, the final output data type of the program
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// Configure the input data path of the job
FileInputFormat.addInputPath(job, new Path(args[0]));
// Configure the output data path of the job
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Determine whether the output path exists. If so, delete it
FileSystem fs = FileSystem.get(getConf());
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// Submit the job and wait for execution to complete
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
//Profile object
Configuration conf = new Configuration();
//Using the tool classtoolrunner submitter
int status = ToolRunner.run(conf, new WordCountDriver(), args);
//Exit the client program. The client exit status code is bound to the execution result of MapReduce program
System.exit(status);
}
}
2. MapReduce Job submission source tracking
refer to: Use of IntelliJ IDEA Debug tool
2.1 MapReduce program entry method
as a MapReduce program written in java language, its entry method is the main method. In the main method, ToolRunner is used to start and run the MapReduce client main class, and its logical implementation is defined in the run method.
@Override
public int run(String[] args) throws Exception {
// Create job instance
Job job = Job.getInstance(getConf(), WordCountDriver.class.getSimpleName());
// Set job driven class
job.setJarByClass(this.getClass());
// Set job mapper reducer class
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// Set the output key value data type of job mapper stage
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//Set the output key value data type of the job reducer stage, that is, the final output data type of the program
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// Configure the input data path of the job
FileInputFormat.addInputPath(job, new Path(args[0]));
// Configure the output data path of the job
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Determine whether the output path exists. If so, delete it
FileSystem fs = FileSystem.get(getConf());
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// Submit the job and wait for execution to complete
return job.waitForCompletion(true) ? 0 : 1;
}
2.2 job.waitForCompletion
the job is executed at the end of the client Waitforcompletement() method. From the name, we can see that the function of this method is to wait for the execution of MR program. Enter the method:
after judging that the state can submit a job, execute the submit() method. The monitorAndPrintJob() method will continuously refresh, obtain the progress information of job operation, and print. If the boolean parameter verbose is true, it indicates that the running progress needs to be printed. If it is false, it just waits for the end of job running and does not print the running log.
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException,ClassNotFoundException {
//When the job status is define
if (state == JobState.DEFINE) {
submit();//aw: submit job
}
if (verbose) {//The verbose value is a boolean type specified by the user
//aw: monitor the job and print status in real time with the progress and task
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
// Pull the completion status information from the client according to the polling interval (5000 ms by default)
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();//Check whether the job completed successfully. Return true to indicate success.
}

2.3 job.submit
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
//Check again to ensure that the job status is define
ensureState(JobState.DEFINE);
//Set up to use the new api
setUseNewAPI();
//Establish connection with program running environment
connect();
//Get job submitters are divided into local submitters and yarn submitters according to the running environment
final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);//todo submit job
}
});
//The client submitted the job successfully, and the status is updated to running
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
2.3.1 connect
when the MapReduce Job is submitted, the connection cluster is implemented through the connect() method of the Job, which actually constructs the cluster instance cluster. Cluster is a tool for connecting MapReduce clusters. It provides a method to obtain MapReduce cluster information.
within the Cluster, there is a client communication protocol instance client that communicates with the Cluster. It is constructed by the static create() method of the ClientProtocolProvider, while Hadoop 2 X provides two modes of ClientProtocol, namely YARNRunner in Yarn mode and LocalJobRunner in Local mode. In fact, they are responsible for communicating with the Cluster. In Yarn mode, the ClientProtocol instance YARNRunner object has a ResourceManager agent ResourceMgrDelegate instance resMgrDelegate, In the Yarn mode, the whole MapReduce client is responsible for communicating with the Yarn Cluster, completing processes such as job submission and job status query, and obtaining the information of the Cluster through it.
private synchronized void connect() throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) {//If the cluster is empty, the cluster instance is constructed
cluster = ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run() throws IOException, InterruptedException, ClassNotFoundException {
return new Cluster(getConfiguration());
}
});
}
}
2.3.1.1 Cluster
the two most important member variables in the Cluster class are the client communication protocol provider ClientProtocolProvider and the client communication protocol ClientProtocol. The instance is called client, and the latter is generated based on the create() method of the former.
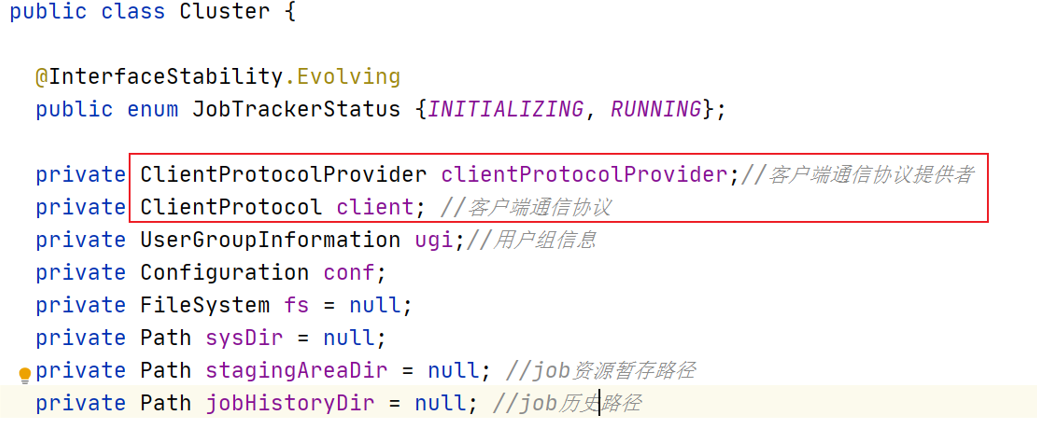
in ClientProtocol, many methods are defined. Clients can use these methods to submit, kill, or obtain some program status information.
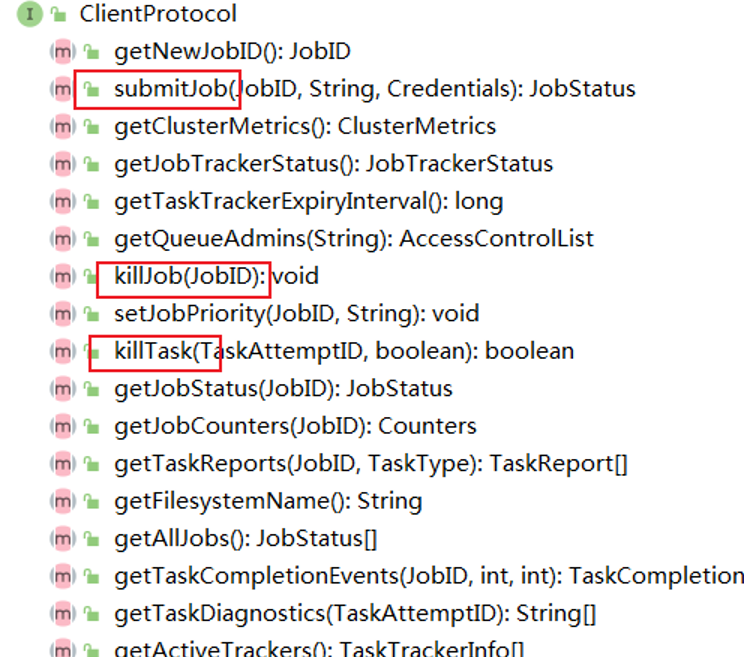
in the construction method of Cluster, the initialization action is completed.

2.3.1.2 initialize
In the Cluster class construction method, we call the initialize initialization method. Take out each ClientProtocolProvider in turn, and construct the ClientProtocol instance through its create() method. If the configuration file does not configure YARN information, build LocalRunner and the MR task runs locally. If the configuration file has configured YARN information, build YarnRunner and the MR task runs on the YARN cluster.

2.3.2 ClientProtocolProvider
two ClientProtocolProvider implementation classes are mentioned in the create() method above.
in MapReduce, there are two implementations of ClientProtocolProvider abstract class: YarnClientProtocolProvider and LocalClientProtocolProvider. The former is Yarn mode and the latter is Local mode.
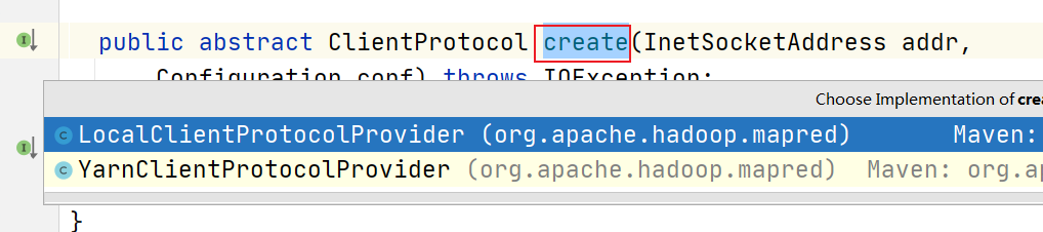
the instance of client communication protocol in Cluster is either YARNRunner in Yarn mode or LocalJobRunner in Local mode.
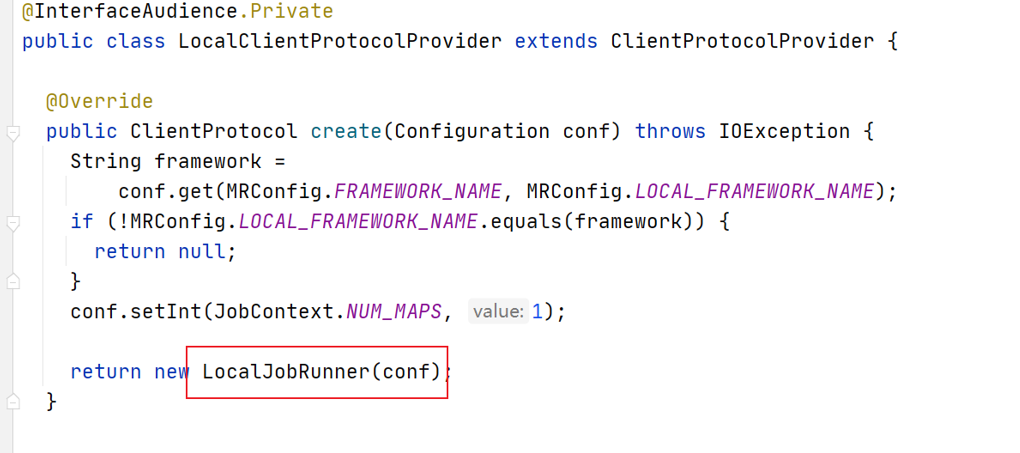
2.3.2.1 LocalClientProtocolProvider
2.3.2.2 YarnClientProtocolProvider
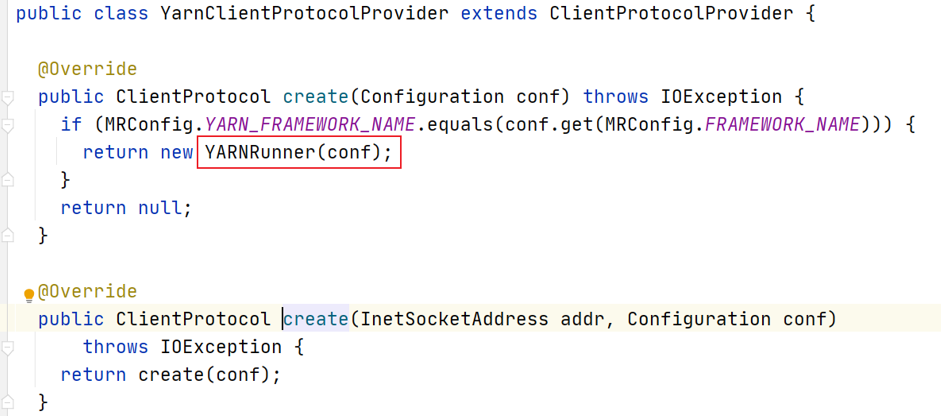
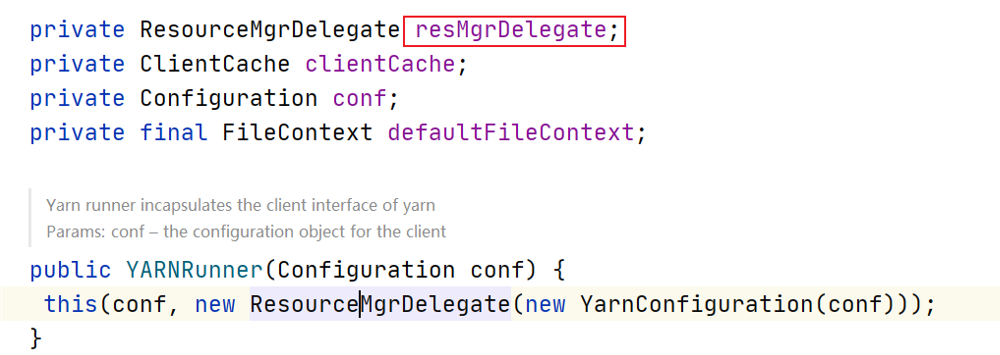
one of the most important variables in YARNRunner is the resMgrDelegate instance of ResourceManager's proxy ResourceMgrDelegate type.
in the Yarn mode, the whole MapReduce client is responsible for communicating with the Yarn cluster, completing processes such as job submission and job status query, and obtaining the information of the cluster through it. There is an instance YarnClient in it, which is responsible for communicating with Yarn, as well as ApplicationId Member variables related to a specific application, such as ApplicationSubmissionContext.
2.3.3 submitJobInternal
At the end of the submit method, we called the subcontractor submitter.. The submitjobinternal method submits tasks. It is the internal method of submitting a Job and implements all the business logic of submitting a Job.
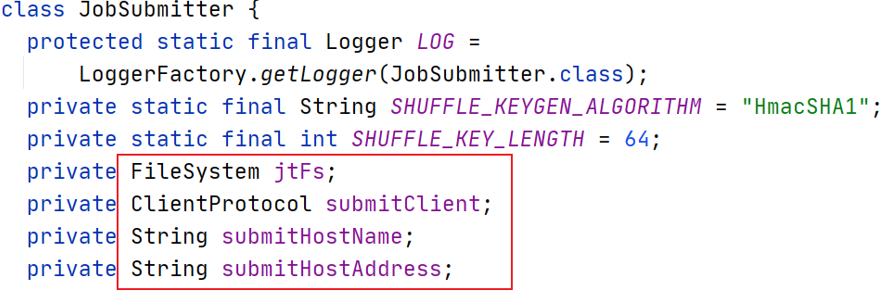
There are four class member variables in the JobSubmitter class:
- File system instance jtFs: used to operate various files required for job operation;
- Client communication protocol instance submitClient: used to interact with the cluster and complete job submission, job status query, etc.
- Host name of submitting job submitHostName;
- The host address of the submitted job is submitHostAddress.
the following is the core code of submitting the task:
JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException {
//Validate the job output specs
//aw: for example, check whether the output path is configured and exists. The correct situation is that it has been configured and does not exist
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
//aw: obtain the path of the job preparation area for submitting and storing jobs and related resources, such as jar, slice information, configuration information, etc
//The default is / TMP / Hadoop yarn / staging / submit job user name / staging
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {//Record the host IP and host name of the submitted job
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
//aw: communicate with the running cluster and set the obtained jobID into the job
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
//Create the final job preparation area path, followed by jobStagingArea / jobID
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {//Set some job parameters
conf.set(MRJobConfig.USER_NAME, UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(), new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(), job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" + "data spill is enabled");
}
//aw: copy the resource files related to the job to the submitJobDir job preparation area, for example: - libjars, - files, - archives
copyAndConfigureFiles(job, submitJobDir);
//Create the file job XML is used to save the configuration information of the job
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job todo
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
//aw: generate the input slice information of this job and write the slice information into the job preparation area submitJobDir
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP, MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps + " exceeded limit " + maxMaps);
}
// write "queue admins of the queue to which job is being submitted"
// to job file. Queue information
String queue = conf.get(MRJobConfig.QUEUE_NAME, JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue, QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t : job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS, trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write the job configuration information into the job in the job preparation area XML file
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
//aw: here, the real role submission is finally carried out
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}