Hadoop environment configuration (Linux virtual machine)
This semester, I chose the course of big data management and analysis, which mainly uses Hadoop framework for data analysis and application development. First, I will configure the environment
be careful
-
It's better to put JDK and Hadoop under / usr/local
-
When adding environment variables, you can add them to / etc/profile
Or follow the link w3cshcool Configuration of teaching materials (strongly recommended)
Environmental requirements

Installation of stand-alone Hadoop
Install JDK
link
https://www.oracle.com/java/technologies/javase-java-archive-javase6-downloads.html
then
sudo nautilus
A folder with permissions will be opened
Recommended download Bin file instead of RPM bin
Then install
./jdk-6u23-linux-x64.bin
Configure JDK
Open the / etc/profile file with vim or vi
vim /etc/profile
Click the keyboard i to edit;
Paste the following contents to the end;
export JAVA_HOME=/home/java/jdk1.6.0_23 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
Then esc
Then enter
:w :q
Save exit and enter
source /etc/profile
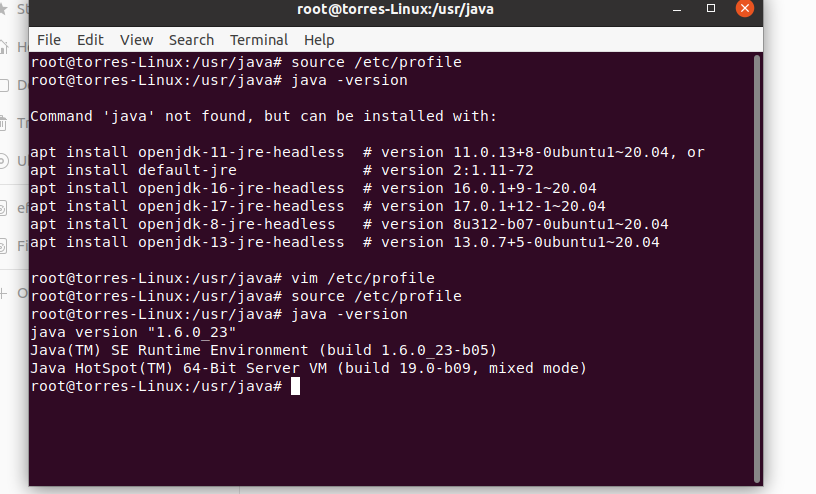
Final verification
java -version
Download and install Hadoop
website:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
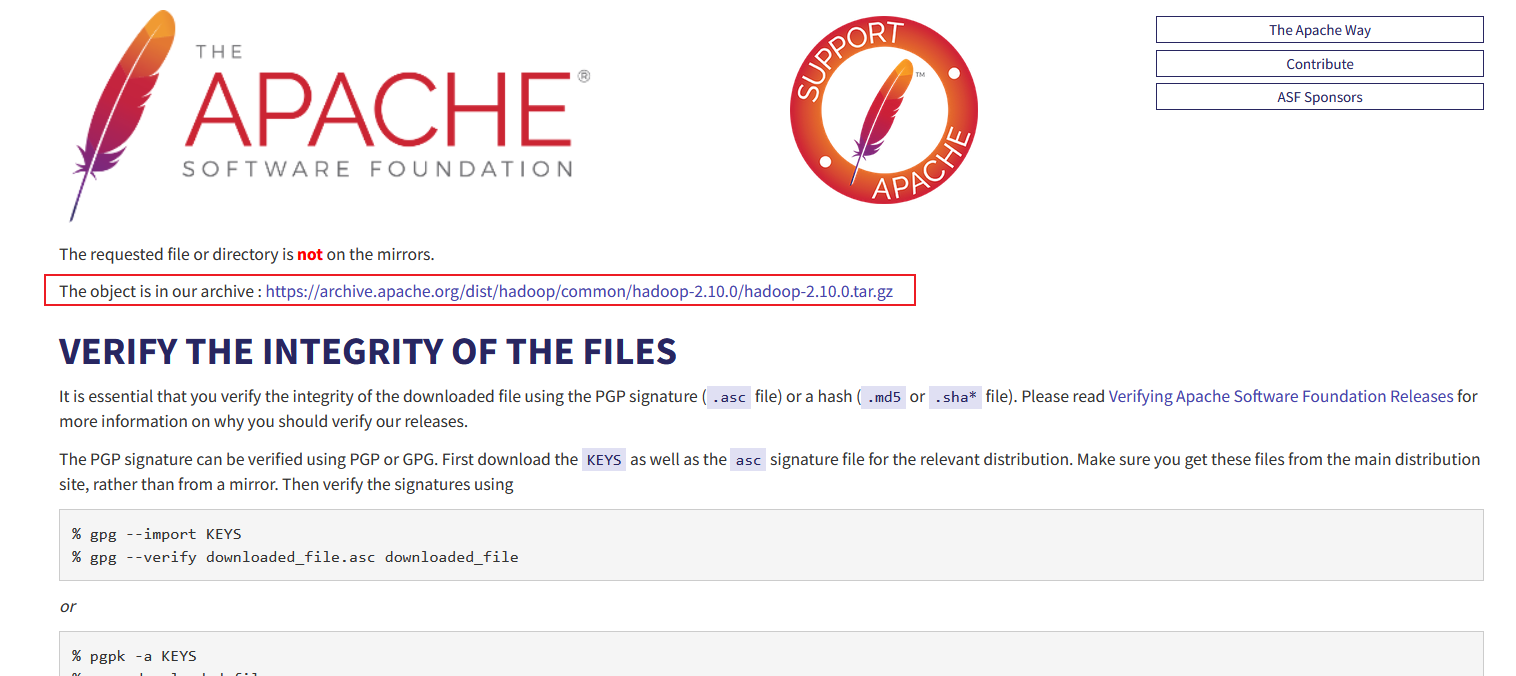
Download and unzip

Then test for availability
./bin/hadoop version # View hadoop version information
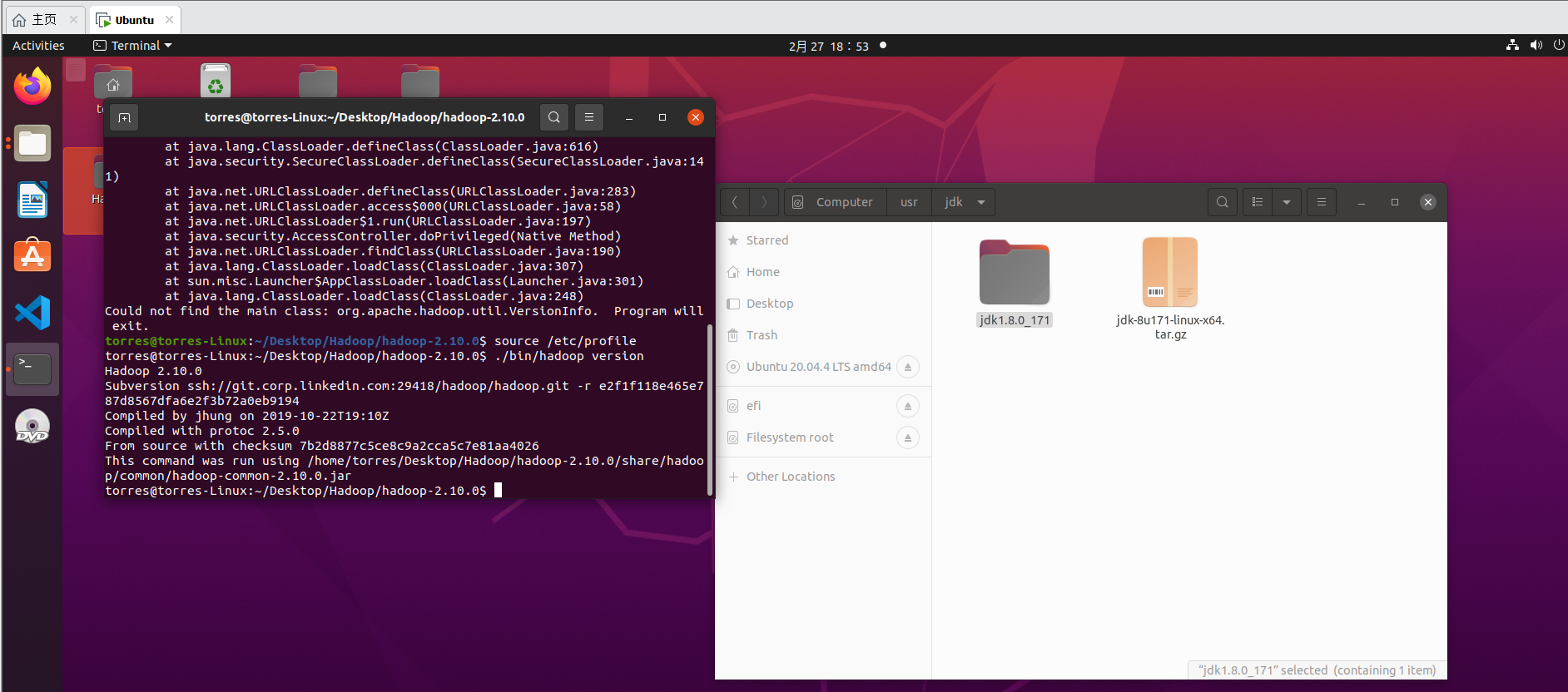
After two hours of DeBug, it's finally ready
-
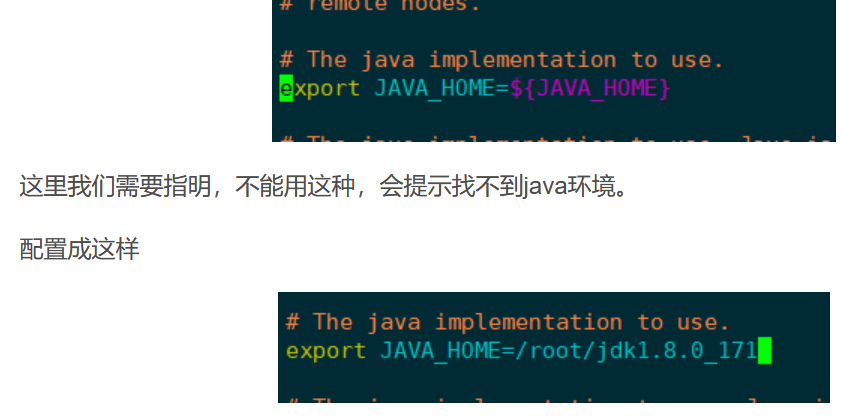
Changed the JDK version to jdk1 8.0_ one hundred and seventy-one
-
Then remember to source /etc/profile after changing / etc/profile
source is required for both roles, and then it's OK~
-
Don't forget to revise this sh file
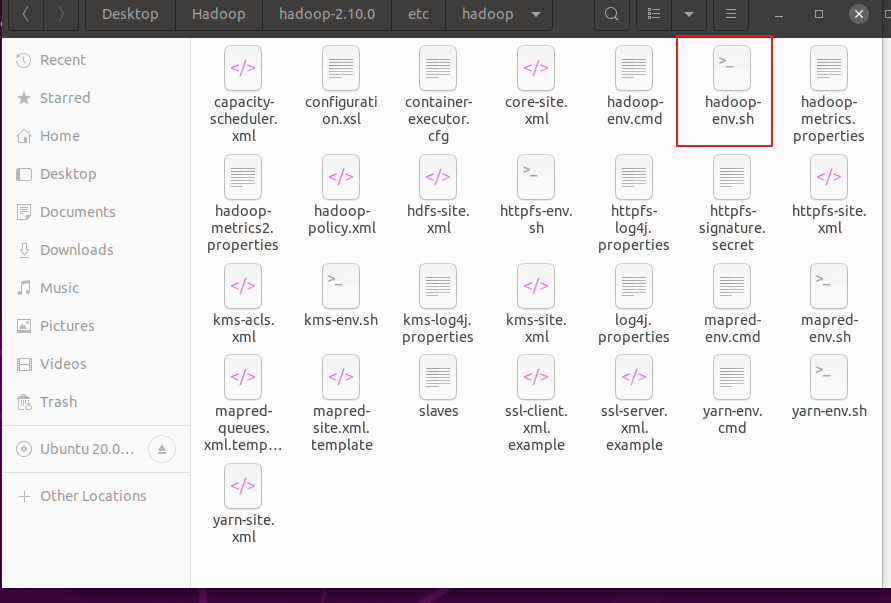
Then you can display the version number of Hadoop normally
Configure SSH
In order to ensure the security of remote management of Hadoop nodes and user shared access between Hadoop nodes, SSH (Secure Shell Protocol) needs to be configured.
In stand-alone mode, no daemon is required, so SSH setting is not required. However, SSH settings are required under single machine pseudo distribution or cluster distribution
So jump first for the time being
Configure Hadoop environment
-
Is to change java_home that's already said above
-
The configuration file of Hadoop is conf / core site xml cof/hdfs-site. XML and conf / mapred site xml
Including core site XML is the global configuration file, followed by the configuration file of HDFS and the configuration file of MapReduce.
-
The core site needs to be modified XML and HDFS site xml
The core site code is as follows
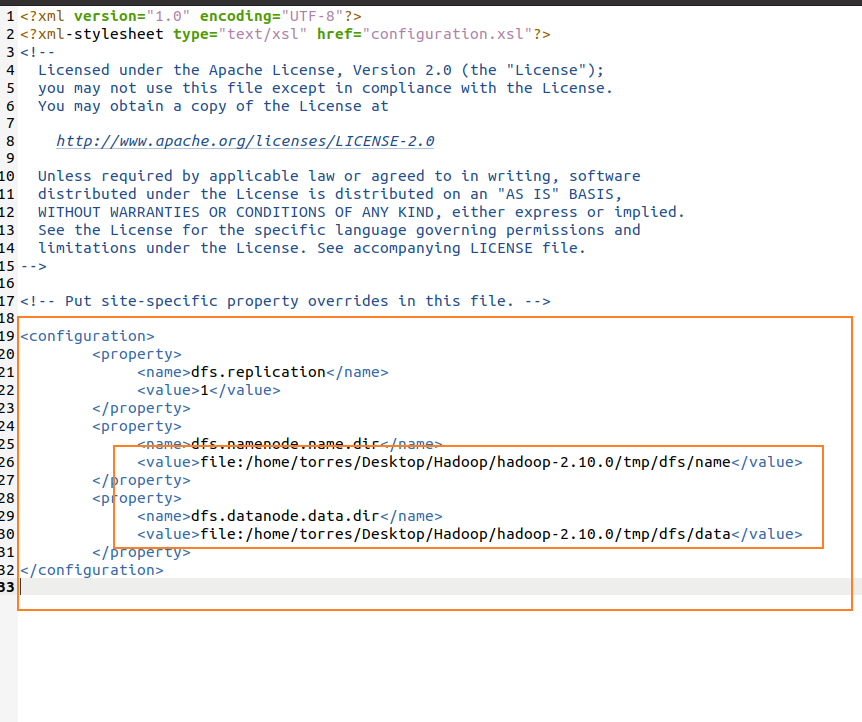
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/root/hadoop-2.10.0/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>HD FS site is as follows
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/root/hadoop-2.10.0/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/root/hadoop-2.10.0/tmp/dfs/data</value> </property> </configuration>The effect is as follows: modify the file by yourself, that is, the file address of hadoop-2.10.0. Others do not need to be changed
Hadoop operation
-
Initialize node
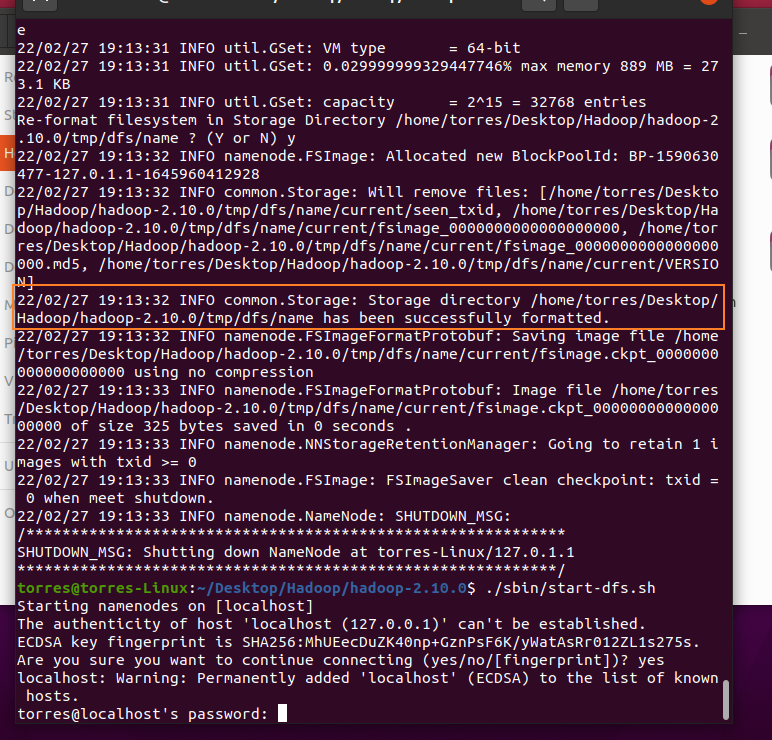
./bin/hdfs namenode -format
-
If it appears, it means success. Otherwise, the possible reasons are shown in address
-
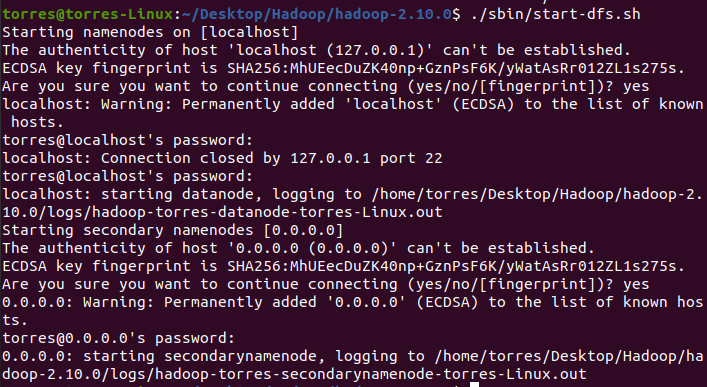
Continue typing/ sbin/start-dfs.sh
-
I found that I asked you to enter the password (it doesn't seem to work, but I don't know why)
-
Therefore, SSH configuration is required
sudo apt-get update #First step sudo apt-get install ssh #Step two sudo apt-get install pdsh #third
-
Generate key pair
ssh-keygen -t rsa # Then enter all the way # It will be saved in by default ssh/id_ In RSA file
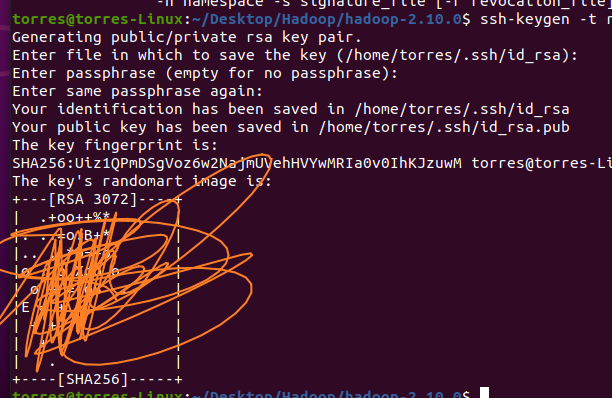
-
# Enter first ssh directory, and then cp id_rsa.pub authorized_keys # Go on ssh localhost
result
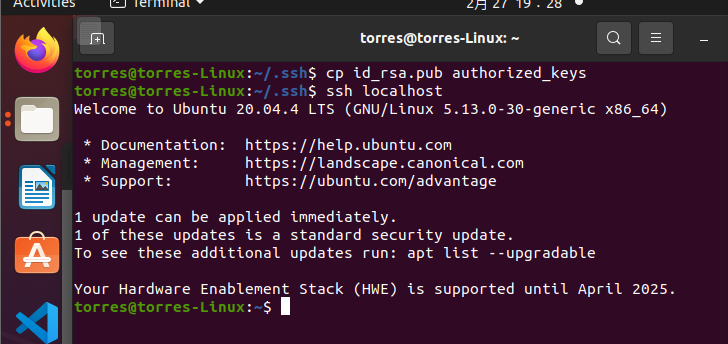
last
part
start-dfs.sh start-yarn.sh
You can complete authentication and login
then
# The default port number for accessing Hadoop is 50070 Use the following URL to get Hadoop services on the browser. http://localhost:50070/ # The default port number for all applications accessing the cluster is 8088 Use the following URL to access this service. http://localhost:8088/
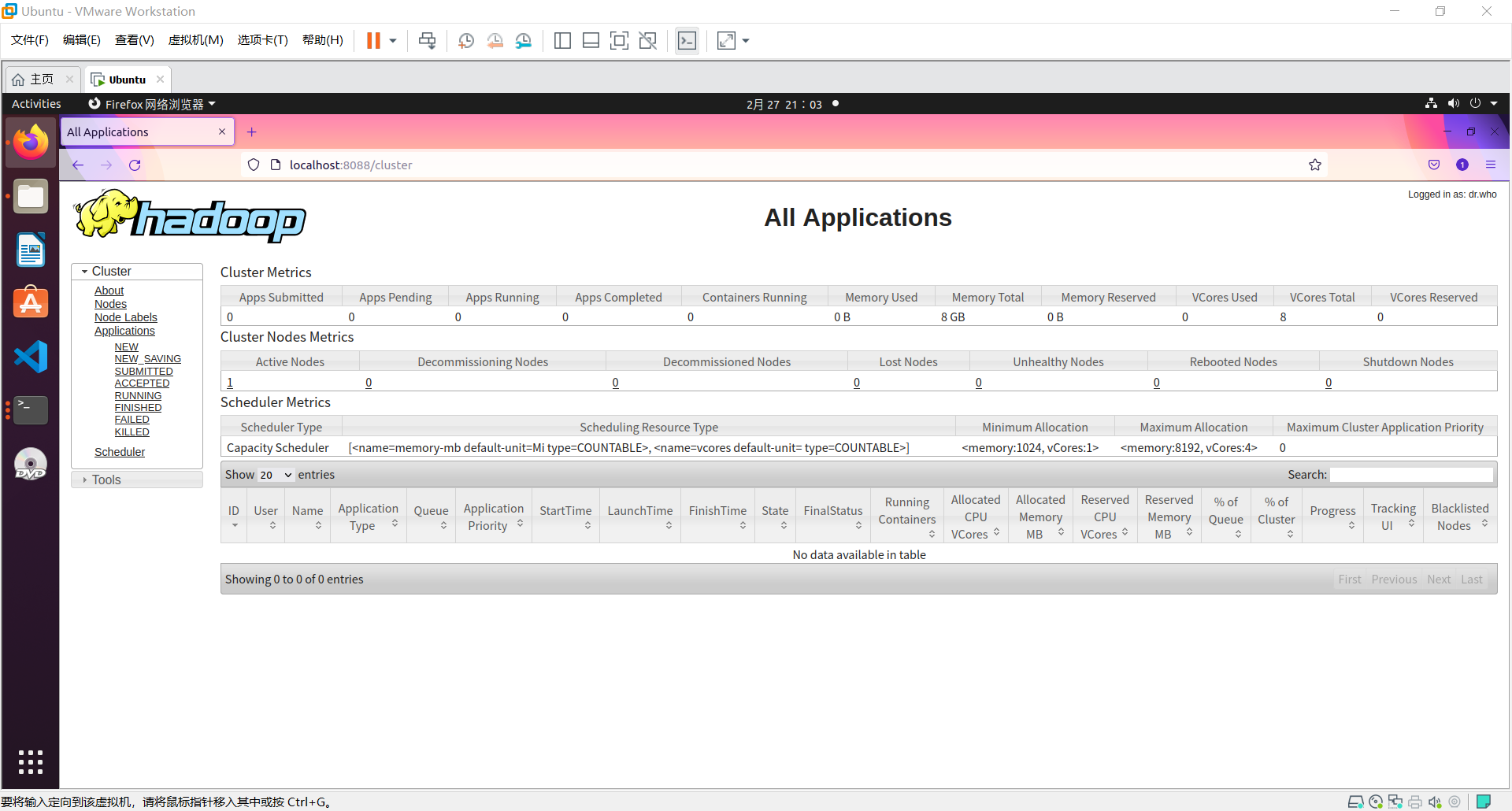
Some problems
-
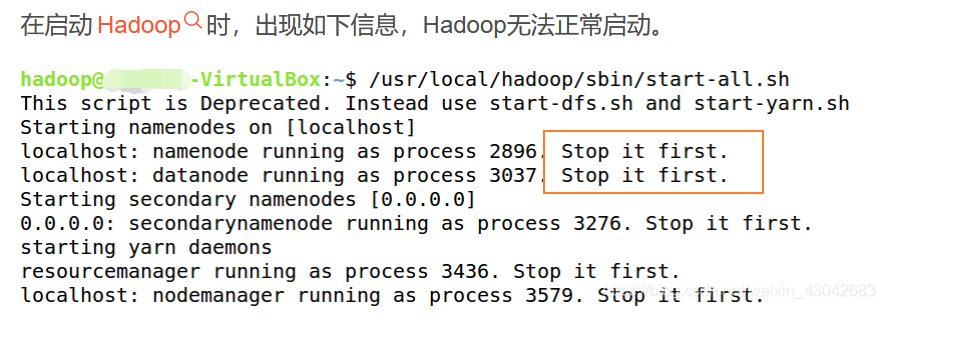
This means that Hadoop nodes are already running when starting Hadoop, so you need to stop all Hadoop services before restarting Hadoop. Then resume normal startup.
Hadoop nodes are already running when starting Hadoop, so you need to stop all Hadoop services before restarting Hadoop. Then resume normal startup.
solve
stop-all.sh
Then restart
Note the input here
./sbin/start-all.sh
-
https://www.w3cschool.cn/hadoop/hadoop_enviornment_setup.html
Finally, this link is the hadoop tutorial of w3school. It feels good and can be configured completely according to this.