Chapter I overview of HA
(1) The so-called HA (high availability), that is, high availability (7 * 24-hour uninterrupted service).
(2) The key strategy to achieve high availability is to eliminate single point of failure. Strictly speaking, ha should be divided into HA mechanisms of various components: ha of HDFS and ha of YARN.
(3) NameNode mainly affects HDFS clusters in the following two aspects
- If the NameNode machine goes down unexpectedly, the cluster will not be available until the administrator restarts
- The NameNode machine needs to be upgraded, including software and hardware upgrades. At this time, the cluster will not be available
The HDFS HA function solves the above problems by configuring multiple NameNodes(Active/Standby) to realize hot standby of namenodes in the cluster. If there is a failure, such as the machine crashes or the machine needs to be upgraded and maintained, the NameNode can be quickly switched to another machine in this way.
Chapter II HDFS-HA cluster construction
Current HDFS cluster planning
| hadoop102 | hadoop103 | hadoop104 |
| NameNode | Secondarynamenode | |
| DataNode | DataNode | DataNode |
The main purpose of HA is to eliminate the single point of failure of namenode. The hdfs cluster needs to be planned as follows
| hadoop102 | hadoop103 | hadoop104 |
| NameNode | NameNode | NameNode |
| DataNode | DataNode | DataNode |
2.1 core issues of hdfs-ha
1) How to ensure the data consistency of the three namenode s
- a.Fsimage: let one nn generate data and let other machines nn synchronize
- b.Edits: it is necessary to introduce a new module JournalNode to ensure the data consistency of edtis files
https://www.cnblogs.com/wkfvawl/p/15475122.html#scroller-28
2) How to make only one nn active and all the others standby at the same time
- a. Manual assignment
- b. Automatic allocation
3) 2nn does not exist in ha architecture. Who will do the work of regularly merging fsimage and edtis
By standby's nn
4) If there is a problem with nn, how can other nn work
- a. manual failover
- b. automatic failover
Chapter III HDFS-HA manual mode
3.1 environmental preparation
(1) Modify IP
(2) Modify the host name and the mapping of host name and IP address
(3) Turn off firewall
(4) ssh password free login
(5) Install JDK, configure environment variables, etc
3.2 planning cluster
| hadoop102 | hadoop103 | hadoop104 |
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
3.3 configure HDFS-HA cluster
1) Official address: http://hadoop.apache.org/
2) Create a ha folder in the opt directory
[atguigu@hadoop102 ~]$ cd /opt [atguigu@hadoop102 opt]$ sudo mkdir ha [atguigu@hadoop102 opt]$ sudo chown atguigu:atguigu /opt/ha
3) Copy hadoop-3.1.3 under / opt/module / to / opt/ha directory (remember to delete the data and log directories)
[atguigu@hadoop102 opt]$ cp -r /opt/module/hadoop-3.1.3 /opt/ha/
4) Configure core site xml
<configuration> <!-- Put multiple NameNode The addresses are assembled into a cluster mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- appoint hadoop The storage directory where files are generated at run time --> <property> <name>hadoop.tmp.dir</name> <value>/opt/ha/hadoop-3.1.3/data</value> </property> </configuration>
5) Configure HDFS site xml
<configuration> <!-- NameNode Data storage directory --> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/name</value> </property> <!-- DataNode Data storage directory --> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/data</value> </property> <!-- JournalNode Data storage directory --> <property> <name>dfs.journalnode.edits.dir</name> <value>${hadoop.tmp.dir}/jn</value> </property> <!-- Fully distributed cluster name --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- In cluster NameNode What are the nodes --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2,nn3</value> </property> <!-- NameNode of RPC mailing address --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop102:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop103:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn3</name> <value>hadoop104:8020</value> </property> <!-- NameNode of http mailing address --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop102:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop103:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>hadoop104:9870</value> </property> <!-- appoint NameNode Metadata in JournalNode Storage location on --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/myclus ter</value> </property> <!-- Access proxy class: client Used to determine which NameNode by Active --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyP rovider</value> </property> <!-- Configure the isolation mechanism, that is, only one server can respond at the same time --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- Required when using isolation mechanism ssh Secret key login--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/atguigu/.ssh/id_rsa</value> </property> </configuration>
6) Distribute the configured hadoop environment to other nodes
3.4 start HDFS-HA cluster
1) Add Hadoop_ Change the home environment variable to the HA directory (three machines)
[atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
Add Hadoop_ The home section should read as follows
#HADOOP_HOME export HADOOP_HOME=/opt/ha/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
Go to the source environment variable on the three machines
[atguigu@hadoop102 ~]$source /etc/profile
2) On each journalnode node, enter the following command to start the journalnode service
[atguigu@hadoop102 ~]$ hdfs --daemon start journalnode [atguigu@hadoop103 ~]$ hdfs --daemon start journalnode [atguigu@hadoop104 ~]$ hdfs --daemon start journalnode
3) On [nn1], format it and start
[atguigu@hadoop102 ~]$ hdfs namenode -format
[atguigu@hadoop102 ~]$ hdfs --daemon start namenode
4) Synchronize metadata information of nn1 on [nn2] and [nn3]
[atguigu@hadoop103 ~]$ hdfs namenode -bootstrapStandby
[atguigu@hadoop104 ~]$ hdfs namenode -bootstrapStandby
5) Start [nn2] and [nn3]
[atguigu@hadoop103 ~]$ hdfs --daemon start namenode
[atguigu@hadoop104 ~]$ hdfs --daemon start namenode
6) View web page display
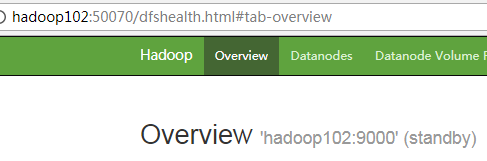
Figure Hadoop 102 (standby)
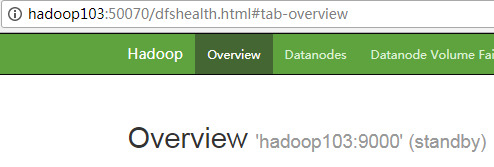
Figure Hadoop 103 (standby)
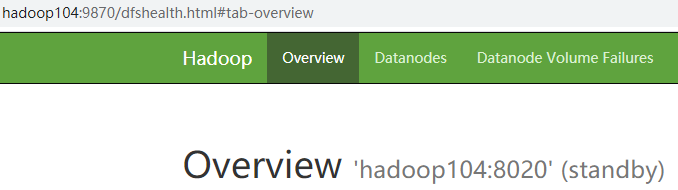
Figure Hadoop 104 (standby)
7) On all nodes, start datanode
[atguigu@hadoop102 ~]$ hdfs --daemon start datanode [atguigu@hadoop103 ~]$ hdfs --daemon start datanode [atguigu@hadoop104 ~]$ hdfs --daemon start datanode
8) Switch [nn1] to Active
[atguigu@hadoop102 ~]$ hdfs haadmin -transitionToActive nn1
9) Check if Active
[atguigu@hadoop102 ~]$ hdfs haadmin -getServiceState nn1
Chapter IV HDFS-HA automatic mode
4.1 HDFS-HA automatic failover mechanism
Automatic failover adds two new components to HDFS deployment: ZooKeeper and zkfailover controller (ZKFC) process, as shown in the figure. ZooKeeper is a highly available service that maintains a small amount of coordination data, notifies clients of changes in these data, and monitors client failures.
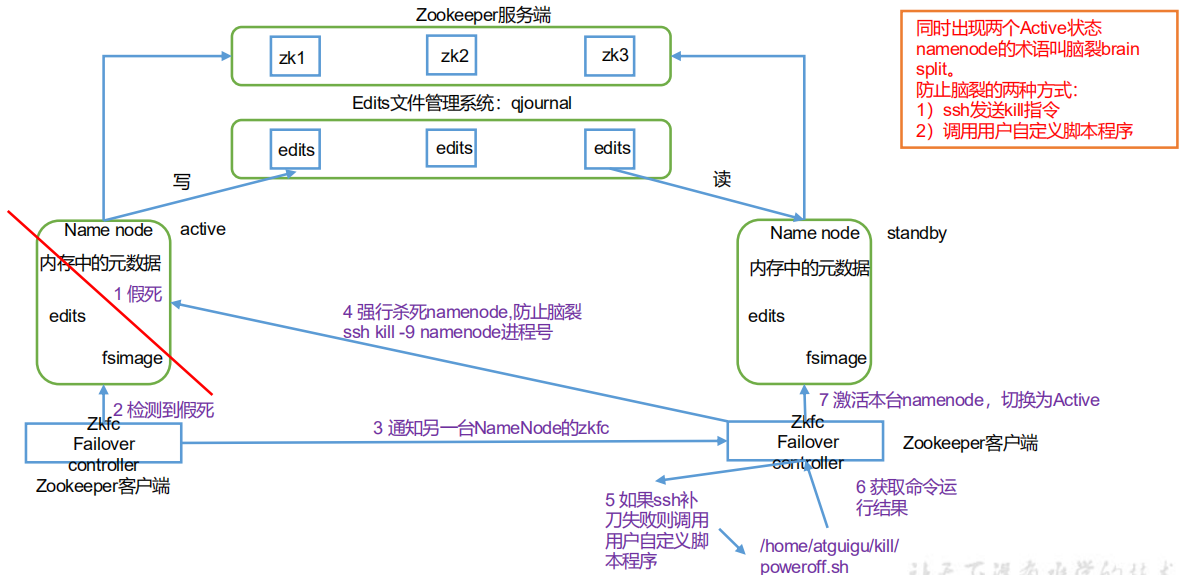
4.2 cluster planning for automatic failover of hdfs-ha
| hadoop102 | hadoop103 | hadoop104 |
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ZKFC | ZKFC | ZKFC |
4.3 configure HDFS-HA automatic failover
1) Specific configuration
(1) At HDFS site Add in XML
<!-- Enable nn Automatic failover --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
(2) At core site Add in XML file
<!-- appoint zkfc To connect zkServer address --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value> </property>
2181: the port that zookeeper provides services to the Client.
(3) Modified distribution profile
[atguigu@hadoop102 etc]$ pwd
/opt/ha/hadoop-3.1.3/etc
[atguigu@hadoop102 etc]$ xsync hadoop/
2) Start
(1) Turn off all HDFS services:
[atguigu@hadoop102 ~]$ stop-dfs.sh
(2) Start the Zookeeper cluster:
[atguigu@hadoop102 ~]$ zkServer.sh start [atguigu@hadoop103 ~]$ zkServer.sh start [atguigu@hadoop104 ~]$ zkServer.sh start
(3) After starting Zookeeper, initialize the HA status in Zookeeper:
[atguigu@hadoop102 ~]$ hdfs zkfc -formatZK
(4) Start HDFS service:
[atguigu@hadoop102 ~]$ start-dfs.sh
(5) You can go to zkcli SH client views the contents of the Namenode election lock node:
[zk: localhost:2181(CONNECTED) 7] get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock myclusternn2 hadoop103 �>(�> cZxid = 0x10000000b ctime = Tue Jul 14 17:00:13 CST 2020 mZxid = 0x10000000b mtime = Tue Jul 14 17:00:13 CST 2020 pZxid = 0x10000000b cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x40000da2eb70000 dataLength = 33 numChildren = 0
3) Verify
(1) kill the Active NameNode process and view the status changes of the three namenodes on the web page
[atguigu@hadoop102 ~]$ kill -9 namenode Process of id
4.3 solve the problem that NN cannot be connected to JN
After automatic failover is configured, use start DFS When the SH group startup script starts the hdfs cluster, it may encounter the problem that the process will shut down automatically after the NameNode gets up for a while. Check the NameNode log and report an error
The information is as follows:
2020-08-17 10:11:40,658 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop104/192.168.6.104:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2020-08-17 10:11:40,659 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop102/192.168.6.102:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2020-08-17 10:11:40,659 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: hadoop103/192.168.6.103:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) 2020-08-17 10:11:49,678 WARN org.apache.hadoop.hdfs.server.namenode.FSEditLog: Unable to determine input streams from QJM to [192.168.6.102:8485, 192.168.6.103:8485, 192.168.6.104:8485]. Skipping.org.apache.hadoop.hdfs.qjournal.client.QuorumException: Got too many exceptions to achieve quorum size 2/3. 3 exceptions thrown:192.168.6.103:8485: Call From hadoop102/192.168.6.102 to hadoop103:8485 failed on connection exception: java.net.ConnectException: connection denied; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
Looking at the error log, we can analyze that the reason for the error is that the NameNode cannot connect to the JournalNode, but the jps command shows that the three JNS have been started normally. Why can't the NN connect to the jn normally? This is because start DFS The default startup sequence of the SH group startup script is to start the NN first, then the DN, and then the JN. The default rpc connection parameter is that the number of retries is 10, and the interval between retries is 1s. That is, if the jn fails to start within 10s after starting the NN, the NN will report an error.
core-default.xml has two parameters as follows:
<!-- NN connect JN The number of retries is 10 by default --> <property> <name>ipc.client.connect.max.retries</name> <value>10</value> </property> <!-- Retry interval, default 1 s --> <property> <name>ipc.client.connect.retry.interval</name> <value>1000</value> </property>
Solution: after encountering the above problems, you can wait a moment. After the JN is successfully started, manually start the next three NN:
[atguigu@hadoop102 ~]$ hdfs --daemon start namenode [atguigu@hadoop103 ~]$ hdfs --daemon start namenode [atguigu@hadoop104 ~]$ hdfs --daemon start namenode
It can also be found in the core site Appropriately increase the above two parameters in XML:
<!-- NN connect JN The number of retries is 10 by default --> <property> <name>ipc.client.connect.max.retries</name> <value>20</value> </property> <!-- Retry interval, default 1 s --> <property> <name>ipc.client.connect.retry.interval</name> <value>5000</value> </property>
Chapter V configuration of YARN-HA
5.1 working mechanism of yarn-ha
1) Official documents:
http://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.htm
2) Working mechanism of YARN-HA
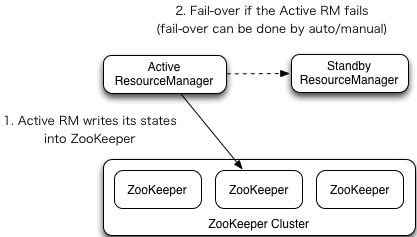
5.2 configure YARN-HA cluster
1) Environmental preparation
(1) Modify IP
(2) Modify the host name and the mapping of host name and IP address
(3) Turn off firewall
(4) ssh password free login
(5) Install JDK, configure environment variables, etc
(6) Configuring Zookeeper clusters
2) Planning cluster
| hadoop102 | hadoop103 | hadoop104 |
| ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager |
| Zookeeper | Zookeeper | Zookeeper |
3) Core issues
a . If the current active rm hangs, how can other RMS host other standby RMS?
The core principle is the same as hdfs, using zk's temporary nodes
b. At present, there are many computing programs waiting to run on rm. How can other rm take over these programs and run?
rm will store the status of all current computing programs in zk, and other RMS will read it after they are up, and then run
4) Specific configuration
(1)yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- Enable resourcemanager ha --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- Declare two resourcemanager Address of --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <!--appoint resourcemanager Logical list of--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2,rm3</value> </property> <!-- ========== rm1 Configuration of ========== --> <!-- appoint rm1 Host name of --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop102</value> </property> <!-- appoint rm1 of web End address --> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop102:8088</value> </property> <!-- appoint rm1 Internal communication address of --> <property> <name>yarn.resourcemanager.address.rm1</name> <value>hadoop102:8032</value> </property> <!-- appoint AM towards rm1 Address of the requested resource --> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>hadoop102:8030</value> </property> <!-- Designated for NM Connected address --> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>hadoop102:8031</value> </property> <!-- ========== rm2 Configuration of ========== --> <!-- appoint rm2 Host name of --> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop103</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop103:8088</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>hadoop103:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>hadoop103:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>hadoop103:8031</value> </property> <!-- ========== rm3 Configuration of ========== --> <!-- appoint rm1 Host name of --> <property> <name>yarn.resourcemanager.hostname.rm3</name> <value>hadoop104</value> </property> <!-- appoint rm1 of web End address --> <property> <name>yarn.resourcemanager.webapp.address.rm3</name> <value>hadoop104:8088</value> </property> <!-- appoint rm1 Internal communication address of --> <property> <name>yarn.resourcemanager.address.rm3</name> <value>hadoop104:8032</value> </property> <!-- appoint AM towards rm1 Address of the requested resource --> <property> <name>yarn.resourcemanager.scheduler.address.rm3</name> <value>hadoop104:8030</value> </property> <!-- Designated for NM Connected address --> <property> <name>yarn.resourcemanager.resource-tracker.address.rm3</name> <value>hadoop104:8031</value> </property> <!-- appoint zookeeper Address of the cluster --> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value> </property> <!-- Enable automatic recovery --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- appoint resourcemanager The status information of is stored in zookeeper colony --> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateSt ore</value> </property> <!-- Inheritance of environment variables --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
(2) Synchronously update the configuration information of other nodes and distribute configuration files
[atguigu@hadoop102 etc]$ xsync hadoop/
4) Start YARN
(1) Execute in Hadoop 102 or Hadoop 103:
[atguigu@hadoop102 ~]$ start-yarn.sh
(2) View service status
[atguigu@hadoop102 ~]$ yarn rmadmin -getServiceState rm1
(3) You can go to zkcli SH client view the contents of the resource manager election lock node:
[atguigu@hadoop102 ~]$ zkCli.sh [zk: localhost:2181(CONNECTED) 16] get -s /yarn-leader-election/cluster-yarn1/ActiveStandbyElectorLock cluster-yarn1rm1 cZxid = 0x100000022 ctime = Tue Jul 14 17:06:44 CST 2020 mZxid = 0x100000022 mtime = Tue Jul 14 17:06:44 CST 2020 pZxid = 0x100000022 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x30000da33080005 dataLength = 20 numChildren = 0
(4) View the status of YARN of Hadoop 102:8088 and Hadoop 103:8088 on the web side
5.3 final planning of Hadoop ha
After the whole ha is built, the cluster will look like the following
| hadoop102 | hadoop103 | hadoop104 |
| NameNode | NameNode | NameNode |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ZKFC | ZKFC | ZKFC |
| ResourceManager | ResourceManager | ResourceManager |
| NodeManager | NodeManager | NodeManager |