Spqrk implements TopN
- Experimentation Requirements
- Data preparation
- Expected results
- Related Classes and Operators
- findspark
- pyspark:
- SparkContext:
- parallelize(*c*, *numSlices=None*)
- collect()
- textFile(*name*, *minPartitions=None*, *use_unicode=True*)
- map(*f*, *preservesPartitioning=False*)
- cache()
- sortBy(keyfunc, *ascending=True*, *numPartitions=None*)
- take(num)
- Implement different TopN schemes
Experimentation Requirements
To get the top five military ranks of Shu military generals, the top 5 military ranks are queried from original data through distributed computing framework.
Data preparation
1 Liu Bei 68 Shu Kingdom 2Ma Chao 90 Shu Kingdom 3Huang Zhong 91 Shu Kingdom 4Wei Yan76 Shu Kingdom 5Jiang Wei 92 Shu Kingdom 6 Guan Yu 96 Shu Kingdom 7 Yan 78 Shu Kingdom 8Monta 64 Shu Nine Flying 88 Shu Kingdoms 10 horses 76 Shu 11Zhao Yun95 Shu Kingdom 12 Fa Zheng 88 Shu Kingdom
Save the original data given in the title in your local Desktop directory and name it as a text fileForceData.txt.
Expected results
6 Guan Yu 96 Shu Kingdom 11Zhao Yun95 Shu Kingdom 5Jiang Wei 92 Shu Kingdom 3Huang Zhong 91 Shu Kingdom 2Ma Chao 90 Shu Kingdom
Related Classes and Operators
Python-Spark website: http://spark.apache.org/docs/latest/api/python/pyspark.html
findspark
Official Introduction: ProvidesFindspark.init() to make pyspark importable as a regular library.
That is, to import pyspark as a regular library provides a **Findspark.initA tool like ()**.
pyspark:
pyspark is a Python API for Spark.
SparkContext:
SparkContext is the main entry point for spark functionality.It represents a connection to a spark cluster and can be used to create RDD, accumulator, and broadcast variables on the cluster.The main entry point for Spark functionality.
parallelize(c, numSlices=None)
Distribute local Python collections to form RDD s.If the input represents a performance range, xrange is recommended.
>>> sc.parallelize([0, 2, 3, 4, 6], 5).glom().collect() [[0], [2], [3], [4], [6]] >>> sc.parallelize(xrange(0, 6, 2), 5).glom().collect() [[], [0], [], [2], [4]]
collect()
Returns a list containing all elements in this RDD.
Note: This method should only be used when the expected result array is small, as all data is loaded into the driver's memory.
textFile(name, minPartitions=None, use_unicode=True)
Reads text files from HDFS, the local file system (available on all nodes), or any Hadoop-supported file system URI and returns them as RDD s of strings.
If use_If Unicode is False, the string will remain str (encoded as utf-8), which is faster and smaller than unicode.
path = os.path.join(tempdir, "sample-text.txt") >>> with open(path, "w") as testFile: ... _ = testFile.write("Hello world!") >>> textFile = sc.textFile(path) >>> textFile.collect() ['Hello world!']
map(f, preservesPartitioning=False)
Returns a new RDD by applying a function to each element of this RDD.
>>> rdd = sc.parallelize(["b", "a", "c"]) >>> sorted(rdd.map(lambda x: (x, 1)).collect()) [('a', 1), ('b', 1), ('c', 1)]
cache()
Use default storage level (MEMORY_ONLY) Keep the RDD.
sortBy(keyfunc, ascending=True, numPartitions=None)
Sort this RDD by the given keyfunc.
>>> tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)] >>> sc.parallelize(tmp).sortBy(lambda x: x[0]).collect() [('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)] >>> sc.parallelize(tmp).sortBy(lambda x: x[1]).collect() [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
take(num)
Take the first num elements of the RDD.
It works by first scanning a partition, then using the results of that partition to estimate the number of other partitions needed to meet the limit.
Note: This method should only be used when the expected result array is small, as all data is loaded into the driver's memory.
sc.parallelize([2, 3, 4, 5, 6]).cache().take(2) [2, 3] >>> sc.parallelize([2, 3, 4, 5, 6]).take(10) [2, 3, 4, 5, 6] >>> sc.parallelize(range(100), 100).filter(lambda x: x > 90).take(3) [91, 92, 93]
Implement different TopN schemes
Implementation scenario one
Idea analysis:
- Reads data in a custom function format and uses the map operator to return a new RDD.
- Use collect() to return a list containing all elements in this RDD.
- sortBy() Sorts this RDD by the given keyfunc.(This topic is to sort by the force value index and use the False option to specify the order from high to low)
- The take() operator is used to select the first num elements of RDD.(This topic is about operations that require top5)
Implement full code:
import findspark findspark.init("/usr/local/spark") # Indicate SPARK_HOME Directory from pyspark import SparkContext sc.stop() sc=SparkContext(appName='forceLevel') def map_func(x):#Customize functions to read data correctly s = x.split() return (s[0],s[1],s[2],s[3]) lines=sc.textFile("file:/home/hadoop/Desktop/forceData.txt").map(lambda x:map_func(x)).cache()#Import data and keep it in memory, where cache(): Keep data in memory tmp=sc.parallelize(lines.collect()).sortBy(lambda x: x[2],False).collect()#Sort by force value indicator and use False option to specify high to low order sc.parallelize(tmp).cache().take(5)#Using take() operator to get the first five elements of RDD
Experimental results: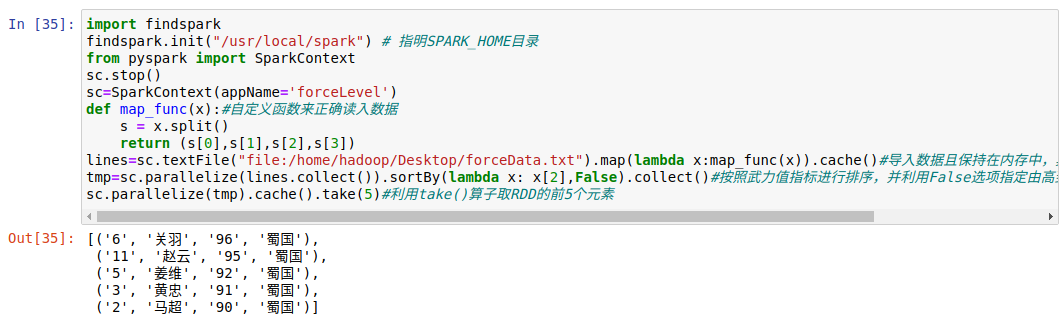
Implementation scenario two
Idea analysis:
- Reads data in a custom function format and uses the map operator to return a new RDD.
- Use collect() to return a list containing all elements in this RDD.
- The top operator is used to select the first num elements of RDD.(because the top operator returns a list in descending order)
import findspark findspark.init("/usr/local/spark") # Indicate SPARK_HOME Directory from pyspark import SparkContext sc.stop() sc=SparkContext(appName='forceLevel') def map_func(x):#Customize functions to read data correctly s = x.split() return (s[0],s[1],s[2],s[3]) lines=sc.textFile("file:/home/hadoop/Desktop/forceData.txt").map(lambda x:map_func(x)).cache()#Import data and keep it in memory, where cache(): Keep data in memory tmp=sc.parallelize(lines.collect(),2).top(5,key=lambda x: x[2])#The top operator is used to select the first num elements of RDD.(because the top operator returns a list in descending order) print(tmp)
Experimental results: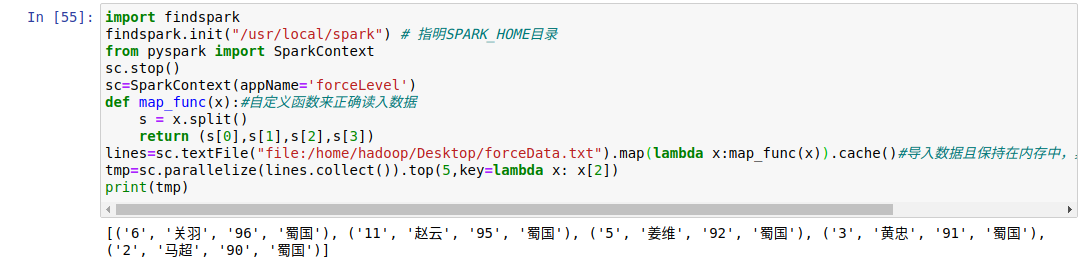
Implementation Plan Three
Idea analysis:
Implement full code:
- Reads data in a custom function format and uses the map operator to return a new RDD.
- Use collect() to return a list containing all elements in this RDD.
- The rdd with force value as key is sorted by sortByKey operator.
- The map operator is used to return a list of requirements for the target format, and the take operator is used to implement TopN with the first five terms.
import findspark findspark.init("/usr/local/spark") # Indicate SPARK_HOME from pyspark import SparkContext sc.stop() def map_func(x):#Customize functions to read data correctly s = x.split() return (s[2], [s[0],s[1],s[3]])#Return to (key,vaklue) format, whereKey:x[0],Value:x[1] and a list of three elements, with the force value as the key followed by the key sort def map_func1(x):#Return to the list of formats you ultimately want return (x[1][0],x[1][1],x[0],x[1][2]) sc=SparkContext(appName='Students') lines=sc.textFile("file:/home/hadoop/Desktop/forceData.txt").map(lambda x:map_func(x)).cache() #Import data and keep it in memory, where cache(): Keep data in memory tmp=sc.parallelize(lines.collect()).sortByKey(keyfunc=lambda x: -int(x)).collect()#The rdd with force value as key is sorted by sortByKey operator. rdd=sc.parallelize(tmp) rdd.map(lambda x:map_func1(x)).take(5)#Returns a list of requirements for the target format, with the first five entries
Experimental results: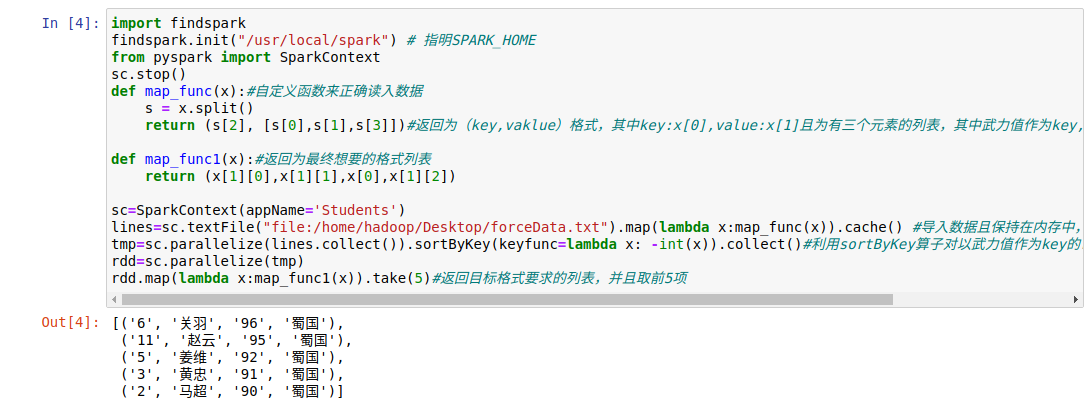
This is the Haop learning notes shared with you this time - the specific idea of using Python and Spqrk to implement TopN and the Spark operator used are described in detail. I hope it is useful for all your little partners. Writing this thing suddenly feels like developing documents is really a good thing, so I will have to train more abilities in this area in the future.If you have any questions, please leave a message. If you think it's useful to you, please agree. Your support is the power for Xiaobian to move forward.