1, Previously on
The last article introduced the Api calling method of MapReduce and the configuration of eclipse. This time, we will use MapReduce to count words in English article files!
Welcome to my previous article: MapReduce related eclipse configuration and Api call
2, Preconditions
| Installation required | Download method |
|---|---|
| IDEA | Own |
| hadoop-eclipse-plugin-2.7.0.jar | Baidu online disk download , extraction code: f259 |
| MobaXterm | Baidu online disk download , extraction code: f64v |
Make sure that the Hadoop cluster is built successfully. If it is not built successfully, welcome to my previous article: Hadoop cluster construction steps (Graphic super detailed version)
HDFS commands to be used this time: Hadoop -- HDF Shell command , I suggest you look at it during operation!!
3, Create Maven project
Open the IDEA tool and click "File" -- "New" -- "Project" in the upper left corner ↓
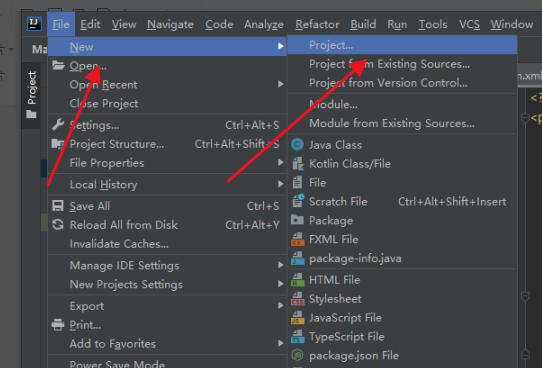
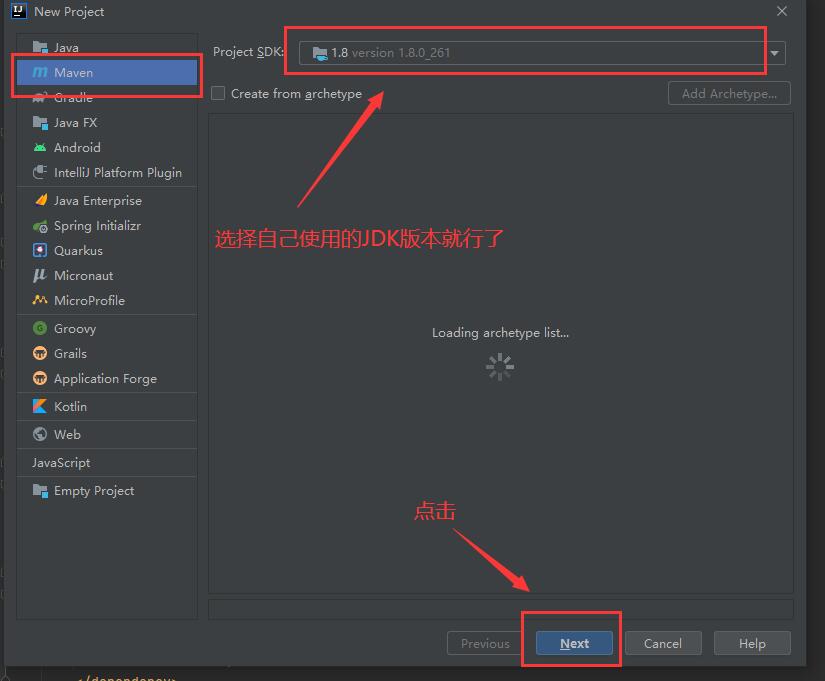
Select Maven project ↓
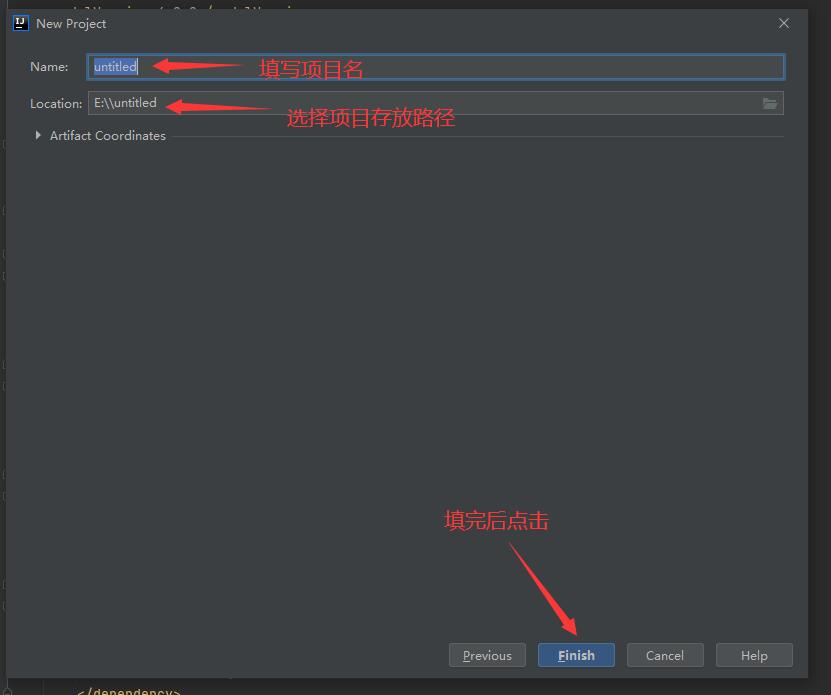
Fill in project information ↓
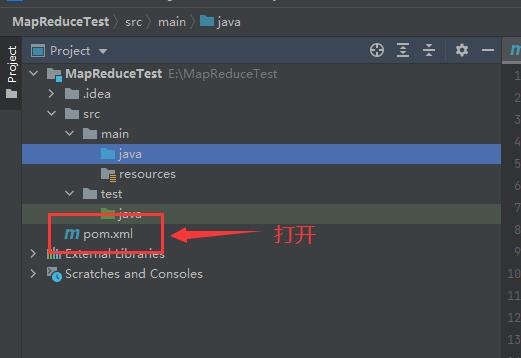
After the project is created successfully, we open pom.xml ↓
Add Hadoop dependency in the configuration file ↓
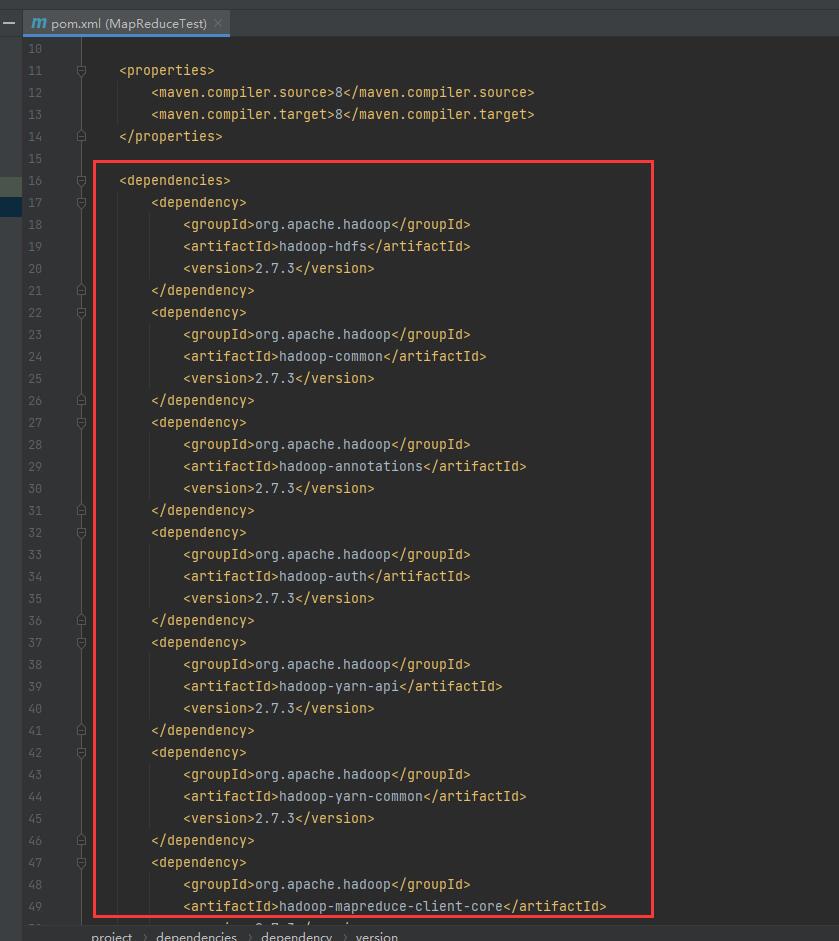
The code is as follows ↓
Note: replace your Hadoop version number in < < version > < / version >, here is 2.7.3!
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-annotations</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
Click this button in the upper right corner to reload the dependency library and configuration file ↓
4, Modify Windows system variables
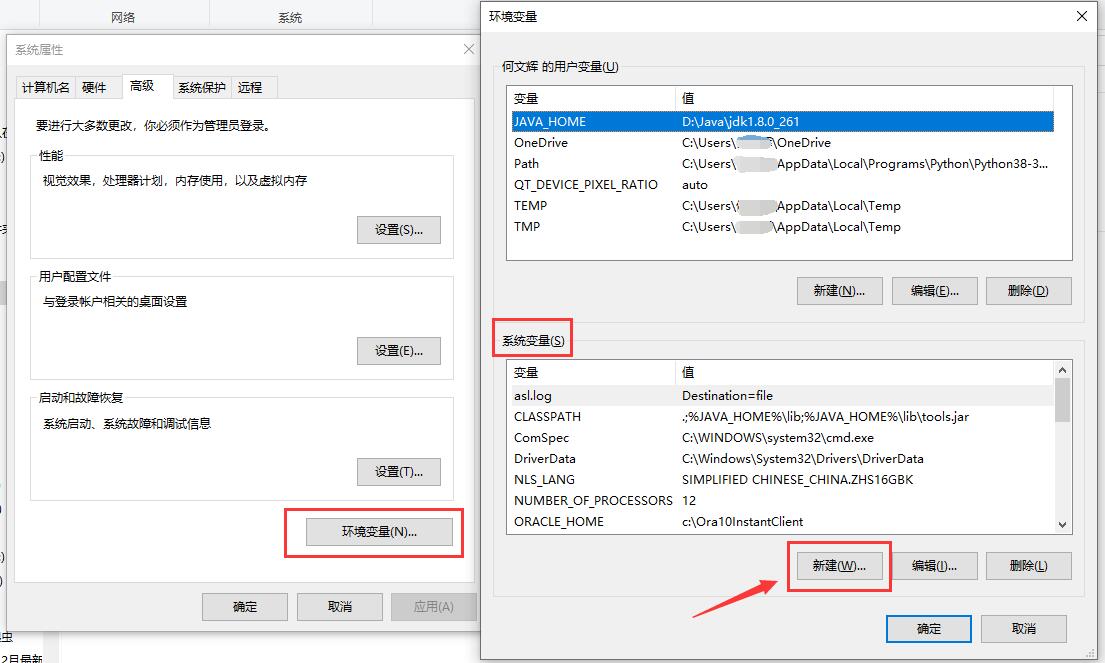
Right click the "this computer" icon on the desktop, click "properties", and create a new system variable in the environment variable ↓
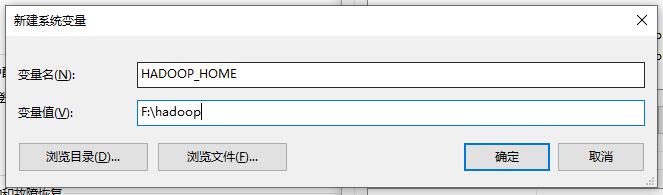
Add hadoop file path to system variable ↓
5, Write the jar package of MapReduce
In the previous article, we compressed and decompressed the entire hadoop file from the linux system to Windows. Now we open the hadoop file, go to the / etc/hadoop / directory, and copy the following four files to the project just created by IDEA
Four files ↓
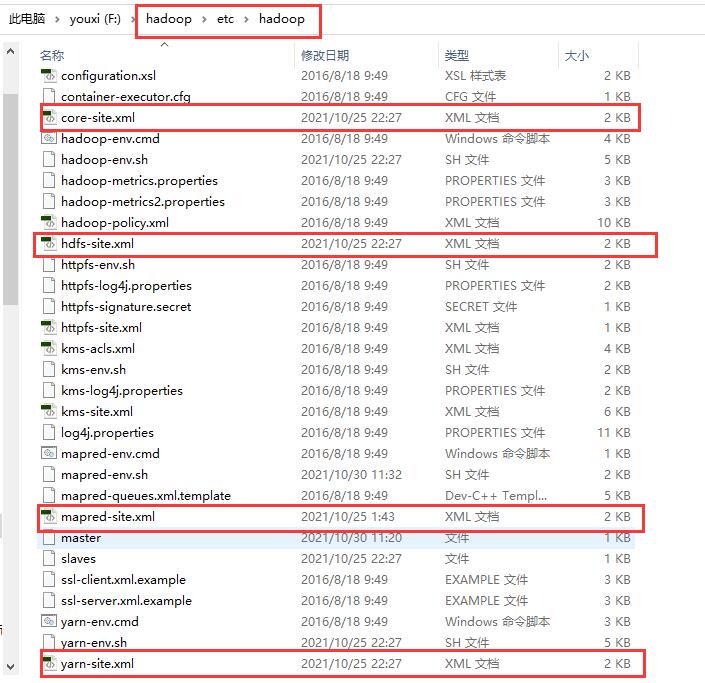
Copy to the resources folder of the project ↓
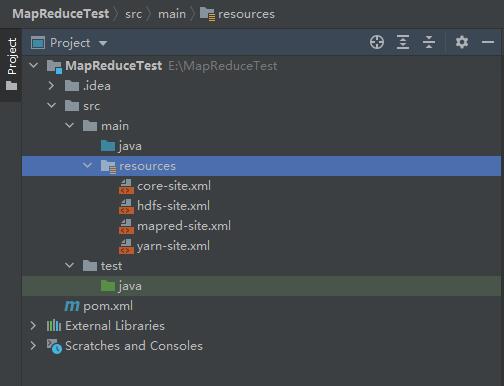
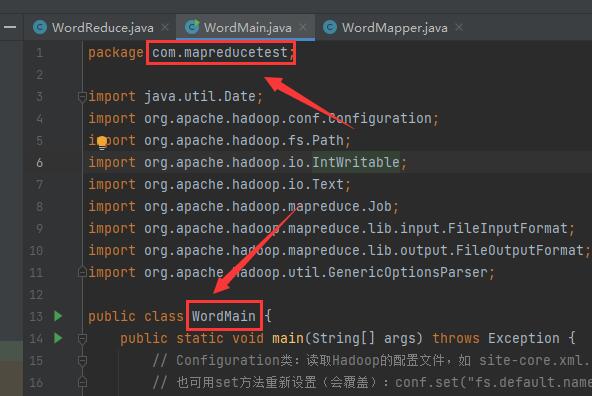
Then we create a package and three classes: WordMain.java, WordMapper.java and WordReduce.java
The first one is to partially configure the creation of tasks, and the latter two classes implement the corresponding Map and Reduce methods respectively
WordMain driver class code ↓
package com.mapreducetest;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordMain {
public static void main(String[] args) throws Exception {
// Configuration class: read Hadoop configuration files, such as site-core.xml;
// You can also use the set method to reset (overwrite): conf.set ("FS. Default. Name"“ hdfs://xxxx:9000 ")
Configuration conf = new Configuration();
// Automatically set the parameters in the command line to the variable conf
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
/**
* There must be input and output
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count"); // Create a new job and pass in the configuration information
job.setJarByClass(WordMain.class); // Set the main class of the job
job.setMapperClass(WordMapper.class); // Set Mapper class of job
job.setCombinerClass(WordReduce.class); // Set job composition class of job
job.setReducerClass(WordReduce.class); // Set the Reducer class of the job
job.setOutputKeyClass(Text.class); // Set key classes for job output data
job.setOutputValueClass(IntWritable.class); // Set job output value class
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); // File input
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); // File output
boolean result = false;
try {
result = job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(new Date().toGMTString() + (result ? "success" : "fail"));
System.exit(result ? 0 : 1); // Wait for completion exit
}
}
WordMapper class code ↓
package com.mapreducetest;
import java.io.IOException;
import java.util.Date;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// Create a WordMap class that inherits from the Mapper abstract class
public class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// The core method of Mapper abstract class has three parameters
public void map(Object key, // First character offset
Text value, // One line of file
Context context) // The Mapper side context is similar to the functions of OutputCollector and Reporter
throws IOException, InterruptedException {
String[] ars = value.toString().split("['.;,?| \t\n\r\f]");
for (String tmp : ars) {
if (tmp == null || tmp.length() <= 0) {
continue;
}
word.set(tmp);
System.out.println(new Date().toGMTString() + ":" + word + "Once, count+1");
context.write(word, one);
}
}
}
WordReducer class code ↓
package com.mapreducetest;
import java.io.IOException;
import java.util.Date;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// Create a WordReduce class that inherits from the Reducer abstract class
public class WordReduce extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable(); // Used to record the final word frequency of the key
// The core method of the Reducer abstract class has three parameters
public void reduce(Text key, // key value output from Map end
Iterable<IntWritable> values, // The Value set output from the Map side (the set with the same key)
Context context) // The context of the Reduce side is similar to the functions of OutputCollector and Reporter
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) // Traverse the values set and add the values
{
sum += val.get();
}
result.set(sum); // Get the final word frequency
System.out.println(new Date().toGMTString()+":"+key+"There it is"+result);
context.write(key, result); // Write results
}
}
After the three files are completed, there is a Maven toolbar on the right side of the IDEA. Open it and find the "clean" and "package" instructions in the Lifecycle. First double-click clean, and then double-click package to package after the program is completed! Then you can see our packaged jar package file in the target file of the project.
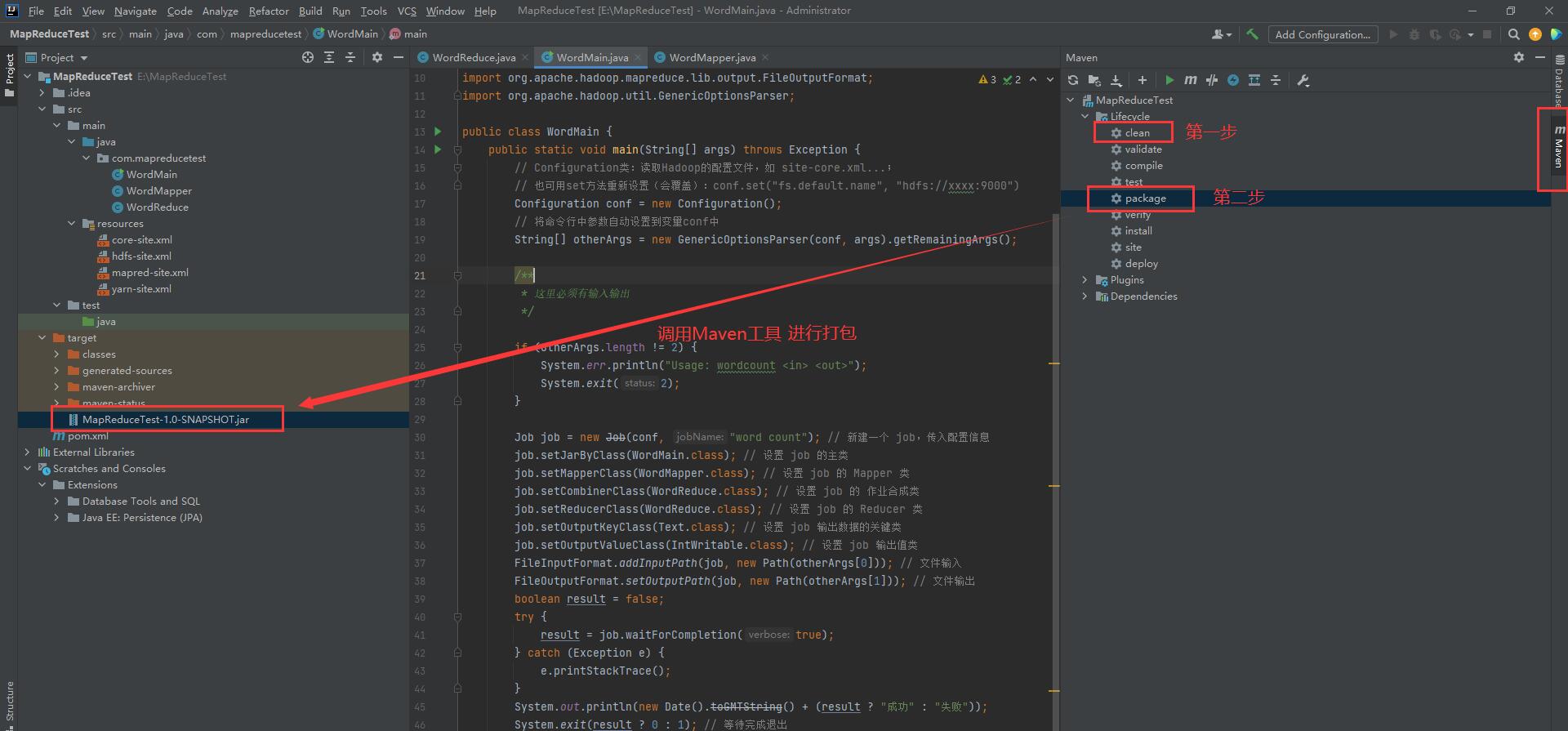
6, Perform word statistics
Let's go to the hadoop master node of linux and put the just packaged jar package and the word text file in the / home directory ↓
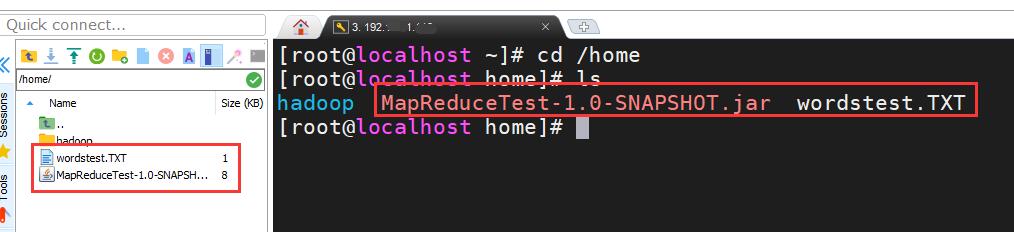
Start hadoop cluster, command ↓
start-all.sh
Then we create an ainput folder on HDFS to store the uploaded files, and then we upload the word files to HDFS ↓
Don't forget to give the folder modifiable, readable and executable permissions. Command ↓
hdfs dfs -mkdir /ainput hdfs dfs -put /home/wordstest.TXT /ainput hdfs dfs -chmod 777 /ainput

Here comes the big play!! We use the uploaded word statistics driver jar package to make word statistics for word files. The command is ↓
hadoop jar MapReduceTest-1.0-SNAPSHOT.jar com.mapreducetest.WordMain /ainput /aoutput
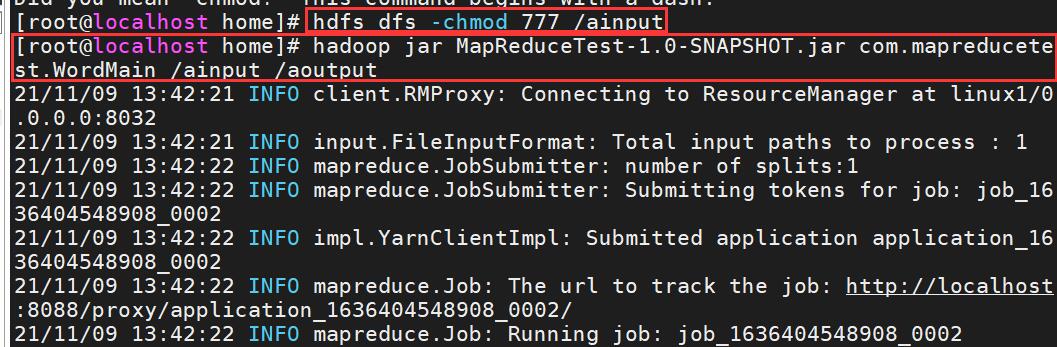
Parse command ↓
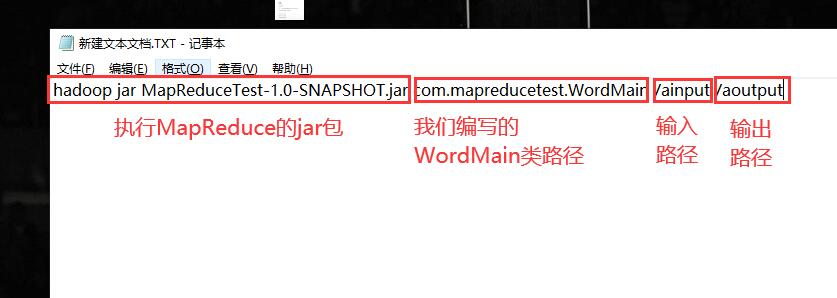
WordMain classpath ↓
Statistical results ↓
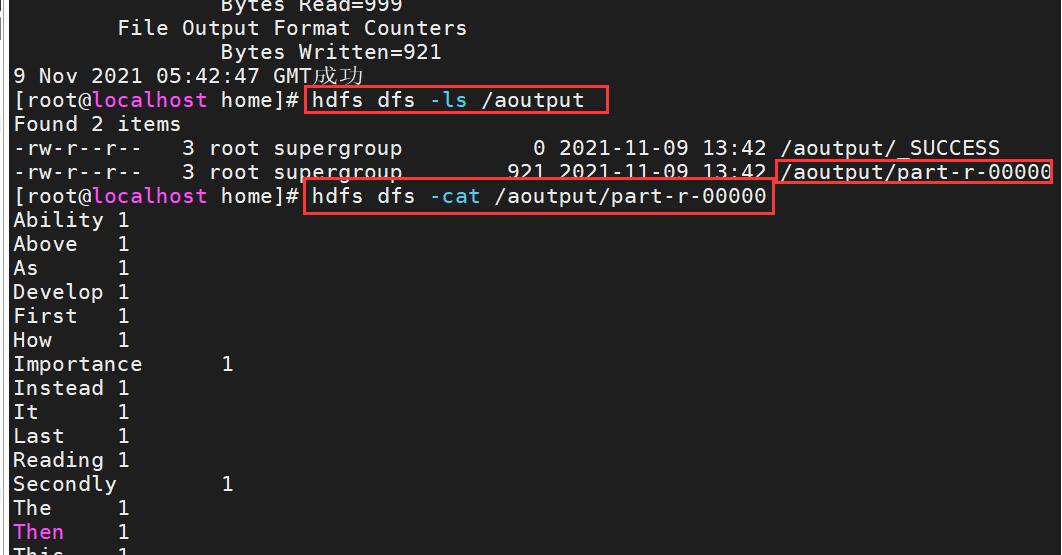
This sharing is over. Thank you for reading!!