Hadoop principle
1. HDFS write process
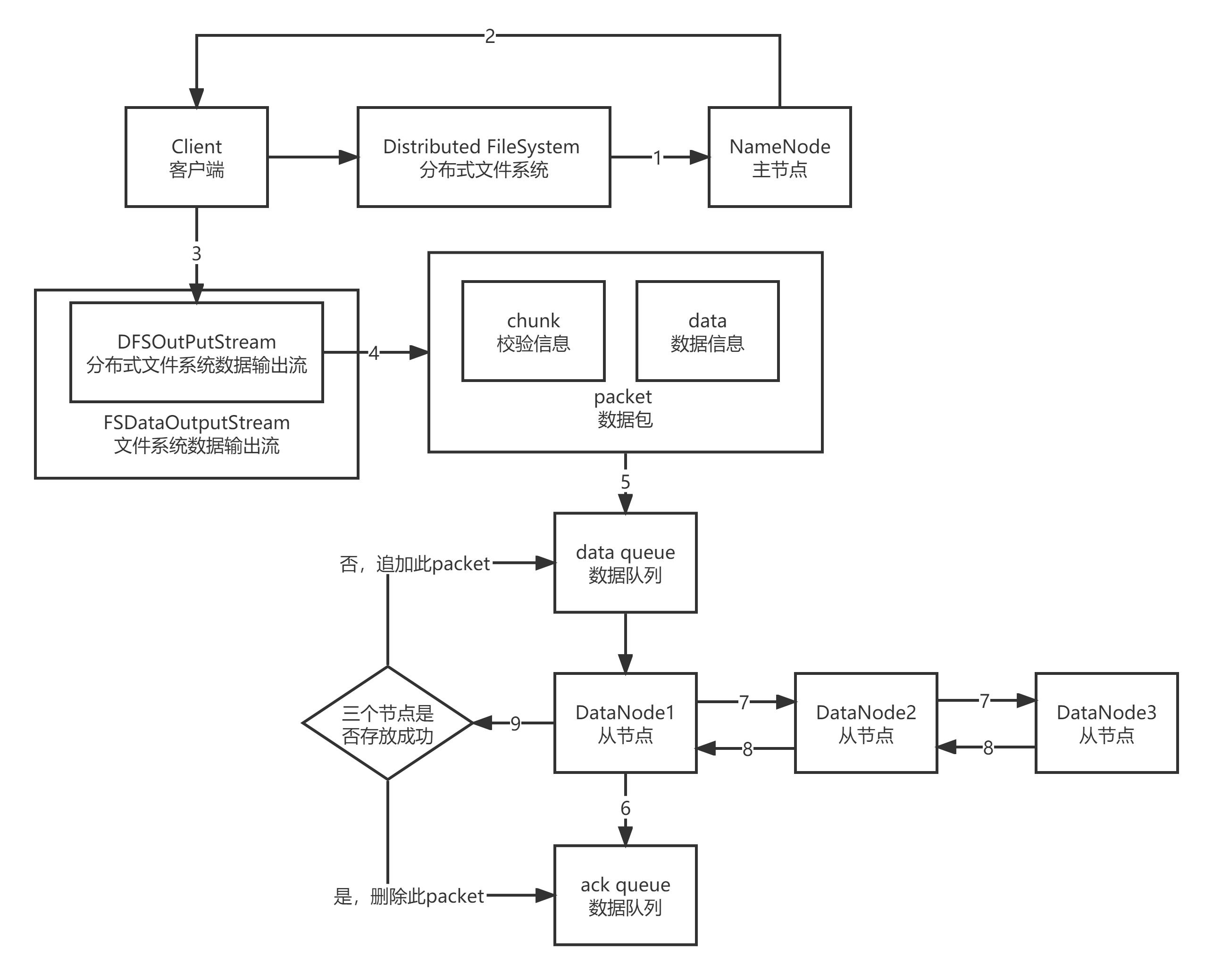
1.client adopt Distributed FileSystem Module direction NameNode Request to upload files, NameNode It will check whether the target file exists, whether the path is correct, and whether the user has permission. 2.NameNode towards client Return whether you can upload or not, and return three items at the same time client Near DataNode Node, recorded as DN1/DN2/DN3. 3.client adopt DFSOutPutStream Perform data cutting. 4.use chunk Verification information(512bytes Verification information+4bytes Check head)plus Data The data information forms a 64 KB of packet data block(Binary). 5.with packet Transfer files as units, load into data queue Yes. 6.DN1 receive packet After, there will be two data flows, one is: DN1-ack queue,Second is DN1-DN2-DN3. 7.DN1 and DN2/DN3 Establish between pipeline File transfer. 8.After the file is transferred, DN3,DN2 Hui Xiang DN1 Return success flag. 9.DN1 according to DN2/DN3 The return flag determines from ack queue Delete this block or append this block to data queue end.
2.HDFS reading process
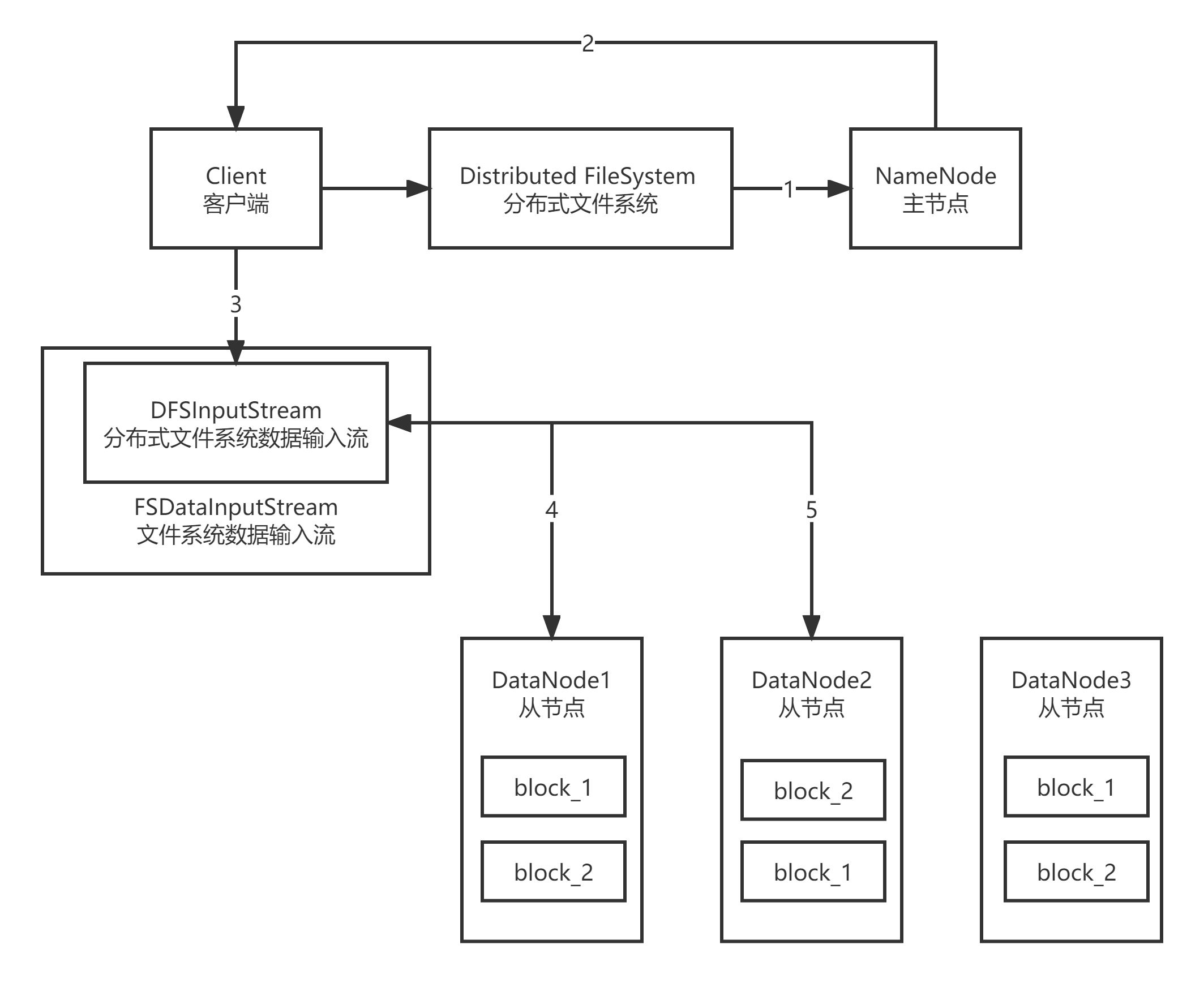
1.client adopt Distributed FileSystem Module direction NameNode Request to download files, NameNode It will check whether the target file exists, whether the path is correct, and whether the user has permission. 2.NameNode towards client Returns how many blocks of this file are stored DataNode Come on. 3.client adopt FSDataInputStream instantiation DFSInputStream,And follow the principle of proximity from DataNode The number of data blocks read on the node packet. 4.client with packet It is received as a unit. It is first cached locally, then written to the target file, and finally integrated block.
3.MapReduce workflow
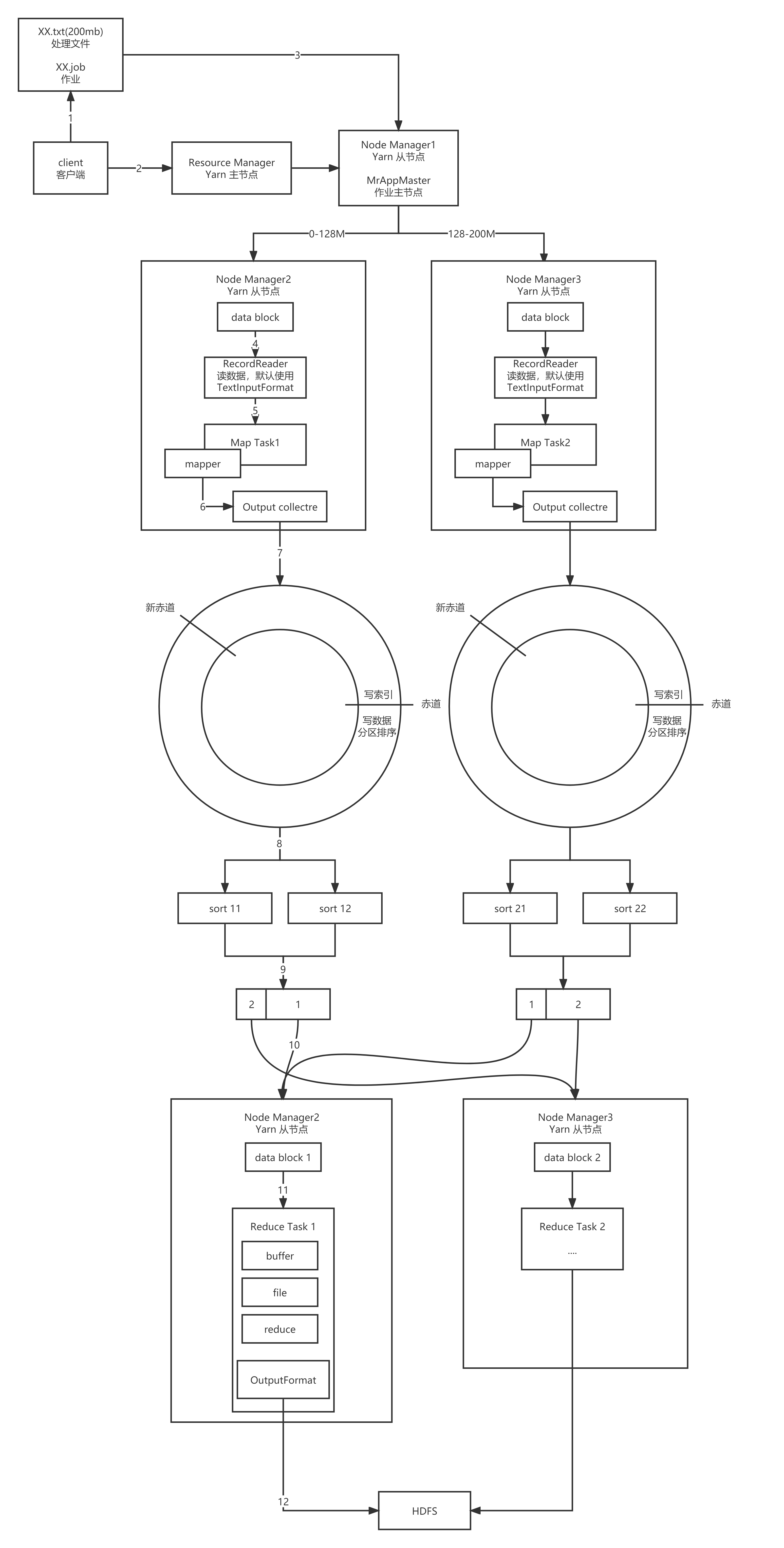
1. Obtain the text path to be processed, the job path, probe the text details, and generate the plan configuration file. 2. Client towards RM Submit the assignment, RM Assign tasks to NM1,NM1 generate MrAppMaster. 3. MrAppMaster Download resources from the path to the local and apply for running resources NM2/NM3,Transfer file segmentation and related resources to NM2/NM3. 4. NM2/NM3 generate mapTask Tasks, using RecordReader Read data (default) TextInputFormat). 5. RecordReader Cut data into K-V Form data to mapper. 6. mapper After calculation, output the data to OutputCollectre. 7. OutputCollectre Write data to the ring buffer, which defaults to 100 M,Start from the equator, write data and index in both directions, and write to 80%Post reverse write 8. Press in the ring buffer for data key Value partition sorting (fast sorting) 9. Overflow when the ring buffer reaches the threshold, merge Merge with key Partition and overflow to disk 10. reduceTask Pull data to local partition 11. reduceTask Merge files, merge and sort 12. adopt OutPutformat Output the results to the specified location. default TextOutputFormat
4. job submission process of yarn
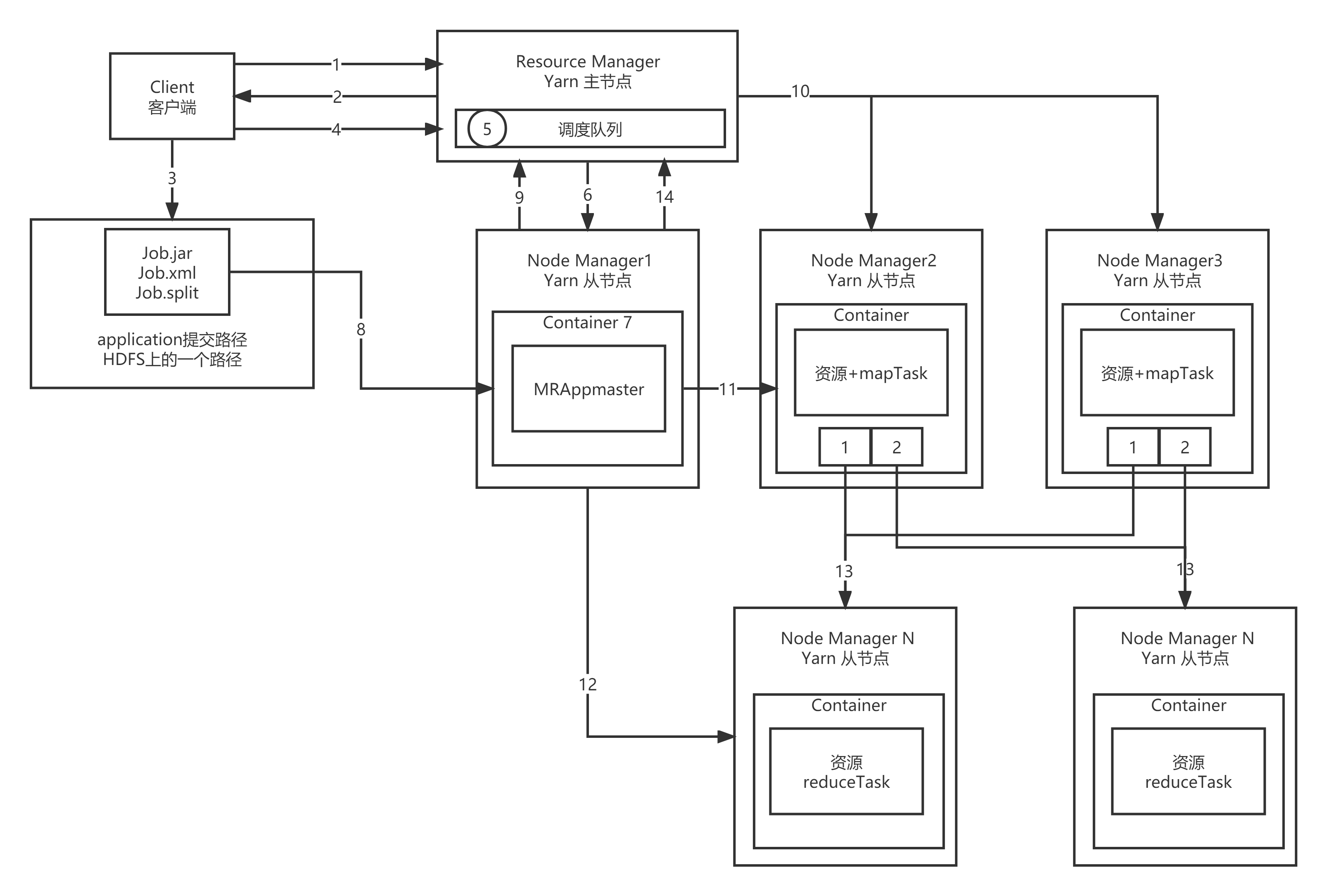
1. client towards RM Apply for one application 2. RM return application Resource submission path and ID 3. client Submit resources required for job operation to application route 4. After resource submission client towards RM Apply for operation APPmaster 5. Initialize the user's request as a Task,And put it into the scheduler 6. RM Notify a free NM To collect Task task 7. Should NM Create container container,And generate a MrAppMaster 8. Should NM take job Download resources locally 9. MrAppMaster towards RM Request to run multiple MapTask Task resources 10. RM Will run MapTask Assign tasks to others NM 11. MrAppMaster Responsible to MapTask Operational NM Send program startup script 12. MrAppMaster wait for MapTask After running, report to RM Apply for operation ReduceTask Resources 13. ReduceTask Pull away MapTask The data of the corresponding partition shall be recorded reduce operation 14. After the program runs, MrAppMaster Hui Xiang RM Apply for cancellation
5.Yarn scheduler
yarn has three schedulers:
- FIFO scheduler: first in first out, single queue, only one task in the queue is executing at the same time.
- Capacity scheduler: the default scheduler is multi queue. Only one task in the queue is executing at the same time.
- Fair scheduler: multiple queues. Each queue allocates resources to start tasks according to the size of internal vacancy. Multiple tasks are executed in the queue at the same time, and the parallelism of the queue is greater than the number of queues.
- Vacancy: the gap between the computing resources obtained by each job in the ideal situation and the computing resources actually obtained. The larger the vacancy, the higher the priority.
tuning
1. HDFS small file archiving
hdfs saves the metadata information of each small file in memory, and a small file occupies 150KB of memory. Generally, the NameNode node uses 128GB memory nodes. Such a memory node can only store 910 million small files, so it is necessary to archive small files and reduce the size of memory metadata.
-
HAR archiving
- file hadoop archive -archiveName dataName.har -p /tmp/data/input /tmp/data/output - decompression hadoop fs -cp har:///tmp/data/output/dataName.har/* /tmp/data/input - matters needing attention After archiving, the source file needs to be deleted manually
-
Adopt CombineTextInputFormat
job.setInputFormatClass(CombineTextInputFormat.class) CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m CombineTextInputFormat.setMinInputSplitSize(job, 2097152);// 2m
-
JVM reuse
<property> <name>mapreduce.job.jvm.numtasks</name> <value>10</value> (Increase here, generally 10-20 Between) <description>How many tasks to run per jvm,if set to -1 ,there is no limit</description> </property>
2.NameNode heartbeat concurrency configuration
formula: 20*ln Cluster size
3. Principle of erasure code
Erasure code is to change the exponential rise of storage cost caused by HDFS storage copy.
There is a file of 300m. If HDFS2 is used for storage, it is assumed that it is saved as 3 copies, which requires 900m space.
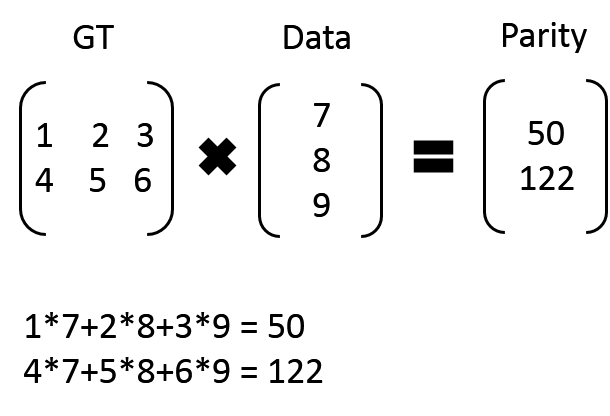
Using HDFS3 for storage, assuming that it is saved as 3 copies, it only takes 500m space (divide 300m files into three copies, one is 100m, add two verification units GT, one is 100m), and even if two copies of data are lost, it can be calculated through the remaining reverse.
4. Hot and cold data separation
HDFS storage type:
| Storage type | Storage mode |
|---|---|
| RAM_DISK | Memory image file system, stored in memory |
| SSD | Solid state disk |
| DISK | Normal disk, default storage type |
| ARCHIVE | There is no specific storage medium, which is mainly used for archiving |
HDFS storage policy:
| Policy ID | Policy name | Replica distribution | explain |
|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK:1,DISK:n-1 | One copy is saved in memory and the other is saved on disk |
| 12 | All_SSD | SSD:n | All copies are saved in SSD |
| 10 | One_SSD | SSD:n,DISK:n-1 | One copy is saved on SSD and the other is saved on disk |
| 7 | Hot(default) | DISK:n | All copies are saved on disk |
| 5 | Warm | DISK:1,ARCHIVE:n-1 | One copy is kept on disk and the other is archived |
| 2 | Cold | ARCHIVE:n | All copies are archived |
Common commands:
# View what storage policies are currently available
hdfs storagepolicies -listPolicies
# Sets the specified storage policy for the specified path (data storage directory)
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx
# Gets the storage policy of the specified path (data storage directory or file)
hdfs storagepolicies -getStoragePolicy -path xxx
# Cancel the storage policy; After executing the change command, the directory or file shall be subject to its parent directory. If it is the root directory, it is HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx
# View the distribution of file blocks
bin/hdfs fsck xxx -files -blocks -locations
# View cluster nodes
hadoop dfsadmin -report
# Common configuration HDFS site XML configuration directory storage type
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///opt/module/hadoop-3.1.4/hdfsdata/ssd,[DISK]file:///opt/module/hadoop-3.1.4/hdfsdata/disk</value>
</property>
5.HDFS load balancing
Load balancing between nodes
Enable data equalization command:
start-balancer.sh -threshold 10
For parameter 10, it means that the difference in disk space utilization of each node in the cluster is no more than 10%, which can be adjusted according to the actual situation.
Stop data balancing command:
stop-balancer.sh
Inter disk load balancing
(1) Generate balance plan (we only have one disk and will not generate plan)
hdfs diskbalancer -plan host name
(2) Execute balanced plan
hdfs diskbalancer -execute host name.plan.json
(3) View the execution of the current balancing task
hdfs diskbalancer -query host name
(4) Cancel balancing task
hdfs diskbalancer -cancel host name.plan.json
6.HDFS benchmark
(1) Test HDFS write performance
// Test content: write 10 128M files to HDFS cluster hadoop jar /opt/module/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3- tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
(2) Test HDFS read performance
// Test content: read 10 128M files of HDFS cluster hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3- tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
(3) Delete test generated data
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
(4) Evaluate MR with Sort program
// RandomWriter is used to generate random numbers. Each node generates 10 Map tasks, and each Map generates binary random numbers of about 1G size hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-dat // Perform Sort program sorting hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data // Verify whether the data is really sorted hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
7. Hadoop LZO compression
-
Compile jar package
1.install maven 2.Compilation environment preparation yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool 3.compile # Download lzo wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz tar -zxvf lzo-2.10.tar.gz cd lzo-2.10 ./configure -prefix=/usr/local/hadoop/lzo/ make make install 4.compile Hadoop-Lzo git clone https://github.com/twitter/hadoop-lzo/archive/master.zip unzip master.zip cd hadoop-lzo-master # Modify hadoop version number vi pom.xml <hadoop.current.version>3.1.3</hadoop.current.version> # Declare two temporary environment variables export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include export LIBRARY_PATH=/usr/local/hadoop/lzo/lib # compile mvn package -Dmaven.test.skip=true cd target # Here is the compiled Hadoop LZO Jar package
-
Configure core site xml
cp hadoop-lzo-0.4.20.jar hadoop3/share/hadoop/common/ vi /hadoop3/etc/hadoop/core-site.xml <configuration> <property> <name>io.compression.codecs</name> <value> org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec </value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property> </configuration> synchronization jar Package and configuration to other nodes -
Configure Lzo index
The slice of Lzo compressed file depends on the index. We need to create an index for Lzo compressed file. If there is no index, there is only one slice of Lzo file
hadoop jar /opt/module/hadoop3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo
8.HDFS benchmark
# Write 10 128M files to HDFS cluster hadoop jar /opt/module/hadoop3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB # Read 10 128M files from HDFS cluster hadoop jar /opt/module/hadoop3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB # Delete test data hadoop jar /opt/module/hadoop3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
9.MapReduce optimization
# Reduce the number of overflow writes mapreduce.task.io.sort.mb shuffle The size of the ring buffer can be appropriately increased mapreduce.task.io.sort.spill.percent shuffle The ring buffer overflow threshold can be appropriately increased # Increase the number of merges per merge mapreduce.task.io.sort.factor reduce merge Number of merges # Adjust MapTask memory, stack, and CPU core count mapreduce.map.memory.mb You can press 128 M Data increase 1 G Memory regulation mapreduce.map.java.opts increase MapTask Heap memory size mapreduce.map.cpu.vcores increase MapTask of CPU Kernel number # Increase the number of parallel data pulled by ReduceTask mapreduce.reduce.shuffle.parallelcopiees Can be appropriately improved # Increase the memory proportion of ReduceTask occupied by Buffer mapreduce.reduce.shuffle.input.buffer.percent Default 0.7,Can be appropriately improved # Adjust how much data in the Buffer is written to disk mapreduce.reduce.shuffle.merge.percent Default 0.66,Can be appropriately improved # Adjust the number of ReduceTask memory, stack and CPU cores mapreduce.reduce.memory.mb You can press 128 M Data increase 1 G Memory regulation mapreduce.reduce.java.opts increase ReduceTask Heap memory size mapreduce.reduce.cpu.vcores increase ReduceTask of CPU Kernel number # Adjust the start time of ReduceTask mapreduce.job.reduce.slowstart.completedmaps Default when MapTask Complete 50%Will start when ReduceTask # Set job timeout mapreduce.task.timeout Default 10 minutes, Task If there is no response, kill the task
10.Yarn optimization
# Configure scheduler, default capacity scheduler yarn.resourcemanager.scheduler.class # The number of threads that ResourceManager processes scheduler requests. The default is 50 yarn.resourcemanager.scheduler.client.thread-count # Whether to let yarn detect the hardware and configure it by itself. The default is false yarn.nodemanager.resource.detect-hardware-capabilities # Whether to treat virtual cores as CPU cores. The default is false yarn.nodemanager.resource.count-logical-processors-as-cores # Virtual core and physical core multiplier, for example: 4-core 8-thread, this parameter should be set to 2, and the default is 1.0 yarn.nodemanager.resource.pcores-vcores-multiplier # NodeManager uses memory, 8G by default yarn.nodemanager.resource.memory-mb # How much memory does the NodeManager reserve for the system yarn.nodemanager.resource.system-reserved-memory-mb # NodeManager uses 8 CPU cores by default yarn.nodemanager.resource.cpu-vcores # Whether to turn on the physical memory check limit container. It is turned on by default yarn.nodemanager.pmem-check-enabled # Whether to enable the virtual memory check limit container. It is on by default yarn.nodemanager.vmem-check-enabled # Virtual memory physical memory ratio, default 2.1 yarn.nodemanager.vmem-pmem-ratio # The minimum memory of the container is 1G by default yarn.scheduler.minimum-allocation-mb # The maximum memory of the container is 8G by default yarn.scheduler.maximum-allocation-mb # The minimum number of CPU cores of the container is 1 by default yarn.scheduler.minimum-allocation-vcores # The maximum number of CPU cores of the container is 4 by default yarn.scheduler.maximum-allocation-vcores