Big data has to mention the most useful weapon Hadoop. This article is the fastest way for you to get started with Hadoop. Hadoop has a quick introduction and a perceptual understanding, which can also be used as a quick index of steps. This article solves the following problems:
- Understand what Hadoop is
- What is Hadoop used for and how to use it
- Hadoop uses a basic process and structure of the whole
Understand what Hadoop is
-
HADOOP is an open source software platform under apache
-
HADOOP provides the function of distributed processing of massive data according to user-defined business logic by using server cluster
-
The core components of HADOOP are
- HDFS (distributed file system)
- YARN (computing resource scheduling system)
- MAPREDUCE (distributed computing programming framework)
- In a broad sense, HADOOP usually refers to a broader concept - HADOOP ecosystem
-
Why Hadoop?
- HADOOP originated from nutch. Nutch's design goal is to build a large-scale whole network search engine, including web page capture, index, query and other functions. However, with the increase of the number of web pages captured, it has encountered a serious scalability problem - how to solve the problem of storage and index of billions of web pages.
- Two papers published by Google in 2003 and 2004 provide a feasible solution to this problem.
- Distributed file system (GFS) can be used to handle the storage of massive web pages
- MAPREDUCE, a distributed computing framework, can be used to deal with the index calculation of massive web pages.
- Nutch's developers completed the corresponding open source implementation of HDFS and MAPREDUCE, and separated from nutch into an independent project HADOOP. By January 2008, HADOOP had become the top project of Apache, ushering in its rapid development period.
What is Hadoop used for and how to use it
What is Hadoop used for
- Cloud computing is the product of the integration of traditional computer technology and Internet technology, such as distributed computing, parallel computing, grid computing, multi-core computing, network storage, virtualization, load balancing and so on. With the help of IAAs (infrastructure as a service), PAAS (platform as a service), SaaS (software as a service) and other business models, provide powerful computing power to end users.
- At this stage, the two underlying supporting technologies of cloud computing are "virtualization" and "big data technology"
- HADOOP is one of the solutions for the PaaS layer of cloud computing, which is not equivalent to PaaS, let alone cloud computing itself.
How to use Hadoop
-
As mentioned above, HADOOP is actually a large ecosystem. Since it is an ecosystem, there are many important components:
- HDFS: distributed file system
- MAPREDUCE: distributed computing program development framework
- HIVE: SQL data warehouse tool based on big data technology (file system + operation framework)
- HBASE: distributed massive database based on HADOOP
- ZOOKEEPER: basic component of distributed coordination service
- Mahout: machine learning algorithm library based on distributed computing frameworks such as mapreduce/spark/flink
- Oozie: workflow scheduling framework
- Sqoop: data import and export tool
- Flume: log data collection framework
(the above methods of use will be supplemented slowly in the future and a pit will be dug)
-
Hadoop cluster construction
When it comes to Hadoop cluster construction, it is to build the required core components. Hadoop cluster includes two important clusters: HDFS cluster and YARN cluster
-
HDFS cluster: responsible for the storage of massive data. The main roles in the cluster are NameNode / DataNode
-
YARN cluster: it is responsible for resource scheduling during massive data operation. The main roles in the cluster are ResourceManager /NodeManager
Note: what is mapreduce? It is actually an application development package, which is mainly responsible for business logic development.
-
This cluster building case takes 5 nodes as an example, and the role allocation is as follows:
> hdp-node-01 NameNode SecondaryNameNode(HDFS) > > hdp-node-02 ResourceManager (YARN) > > hdp-node-03 DataNode NodeManager (HDFS) > > hdp-node-04 DataNode NodeManager (HDFS) > > hdp-node-05 DataNode NodeManage r(HDFS)
The deployment diagram is as follows:
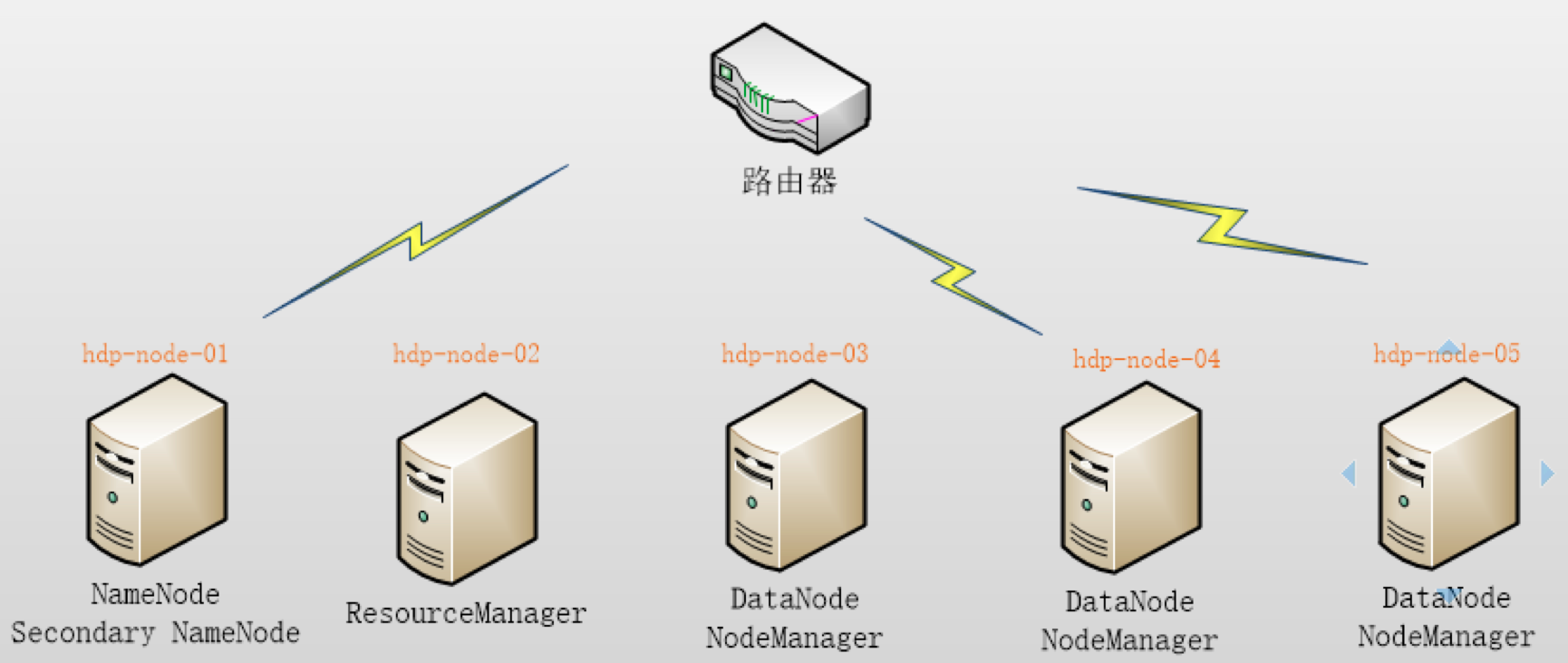
Cluster construction case
Because the simulator can be used to simulate five linux servers, the details are ignored.
Hadoop installation and deployment to ensure that each linux has Hadoop installation package:
-
Planning installation directory: / home/hadoop/apps/hadoop-2.6.1
-
Modify basic configuration file: $HADOOP_HOME/etc/hadoop/
The corresponding Hadoop simplest configuration is as follows:-
Hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/home/hadoop/apps/jdk1.8
-
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-node-01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/HADOOP/apps/hadoop-2.6.1/tmp</value> </property> </configuration> -
hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>hdp-node-01:50090</value> </property> </configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Note: the configuration of the five linux should be the same. Hadoop 2.0 is used here 6.1 modify according to your own
-
Start cluster
Execute in the terminal:
#Initialize HDFS bin/hadoop namenode -format #Start HDFS bin/start-dfs.sh #Start YARN bin/start-yarn.sh
test
1. Upload files to HDFS
Upload a text file locally to the / wordcount/input directory of hdfs
Terminal code:
[HADOOP@hdp-node-01 ~]$ HADOOP fs -mkdir -p /wordcount/input [HADOOP@hdp-node-01 ~]$ HADOOP fs -put /home/HADOOP/somewords.txt /wordcount/input
2. Run a mapreduce program
Run an example mr program in the HADOOP installation directory:
cd $HADOOP_HOME/share/hadoop/mapreduce/ hadoop jar mapredcue-example-2.6.1.jar wordcount /wordcount/input /wordcount/output
Note: example is hadoop's own program, which is used to test whether the setup is successful
Hadoop data processing flow
Typical BI system flow chart is as follows:
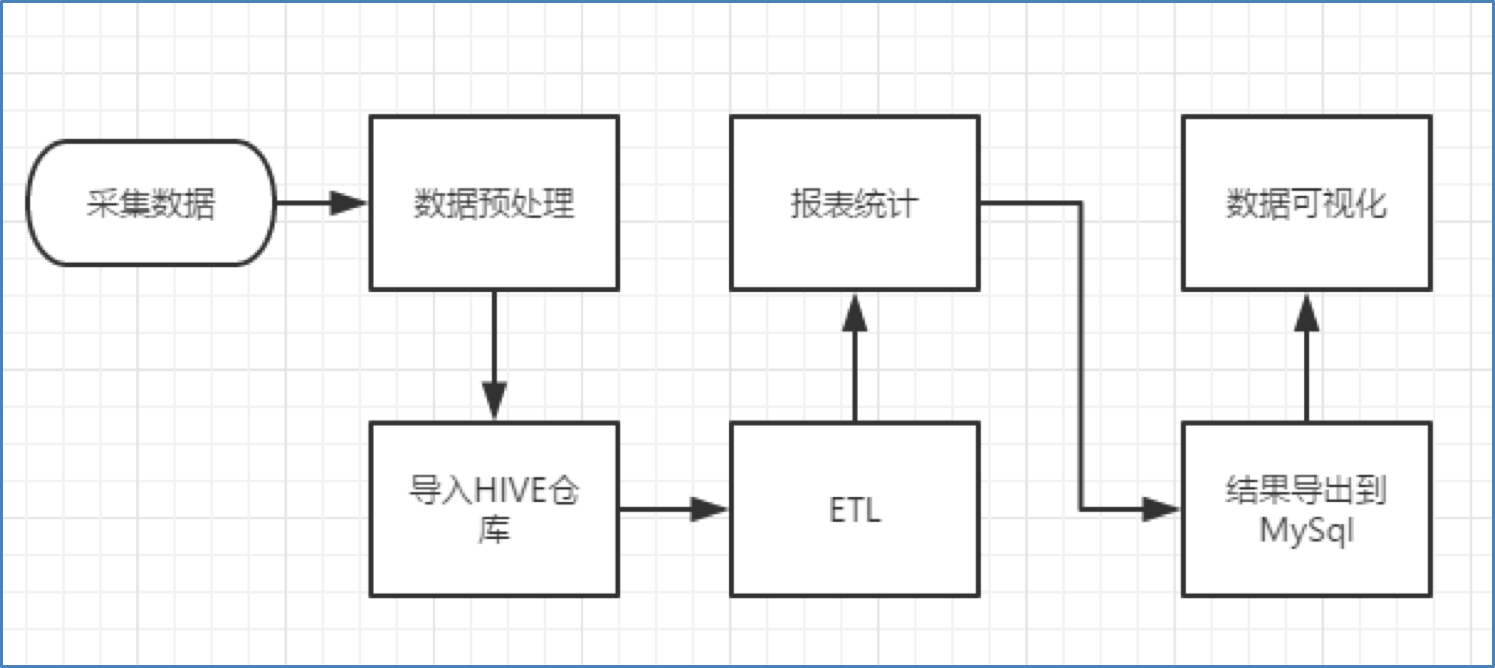
BI system flow chart
As shown in the figure, although the technologies used may be different, the process is basically as shown in the figure:
-
Data collection: customize and develop the collection program, or use the open source framework FLUME
-
Data preprocessing: custom developed mapreduce program runs on hadoop cluster
-
Data warehouse technology: Hive based on hadoop
-
Data export: sqoop data import and export tool based on hadoop
-
Data visualization: customize and develop web programs or use kettle and other products
-
Process scheduling of the whole process: oozie tools in hadoop ecosystem or other similar open source products
Author: Mu Jiujiu
Link: https://www.jianshu.com/p/94844ec599bf
Source: Jianshu
The copyright belongs to the author. For commercial reprint, please contact the author for authorization. For non-commercial reprint, please indicate the source.