Introduction to High Availability
High Availability of Hadoop can be divided into HDFS high availability and YARN high availability. Their implementation is basically similar, but HDFS NameNode requires much higher data storage and consistency than YARN Resource Manger, so its implementation is more complex. So let's explain the following:
1.1 High Availability Architecture
HDFS High Availability Architecture is as follows:

Pictures are quoted from: https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-high-availability/
HDFS High Availability Architecture consists of the following components:
-
Active NameNode and Standby NameNode: The two NameNodes are mutually available. One is in Active state, the main NameNode, and the other is in Standby state. Only the main NameNode can provide reading and writing services to the outside world.
-
ZKFailover Controller: ZKFailover Controller runs as an independent process, which controls the master switch of NameNode. ZKFailover Controller can detect the health status of NameNode in time, and realize automatic backup election and switching with Zookeeper when the main NameNode fails. Of course, NameNode also supports manual backup switching without Zookeeper.
-
Zookeeper Cluster: Provides backup election support for backup switching controllers.
-
Shared storage system: Shared storage system is the most critical part to achieve high availability of NameNode. Shared storage system preserves the metadata of HDFS generated by NameNode during its operation. Master NameNode and NameNode realize metadata synchronization through shared storage system. When switching between master and standby, the new master NameNode can continue to provide services only after confirming that metadata is fully synchronized.
- DataNode node: In addition to sharing metadata information of HDFS through shared storage system, the mapping relationship between HDFS data blocks and DataNode is also needed for master NameNode and standby NameNode. DataNode reports the location information of the data block to both the main NameNode and the standby NameNode.
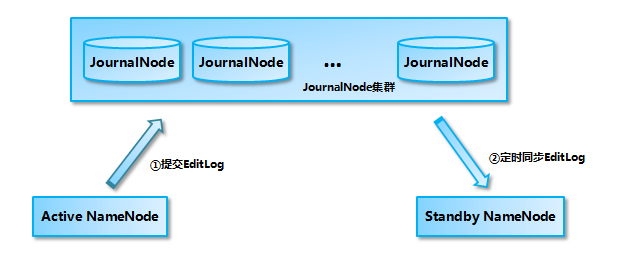
1.2 Data Synchronization Mechanism Analysis of Shared Storage System Based on QJM
At present, Hadoop supports the use of Quorum Journal Manager (QJM) or Network File System (NFS) as a shared storage system. This paper takes QJM cluster as an example to illustrate: Active NameNode first submits EditLog to Journal Node cluster, then Standby NameNode synchronizes EditLog from Journal Node cluster, when A After the active NameNode goes down, Standby NameNode can provide services to the outside world after confirming that metadata is fully synchronized.
It should be noted that writing EditLog to the JournalNode cluster follows the strategy of "more than half write is successful", so you need at least three JournalNode nodes. Of course, you can continue to increase the number of nodes, but you should ensure that the total number of nodes is odd. At the same time, if there are 2N+1 JournalNode, then according to the principle of more than half writing, it can tolerate at most N JournalNode nodes hanging up.
1.3 NameNode primary and standby switching
NameNode's main and standby switching process is shown in the following figure:
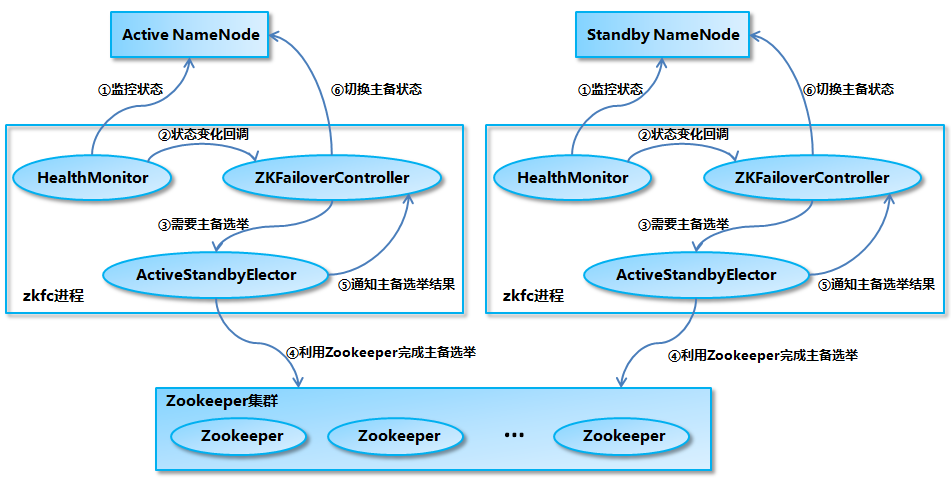
- After the initialization of Health Monitor is completed, internal threads are started to call the method corresponding to the HASERVICE Protocol RPC interface of NameNode periodically to detect the health status of NameNode.
- If the Health Monitor detects a change in the health status of NameNode, it calls back the corresponding method registered by ZKFailover Controller for processing.
- If ZKFailover Controller decides that a primary-standby switch is needed, it will first use Active Standby Elector to conduct an automatic primary election.
- Active Standby Elector interacts with Zookeeper to complete an automatic backup election.
- Active Standby Elector calls back the corresponding method of ZKFailover Controller to notify the current NameNode to become the main NameNode or the standby NameNode after the primary election is completed.
- ZKFailover Controller calls the HASERVICE Protocol RPC interface corresponding to NameNode to convert NameNode to Active or Standby state.
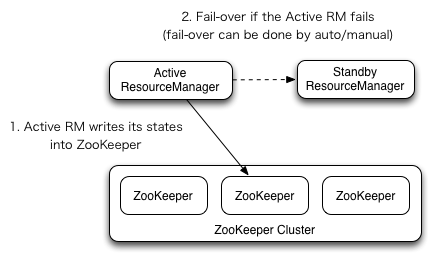
1.4 YARN High Availability
The high availability of YARN Resource Manager is similar to that of HDFS NameNode. However, unlike NameNode, ResourceManager does not have so much metadata information to maintain, so its status information can be written directly to Zookeeper and relies on Zookeeper for primary and standby elections.
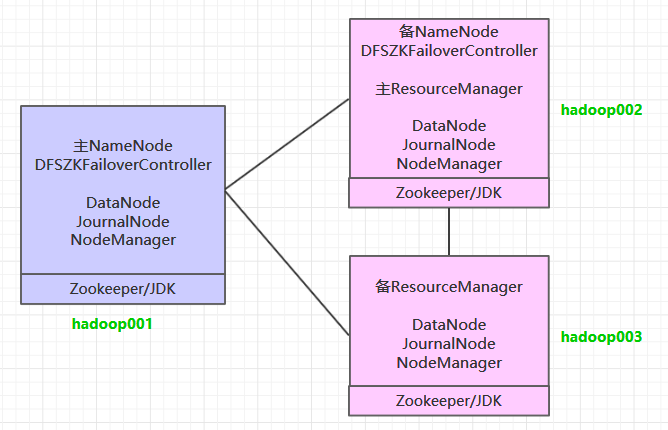
II. Cluster Planning
In accordance with the design goal of high availability, at least two NameNode s and two Resource Managers need to be guaranteed, while at least three Journal Nodes are required to satisfy the principle of "more than half writing is successful". Three hosts are used to build the cluster. The cluster planning is as follows:
Pre-conditions
- JDK is installed on all servers. The installation steps can be seen as follows: Installation of JDK under Linux;
- Setting up ZooKeeper cluster, the steps can be seen as follows: Construction of Zookeeper Single Computer Environment and Cluster Environment
- SSH secret-free login is configured between all servers.
IV. Cluster Configuration
4.1 Download and Unzip
Download Hadoop. Here I download the CDH version of Hadoop, the download address is: http://archive.cloudera.com/cdh5/cdh/5/
# tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
4.2 Configure environment variables
Edit profile file:
# vim /etc/profile
Add the following configuration:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATHExecute the source command to make the configuration take effect immediately:
# source /etc/profile
4.3 Configuration Modification
Go into the ${HADOOP_HOME}/etc/hadoop directory and modify the configuration file. The contents of each configuration file are as follows:
1. hadoop-env.sh
# Specify the installation location of JDK export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!-- Appoint namenode Of hdfs Communication Address of Protocol File System -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!-- Appoint hadoop Catalog of temporary files stored in cluster -->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<!-- ZooKeeper Address of Cluster -->
<name>ha.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop002:2181</value>
</property>
<property>
<!-- ZKFC connection to ZooKeeper Timeout duration -->
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
</property>
</configuration>3. hdfs-site.xml
<configuration>
<property>
<!-- Appoint HDFS Number of copies -->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- namenode The storage location of node data (i.e. metadata) can specify multiple directories for fault tolerance, and multiple directories are separated by commas. -->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!-- datanode Storage location of node data (i.e. data blocks) -->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
<property>
<!-- Logical name of cluster service -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- NameNode ID list-->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- nn1 Of RPC Mailing address -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop001:8020</value>
</property>
<property>
<!-- nn2 Of RPC Mailing address -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop002:8020</value>
</property>
<property>
<!-- nn1 Of http Mailing address -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop001:50070</value>
</property>
<property>
<!-- nn2 Of http Mailing address -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop002:50070</value>
</property>
<property>
<!-- NameNode Metadata in JournalNode Shared storage directory on -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/mycluster</value>
</property>
<property>
<!-- Journal Edit Files Storage catalogue -->
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journalnode/data</value>
</property>
<property>
<!-- Configure isolation mechanism to ensure that there is only one at any given time NameNode Being active -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!-- Use sshfence Mechanisms needed ssh Privacy free login -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- SSH timeout -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<!-- Access proxy class to determine the current status Active State NameNode -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- Turn on automatic failover -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>4. yarn-site.xml
<configuration>
<property>
<!--To configure NodeManager Accessory services running on. Need to be configured mapreduce_shuffle Only then can we Yarn Up operation MapReduce Program.-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- Whether log aggregation is enabled (Optional) -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- Storage time of aggregated logs (Optional) -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<!-- Enable RM HA -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- RM Cluster identifier -->
<name>yarn.resourcemanager.cluster-id</name>
<value>my-yarn-cluster</value>
</property>
<property>
<!-- RM Logic ID list -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- RM1 Service Address -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop002</value>
</property>
<property>
<!-- RM2 Service Address -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop003</value>
</property>
<property>
<!-- RM1 Web Address of the application -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop002:8088</value>
</property>
<property>
<!-- RM2 Web Address of the application -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop003:8088</value>
</property>
<property>
<!-- ZooKeeper Address of Cluster -->
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<property>
<!-- Enable automatic recovery -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!-- Classes for persistent storage -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>5. mapred-site.xml
<configuration>
<property>
<!--Appoint mapreduce The job runs at yarn upper-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5. slaves
Configure the host name or IP address of all subordinate nodes, one per line. The DataNode service and NodeManager service on all dependent nodes are started.
hadoop001 hadoop002 hadoop003
4.4 Distribution Procedure
Hadoop installation packages are distributed to two other servers, and it is recommended that Hadoop environment variables be configured on both servers.
# Distribution of installation packages to Hadoop 002 scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/ # Distribution of installation packages to Hadoop 003 scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/
V. Starting Clusters
5.1 Start ZooKeeper
Start ZooKeeper service on three servers:
zkServer.sh start
5.2 Start Journal node
Start the journalnode process in the ${HADOOP_HOME}/sbin directory of three servers:
hadoop-daemon.sh start journalnode
5.3 Initialize NameNode
Execute the NameNode initialization command on hadop001:
hdfs namenode -format
After executing the initialization command, you need to copy the contents of the NameNode metadata directory to other unformatted NameNodes. The metadata storage directory is the directory specified by the dfs.namenode.name.dir attribute in hdfs-site.xml. Here we need to copy it to Hadoop 002:
scp -r /home/hadoop/namenode/data hadoop002:/home/hadoop/namenode/
5.4 Initialization of HA state
Use the following commands on any NameNode to initialize the HA state in ZooKeeper:
hdfs zkfc -formatZK
5.5 Start HDFS
Go to the ${HADOOP_HOME}/sbin directory of Hadoop 001 and start HDFS. At this point, the NameNode service on hadoop001 and hadoop002 and the DataNode service on three servers will be started:
start-dfs.sh
5.6 Start YARN
Go to the ${HADOOP_HOME}/sbin directory of Hadoop 002 and start YARN. At this point, the ResourceManager service on hadoop002 and the NodeManager service on three servers will be started:
start-yarn.sh
It should be noted that the ResourceManager service on hadoop003 is usually not started at this time and needs to be started manually:
yarn-daemon.sh start resourcemanager
6. Viewing Clusters
6.1 View Process
After successful startup, the processes on each server should be as follows:
[root@hadoop001 sbin]# jps 4512 DFSZKFailoverController 3714 JournalNode 4114 NameNode 3668 QuorumPeerMain 5012 DataNode 4639 NodeManager [root@hadoop002 sbin]# jps 4499 ResourceManager 4595 NodeManager 3465 QuorumPeerMain 3705 NameNode 3915 DFSZKFailoverController 5211 DataNode 3533 JournalNode [root@hadoop003 sbin]# jps 3491 JournalNode 3942 NodeManager 4102 ResourceManager 4201 DataNode 3435 QuorumPeerMain
6.2 View Web UI
The port numbers of HDFS and YARN are 50070 and 8080 respectively. The interface should be as follows:
NameNode on Hadoop 001 is available at this time:
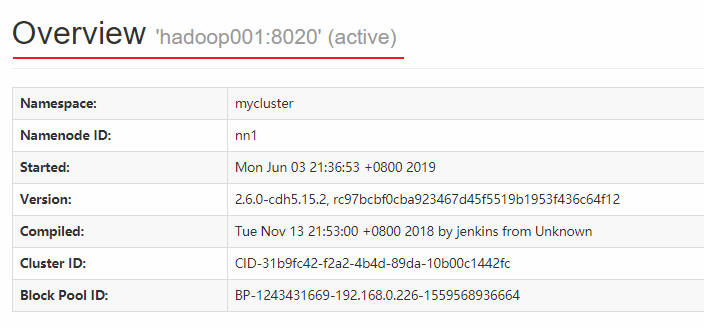
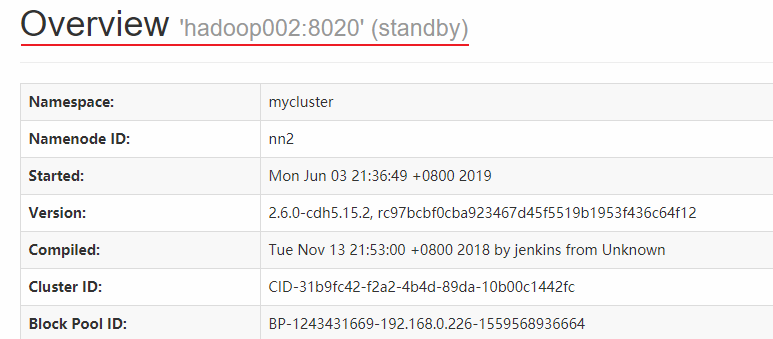
NameNode on Hadoop 002 is in standby state:
<br/>
<br/>
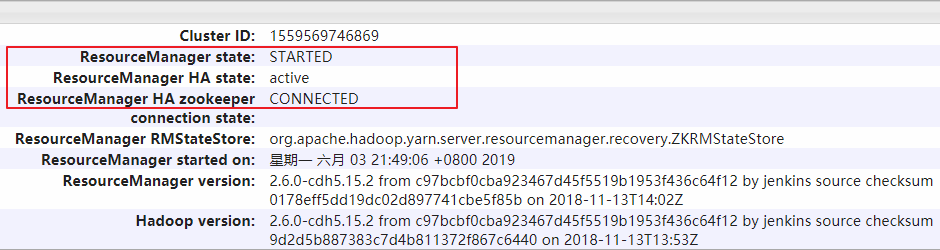
Resource Manager on Hadoop 002 is available:
<br/>
<br/>
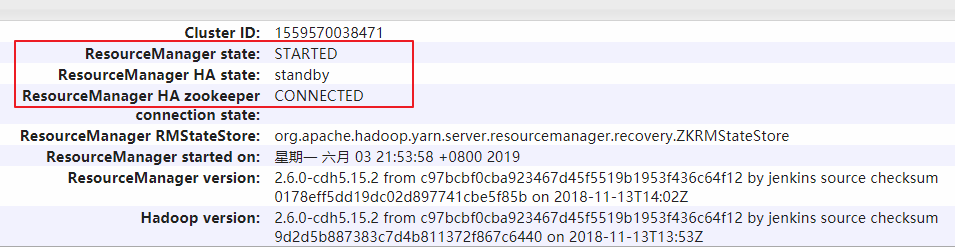
ResourceManager on hadoop003 is in standby state:
<br/>
<br/>
At the same time, the interface also has relevant information about Journal Manager:
<br/>
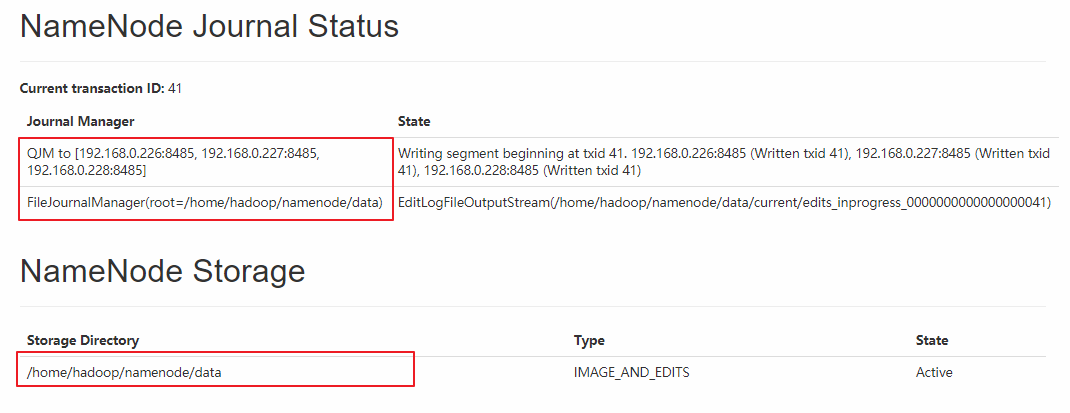
VII. Second Start-up of Cluster
The initial start-up of the cluster above involves some necessary initialization operations, so the process is slightly cumbersome. But once the cluster is built, it is convenient to start it again. The steps are as follows (first, make sure the ZooKeeper cluster is started):
When HDFS is started in Hadoop 001, all HDFS-related services, including NameNode, DataNode and JournalNode, are started:
start-dfs.sh
Start YARN at Hadoop 002:
start-yarn.sh
At this point, the ResourceManager service on hadoop003 is usually not started and needs to be started manually:
yarn-daemon.sh start resourcemanager
Reference material
The above steps are mainly referred to from official documents:
For a detailed analysis of Hadoop's high availability principle, read:
Hadoop NameNode High Availability Implementation Parsing
For more big data series articles, see the GitHub Open Source Project: Introduction Guide to Big Data