demand
Crawling Pictures in Webmaster material
ImagesPipeline for image data crawling
Crawl pictures
xpath parses the attribute value of the picture src. Make a separate request for the picture address to obtain the binary type data of the picture.
ImagesPipeline
You only need to parse the src attribute in img and submit it to the pipeline, and the pipeline will request the src of the picture, send the binary of the obtained picture and store it persistently.
Use process
- Data analysis (get the address of the picture)
- Submit the item storing the address to the specified pipeline class
- There is a self customized pipeline class based on ImagesPipeLine in the pipeline file
- function method get_media_request send request
- function method fifle_path custom picture name
- function method item_completed passes the item to the next pipeline class to be executed - In the configuration file
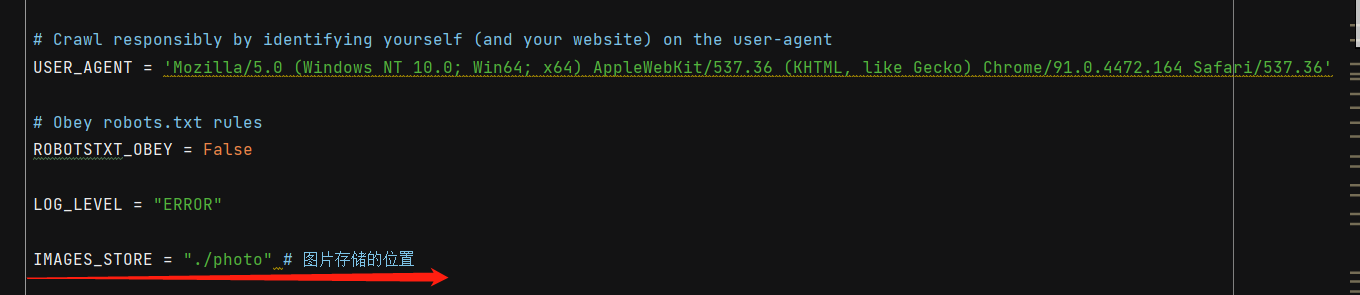
- specify the location where pictures are stored: IMAGES_STORE = "./photo"
- specify the open pipe: self customized pipe class
matters needing attention
When we parse the picture address according to xpath, we find that the address we crawled to is empty.
The main documents are as follows:
import scrapy
class PhotoSpider(scrapy.Spider):
name = 'photo'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
src_list = response.xpath('//div[@id="container"]/div/div/a/img/@src').extract()
print(src_list)
for src in src_list:
src = "https:" + src
print(src)

Why?
When we open the web page and check the code, we will find that the attributes of these picture addresses are divided into two types: SRC and src2.


So what's the difference between the two?
When we open the check code drop-down page, we will find that if the image enters the visualization area, the attribute will change from src 2 to src.
Therefore, when crawling data for xpath parsing, our attribute selection should be src2.
Master file
import scrapy
from photopro.items import PhotoproItem
import re
class PhotoSpider(scrapy.Spider):
name = 'photo'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
src_list = response.xpath('//div[@id="container"]/div/div/a/img/@src2').extract()
for src in src_list:
src = "https:" + src
print(src)

At the same time, by clicking on the details page to view the picture, we found that the crawled address is only a thumbnail, and there is a difference between the original image and the crawled address_ s.
Crawl to the address https://scpic3.chinaz.net/Files/pic/pic9/202107/bpic23822_s.jpg
HD address https://scpic3.chinaz.net/Files/pic/pic9/202107/bpic23822.jpg
🆗, Knowing these two considerations, we can write code.
code implementation
Self customized pipeline class: pipelines py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# class PhotoproPipeline:
# def process_item(self, item, spider):
# return item
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class ImgPipeline(ImagesPipeline):
# Request the image in item
def get_media_requests(self, item, info):
yield scrapy.Request(url = item["src"])
# Name of custom picture
def file_path(self, request, response = None, info = None):
url = request.url
file_name = url.split("/")[-1]
return file_name
def item_completed(self, result, item, info):
return item # The return value is passed to the next pipeline class to be executed
items.py code
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class PhotoproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
pass
Master file code
import scrapy
from photopro.items import PhotoproItem
import re
class PhotoSpider(scrapy.Spider):
name = 'photo'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
src_list = response.xpath('//div[@id="container"]/div/div/a/img/@src2').extract()
for src in src_list:
src = "https:" + src
src = re.sub("_s", "", src)
item = PhotoproItem()
item["src"] = src
# print(src)
yield item
configuration file

photopro.pipelines. Photopro. In imgpipeline pipelines. What you fill in the back must be the pipe class customized in the front.
Operation results

