File system operation
First, we study the system calls used to communicate with the kernel from the standard library. Although file operation is a standard function for all applications, the operation on the file system is limited to a few system programs, that is, the mount and umount programs used to mount and unmount the file system.
Register file system
When the file system is registered with the kernel, the file system is compiled into modules or permanently compiled into the kernel. fs/super. Register in C_ File system is used to register the file system with the kernel. A file system cannot be registered twice.
The source code used to describe the structure of the file system is as follows
struct file_system_type
{
const char *name;//Save the name of the file system
int fs_flags; //Flags used, such as indicating read-only loading, prohibiting / setudi/setgid operations, or other fine-tuning.
//The file system must be on the physical device
#define FS_REQUIRES_DEV 1
//This file system needs to use the binary data structure mount data * NFS uses this mount data
#define FS_BINARY_MOUNTDATA 2
//The system contains subtypes. The most common is FUSE. FUSE is not a real file system, so it should be distinguished by file system types, and different file systems can be realized through FUSE interface.
#define FS_HAS_SUBTYPE 4
//After each mount, there is a different user namespace, such as deypts
#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */
#define FS_USERNS_DEV_MOUNT 16 /* A userns mount does not imply MNT_NODEV */
#define FS_USERNS_VISIBLE 32 /* FS must already be visible */
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);//User calls sys_ When mount mounts a file system, it will eventually call the callback function
struct dentry *(*mount2) (struct vfsmount *, struct file_system_type *, int,
const char *, void *);
void *(*alloc_mnt_data) (void);
void (*kill_sb) (struct super_block *);//Delete the superblock in memory and use it when unmounting the file system.
struct module *owner; //Point to the module that implements the file system, usually THIS_MODULES macro
struct file_system_type * next; //Point to the next file system model in the file system linked list
struct hlist_head fs_supers; //The file system super block structure string of this file system type is in this header.
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_writers_key[SB_FREEZE_LEVELS];
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};
register_filesystem function
/**
* register_filesystem - register a new filesystem
* @fs: the file system structure
* * Adds the file system passed to the list of file systems the kernel
* is aware of for mount and other syscalls. Returns 0 on success,
* or a negative errno code on an error.
* * The &struct file_system_type that is passed is linked into the kernel
* structures and must not be freed until the file system has been
* unregistered.
*/
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
BUG_ON(strchr(fs->name, '.'));
if (fs->next)
return -EBUSY;
write_lock(&file_systems_lock);
p = find_filesystem(fs->name, strlen(fs->name));
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
Loading and unloading
The loading and unloading of the directory tree is much more complex than just registering the file system, because the latter only needs to add objects to a linked list, while the former needs to perform many operations on the internal data structure of the kernel, so it is much more complex. The loading of the file system is initiated by the mount system call, We need to clarify the tasks that must be performed to mount a new file system in an existing directory tree. You also need a data structure that describes the mount point.
- vfsmount structure: a single file system hierarchy is adopted, and the new file system can be integrated into it. mount can be used to query the loading status of each file system in the directory tree as follows:
vfsmount structure (file system hierarchy, including various file system types)
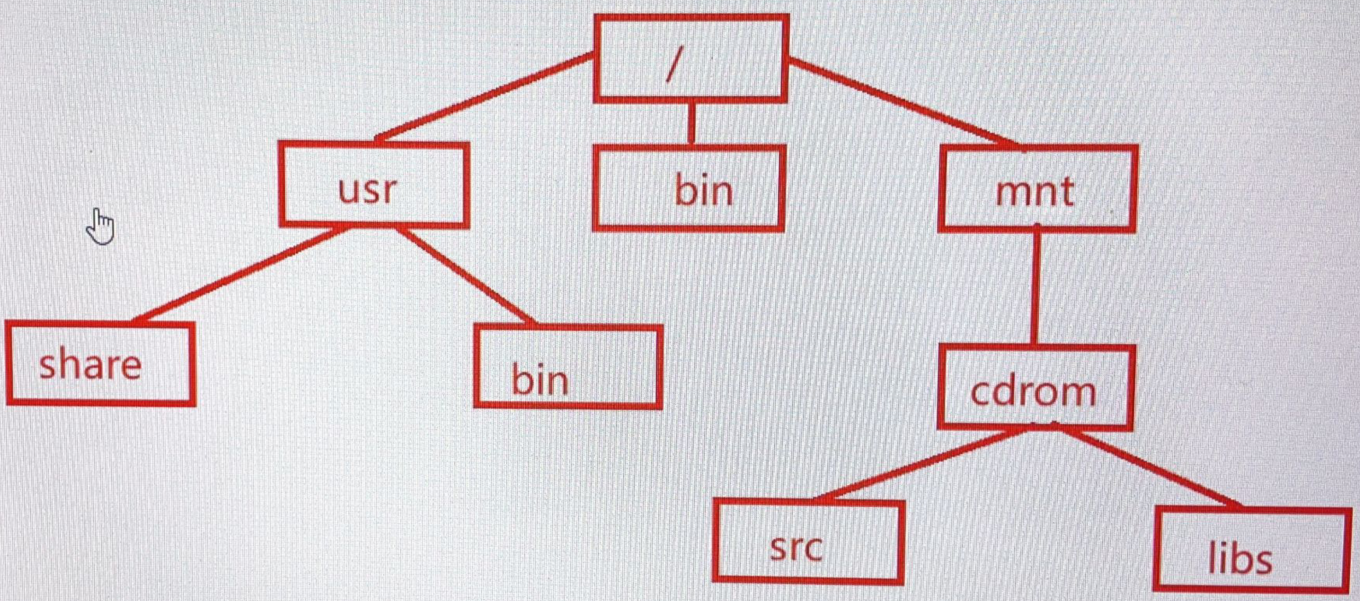
When the file system is mounted to a directory, the contents of the mount point are replaced by the contents of the file system to be mounted, but they are not lost or damaged, but they are inaccessible. As long as the mounted file system is unloaded, it can be accessed again, which is equivalent to mounting a U SB flash disk or sd card.
Vfsmount structure describes the mounting information of an independent file system. Each different mounting point corresponds to an independent vfsmount structure. All directories and files belonging to the same file system belong to the same vfsmount. The vfsmount structure corresponds to the top-level directory of the file system, that is, the mounting directory.
The analysis of mount source code is as follows:
struct mount {
struct hlist_node mnt_hash;
struct mount *mnt_parent; //The parent file system of the mount point
struct dentry *mnt_mountpoint; //dentry (directory entry) of the mount point in the parent file system
struct vfsmount mnt;
union {
struct rcu_head mnt_rcu;
struct llist_node mnt_llist;
};
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
#else
int mnt_count;
int mnt_writers;
#endif
//Sub file system linked list
struct list_head mnt_mounts; /* list of children, anchored here */
//Linked list element for MNT in parent file system_ Mount linked list
struct list_head mnt_child; /* and going through their mnt_child */
struct list_head mnt_instance; /* mount instance on sb->s_mounts */
//Device name, for example, / dev/dsk/hda1
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
//A linked list element used in a file system specific expiration linked list
struct list_head mnt_expire; /* link in fs-specific expiry list */
//Linked list element, which is used to share the loaded circular linked list
struct list_head mnt_share; /* circular list of shared mounts */
//Dependent loaded linked list
struct list_head mnt_slave_list;/* list of slave mounts */
//Linked list element, which is used for the linked list of dependent loads
struct list_head mnt_slave; /* slave list entry */
//Point to the master mount, and the slave mount is located in master - > MNT_ slave_ List linked list
struct mount *mnt_master; /* slave is on master->mnt_slave_list */
//Namespace to which it belongs
struct mnt_namespace *mnt_ns; /* containing namespace */
struct mountpoint *mnt_mp; /* where is it mounted */
struct hlist_node mnt_mp_list; /* list mounts with the same mountpoint */
struct list_head mnt_umounting; /* list entry for umount propagation */
#ifdef CONFIG_FSNOTIFY
struct hlist_head mnt_fsnotify_marks;
__u32 mnt_fsnotify_mask;
#endif
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
int mnt_expiry_mark; /* true if marked for expiry */
struct hlist_head mnt_pins;
struct fs_pin mnt_umount;
struct dentry *mnt_ex_mountpoint;
};
The parent-child relationship between file systems is represented by the linked list implemented by the two members described above, MNT_ The mounts header is the starting point of the linked list of sub file systems, while MNT_ The child field is used as the linked list element.
Each vfsmount instance in the system is identified in two ways:
1. All loaded file systems of a namespace are saved in the namespace - > List linked list;
2. MNT using vfsmount_ List members are used as linked list elements.
Super block management
When loading a new file system, vfsmont is not the only structure that needs to be created in memory. The loading operation starts with the reading of the super block.
struct super_block {
//Set the member to the starting position
struct list_head s_list; /* Keep this first */
//Search index, not kdev_t
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size Maximum file length*/
struct file_system_type *s_type;
const struct super_operations *s_op; //It points to a structure containing function pointers and provides an interface to handle the related operations of superblocks. The implementation of the operations must be implemented by the code of the underlying file system.
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_iflags; /* internal SB_I_* flags */
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security;
#endif
const struct xattr_handler **s_xattr;
const struct fscrypt_operations *s_cop;
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_mounts; /* list of mounts; _not_ for fs use */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct hlist_node s_instances;
unsigned int s_quota_types; /* Bitmask of supported quota types */
struct quota_info s_dquot; /* Diskquota specific options */
struct sb_writers s_writers;
char s_id[32]; /* Informational name */
u8 s_uuid[16]; /* UUID */
void *s_fs_info; /* Filesystem private info File system private information*/
unsigned int s_max_links;
fmode_t s_mode;
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
file_system_type
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char *s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
char __rcu *s_options;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
/* Number of inodes with nlink == 0 but still referenced */
atomic_long_t s_remove_count;
/* Being remounted read-only */
int s_readonly_remount;
/* AIO completions deferred from interrupt context */
struct workqueue_struct *s_dio_done_wq;
struct hlist_head s_pins;
/*
* Keep the lru lists last in the structure so they always sit on their
* own individual cachelines.
*/
struct list_lru s_dentry_lru ____cacheline_aligned_in_smp;
struct list_lru s_inode_lru ____cacheline_aligned_in_smp;
struct rcu_head rcu;
struct work_struct destroy_work;
struct mutex s_sync_lock; /* sync serialisation lock */
/*
* Indicates how deep in a filesystem stack this SB is
*/
int s_stack_depth;
/* s_inode_list_lock protects s_inodes */
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; /* all inodes Linked list of all inode s*/
};
*const struct super_operations s_op; // It points to a structure containing function pointers and provides an interface to handle the related operations of superblocks. The implementation of the operations must be implemented by the code of the underlying file system.
Including reading and writing inodes, deleting inodes, etc
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
//Remove inode s from memory and underlying storage media
void (*destroy_inode)(struct inode *);
//Mark the passed inode structure as "dirty", which means it has been modified
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_super) (struct super_block *);
int (*freeze_fs) (struct super_block *);
int (*thaw_super) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
int (*remount_fs2) (struct vfsmount *, struct super_block *, int *, char *);
void *(*clone_mnt_data) (void *);
void (*copy_mnt_data) (void *, void *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct dentry *);
int (*show_options2)(struct vfsmount *,struct seq_file *, struct dentry *);
int (*show_devname)(struct seq_file *, struct dentry *);
int (*show_path)(struct seq_file *, struct dentry *);
int (*show_stats)(struct seq_file *, struct dentry *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
struct dquot **(*get_dquots)(struct inode *);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
long (*nr_cached_objects)(struct super_block *,
struct shrink_control *);
long (*free_cached_objects)(struct super_block *,
struct shrink_control *);
};
mount system call
The entry point of mount system call is sys_mount function,
/*
* Flags is a 32-bit value that allows up to 31 non-fs dependent flags to
* be given to the mount() call (ie: read-only, no-dev, no-suid etc).
* * data is a (void *) that can point to any structure up to
* PAGE_SIZE-1 bytes, which can contain arbitrary fs-dependent
* information (or be NULL).
* * Pre-0.97 versions of mount() didn't have a flags word.
* When the flags word was introduced its top half was required
* to have the magic value 0xC0ED, and this remained so until 2.4.0-test9.
* Therefore, if this magic number is present, it carries no information
* and must be discarded.
*/
long do_mount(const char *dev_name, const char __user *dir_name,
const char *type_page, unsigned long flags, void *data_page)
{
struct path path;
int retval = 0;
int mnt_flags = 0;
/* Discard magic */
if ((flags & MS_MGC_MSK) == MS_MGC_VAL)
flags &= ~MS_MGC_MSK;
/* Basic sanity checks */
if (data_page)
((char *)data_page)[PAGE_SIZE - 1] = 0;
/* ... and get the mountpoint */
retval = user_path(dir_name, &path);
if (retval)
return retval;
retval = security_sb_mount(dev_name, &path,
type_page, flags, data_page);
if (!retval && !may_mount())
retval = -EPERM;
if (retval)
goto dput_out;
/* Default to relatime unless overriden */
if (!(flags & MS_NOATIME))
mnt_flags |= MNT_RELATIME;
/* Separate the per-mountpoint flags */
if (flags & MS_NOSUID)
mnt_flags |= MNT_NOSUID;
if (flags & MS_NODEV)
mnt_flags |= MNT_NODEV;
if (flags & MS_NOEXEC)
mnt_flags |= MNT_NOEXEC;
if (flags & MS_NOATIME)
mnt_flags |= MNT_NOATIME;
if (flags & MS_NODIRATIME)
mnt_flags |= MNT_NODIRATIME;
if (flags & MS_STRICTATIME)
mnt_flags &= ~(MNT_RELATIME | MNT_NOATIME);
if (flags & MS_RDONLY)
mnt_flags |= MNT_READONLY;
/* The default atime for remount is preservation */
if ((flags & MS_REMOUNT) &&
((flags & (MS_NOATIME | MS_NODIRATIME | MS_RELATIME |
MS_STRICTATIME)) == 0)) {
mnt_flags &= ~MNT_ATIME_MASK;
mnt_flags |= path.mnt->mnt_flags & MNT_ATIME_MASK;
}
flags &= ~(MS_NOSUID | MS_NOEXEC | MS_NODEV | MS_ACTIVE | MS_BORN |
MS_NOATIME | MS_NODIRATIME | MS_RELATIME| MS_KERNMOUNT |
MS_STRICTATIME);
if (flags & MS_REMOUNT) //Options for modifying mounted file systems
retval = do_remount(&path, flags & ~MS_REMOUNT, mnt_flags,
data_page);
else if (flags & MS_BIND) //Used to mount a file system through the loopback interface
retval = do_loopback(&path, dev_name, flags & MS_REC);
else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE))
retval = do_change_type(&path, flags);//Responsible for handling shared, dependent and unbound loads, he can change the load flag or establish the required data structure association between the involved vfsmount instances.
else if (flags & MS_MOVE)
retval = do_move_mount(&path, dev_name); //Used to move a mounted file system
else
//Handling normal load operations
retval = do_new_mount(&path, type_page, flags, mnt_flags,
dev_name, data_page);
dput_out:
path_put(&path);
return retval;
}
Shared subtrees
The core feature of shared subtree is to allow mount and unload events to be transmitted between different namespaces in an automatic and controllable way. This means that mounting a disc in one namespace will also trigger the mounting of the same disc in other namespaces.
In the shared subtree, each mount point has a tag called propagation type, which determines whether the mount points created or deleted in a namespace will be transferred to other namespaces.
There are four delivery types for shared subtrees:
- MS_SHARED: the mount point and its shared mount and unload events.
- MS_PRIVATE: in contrast to shared mount, events marked private will not be delivered to any peer group. The secondary flag is used by default for mount operation.
- MS_SLAVE: this transfer type is between shared and slave. A slave mount has a master (a shared peer group). Slave mount cannot transfer events to the master mount
- MS_UNBINDABLE: this mount point cannot be abbreviated.