We have already talked about the principle of Bloom filter [practical problem] - bloom filter for cache penetration (1) , we all understand that it works like this, so how do we use bloom filter in general? If you do it yourself, how do you do it?
Bloom filter
Read the definition again:
Bloom Filter was proposed by Burton Howard Bloom in 1970. It is actually composed of a long binary vector and a series of random hash mapping functions (in short, it is the feature of storing data with binary arrays).
For example, the following example: if there are three hash functions, then "Chen Liu" will be hashed by the three hash functions respectively, and the length of the bit array will be subtracted and hashed to three positions respectively.

If you still don't understand the principle, you can check my last article.
Handwritten bloom filter
Then, when we write bloom filter, we first need a bit group. There is an encapsulated bit group, BitSet, in Java.
Briefly introduce BitSet, that is, bitmap, which realizes the use of compact storage space to represent large space bit data. When using, we can directly specify the size, which is equivalent to creating a digit group of the specified size.
BitSet bits = new BitSet(size);
At the same time, BitSet provides a large number of API s. The basic operations mainly include:
- Empty data group
- Flip a bit of data
- Set the data of a bit
- Get the data of a bit
- Gets the number of bits of the current bitSet
Here are the points to consider when writing a simple bloom filter:
- The size space of the digit group needs to be specified. When others are the same, the larger the size of the digit group, the less likely the hash conflict is.
- For multiple hash functions, we need to use the hash array to store them. How to set the hash function? In order to avoid conflict, we should use multiple different prime numbers as seeds.
- Methods: two methods are mainly implemented: one is to add elements to the bloom filter, and the other is to judge whether the bloom filter contains an element.
The following is a specific implementation. It is only a simple simulation and cannot be used in the production environment. The hash function is relatively simple. It mainly uses the high and low bits of the hash value to XOR, multiply it by the seed, and then take the remainder of the bit array size:
import java.util.BitSet;
public class MyBloomFilter {
// Default size
private static final int DEFAULT_SIZE = Integer.MAX_VALUE;
// Minimum size
private static final int MIN_SIZE = 1000;
// The size is the default size
private int SIZE = DEFAULT_SIZE;
// Seed factor of hash function
private static final int[] HASH_SEEDS = new int[]{3, 5, 7, 11, 13, 17, 19, 23, 29, 31};
// Digit group, 0 / 1, representing characteristics
private BitSet bitSet = null;
// hash function
private HashFunction[] hashFunctions = new HashFunction[HASH_SEEDS.length];
// No parameter initialization
public MyBloomFilter() {
// By default size
init();
}
// Initialization with parameters
public MyBloomFilter(int size) {
// Initialization size is less than the minimum size
if (size >= MIN_SIZE) {
SIZE = size;
}
init();
}
private void init() {
// Initialization bit size
bitSet = new BitSet(SIZE);
// Initialize hash function
for (int i = 0; i < HASH_SEEDS.length; i++) {
hashFunctions[i] = new HashFunction(SIZE, HASH_SEEDS[i]);
}
}
// Adding elements is equivalent to adding the characteristics of elements to the array in place
public void add(Object value) {
for (HashFunction f : hashFunctions) {
// The calculated position of hash is true
bitSet.set(f.hash(value), true);
}
}
// Determine whether the characteristics of the element exist in the bit array
public boolean contains(Object value) {
boolean result = true;
for (HashFunction f : hashFunctions) {
result = result && bitSet.get(f.hash(value));
// As long as one of the hash functions is calculated to be false, it will return directly
if (!result) {
return result;
}
}
return result;
}
// hash function
public static class HashFunction {
// Digit group size
private int size;
// hash seed
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
// hash function
public int hash(Object value) {
if (value == null) {
return 0;
} else {
// hash value
int hash1 = value.hashCode();
// High hash value
int hash2 = hash1 >>> 16;
// Merge hash values (equivalent to combining high and low features)
int combine = hash1 ^ hash1;
// Multiply and then take the remainder
return Math.abs(combine * seed) % size;
}
}
}
public static void main(String[] args) {
Integer num1 = new Integer(12321);
Integer num2 = new Integer(12345);
MyBloomFilter myBloomFilter =new MyBloomFilter();
System.out.println(myBloomFilter.contains(num1));
System.out.println(myBloomFilter.contains(num2));
myBloomFilter.add(num1);
myBloomFilter.add(num2);
System.out.println(myBloomFilter.contains(num1));
System.out.println(myBloomFilter.contains(num2));
}
}
The operation results meet the expectations:
false false true true
However, the above method does not support the expected misjudgment rate, but can refer to the size of the positioning array.
Of course, we can also provide the amount of data and the expected error rate to initialize. The approximate initialization code is as follows:
// Initialization with parameters
public BloomFilter(int num,double rate) {
// Calculate the size of the digit group
this.size = (int) (-num * Math.log(rate) / Math.pow(Math.log(2), 2));
// Number of hsah functions
this.hashSize = (int) (this.size * Math.log(2) / num);
// Initialize bit group
this.bitSet = new BitSet(size);
}
Redis implementation
At ordinary times, we can choose to use the Redis feature in bloom filter. Why? Because Redis has instructions similar to BitSet, such as setting the value of bit group:
setbit key offset value
The above key is the key, offset is the offset, and value is 1 or 0. For example, the following is to set the 7th position of key1 to 1.
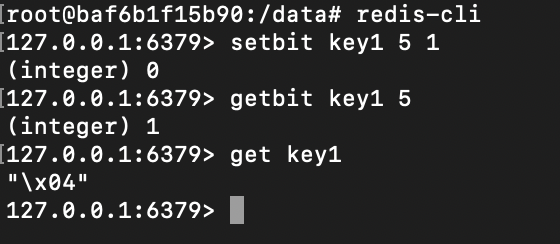
To obtain the value of a bit, you can use the following command:
gitbit key offset
With the help of redis, we can implement excellent bloom filter, but in fact we don't need to write it ourselves. Redison client has been well implemented.
Here is the usage:
To build a project using maven, you first need to import the package to POM xml:
<dependencies>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.2</version>
</dependency>
</dependencies>
The code is as follows. For the docker I use, remember to set the password when starting up. Changing the password when running will not work:
docker run -d --name redis -p 6379:6379 redis --requirepass "password"
The implementation code is as follows. First, you need to connect to redis, then create a redismission, and use the redismission to create a bloom filter. You can use it directly. (the expected quantity and expected misjudgment rate can be specified)
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class BloomFilterTest {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
config.useSingleServer().setPassword("password");
// This is equivalent to creating a redis connection
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("myBloomFilter");
//Initialization, the estimated number of elements is 100000000, and the expected error rate is 4%
bloomFilter.tryInit(100000000,0.04);
//Insert the number 10086 into the bloom filter
bloomFilter.add("12345");
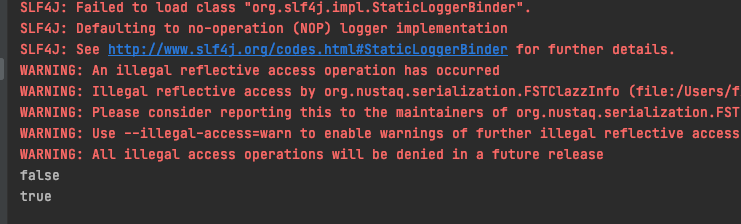
System.out.println(bloomFilter.contains("123456"));//false
System.out.println(bloomFilter.contains("12345"));//true
}
}
The operation results are as follows: it is worth noting that this is the case of a single redis. If it is a redis cluster, the method is slightly different.
Google GUAVA implementation
The guava package provided by Google also provides bloom filter and introduces pom files:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
The specific implementation calling code is as follows. You can also specify the specific storage quantity and the estimated false positive rate:
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8),1000000,0.04);
bloomFilter.put("Sam");
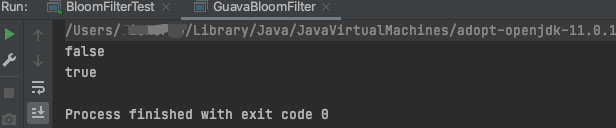
System.out.println(bloomFilter.mightContain("Jane"));
System.out.println(bloomFilter.mightContain("Sam"));
}
}
The results of the implementation are as follows, which are in line with expectations
The above three types are handwriting, redis and guava. They practice bloom filter, which is just a simple usage. In fact, you can also see the implementation in redis and guava. If you are interested, you can learn about it. I'll set up a Flag first.
About the author
Qin Huai, the official account of Qin Huai grocery store, is not in the right place for a long time. Personal writing direction: Java source code analysis, JDBC, Mybatis, Spring, redis, distributed, sword finger Offer, LeetCode, etc. I carefully write every article. I don't like the title party and fancy. I mostly write a series of articles. I can't guarantee that what I write is completely correct, but I guarantee that what I write has been practiced or searched for information. Please correct any omissions or mistakes.