preface
Why write an RPC framework? I think from the perspective of personal growth, if a programmer can clearly understand the elements of the RPC framework and master the technologies involved in the RPC framework, such as service registration and discovery, load balancing, serialization protocol, RPC communication protocol, Socket communication, asynchronous call, fuse degradation and so on, he can improve his basic quality in an all-round way. Although there are relevant source codes, it's easy to look at the source code, and writing one is the best way to really master this technology.
What is RPC
RPC (Remote Procedure Call) is a Remote Procedure Call. In short, it calls a remote service like calling a local method. At present, gRPC, Dubbo and Spring Cloud are widely used outside. I believe everyone is familiar with the concept of RPC. I won't introduce it too much here.
II. Elements of distributed RPC framework
A distributed RPC framework is inseparable from three basic elements:
- Service provider
- Service consumer
- Registry
Around the above three basic elements, we can further expand service routing, load balancing, service degradation, serialization protocol, communication protocol and so on.
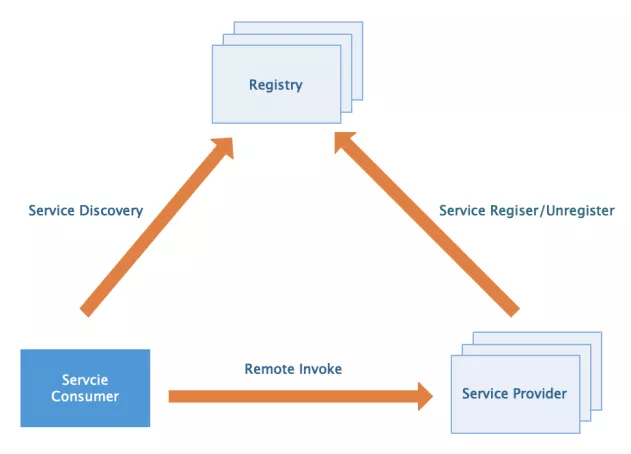
1 Registration Center
It is mainly used to complete service registration and discovery. Although service calls are directly sent by service consumers to service providers, services are deployed in clusters, and the number of service providers changes dynamically, so the service address cannot be determined in advance. Therefore, how to discover these services needs a unified registry to host.
2 service provider (RPC server)
It needs to provide an external service interface. It needs to connect to the registry when the application is started and send the service name and its service metadata to the registry. At the same time, a service offline mechanism needs to be provided. Service name and real service address mapping need to be maintained. The server also needs to start the Socket service to listen to client requests.
3 service consumer (RPC client)
The client needs to have the basic ability to obtain services from the registry. When the application starts, it needs to scan the dependent RPC services and generate proxy call objects for them. At the same time, it needs to pull the service metadata from the registry and store it in the local cache, and then initiate and monitor the changes of each service to update the cache in time. When initiating a service call, obtain the service address list from the local cache through the proxy call object, and then select a load balancing strategy to filter out a target address to initiate the call. When calling, the request data will be serialized and socket communication will be carried out using a conventional communication protocol.
III. technical selection
1 Registration Center
At present, Zookeeper, Nacos, Consul and Eureka are mature registries. Their main comparisons are as follows:
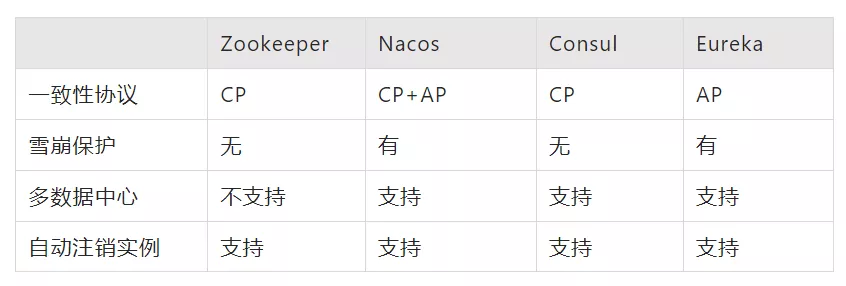
This implementation supports two registration centers, Nacos and Zookeeper, which can be switched according to the configuration.
2 IO communication framework
This implementation uses netty as the underlying communication framework. Netty is a high-performance event driven non blocking IO(NIO) framework.
3 communication protocol
In the process of TCP communication, packets are divided according to the actual situation of TCP buffer. Therefore, in business, it is considered that a complete packet may be split into multiple packets by TCP for transmission, or multiple small packets may be encapsulated into a large packet for transmission, which is the so-called TCP packet sticking and unpacking problem. Therefore, the transmitted data packets need to be encapsulated in a communication protocol.
The solutions of mainstream protocols in the industry can be summarized as follows:
- The message length is fixed. For example, the size of each message is a fixed length of 100 bytes. If it is not enough, make up with spaces.
- The special terminator at the end of the package is used for segmentation.
- The message is divided into a message header and a message body. The message header contains a field representing the total length of the message (or the length of the message body).
Obviously, both 1 and 2 have some limitations. Scheme 3 is adopted in this implementation. The specific protocol design is as follows:
+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+ | BYTE | | | | | | | ........ +--------------------------------------------+--------+-----------------+--------+--------+--------+--------+--------+--------+-----------------+ | magic | version| type | content lenth | content byte[] | | +--------+-----------------------------------------------------------------------------------------+--------------------------------------------+
- The first byte is the magic number. For example, I define it as 0X35.
- The second byte represents the protocol version number to extend the protocol and use different protocol parsers.
- The third byte is the request type. For example, 0 represents the request and 1 represents the response.
- The fourth byte represents the message length, that is, the content of this length after the four bytes is the message content.
4 serialization protocol
This implementation supports three serialization protocols. JavaSerializer, Protobuf and Hessian can be flexibly selected according to the configuration. It is recommended to select Protobuf, which has small serialized code stream and high performance, and is very suitable for RPC calls. Google's own gRPC also uses it as a communication protocol.
5 load balancing
This implementation supports two main load balancing strategies, random and polling. Both of them support weighted random and polling, which are actually four strategies.
IV. overall structure
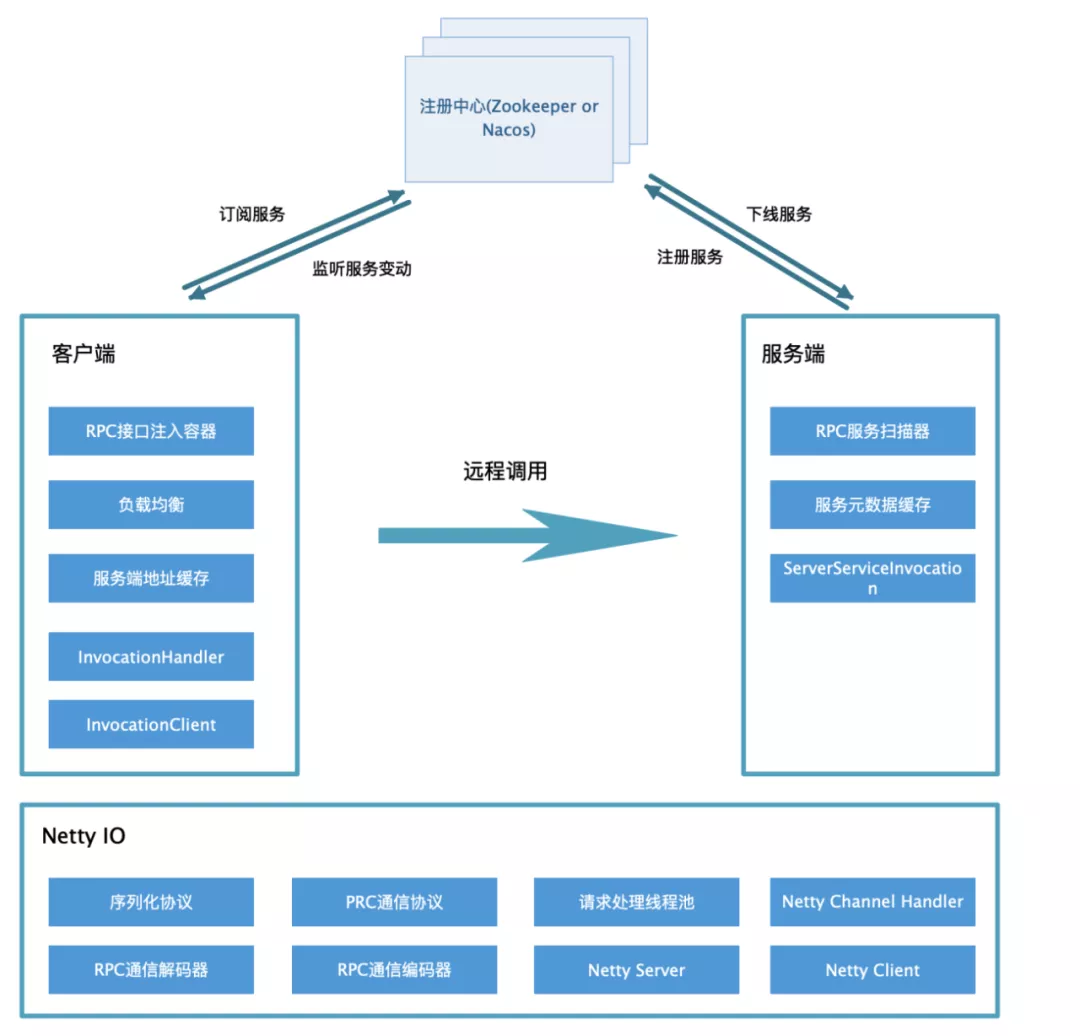
Five realization
Overall structure of the project:

1 service registration discovery
Zookeeper
Zookeeper adopts the data model of node tree, which is similar to linux file system. It is relatively simple for /, / node1, / node2.
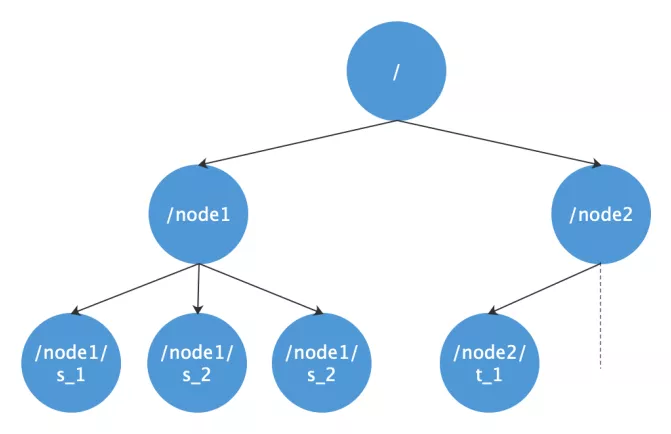
Zookeeper node type is the core principle for zookeeper to realize many functions. It is divided into three types: persistent node, temporary node and sequential node.
We create a persistent node for each service name. When registering a service, we actually create a temporary node under the persistent node in zookeeper, which stores the IP, port, serialization mode, etc. of the service.

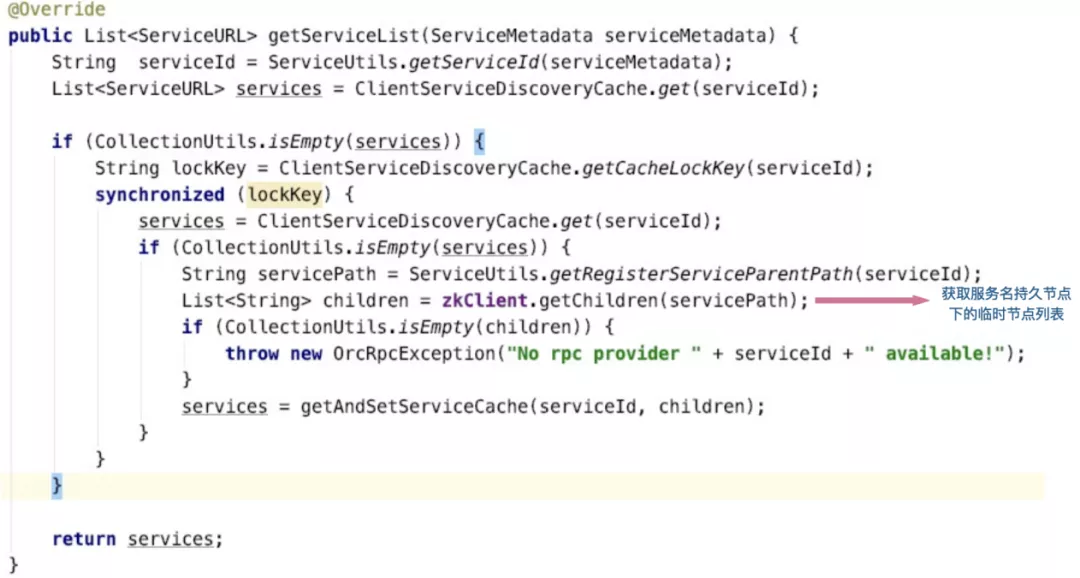
When the client obtains the service, it parses the service address data by obtaining the temporary node list under the persistent node:
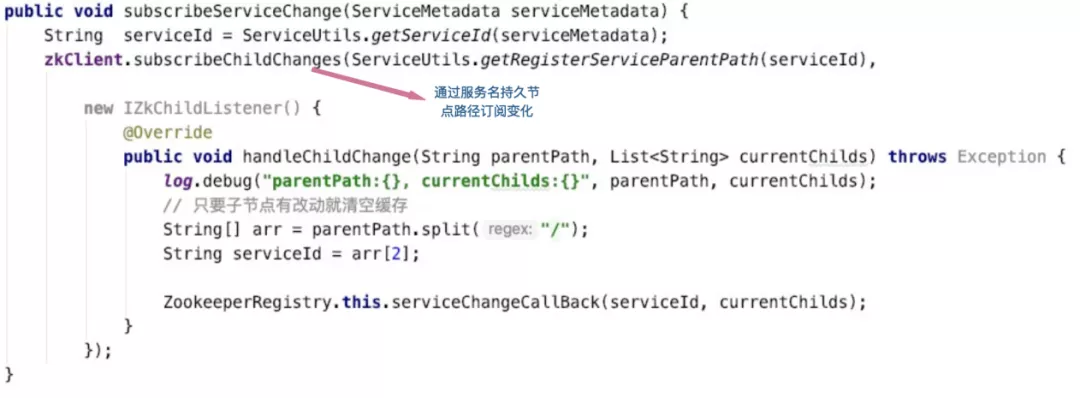
Client monitoring service changes:
Nacos
Nacos is an open-source micro Service Management Middleware of Alibaba. It is used to complete the registration, discovery and configuration center between services, which is equivalent to Eureka+Config of Spring Cloud.
Unlike Zookeeper, which needs to use the feature of creating nodes to realize registration discovery, Nacos specifically provides the function of registration discovery, so it is more convenient and simple to use. Mainly focus on the three methods provided by the NamingService interface: registerInstance, getAllInstances and subscribe; registerInstance is used to complete the service registration of the server, getAllInstances is used to complete the client service acquisition, and subscribe is used to complete the client service change monitoring. I won't introduce it here. For details, please refer to the implementation source code.
2 service provider
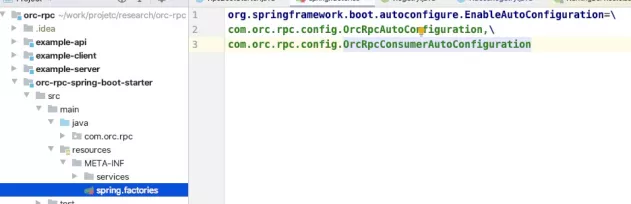
Complete the initialization of the registry and RPC boot class (RpcBootStarter) in the autoconfiguration class orcrpcoautoconfiguration:
The startup process of the server is as follows:
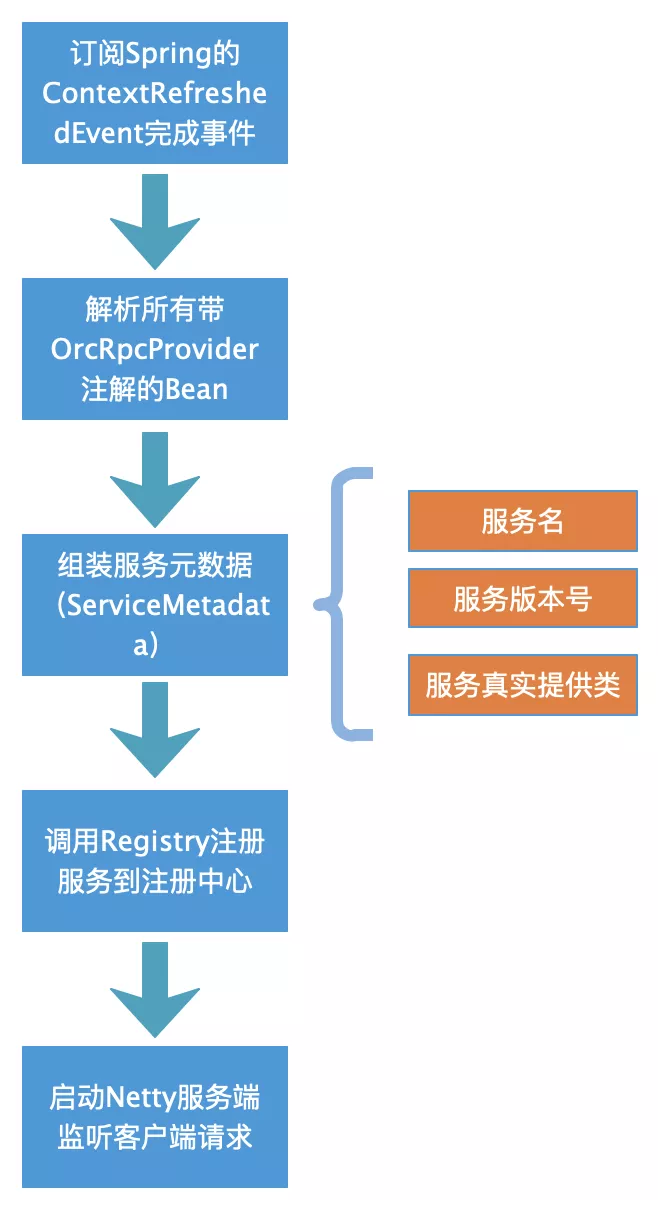
RPC startup (RpcBootStarter):

When listening to Spring container initialization events above, please note that Spring contains multiple containers, such as web containers and core containers, which also have parent-child relationships. In order to avoid repeated registration, only the top-level containers can be processed.
3. Service consumer
The service consumer needs to create proxy objects for the dependent services before the application is started. There are many methods, including two common ones:
- First, it is triggered when the Spring Context initialization completion event of the application is completed. Scan all beans, obtain the field with OrcRpcConsumer annotation in the Bean, and then create a field type proxy object. After creation, set the proxy object to this field. Subsequently, a server-side connection is created through the proxy object and a call is initiated.
- Second, through spring's beanfactoryprocessor, it can process the bean definition (configuration metadata); Spring IOC will run beanfactoryprocessor to read beandefinitions before the container instantiates any other beans. You can modify these beandefinitions or add some beandefinitions.
This implementation also adopts the second method, and the processing flow is as follows:
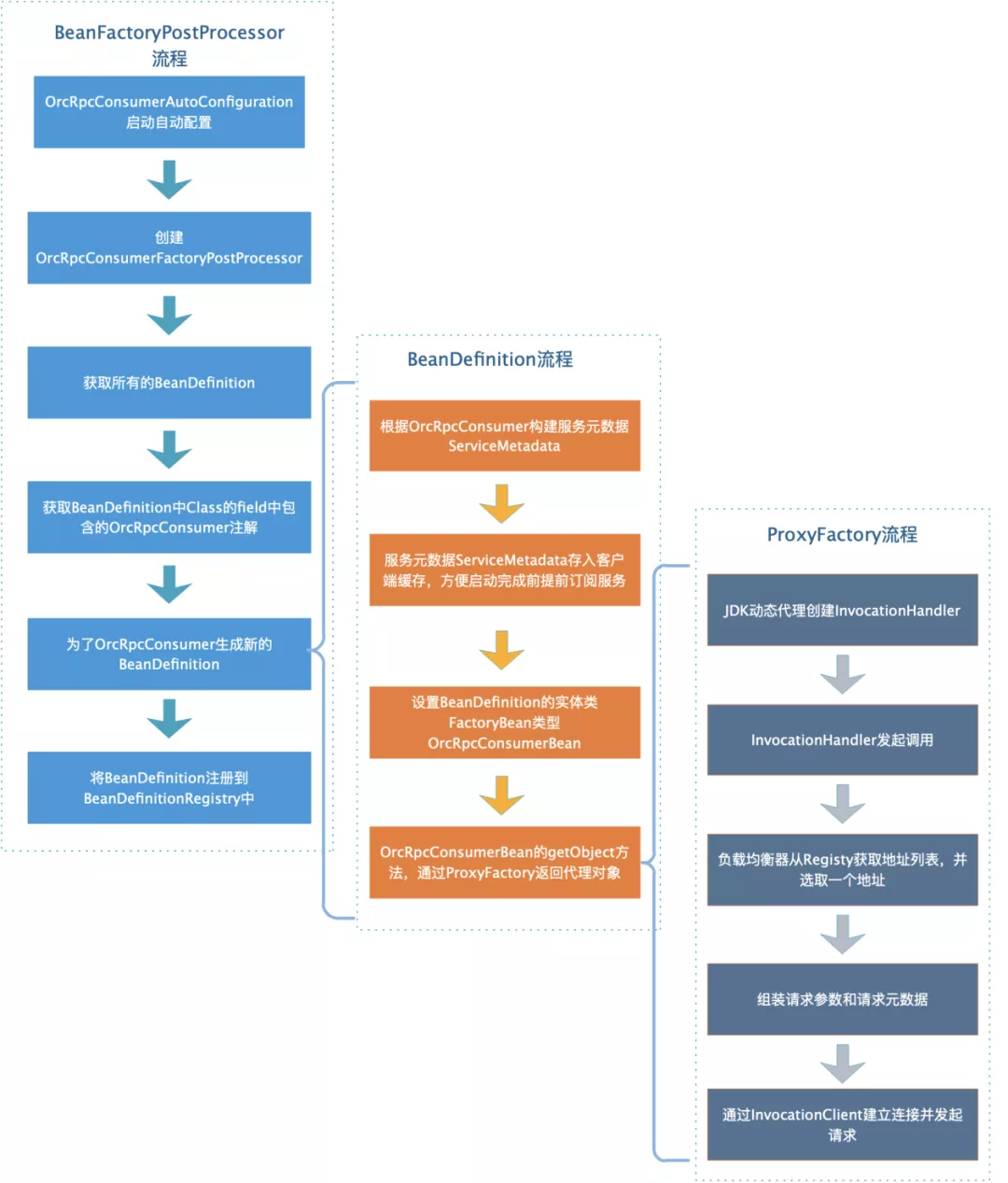
The main implementation of beanfactoryprocessor:
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)
throws BeansException {
this.beanFactory = beanFactory;
postProcessRpcConsumerBeanFactory(beanFactory, (BeanDefinitionRegistry)beanFactory);
}
private void postProcessRpcConsumerBeanFactory(ConfigurableListableBeanFactory beanFactory, BeanDefinitionRegistry beanDefinitionRegistry) {
String[] beanDefinitionNames = beanFactory.getBeanDefinitionNames();
int len = beanDefinitionNames.length;
for (int i = 0; i < len; i++) {
String beanDefinitionName = beanDefinitionNames[i];
BeanDefinition beanDefinition = beanFactory.getBeanDefinition(beanDefinitionName);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null) {
Class<?> clazz = ClassUtils.resolveClassName(beanClassName, classLoader);
ReflectionUtils.doWithFields(clazz, new FieldCallback() {
@Override
public void doWith(Field field) throws IllegalArgumentException, IllegalAccessException {
parseField(field);
}
});
}
}
Iterator<Entry<String, BeanDefinition>> it = beanDefinitions.entrySet().iterator();
while (it.hasNext()) {
Entry<String, BeanDefinition> entry = it.next();
if (context.containsBean(entry.getKey())) {
throw new IllegalArgumentException("Spring context already has a bean named " + entry.getKey());
}
beanDefinitionRegistry.registerBeanDefinition(entry.getKey(), entry.getValue());
log.info("register OrcRpcConsumerBean definition: {}", entry.getKey());
}
}
private void parseField(Field field) {
// Get all OrcRpcConsumer annotations
OrcRpcConsumer orcRpcConsumer = field.getAnnotation(OrcRpcConsumer.class);
if (orcRpcConsumer != null) {
// Use the type of field and OrcRpcConsumer annotation to generate BeanDefinition
OrcRpcConsumerBeanDefinitionBuilder beanDefinitionBuilder = new OrcRpcConsumerBeanDefinitionBuilder(field.getType(), orcRpcConsumer);
BeanDefinition beanDefinition = beanDefinitionBuilder.build();
beanDefinitions.put(field.getName(), beanDefinition);
}
}The main implementation of ProxyFactory:
public class JdkProxyFactory implements ProxyFactory{
@Override
public Object getProxy(ServiceMetadata serviceMetadata) {
return Proxy
.newProxyInstance(serviceMetadata.getClazz().getClassLoader(), new Class[] {serviceMetadata.getClazz()},
new ClientInvocationHandler(serviceMetadata));
}
private class ClientInvocationHandler implements InvocationHandler {
private ServiceMetadata serviceMetadata;
public ClientInvocationHandler(ServiceMetadata serviceMetadata) {
this.serviceMetadata = serviceMetadata;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String serviceId = ServiceUtils.getServiceId(serviceMetadata);
// Select a service provider address through the load balancer
ServiceURL service = InvocationServiceSelector.select(serviceMetadata);
OrcRpcRequest request = new OrcRpcRequest();
request.setMethod(method.getName());
request.setParameterTypes(method.getParameterTypes());
request.setParameters(args);
request.setRequestId(UUID.randomUUID().toString());
request.setServiceId(serviceId);
OrcRpcResponse response = InvocationClientContainer.getInvocationClient(service.getServerNet()).invoke(request, service);
if (response.getStatus() == RpcStatusEnum.SUCCESS) {
return response.getData();
} else if (response.getException() != null) {
throw new OrcRpcException(response.getException().getMessage());
} else {
throw new OrcRpcException(response.getStatus().name());
}
}
}
}This implementation only uses JDK dynamic proxy, or cglib or Javassist can be used to achieve better performance, which is in JdkProxyFactory.
4 IO module
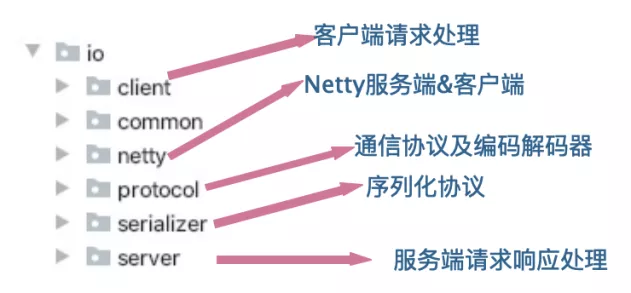
The UML diagram is as follows:
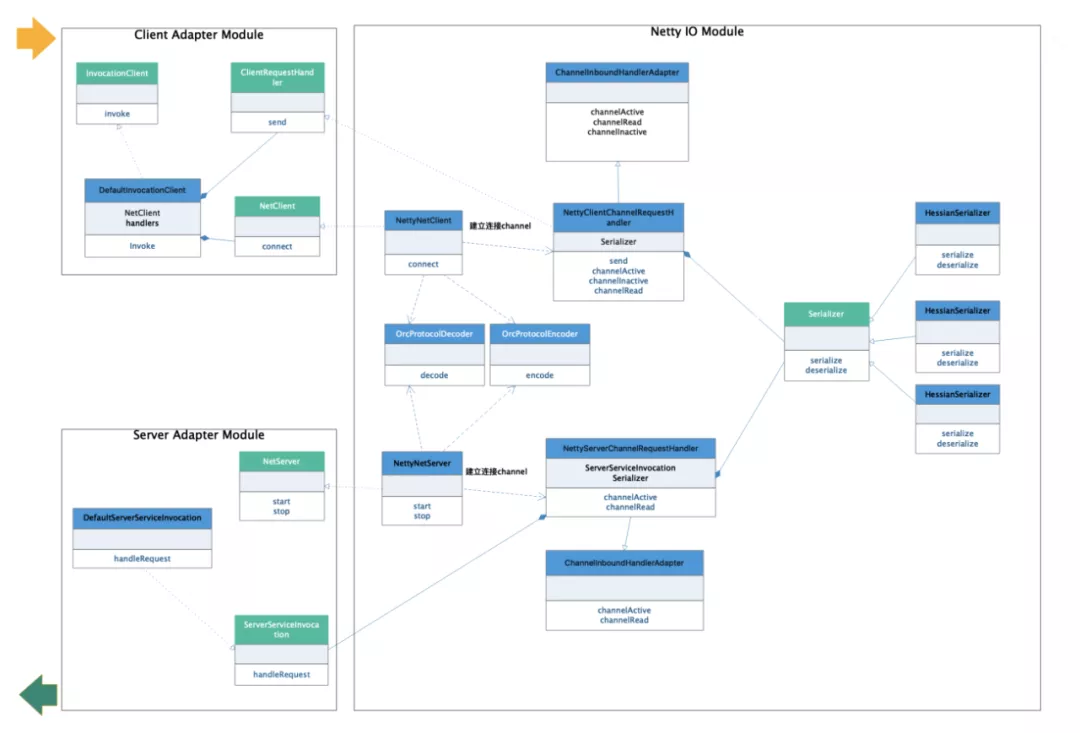
The structure is relatively clear, which is divided into three modules: client call adaptation module, server request response adaptation module and Netty IO service module.
Client call adaptation module
This module is relatively simple. It is mainly to establish a service termination for the client call and store the connection in the cache to avoid repeated connection with the service call in the future. The call is initiated after the connection is established successfully. The following is the implementation of DefaultInvocationClient:

Server request response adaptation module
The service request response module is also relatively simple. It obtains the service metadata from the cache according to the service name in the request, then obtains the called method and parameter type information from the request, and reflects the call method information. Then get the bean from the spring context for reflection call.
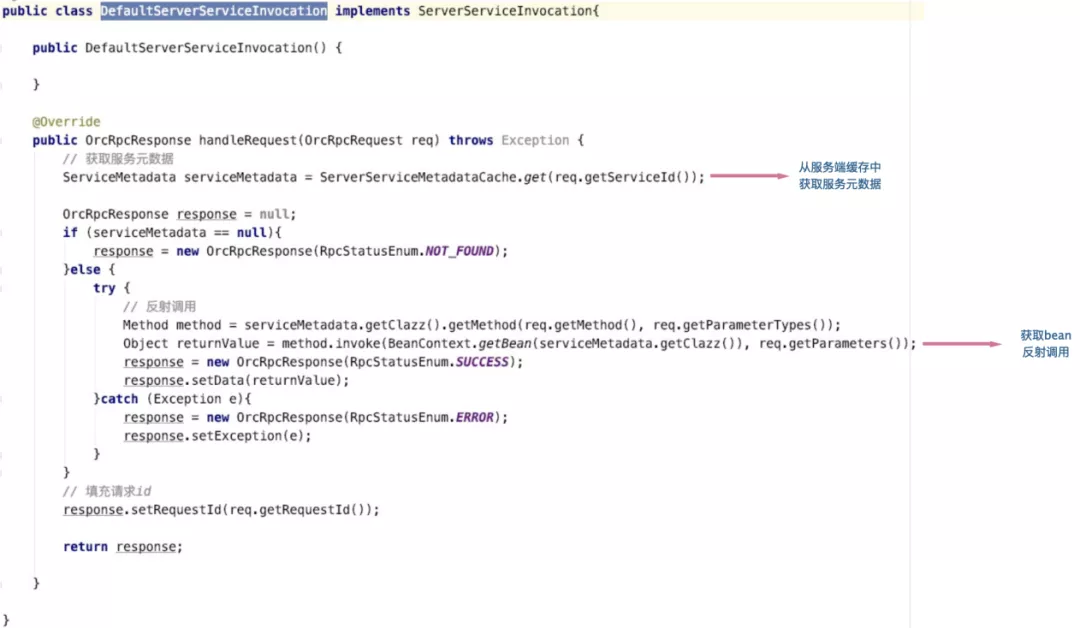
Netty IO service module
Netty IO service module is the core, which is slightly more complex. The main processing flow of client and server is as follows:
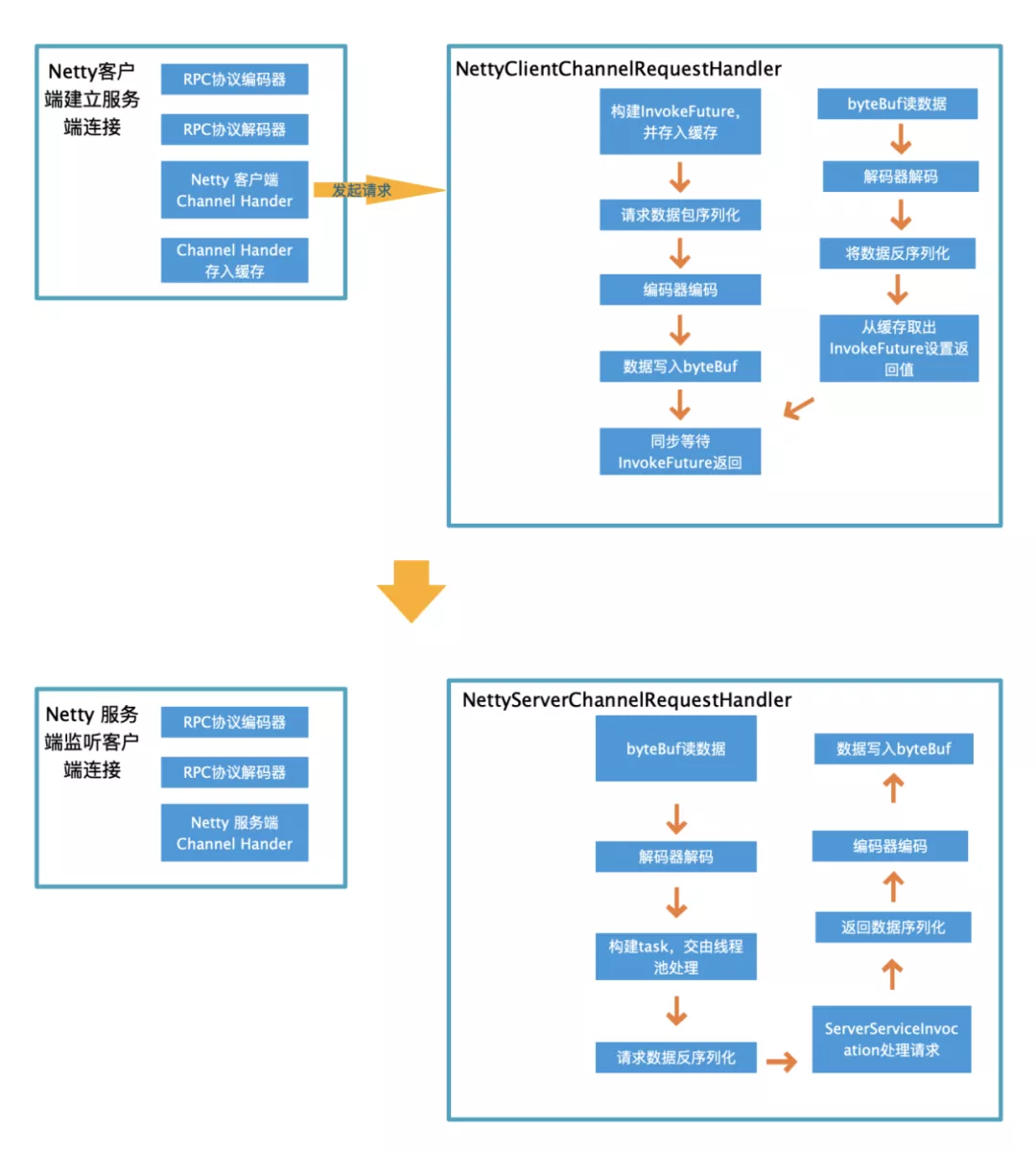
Among them, the focus is on the implementation of these four classes: NettyNetClient, NettyNetServer, NettyClientChannelRequestHandler and NettyServerChannelRequestHandler. The above UML diagram and the following flowchart basically clarify their relationship and the processing flow of a request, which will not be expanded here.
Now let's focus on the codec.
In the technical selection section, the adopted communication protocol is mentioned and the private RPC Protocol is defined:
+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+ | BYTE | | | | | | | ........ +--------------------------------------------+--------+-----------------+--------+--------+--------+--------+--------+--------+-----------------+ | magic | version| type | content lenth | content byte[] | | +--------+-----------------------------------------------------------------------------------------+--------------------------------------------+
- The first byte is the magic number, defined as 0X35.
- The second byte represents the protocol version number.
- The third byte is the request type, 0 represents the request and 1 represents the response.
- The fourth byte represents the message length, that is, the content of this length after the four bytes is the message content.
The implementation of encoder is as follows:
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, ProtocolMsg protocolMsg, ByteBuf byteBuf)
throws Exception {
// Write protocol header
byteBuf.writeByte(ProtocolConstant.MAGIC);
// Write version
byteBuf.writeByte(ProtocolConstant.DEFAULT_VERSION);
// Write request type
byteBuf.writeByte(protocolMsg.getMsgType());
// Write message length
byteBuf.writeInt(protocolMsg.getContent().length);
// Write message content
byteBuf.writeBytes(protocolMsg.getContent());
}The implementation of the decoder is as follows:

Six tests
In the case of my MacBook Pro 13 inch, 4-core I5, 16g memory, using the Nacos registry, starting a server and a client, and using the polling load balancing strategy, I use Apache ab to test.
When 8 threads are enabled to initiate 10000 requests, all requests can be completed in 18 seconds. qps550:
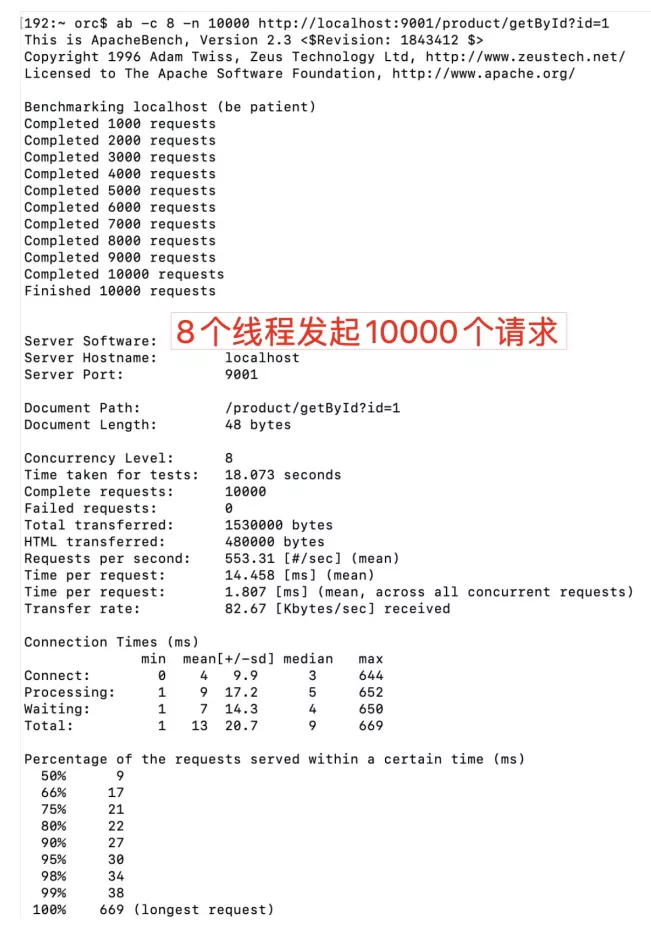
When 100 threads are enabled to initiate 10000 requests, all requests can be completed in 13.8 seconds. qps724:

VII. Summary
In the process of implementing this RPC framework, I also relearned a lot of knowledge, such as communication protocol, IO framework, etc. I also learned the hottest gRPC horizontally, so I saw a lot of relevant source code and gained a lot. In the future, I will continue to maintain and upgrade the framework, such as introducing fuse degradation and other mechanisms to achieve continuous learning and progress.