In this article, we mainly share a practical case: unknown bytecode instruction.
Next, we will take a look at the application of bytecode by introducing some common features in the Java language. Because there are many Java features, here we will only introduce some features we often encounter. javap is a sharp weapon in your hand. Complex concepts can be shown here, and you can be deeply impressed by it.
There are many codes in this article, and relevant code examples can be found in the warehouse. It is recommended to do it in practice.
exception handling
In the last lesson, you may have noticed that the byte code generated by synchronized actually contains two monitorexit instructions to ensure that all abnormal conditions can exit.
This involves the exception handling mechanism of Java bytecode, as shown in the figure below.
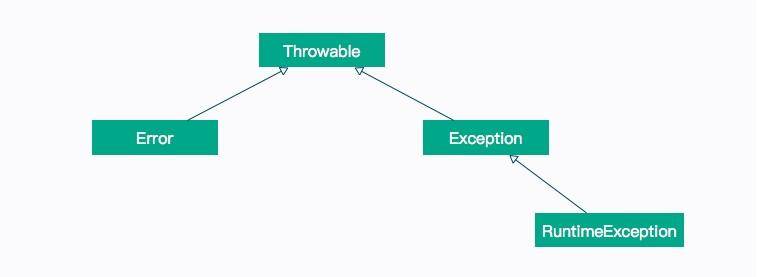
If you are familiar with the Java language, you will not be unfamiliar with the above exception inheritance system. Among them, Error and RuntimeException are unchecked exceptions, that is, exceptions that do not need to be caught by catch statements; Other exceptions need to be handled manually by the programmer.
Exception table
When an exception occurs, Java can construct the exception stack through the Java execution stack. Recall the stack frames in the last article. To get this exception stack, you only need to traverse them.
But this operation is much more expensive than conventional operation. Java's Log framework usually prints all error information into the Log, which will significantly affect the performance in case of many exceptions.
Let's look at the bytecode generated in the last article:
void doLock(); descriptor: ()V flags: Code: stack=2, locals=3, args_size=1 0: aload_0 1: getfield #3 // Field lock:Ljava/lang/Object; 4: dup 5: astore_1 6: monitorenter 7: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream; 10: ldc #8 // String lock 12: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 15: aload_1 16: monitorexit 17: goto 25 20: astore_2 21: aload_1 22: monitorexit 23: aload_2 24: athrow 25: return Exception table: from to target type 7 17 20 any 20 23 20 any
It can be seen that the compiled bytecode has an Exception table called Exception table. Each row of data in it is an exception handler:
- from - specifies the start position of the bytecode index
- to - specifies the end position of the bytecode index
- target: the starting position of exception handling
- Type = exception type
In other words, as long as an exception occurs between from and to, it will jump to the position specified by the target.
finally
Usually, when we read some files, we will close the stream in the finally code block to avoid memory overflow. For this scenario, let's analyze the exception table of the following code.
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class A {
public void read() {
InputStream in = null;
try {
in = new FileInputStream("A.java");
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (null != in) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
The above code catches a FileNotFoundException exception, and then catches an IOException in finally. When we analyzed the bytecode, we found an interesting place: IOException appeared three times.
Exception table: from to target type 17 21 24 Class java/io/IOException 2 12 32 Class java/io/FileNotFoundException 42 46 49 Class java/io/IOException 2 12 57 any 32 37 57 any 63 67 70 Class java/io/IOException
The Java compiler uses a silly way to organize finally bytecode. It copies a copy of finally code on the normal execution path of try and catch, and appends it to the back of the normal execution logic; At the same time, copy another copy to the exit of other exception execution logic.
This is also the reason why the following methods do not report errors. The answer can be found in the bytecode.
//B.java
public int read() {
try {
int a = 1 / 0;
return a;
} finally {
return 1;
}
}
The following is the bytecode of the above program. You can see that after the exception, you will directly jump to serial number 8.
stack=2, locals=4, args_size=1 0: iconst_1 1: iconst_0 2: idiv 3: istore_1 4: iload_1 5: istore_2 6: iconst_1 7: ireturn 8: astore_3 9: iconst_1 10: ireturn Exception table: from to target type 0 6 8 any
Packing and unpacking
At the beginning of learning java language, you may be confused by automatic packing and unpacking. There are eight basic types in Java, but in view of the object-oriented characteristics of Java, they also have eight corresponding wrapper types, such as int and Integer. The value of wrapper type can be null. Many times, they can assign values to each other.
Let's use the following code to observe from the bytecode level:
public class Box {
public Integer cal() {
Integer a = 1000;
int b = a * 10;
return b;
}
}
The above is a simple code. First, use the packing type to construct a number with a value of 1000, and then multiply it by 10 to return. However, the intermediate calculation process uses the common type int.
public java.lang.Integer read(); descriptor: ()Ljava/lang/Integer; flags: ACC_PUBLIC Code: stack=2, locals=3, args_size=1 0: sipush 1000 3: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer; 6: astore_1 7: aload_1 8: invokevirtual #3 // Method java/lang/Integer.intValue:()I 11: bipush 10 13: imul 14: istore_2 15: iload_2 16: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer; 19: areturn
By observing the bytecode, we find that the assignment operation uses integer Valueof method, integer is called during multiplication Intvalue method to get the value of the basic type. When the method returns, integer is used again The results are packaged by valueof method.
This is the underlying implementation of automatic packing and unpacking in Java.
But there is a trap problem at the Java level. Let's continue to track integer Valueof method.
@HotSpotIntrinsicCandidate
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
This IntegerCache caches Integer objects between low and high. You can modify the upper limit through - XX:AutoBoxCacheMax.
The following is a classic interview question. Please consider what results will be output after running the code?
public class BoxCacheError{
public static void main(String[] args) {
Integer n1 = 123;
Integer n2 = 123;
Integer n3 = 128;
Integer n4 = 128;
System.out.println(n1 == n2);
System.out.println(n3 == n4);
}
When I use java BoxCacheError to execute, it is true and false; When I add the parameter java -XX:AutoBoxCacheMax=256 BoxCacheError, the result is true, true, which is why.
Array access
We all know that when accessing the length of an array, we use its properties directly Length can be obtained, but the definition of array cannot be found in Java.
For example, the type int [] can be obtained through getClass (getClass is the method in the Object class). Its specific type is [I].
In fact, array is a built-in Object type of the JVM, and this Object is also an inherited Object class.
Let's use the following code to observe the generation and access of arrays.
public class ArrayDemo {
int getValue() {
int[] arr = new int[]{
1111, 2222, 3333, 4444
};
return arr[2];
}
int getLength(int[] arr) {
return arr.length;
}
}
First look at the bytecode of the getValue method.
int getValue(); descriptor: ()I flags: Code: stack=4, locals=2, args_size=1 0: iconst_4 1: newarray int 3: dup 4: iconst_0 5: sipush 1111 8: iastorae 9: dup 10: iconst_1 11: sipush 2222 14: iastore 15: dup 16: iconst_2 17: sipush 3333 20: iastore 21: dup 22: iconst_3 23: sipush 4444 26: iastore 27: astore_1 28: aload_1 29: iconst_2 30: iaload 31: ireturn
You can see that the code for creating a new array is compiled into the newarray instruction. The initial contents in the array are sequentially compiled into a series of instructions and put into:
- sipush pushes a short integer constant value to the top of the stack;
- iastore stores the int value at the top of the stack into the specified index position of the specified array.
In order to support multiple types, from operand stack to array, there are more instructions: bastore, castore, sastore, iastore, lastore, fastore, dastore, aastore.
The access of array elements is realized through lines 28 to 30:
- aload_1 push the local variable of the second reference type to the top of the stack. Here is the generated array;
- iconst_2 push int type 2 to the top of the stack;
- iaload pushes the value of the specified index of the int array to the top of the stack.
It is worth noting that during the running of this code, it is possible to generate
ArrayIndexOutOfBoundsException, but since it is a non caught exception, we do not need to provide an exception handler for this exception.
Let's take another look at the bytecode of getLength. The bytecode is as follows:
int getLength(int[]); descriptor: ([I)I flags: Code: stack=1, locals=2, args_size=2 0: aload_1 1: arraylength 2: ireturn
It can be seen that obtaining the length of the array is completed by the bytecode instruction arraylength.
foreach
Whether it is a Java array or a List, you can use the foreach statement to traverse. The typical code is as follows:
import java.util.List;
public class ForDemo {
void loop(int[] arr) {
for (int i : arr) {
System.out.println(i);
}
}
void loop(List<Integer> arr) {
for (int i : arr) {
System.out.println(i);
}
}
Although their expressions are consistent at the language level, the actual implementation methods are not the same. Let's first look at the bytecode of traversing the array:
void loop(int[]); descriptor: ([I)V flags: Code: stack=2, locals=6, args_size=2 0: aload_1 1: astore_2 2: aload_2 3: arraylength 4: istore_3 5: iconst_0 6: istore 4 8: iload 4 10: iload_3 11: if_icmpge 34 14: aload_2 15: iload 4 17: iaload 18: istore 5 20: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; 23: iload 5 25: invokevirtual #3 // Method java/io/PrintStream.println:(I)V 28: iinc 4, 1 31: goto 8 34: return
It is easy to see that it interprets the code into the traditional variable mode, that is, the form of for (int i; I < length; I + +).
The bytecode of List is as follows:
void loop(java.util.List<java.lang.Integer>); Code: 0: aload_1 1: invokeinterface #4, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator; 6: astore_2- 7: aload_2 8: invokeinterface #5, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z 13: ifeq 39 16: aload_2 17: invokeinterface #6, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object; 22: checkcast #7 // class java/lang/Integer 25: invokevirtual #8 // Method java/lang/Integer.intValue:()I 28: istore_3 29: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; 32: iload_3 33: invokevirtual #3 // Method java/io/PrintStream.println:(I)V 36: goto 7 39: return
It actually iterates and traverses the list object. In the loop, iterator The next () method.
Using JD GUI and other decompilation tools, you can see the actual generated code:
void loop(List<Integer> paramList) {
for (Iterator<Integer> iterator = paramList.iterator(); iterator.hasNext(); ) {
int i = ((Integer)iterator.next()).intValue();
System.out.println(i);
}
}
annotation
Annotations have been widely used in Java, and the Spring framework has come back to life due to the existence of annotations. The function of annotation in development is to make data constraints and standard definitions, which can be understood as the standard of code, and help us write convenient, fast and concise code.
So where is the annotation information stored? Let's take a look at one of these situations using two Java files.
MyAnnotation.java
MyAnnotation.java
public @interface MyAnnotation {
}
AnnotationDemo
@MyAnnotation
public class AnnotationDemo {
@MyAnnotation
public void test(@MyAnnotation int a){
}
}
Let's take a look at bytecode information.
{
public AnnotationDemo();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 2: 0
public void test(int);
descriptor: (I)V
flags: ACC_PUBLIC
Code:
stack=0, locals=2, args_size=2
0: return
LineNumberTable:
line 6: 0
RuntimeInvisibleAnnotations:
0: #11()
RuntimeInvisibleParameterAnnotations:
0:
0: #11()
}
SourceFile: "AnnotationDemo.java"
RuntimeInvisibleAnnotations:
0: #11()
You can see that both class annotations and method annotations are made by a
The RuntimeInvisibleAnnotations structure is used to store parameters, and the storage of parameters is guaranteed by {RuntimeInvisibleParameterAnotations.
Summary
In this article, we briefly introduce some common problems in our work, and analyze its principle from the bytecode level, including exception handling and the execution order of finally blocks; And the underlying implementation of hidden boxing and unpacking and foreach syntax sugar.
Because there are many features of Java, we won't list them one by one here, but we can use this simple way to have a look. It can be considered that this article belongs to throwing bricks and attracting jade, and gives a learning idea.
In addition, you can also think about the performance and complexity. It can be noted that many redundant bytecode instructions will be generated in the hidden boxing and unpacking operation. So, will this thing consume performance? The answer is yes, but don't worry about it.
last
In a word, the interviewer asked around and asked so many Redis knowledge points. The review was not in place and the mastery of knowledge points was not proficient enough, so the interview was blocked. Share these Redis interview knowledge analysis and some learning notes I sorted out for your reference
Note to those who need these learning notes: You can get it for free by poking here
More study notes and interview materials are also shared as follows (all available for free):
Execution sequence of y block; And the underlying implementation of hidden boxing and unpacking and foreach syntax sugar.
Because there are many features of Java, we won't list them one by one here, but we can use this simple way to have a look. It can be considered that this article belongs to throwing bricks and attracting jade, and gives a learning idea.
In addition, you can also think about the performance and complexity. It can be noted that many redundant bytecode instructions will be generated in the hidden boxing and unpacking operation. So, will this thing consume performance? The answer is yes, but don't worry about it.
last
In a word, the interviewer asked around and asked so many Redis knowledge points. The review was not in place and the mastery of knowledge points was not proficient enough, so the interview was blocked. Share these Redis interview knowledge analysis and some learning notes I sorted out for your reference
Note to those who need these learning notes: You can get it for free by poking here
More study notes and interview materials are also shared as follows (all available for free):
[external chain picture transferring... (img-exZbl8IY-1623641084579)]