Hash table, also known as hash table, can also be translated into hash table directly. Hash table is a data structure that can be accessed directly according to key - value. It is based on the array and speeds up the search speed by mapping keywords to a subscript of the array. However, it is different from the data structures such as array, linked list and tree. Finding a keyword in these data structures usually needs to traverse the whole data structure, that is, the time level of O(N), but for the hash table, it is only the time level of O(1).
Note that an important problem here is how to convert keywords into subscripts of arrays. This conversion function is called hash function (also known as hash function), and the conversion process is called hashing.
1. Introduction of hash function
We have all used dictionaries. The advantage of dictionaries is that we can quickly locate the words we want to find through the previous directory. If we want to write every word in an English dictionary, from a to zyzzyva (the last word in the Oxford Dictionary), into the computer memory for fast reading and writing, hash table is a good choice.
Here we narrow down the scope. For example, we want to store 5000 English words in memory. We may think that each word will occupy an array unit, so the size of the array is 5000. At the same time, we can use the array subscript to access words. This idea is perfect, but how can the array subscript be related to words?
First, we need to establish the relationship between words and numbers (array subscripts):
We know that ASCII is a kind of code, in which a stands for 97, b stands for 98, and so on. Up to 122 stands for z, and each word is composed of these 26 letters. We can design a set of code similar to ASCII without ASCII coding. For example, a stands for 1, b stands for 2, and so on, and z stands for 26, so we know the representation method.
Next, how to combine the numbers of single letters into numbers representing the whole word?
① add up the numbers
First, the first simple method is to add the numbers represented by each letter of the word, and the sum is the subscript of the array.
For example, convert the word cats into numbers:
cats = 3 + 1 + 20 + 19 = 43
Then the subscript of the word cats stored in the array is 43. All English words can be converted into array subscripts in this way. But is this really feasible?
Suppose we agree that a word can have at most 10 letters, then the last word in the dictionary is zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
zzzzzzzzzz = 26*10 = 260
Then we can get the range of word coding from 1 to 260. Obviously, this range is not enough to store 5000 words, so there must be multiple words stored in one location, and the average data item of each array needs to store 192 words (5000 divided by 260).
How can we solve the above problems?
The first method: consider that each array item contains a sub array or a sub linked list. This method is really fast to store data items, but it is still very slow if we want to find one of 192 words.
The second method: why should so many words occupy the same data item? In other words, we didn't divide the words enough, and the array can represent too few elements. We need to expand the subscript of the array to store only one word in each position.
For the second method above, the problem arises. How can we extend the subscript of the array?
②. Power multiplication
We divide the numbers represented by words into sequences, multiply these digits with the appropriate power of 27 (because there are 26 possible characters and spaces, a total of 27), and then add the products to get the unique number of each word.
For example, convert the word cats into numbers:
cats = 3*273 + 1*272 + 20*271 + 19*270 = 59049 + 729 + 540 + 19 = 60337
This process will create a unique number for each word, but note that we only calculate the word composed of 4 letters here. If the word is very long, such as the longest 10 letter word zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz, It's impossible to allocate so much space for an array.
So the problem with this scheme is that although each word is assigned a unique subscript, only a small part of the words are stored, and a large part of them are empty. So now we need a method to compress the huge integer range obtained in the digital power multiplication system to an acceptable array range.
For English dictionaries, assuming that there are only 5000 words, we choose an array space with a capacity of 10000 to store them (we will explain why we need double the space later). Then we need to compress the range from 0 to more than 700 million to the range from 0 to 10000.
The first method: take the remainder to get the remainder after a number is divided by another integer. First, let's assume that we want to compress the number from 0-199 (represented by largeNumber) into the number from 0-9 (represented by smallNumber), which has 10 numbers, so the value of the variable smallRange is 10. The conversion expression is:
smallNumber = largeNumber % smallRange
When a number is divided by 10, the remainder must be between 0-9. In this way, we compress the number from 0-199 to 0-9, and the compression ratio is 20:1.
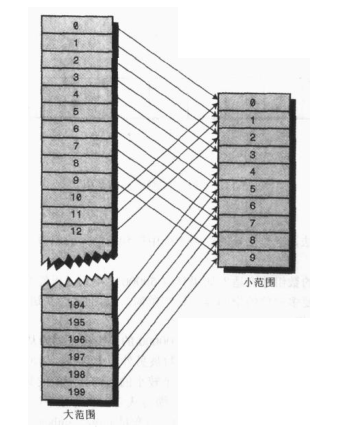
We can also use a similar method to compress the number representing the unique word into the subscript of the array:
arrayIndex = largerNumber % smallRange
This is the hash function. It hashes a large range of numbers into a small range of numbers corresponding to the subscript of the array. After using the hash function to insert data into the array, the array is the hash table.
2. Conflict
If the huge number range is compressed to a smaller number range, there will be several different words hashed to the same array subscript, that is, there will be a conflict.
The conflict may lead to the failure of the hashing scheme. As we said earlier, the size of the specified array range is twice that of the actual stored data, so half of the space may be empty. Therefore, when the conflict occurs, one method is to find a vacancy in the array through the systematic method and fill in the word, instead of using the hash function to get the subscript of the array, This method is called open address method. For example, the hash result of adding the word cats is 5421, but its location has been occupied by the word parsnip, so we will consider storing the word cats in a location 5422 after parsnip.
Another method, as we mentioned earlier, is to create a sub linked list or sub array for each data item of the array. Then words are not stored directly in the array. In case of conflict, new data items are directly stored in the linked list represented by the subscript of the array. This method is called chain address method.
3. Open address method
In the development address method, if the data item cannot be directly stored in the array subscript calculated by the hash function, it is necessary to find other locations. There are three methods: linear detection, secondary detection and rehashing.
①. Linear detection
In linear detection, it will linearly find blank cells. For example, if 5421 is the location where data is to be inserted, but it has been occupied, then use 5422. If 5422 is also occupied, then use 5423, and so on. The array subscripts increase in turn until a blank location is found. This is called linear detection because it looks for blank cells step by step along the array subscript.
Full code:
package com.ys.hash;
public class MyHashTable {
private DataItem[] hashArray; //The DataItem class represents the information of each data item
private int arraySize;//Initial size of the array
private int itemNum;//How many items of data does the array actually store
private DataItem nonItem;//Used to delete data items
public MyHashTable(int arraySize){
this.arraySize = arraySize;
hashArray = new DataItem[arraySize];
nonItem = new DataItem(-1);//The index of the deleted data item is - 1
}
//Determine whether the array is full
public boolean isFull(){
return (itemNum == arraySize);
}
//Determine whether the array is empty
public boolean isEmpty(){
return (itemNum == 0);
}
//Print array contents
public void display(){
System.out.println("Table:");
for(int j = 0 ; j < arraySize ; j++){
if(hashArray[j] != null){
System.out.print(hashArray[j].getKey() + " ");
}else{
System.out.print("** ");
}
}
}
//The array subscript is obtained by hash function conversion
public int hashFunction(int key){
return key%arraySize;
}
//Insert data item
public void insert(DataItem item){
if(isFull()){
//Extended hash table
System.out.println("Hash table is full, re hashing...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction(key);
while(hashArray[hashVal] != null && hashArray[hashVal].getKey() != -1){
++hashVal;
hashVal %= arraySize;
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* The array has a fixed size and cannot be extended, so the extended hash table can only create a larger array, and then insert the data in the old array into the new array.
* However, the hash table calculates the position of the given data according to the size of the array, so these data items can no longer be placed in the same position of the new array and the old array.
* Therefore, you cannot copy directly. You need to traverse the old array in order and insert each data item into the new array using the insert method.
* This process is called rehashing. This is a time-consuming process, but it is necessary if the array is to be extended.
*/
public void extendHashTable(){
int num = arraySize;
itemNum = 0;//Re count, because the original data will be transferred to the new expanded array
arraySize *= 2;//Double array size
DataItem[] oldHashArray = hashArray;
hashArray = new DataItem[arraySize];
for(int i = 0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//Delete data item
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction(key);
while(hashArray[hashVal] != null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem means an empty Item, and its key is - 1
itemNum--;
return temp;
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
//Find data item
public DataItem find(int key){
int hashVal = hashFunction(key);
while(hashArray[hashVal] != null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
++hashVal;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}It should be noted that when the hash table becomes too full, we need to expand the array, but it should be noted that the data items cannot be placed in the same position as the old array, but the insertion position should be recalculated according to the size of the array. This is a time-consuming process, so generally we need to determine the range of data and give the size of a good array without capacity expansion.
In addition, when the hash table becomes full, we should frequently detect the insertion location every time we insert a new data, because many locations may be occupied by the previously inserted data, which is called aggregation. The fuller the array, the more likely aggregation will occur.
It's like a crowd. When someone faints in the mall, the crowd will slowly gather. The first crowd gathered because they saw the fallen man, while the latter gathered because they wanted to know what they were looking at together. The larger the crowd, the more people it will attract.
②. Filling factor
The ratio of the data items filled in the hash table to the table length is called the filling factor. For example, after 6667 data are filled in the hash table with 10000 units, the filling factor is 2 / 3. When the loading factor is not too large, the aggregation distribution is more consistent, while when the loading factor is relatively large, the aggregation occurs greatly.
We know that linear detection is a step-by-step backward detection. When the loading factor is relatively large, aggregation will occur frequently. If we detect relatively large units instead of step-by-step detection, this is the secondary detection to be discussed below.
③ secondary detection
Secondary detection is a way to prevent aggregation. The idea is to detect units far away from each other, rather than units adjacent to the original position.
In linear detection, if the original subscript calculated by hash function is x, linear detection is x+1, x+2, x+3, and so on; In the secondary detection, the detection process is x+1, x+4, x+9, x+16, and so on. The distance to the original position is the square of the number of steps. Although secondary detection eliminates the original aggregation problem, it produces another finer aggregation problem, which is called secondary aggregation: for example, 184302420 and 544 are inserted into the table in turn, and their mapping is 7. Then 302 needs to detect with 1 as the step, 420 needs to detect with 4 as the step, and 544 needs to detect with 9 as the step. As long as there is an item whose keyword is mapped to 7, a longer step detection is required. This phenomenon is called secondary aggregation. Secondary aggregation is not a serious problem, but secondary detection will not be used often because there are good solutions, such as re hashing.
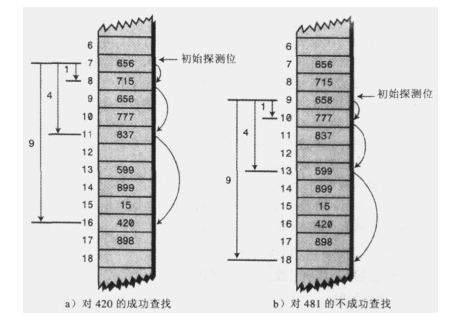
④ Re hashifa
In order to eliminate the original aggregation and secondary aggregation, we use another method: re hashing method.
We know that the reason for secondary aggregation is that the step size of the detection sequence generated by the algorithm of secondary detection is always fixed: 1, 4, 9, 16 and so on. What we think of is that we need to generate a probe sequence that depends on keywords, instead of each keyword being the same. Then, different probe sequences can be used even if different keywords are mapped to the same array subscript.
The method is to hash the keyword again with different hash functions, and use the result as the step size. For the specified keyword, the step size is unchanged throughout the probe, but different keywords use different steps.
The second hash function must have the following characteristics:
I. different from the first hash function
2. 0 cannot be output (otherwise, there will be no step size, each detection is in situ, and the algorithm will fall into a dead cycle).
Experts have found that the following forms of hash functions work very well: stepsize = constant - key% constant; Where constant is a prime number and is less than the capacity of the array.
Then Hashi method requires that the capacity of the table is a prime number. If the table length is 15 (0-14), non prime number, a specific keyword is mapped to 0, and the step size is 5, the detection sequence is 0,5,10,0,5,10, and so on. The algorithm only tries these three units, so it is impossible to find some blank units, and eventually the algorithm crashes. If the array capacity is 13, prime, the probe sequence will eventually access all cells. That is, 0,5,10,2,7,12,4,9,1,6,11,3. It can be detected as long as there is a vacancy in the table.
Full rehash Code:
package com.ys.hash;
public class HashDouble {
private DataItem[] hashArray; //The DataItem class represents the information of each data item
private int arraySize;//Initial size of the array
private int itemNum;//How many items of data does the array actually store
private DataItem nonItem;//Used to delete data items
public HashDouble(){
this.arraySize = 13;
hashArray = new DataItem[arraySize];
nonItem = new DataItem(-1);//The index of the deleted data item is - 1
}
//Determine whether the array is full
public boolean isFull(){
return (itemNum == arraySize);
}
//Determine whether the array is empty
public boolean isEmpty(){
return (itemNum == 0);
}
//Print array contents
public void display(){
System.out.println("Table:");
for(int j = 0 ; j < arraySize ; j++){
if(hashArray[j] != null){
System.out.print(hashArray[j].getKey() + " ");
}else{
System.out.print("** ");
}
}
}
//The array subscript is obtained by hash function conversion
public int hashFunction1(int key){
return key%arraySize;
}
public int hashFunction2(int key){
return 5 - key%5;
}
//Insert data item
public void insert(DataItem item){
if(isFull()){
//Extended hash table
System.out.println("Hash table is full, re hashing...");
extendHashTable();
}
int key = item.getKey();
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);//The second hash function is used to calculate the number of detection steps
while(hashArray[hashVal] != null && hashArray[hashVal].getKey() != -1){
hashVal += stepSize;
hashVal %= arraySize;//Probe backward in the specified number of steps
}
hashArray[hashVal] = item;
itemNum++;
}
/**
* The array has a fixed size and cannot be extended, so the extended hash table can only create a larger array, and then insert the data in the old array into the new array.
* However, the hash table calculates the position of the given data according to the size of the array, so these data items can no longer be placed in the same position of the new array and the old array.
* Therefore, you cannot copy directly. You need to traverse the old array in order and insert each data item into the new array using the insert method.
* This process is called rehashing. This is a time-consuming process, but it is necessary if the array is to be extended.
*/
public void extendHashTable(){
int num = arraySize;
itemNum = 0;//Re count, because the original data will be transferred to the new expanded array
arraySize *= 2;//Double array size
DataItem[] oldHashArray = hashArray;
hashArray = new DataItem[arraySize];
for(int i = 0 ; i < num ; i++){
insert(oldHashArray[i]);
}
}
//Delete data item
public DataItem delete(int key){
if(isEmpty()){
System.out.println("Hash Table is Empty!");
return null;
}
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] != null){
if(hashArray[hashVal].getKey() == key){
DataItem temp = hashArray[hashVal];
hashArray[hashVal] = nonItem;//nonItem means an empty Item, and its key is - 1
itemNum--;
return temp;
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
//Find data item
public DataItem find(int key){
int hashVal = hashFunction1(key);
int stepSize = hashFunction2(key);
while(hashArray[hashVal] != null){
if(hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
hashVal += stepSize;
hashVal %= arraySize;
}
return null;
}
public static class DataItem{
private int iData;
public DataItem(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
}
}
4. Chain address method
In the open address method, a vacancy is found to solve the conflict problem through the re hashing method. Another method is to set a linked list (i.e. chain address method) in each cell of the hash table. The keyword value of a data item is still mapped to the cell of the hash table as usual, and the data item itself is inserted into the linked list of this cell. Other data items also mapped to this position only need to be added to the linked list, and there is no need to find empty bits in the original array.
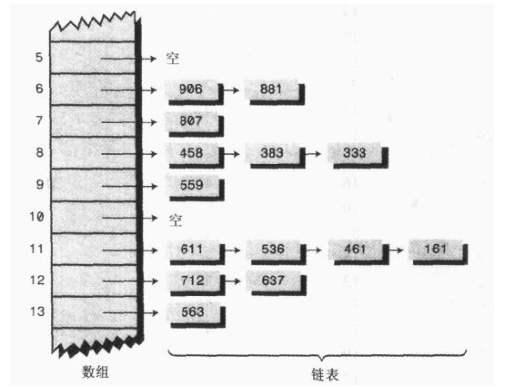
Ordered linked list:
package com.ys.hash;
public class SortLink {
private LinkNode first;
public SortLink(){
first = null;
}
public boolean isEmpty(){
return (first == null);
}
public void insert(LinkNode node){
int key = node.getKey();
LinkNode previous = null;
LinkNode current = first;
while(current != null && current.getKey() < key){
previous = current;
current = current.next;
}
if(previous == null){
first = node;
}else{
previous.next = node;
}
node.next = curent;
}
public void delete(int key){
LinkNode previous = null;
LinkNode current = first;
if(isEmpty()){
System.out.println("Linked is Empty!!!");
return;
}
while(current != null && current.getKey() != key){
previous = current;
current = current.next;
}
if(previous == null){
first = first.next;
}else{
previous.next = current.next;
}
}
public LinkNode find(int key){
LinkNode current = first;
while(current != null && current.getKey() <= key){
if(current.getKey() == key){
return current;
}
current = current.next;
}
return null;
}
public void displayLink(){
System.out.println("Link(First->Last)");
LinkNode current = first;
while(current != null){
current.displayLink();
current = current.next;
}
System.out.println("");
}
class LinkNode{
private int iData;
public LinkNode next;
public LinkNode(int iData){
this.iData = iData;
}
public int getKey(){
return iData;
}
public void displayLink(){
System.out.println(iData + " ");
}
}
}Chain address method:
package com.ys.hash;
import com.ys.hash.SortLink.LinkNode;
public class HashChain {
private SortLink[] hashArray;//Store linked list in array
private int arraySize;
public HashChain(int size){
arraySize = size;
hashArray = new SortLink[arraySize];
//new initializes the array for each empty linked list
for(int i = 0 ; i < arraySize ; i++){
hashArray[i] = new SortLink();
}
}
public void displayTable(){
for(int i = 0 ; i < arraySize ; i++){
System.out.print(i + ": ");
hashArray[i].displayLink();
}
}
public int hashFunction(int key){
return key%arraySize;
}
public void insert(LinkNode node){
int key = node.getKey();
int hashVal = hashFunction(key);
hashArray[hashVal].insert(node);//You can add it directly to the linked list
}
public LinkNode delete(int key){
int hashVal = hashFunction(key);
LinkNode temp = find(key);
hashArray[hashVal].delete(key);//Find the data item to be deleted from the linked list and delete it directly
return temp;
}
public LinkNode find(int key){
int hashVal = hashFunction(key);
LinkNode node = hashArray[hashVal].find(key);
return node;
}
}In the chain address method, the loading factor (the ratio of the number of data items to the capacity of the hash table) is different from the open address method. In the chain address method, an array of N units is required to transfer in N or more data items. Therefore, the loading factor is generally 1 or greater than 1 (there may be two or more data items in the chain list contained in some locations).
The time level of O(1) is required to find the initial unit, and the time of searching the linked list is directly proportional to M. m is the average number of items contained in the linked list, that is, the time level of O(M).
5. Bucket
Another method is similar to the chain address method. It uses subarrays in each data item instead of linked lists. Such an array is called a bucket.
This method is obviously not as effective as the linked list, because the bucket capacity is not easy to choose. If the capacity is too small, it may overflow. If it is too large, it will cause performance waste. However, the linked list is dynamically allocated, so there is no such problem. Therefore, barrels are generally not used.
6. Summary
The hash table is based on an array, similar to the storage form of key value. The keyword value is mapped into the index of the array through the hash function. If a keyword is hashed to the occupied array unit, this situation is called conflict. There are two methods to solve conflicts: open address method and chain address method. In the development of address method, the conflicting data items are placed in other positions of the array; In the chain address method, each cell contains a linked list, and all data items mapped to the same array subscript are inserted into the linked list.